
이번 글에서는 오는 7월 대한민국 서울에서 개최되는 머신러닝(ML) 및 인공지능(AI) 분야 최고 권위의 학술대회인 ICML 2026에서 발표될 네이버클라우드의 논문(Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging)을 소개합니다.
최민식 (NAVER Cloud*, 고려대학교)
김기욱 (NAVER Cloud, KAIST)
* Internship
서로 충돌하는 데이터를 다루는 새로운 관점
최근 멀티모달 대규모 언어모델(MLLM)을 만드는 표준 레시피는 점점 더 큰 여러 종류의 지시 및 응답 데이터를 한데 섞은 학습 데이터인 Instruction Mixture를 활용한 후학습(Post-training)으로 수렴하고 있습니다. 인식(Perception), 추론(Reasoning), OCR, 문서 이해, 비디오 이해 등 모델이 수행해야 하는 능력이 다양해질수록, 학습에 사용되는 데이터셋의 수와 종류 역시 빠르게 늘어나고 있는데요. 하지만 서로 다른 성격의 데이터를 하나의 학습 과정에 함께 투입한다고 해서 항상 좋은 결과가 나오는 것은 아닙니다. 오히려 규모가 커질수록 두 가지 문제가 점점 더 뚜렷하게 드러납니다.
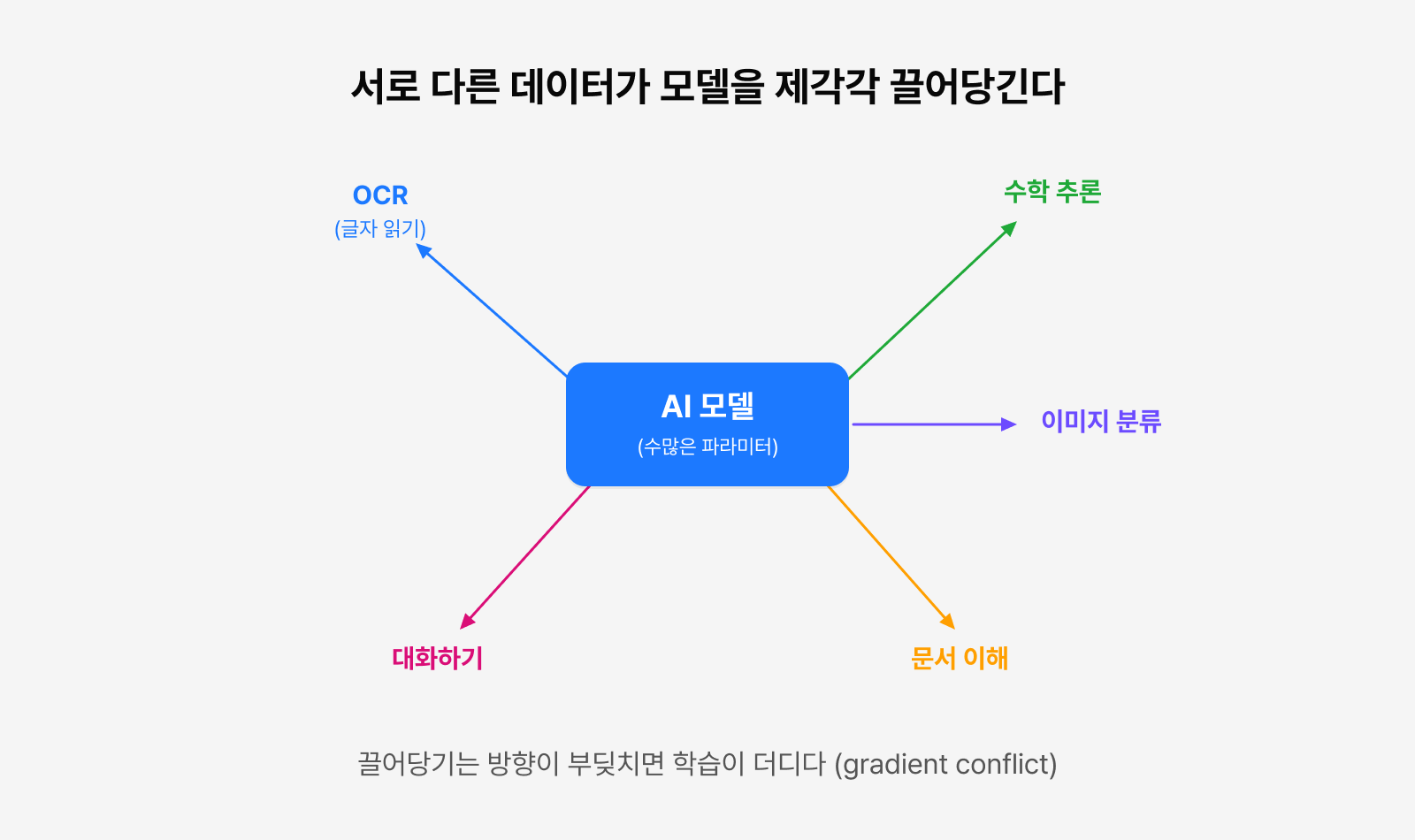
그림 1. 서로 다른 데이터셋이 모델을 각기 다른 방향으로 끌어당기면서 발생하는 Gradient Conflict
첫째, 데이터셋 간 충돌 (Gradient Conflict)
서로 다른 목표를 가진 태스크들이 하나의 모델 안에서 경쟁하다 보면, 한쪽을 잘하게 만드는 학습이 다른 쪽 능력을 깎아내리는 Negative Transfer가 생깁니다. 여러 사람이 한 수레를 제각기 다른 방향으로 미는 상황과 비슷한데요. 그 결과 학습 효율과 최종 성능이 저하될 수 있습니다.
둘째, 무거운 통신 비용
일반적으로 모든 데이터를 한꺼번에 함께 학습하는 방식인 Joint Training은 학습 스텝마다 All-reduce 연산으로 GPU 간 Gradient를 동기화해야 합니다. 여러 GPU가 각자 계산한 학습 방향을 매번 한 데 하나로 모아 맞추는 과정인데요. 이는 곧 NVLink 같은 초고속 인터커넥트로 촘촘히 연결된 대규모 클러스터를 사실상 전제로 한다는 뜻입니다. 따라서 GPU가 여러 서버에 분산되어 있거나 자원이 파편화된 환경에서는 이 방식이 비효율적이거나 아예 적용하기 어려울 수 있습니다.
저희가 이번에 공개한 논문 MERIT(Merge-Ready Instruction Tuning)은 이 두 문제를 동시에 해결하는 새로운 관점을 제안합니다. 핵심 아이디어는 의외로 단순합니다.
“데이터셋을 합치기 전에, 먼저 잘 나눈다.”
MERIT은 먼저 데이터셋 간의 관계를 분석해 서로 유사한 데이터셋끼리 그룹을 구성하고, 각 그룹을 독립적으로 Fine-tuning 한 뒤 마지막에 여러 모델의 가중치를 평균 내어 하나로 합치는 Weight Merging을 단 한 번만 수행합니다. 학습하는 동안 그룹 간 통신이 전혀 필요하지 않으면서도, 최종적으로는 하나의 통합 모델을 얻게 되죠.
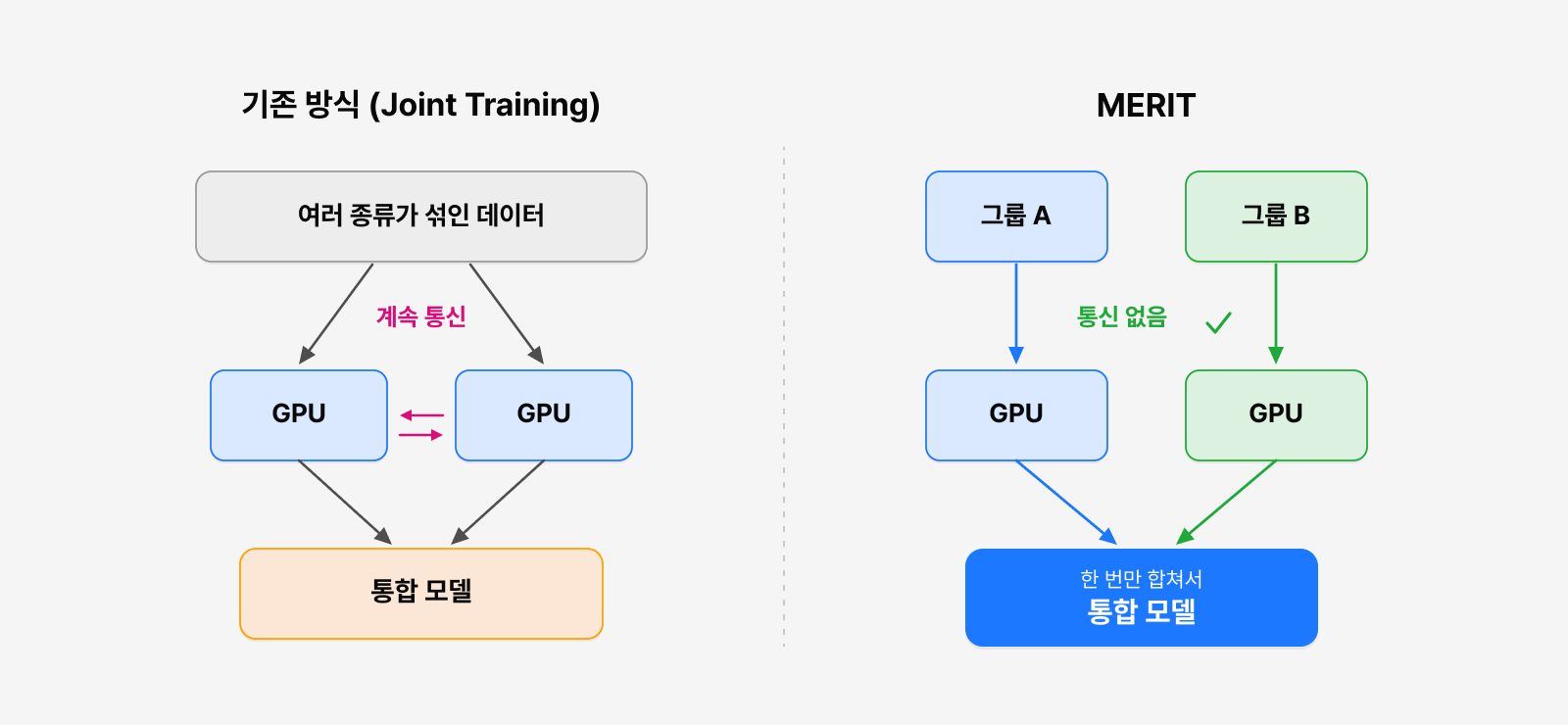
그림 2. 매 스텝 Gradient를 동기화하는 기존 Joint Training(좌)과 그룹별로 독립 학습한 뒤 한 번만 병합하는 MERIT(우)
왜 먼저 나누고 나중에 합치는가?
기존의 멀티모달 Instruction Tuning, 즉 모델이 다양한 지시를 잘 따르도록 가르치는 학습은 다양한 데이터셋을 하나의 거대한 덩어리(Mixture)로 섞은 뒤, 단일 클러스터에서 지속적으로 Gradient를 동기화하며 학습하는 방식이 일반적이었습니다. 이 방식에서는 데이터셋 간 충돌 역시 학습 스텝마다 서로 다른 데이터가 모델을 반대로 끌어당기는 Gradient Conflict 문제로 다뤄져 왔습니다.
그런데 정말 모든 데이터를 동시에 함께 학습해야 할까요?
본 연구에서는 오히려 학습 전에 데이터셋을 적절히 분리하는 것이 더 중요하다고 보았습니다. 먼저 데이터셋 간 Gradient 충돌 구조를 분석하고, 서로 충돌이 큰 데이터셋은 다른 그룹으로 떼어놓고 비슷한 학습 방향을 갖는 데이터셋끼리 묶습니다. 각 그룹은 서로 통신 없이 독립적으로 Fine-tuning 하고, 학습이 끝난 뒤 데이터양에 비례해 가중치를 둔 평균을 내는 방식(Token-weighted Averaging)으로 한 번만 병합하는 것이죠.
이 접근이 잘 동작하는 이유는 Merge-ready Initialization, 즉 합치기 좋은 출발점에 있습니다. 현대 MLLM의 후학습은 보통 이미 충분히 정렬된 강력한 체크포인트(예: LLaVA Training Recipe를 거친 모델)에서 시작하는데요. 이렇게 잘 정렬된 지점에서 출발한 모델들은 Fine-tuning 과정에서도 대체로 Loss가 완만하게 낮은 분지 형태의 영역, 즉 Flat Basin 안에 머무르는 경향이 있습니다. 쉽게 말해 서로 다른 데이터셋으로 학습되더라도 모델들은 여전히 비슷한 파라미터 영역에 위치한다는 뜻이죠. 따라서 각 그룹을 독립적으로 학습하더라도, 마지막에 각 모델의 가중치를 위치마다 단순 평균을 내는 Weight Averaging 방식만으로 자연스럽게 하나의 모델로 병합될 수 있습니다. 이는 여러 모델을 평균 내 더 좋은 성능을 얻은 Model Soups 계열 연구에서 관찰된 현상과도 유사합니다.
MERIT 파이프라인
조금 더 구체적으로 들여다보면, MERIT은 크게 다섯 단계로 구성됩니다.
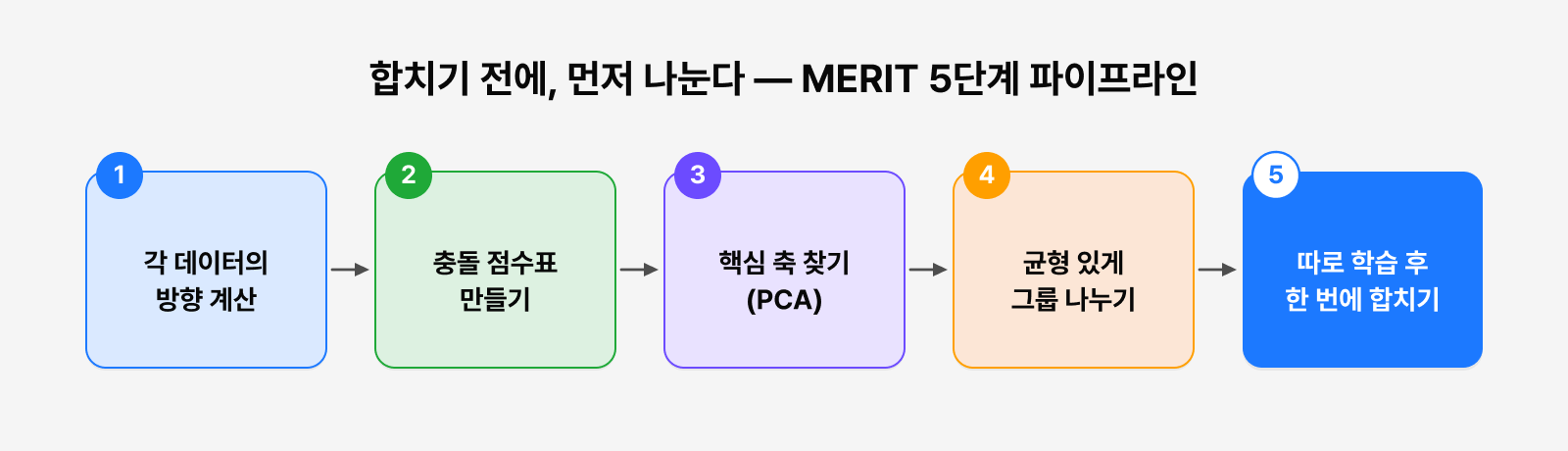
그림 3. MERIT의 5단계 파이프라인
Gradient 추정 → Conflict Matrix → PCA → Balanced Partitioning → 독립 학습·병합
1. 각 데이터의 방향 계산: Dataset-level Gradient 추정
먼저 각 데이터셋에서 약 200개의 샘플을 추출해, Merge-ready Initialization 시점에서 그 데이터셋을 대표하는 Gradient gi를 계산합니다. 즉 ‘이 데이터셋은 모델을 어느 방향으로 끌어당기는가’를 하나의 화살표로 요약하는 셈인데요. 200개 샘플만으로 충분한지 의문이 들 수 있지만, 실험적으로는 약 160~200개 수준부터 Gradient 방향이 안정적으로 수렴하는 구간에 진입하는 것을 확인했습니다.
2. 충돌 점수표 만들기: Cosine Similarity 기반 Conflict Matrix 구축
다음으로 데이터셋 쌍마다 Gradient 방향이 얼마나 비슷한지를 Cosine Similarity로 계산합니다.
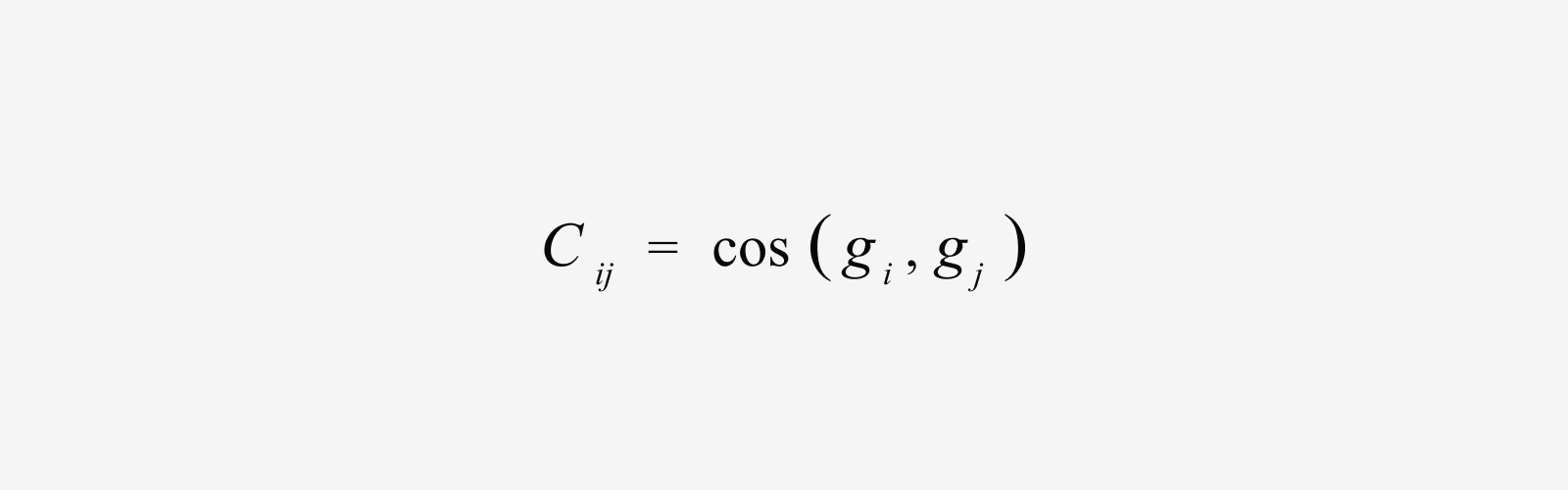
값이 클수록 두 데이터셋이 모델을 비슷한 방향으로 업데이트한다는 의미이기 때문에, 함께 학습해도 충돌이 적을 가능성이 높습니다. 반대로 값이 작거나 음수면 상반된 방향으로 모델을 끌어당겨, Gradient Conflict가 발생할 가능성이 크죠. 두 데이터셋이 같은 쪽을 보는지 혹은 등을 돌리고 있는지를 수치로 나타낸 표라고 보면 됩니다.
3. 핵심 축 찾기: PCA를 통한 Dominant Conflict Axes 추출
이후 Conflict Matrix C에 PCA를 적용해 데이터셋 간 의견 차이를 가장 잘 설명하는 상위 r개 Eigenvector, 즉 주성분(대표 축)을 추출합니다. 각 데이터셋은 이 대표 축을 기준으로 새로운 공간에 배치되며, 각 축은 데이터셋 간 의견 차이가 가장 크게 나타나는 방향을 의미하는데요. 쉽게 말해 데이터셋들이 어떤 주제에서 가장 크게 의견이 갈리는지를 보여줍니다. 이를 통해 수많은 충돌 관계를 몇 개의 대표적인 방향으로 요약할 수 있습니다.
4. 균형 있게 그룹 나누기: Balanced Conflict-aware Partitioning
추출된 PCA 좌표를 기준으로 데이터셋을 재귀적으로 분할합니다. 단순히 좌표의 부호(+/−)만으로 나누면 한쪽 그룹에 데이터가 과도하게 몰릴 수 있어, MERIT은 각 그룹의 크기가 최대한 균형을 이루도록 분할 알고리즘을 설계했습니다.
이 과정을 재귀적으로 반복하면 데이터셋은 점차 더 세분되는데요. 예를 들어 1회 나누면 2개, 2회차에서는 4개, 3회차에서는 8개 그룹으로 나뉘게 됩니다. 이를 통해 서로 유사한 특성을 가진 데이터셋은 같은 그룹으로 묶고, 서로 충돌하는 데이터셋은 자연스럽게 분리할 수 있습니다.
5. 따로 학습 후 한 번에 합치기: 독립 학습과 단 한 번의 병합
데이터셋을 그룹으로 나눈 뒤에는 마지막으로 각 그룹을 동일한 초기 체크포인트에서 독립적으 Fine-tuning 합니다. 이 과정에서 그룹 간에는 별도의 통신이 이루어지지 않습니다. 학습이 끝난 뒤에는 각 그룹에서 학습된 모델을 하나로 병합하는데요. 이때 데이터양에 비례해 가중치를 둔 평균인 Token-weighted Averaging을 사용하여 단 한 번만 모델을 병합합니다.
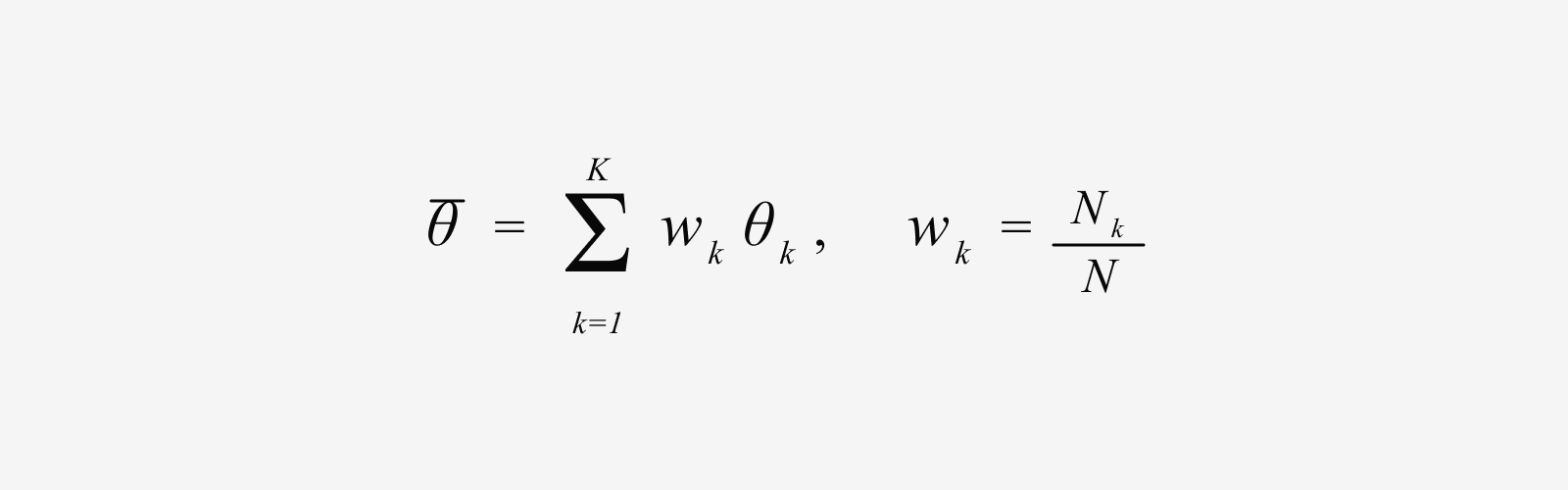
여기서 Nk는 그룹 k가 학습에 사용한 토큰 수를 의미합니다. 여기서 중요한 점은 MERIT이 기존 방법보다 더 많은 데이터를 학습한 것이 아니라는 점입니다. 본 연구에서는 MERIT과 기존 방식인 Joint Training의 전체 학습 토큰 수를 동일하게 유지했습니다. 따라서 MERIT이 더 좋은 성능을 보였다면, 그 이유는 추가 학습량 때문이 아니라 데이터를 충돌 패턴에 따라 분할하고 다시 병합하는 학습 전략 자체에 있다고 볼 수 있습니다.
MERIT의 핵심: 왜 모델을 평균 내도 성능이 유지될까?
조금 더 깊이 들어가 보면 MERIT이 잘 동작하는 이유는 Loss Landscape 관점에서 설명할 수 있습니다. 여기서 Loss는 모델의 오류 정도를 나타내는 값으로, 학습 과정은 이 값을 낮추는 방향으로 진행됩니다. 연구진은 각 그룹에서 학습된 모델들이 모두 비슷한 성능의 해답 영역(Flat Basin) 안에 위치한다고 가정했습니다. Flat Basin은 모델 파라미터가 조금 달라져도 성능이 크게 변하지 않는 비교적 넓고 평평한 영역을 의미하는데요.
이때 같은 Flat Basin 안에 있는 모델 체크포인트 θₖ에 대해 Loss를 Local Quadratic으로 근사하면, 가중 평균 모델의 Loss는 개별 모델 Loss의 가중 평균보다 작거나 같게 나타납니다. 이 차이는 아래와 같은 Curvature-weighted Variance 형태로 정리됩니다.
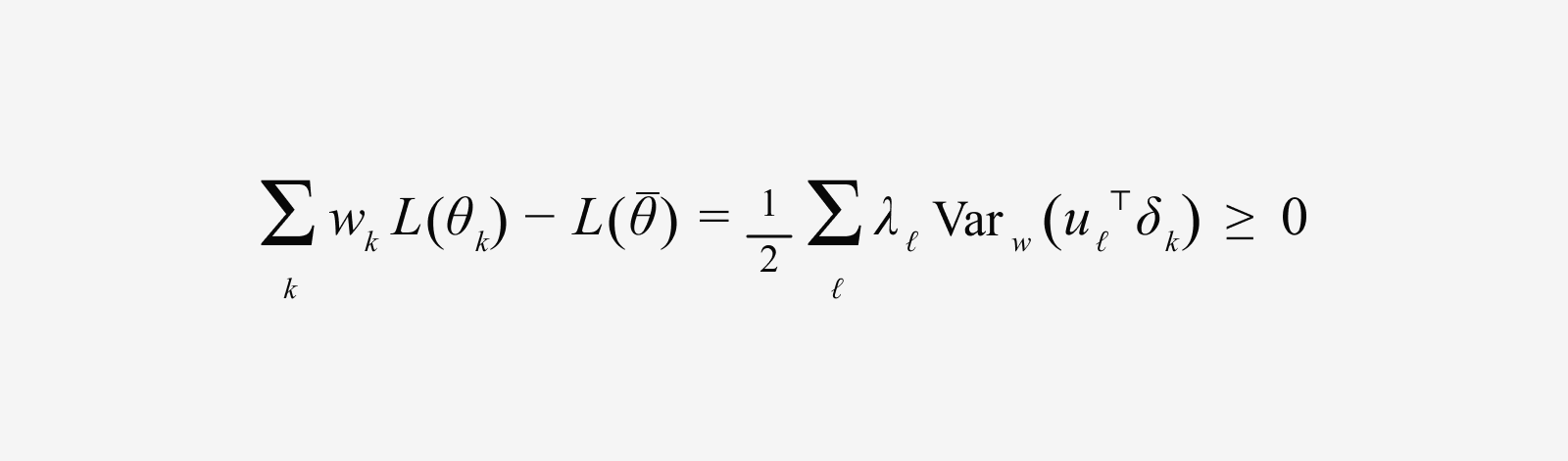
여기서 λℓ은 Hessian의 고윳값으로 해당 방향이 모델 성능에 얼마나 큰 영향을 미치는지를 나타내는 값인데요. λ가 클수록 해당 방향에서의 작은 변화도 성능에 큰 영향을 줄 수 있습니다. uℓ은 대응하는 고유벡터로 모델 파라미터 공간에서의 특정 변화 방향을 의미합니다.
이 식이 의미하는 바는 직관적입니다. λℓ 값이 큰 방향, 즉 Curvature이 커서 모델 성능이 민감하게 변하는 방향에서 모델들이 서로 다르게 움직일수록 병합을 통해 얻을 수 있는 이득이 커진다는 것입니다. 쉽게 말해 성능에 큰 영향을 미치는 방향에서 각 모델이 서로 다른 정보를 학습한 경우, 병합 과정에서 각 모델의 강점은 유지하면서도 편향이나 충돌은 완화될 수 있습니다.
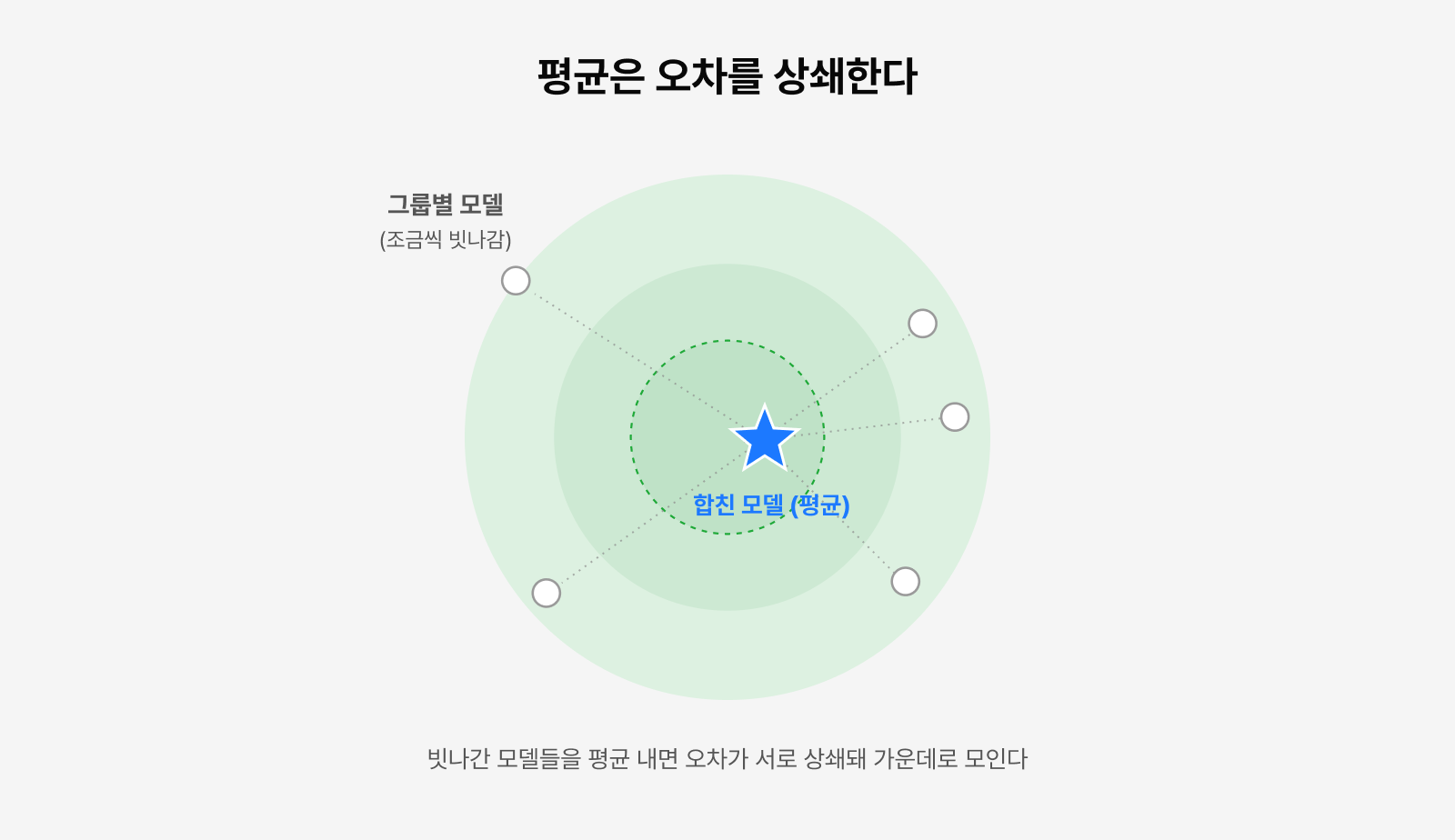
그림 4. 개별 모델들이 빗나간 방향으로 흩어져 있어도, 가중 평균은 그 변동을 상쇄해 더 나은 한 점으로 모인다.
MERIT의 PCA 기반 분할은 바로 이 점을 활용합니다. 데이터셋 간 주요 Gradient Conflict를 기준으로 그룹을 나누면, 각 그룹은 서로 다른 방향의 업데이트를 학습하게 되는데요. 이후 이 모델들을 병합하면 이러한 차이가 평균화되면서, 특히 모델 성능이 민감하게 변하는 High-curvature 방향에서의 불필요한 변동이 효과적으로 줄어듭니다.
비유하자면 Merging은 일종의 Curvature-aware Spectral Filter처럼 동작합니다. 기존 방식인 Joint Training에서는 모든 데이터셋의 업데이트가 학습 내내 함께 상호작용하는 반면, MERIT은 먼저 독립적으로 학습한 뒤 병합 과정에서 High-curvature 방향에서 발생한 차이를 평균화합니다. 쉽게 말해 모델 병합 과정은 여러 의견이 충돌하는 토론을 정리하는 편집자의 역할과 비슷한데요. 각 모델이 독립적으로 학습하며 생긴 차이 가운데, 성능에 큰 영향을 미치는 방향에서의 편차는 병합 과정에서 평균화됩니다. 그 결과 데이터셋 간 충돌은 완화하면서도 각 모델이 학습한 정보를 하나의 모델로 통합할 수 있는 것이죠. 결과적으로 MERIT은 학습 중 통신 없이도 Gradient Conflict를 완화하면서, 병합을 통해 성능을 개선할 수 있습니다.
실험 결과
1. Controlled Ablation: MERIT의 성능 향상은 어디서 올까?
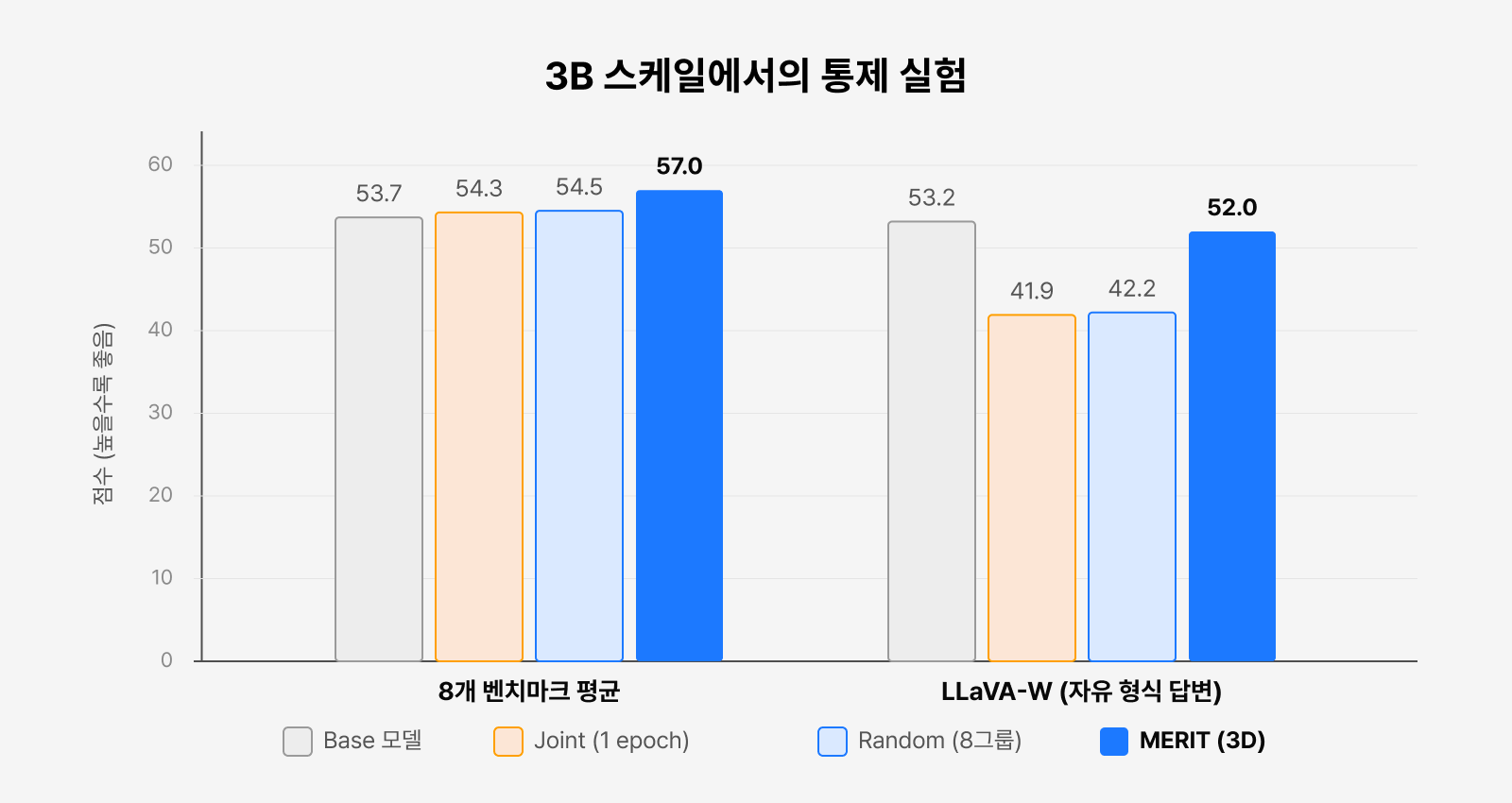
그림 5. 3B 통제 실험. 8개 벤치마크 평균에서 MERIT(3D)이 가장 높고,
자유 형식 답변(LLaVA-W)에서는 Joint Training이 크게 무너지는 동안 MERIT이 원본 수준을 지킨다.
Qwen2.5-VL-3B, 136개 Vision-FLAN 태스크를 활용한 실험에서 확인한 가장 흥미로운 결과 중 하나는 단순히 데이터셋을 무작위로 나누어 병합하는 방식인 Random Split만 적용하더라도 기존 Joint Training보다 성능이 소폭 향상되었다는 점입니다. 이는 ‘합치기 쉬운 출발점’인 Merge-ready Initialization 덕분에 어떤 방식으로 분할하더라도 Weight Merging 자체에서 일정 수준의 이득을 얻을 수 있음을 보여줍니다.
그러나 데이터셋 간 충돌을 고려해 분할하는 Conflict-aware Split을 적용하면 성능 격차는 한층 뚜렷해집니다. Random Split은 모델 간 차이를 통제 없이 나누는 데 그친다면, MERIT은 주요 충돌 축인 conflict axis를 기준으로 나누어 병합 효과가 가장 커지는 방향으로 차이를 유도하기 때문이죠.
특히 LLaVA-W 같은 자유 형식 응답 평가에서 효과가 두드러집니다. Joint Training은 점수가 41.9~42.8까지 떨어지는 반면, MERIT은 52.0을 기록해 원본 모델(53.2)에 훨씬 가까운 성능을 유지했는데요. 즉, 다양한 데이터셋을 한꺼번에 학습하는 과정에서 발생하는 성능 저하를 효과적으로 완화한 것입니다. 이는 뒤에서 설명할 Short-answer Collapse 현상과도 밀접하게 연결됩니다. 전체 결과는 아래 표와 같습니다.
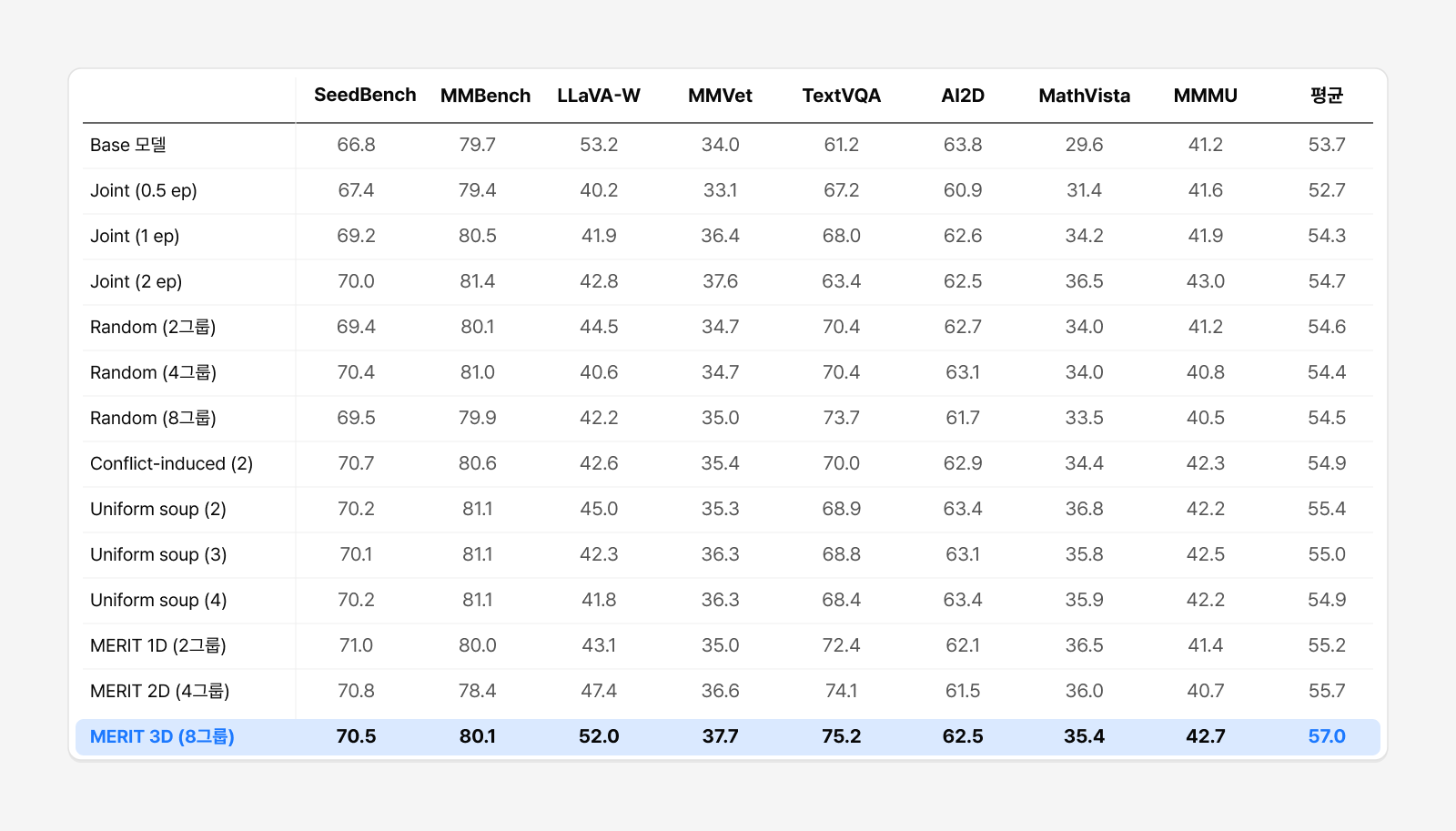
표 1. 3B 통제 실험 전체 결과 (논문 Table 2, Qwen2.5-VL-3B · 136개 Vision-FLAN). 굵게 = 최고 평균
2. Large-scale MLLM Setting: 모델과 데이터 규모를 키워도 효과는 유지될까?
앞선 실험이 통제된 환경에서 MERIT의 효과를 검증했다면, 이번에는 더 큰 모델과 더 많은 데이터를 활용한 환경에서도 동일한 경향이 나타나는지 살펴봤습니다. 그 결과 Qwen2.5-7B, 1.6M Mixture를 활용한 더 큰 규모의 설정에서도 유사한 경향이 관찰됐습니다.
동일한 데이터 예산(0.7M + 1.6M)에서 Joint FFT와 MERIT을 비교하면 전체 평균은 비슷하지만(54.9 → 55.4), 세부 항목에서는 의미 있는 차이가 나타났습니다. 특히 MMVet(32.5 → 35.1)이나 MathVista(32.9 → 35.4)처럼 자유 형식 응답과 복합 추론이 중요한 항목에서 MERIT이 더 높은 성능을 기록했습니다. 반면 텍스트 중심(Text-rich)의 평가 항목에서는 근소하게 낮아지는 경향도 확인되었습니다.
이러한 경향은 모델과 데이터 규모를 키운 3.6M 설정에서도 유지되었는데요. 전체 평균 성능은 MERIT이 60.9에서 61.5로 향상되었으며, 특히 자유 형식 응답을 평가하는 LLaVA-W에서는 차이가 더욱 두드러졌습니다. Joint FFT의 경우 점수가 67.1에서 50.2까지 크게 하락한 반면, MERIT은 66.2를 유지하며 원본 모델의 성능을 거의 그대로 보존했습니다. 이는 앞선 Controlled Study에서 관찰된 ‘스타일 보존’ 효과가 대규모 환경에서도 유효함을 보여주는 결과라고 볼 수 있습니다.
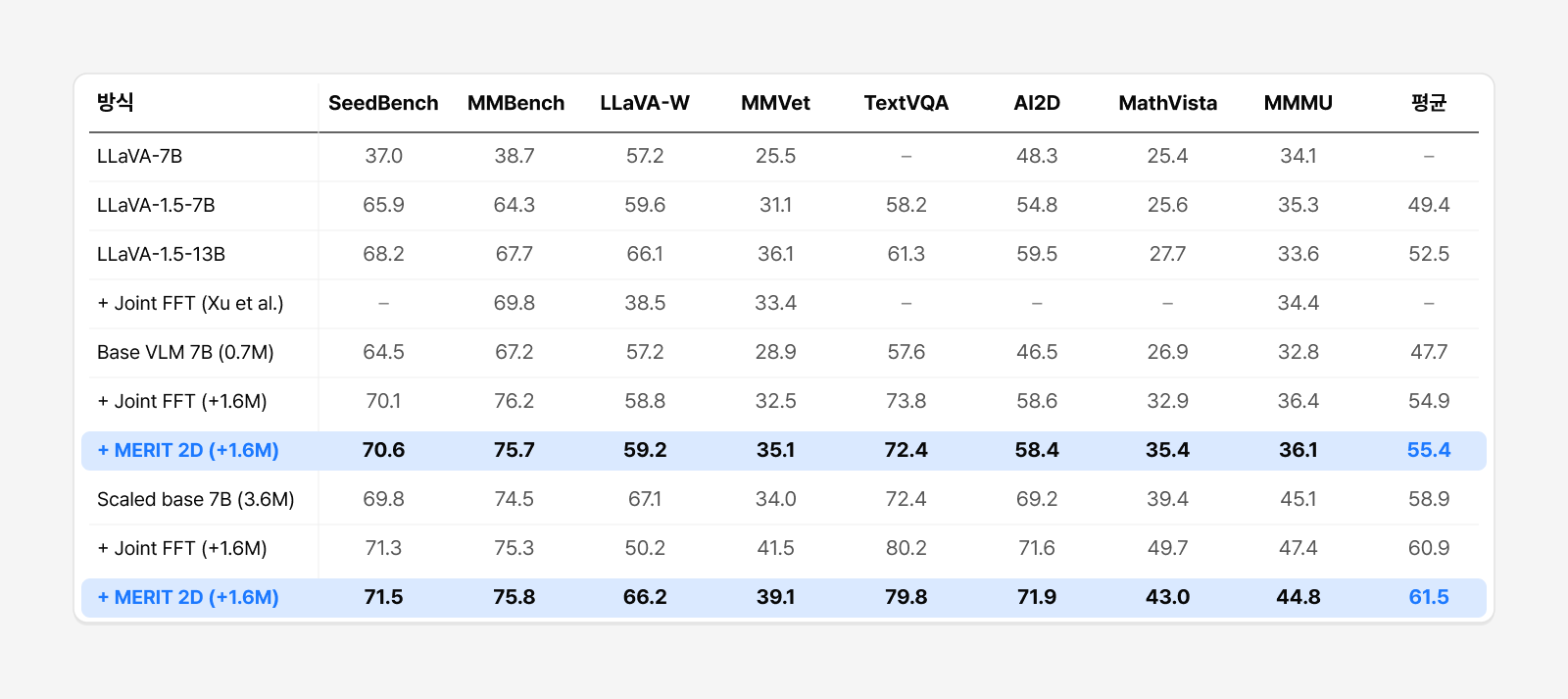
표 2. 7B 실험 전체 결과 (논문 Table 3). 두 가지 base 모델에서 Joint FFT와 MERIT(2D)을 같은 학습량으로 비교
3. Text-only Instruction Tuning Setting: 텍스트 모델에서도 확인된 MERIT의 효과
Qwen2.5-3B와 FLAN Mixture를 활용한 순수 텍스트 Instruction Tuning에서도 동일한 파이프라인을 적용해 보았습니다. MERIT(2D)는 8개 텍스트 벤치마크 평균 58.4를 기록해, Joint Training (1 epoch, 57.6)을 앞서고 두 배로 학습한 Joint Training (2 epoch, 58.3) 및 Random Split(58.2~58.3)을 절반의 학습량으로 따라잡거나 넘어섰습니다. 즉 MERIT의 성능 향상은 특정 멀티모달 환경에서만 나타나는 현상이 아니었습니다. 이는 텍스트 기반 Instruction Tuning에서도 데이터셋 간 충돌을 고려한 분할 전략이 효과적으로 작동하며, 더 적은 학습량으로도 기존 학습 방식과 동등하거나 더 나은 성능을 달성할 수 있음을 보여줍니다.
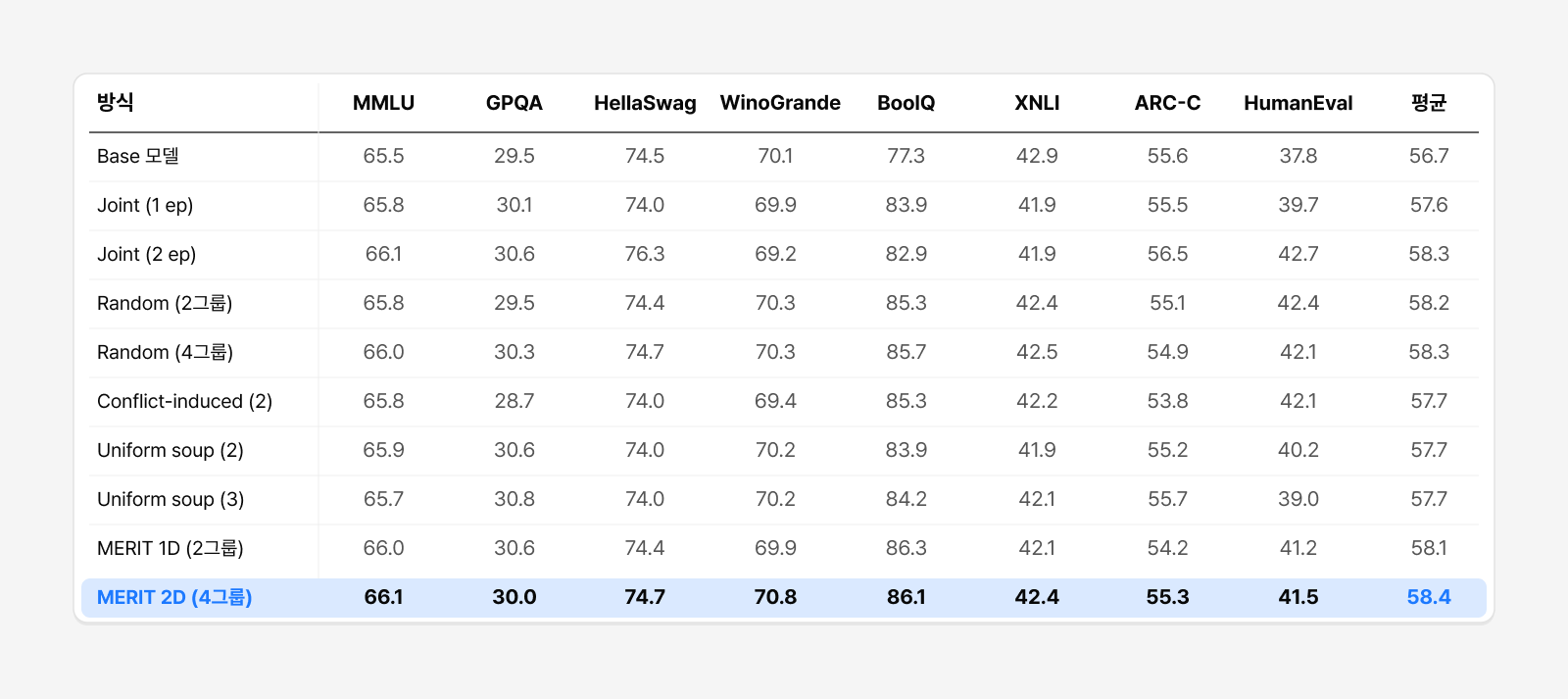
표 3. 순수 텍스트 Instruction Tuning 전체 결과 (논문 Table 4, Qwen2.5-3B · 66개 FLAN 태스크)
짚어볼 만한 디테일 두 가지
1. Short-answer Collapse가 사라지는 이유
LLaVA-W처럼 응답의 유용성뿐 아니라 사용자 선호도와 응답 스타일까지 평가하는 벤치마크에서는, Joint Training 과정에서 응답이 지나치게 짧고 단순한 형태로 수렴하는 현상(Short-answer Collapse)이 종종 관찰됩니다. 이러한 현상은 Vision-FLAN과 같은 정답형(Short-form) 태스크와 대화형 태스크가 같은 학습 과정 안에서 경쟁하면서 발생하는 현상으로 풀이되는데요. 한쪽은 간결한 정답을 선호하고, 다른 한쪽은 풍부한 설명과 상호작용을 요구하기 때문에 학습 과정에서 충돌이 발생하는 것입니다.
반면 MERIT은 이들을 초기 단계부터 서로 다른 그룹으로 분리하기 때문에, 각 스타일이 독립적으로 유지된 채 학습됩니다. 결과적으로 최종 병합 이후에도 대화 능력이 더 잘 보존되며, 응답의 다양성과 풍부함 역시 유지되는 경향을 보입니다.
2. 실용성에 대한 고민
MERIT은 학습 전에 한 번의 전처리 단계를 거쳐야 합니다. 이 단계가 너무 무겁다면 실용성이 떨어질 텐데요, 본 연구에서는 이 비용도 함께 따져봤습니다. 3B 모델 실험 환경 기준으로 Gradient 추출에 약 1시간 반, Similarity Matrix 계산에 약 30분이 걸렸는데요. 실제 학습에 드는 시간에 비하면 충분히 감당할 만한 수준이었습니다. 게다가 새로운 데이터셋 m개가 추가되더라도 전체 파이프라인을 다시 돌릴 필요는 없습니다. 기존 데이터셋과의 유사도인 Cross-similarity만 추가로 계산하면 되고, 그 비용도 O(Tm) 수준에 머물기 때문이죠. (T는 기존 데이터셋 수, m은 새로 추가된 데이터셋 수입니다.) 덕분에 데이터를 바꿔가며 여러 Data Ablation을 돌리는 실무 환경에서 특히 유리합니다. 정리하면 MERIT은 한 번의 가벼운 전처리 비용만 추가로 요구할 뿐, 이후 학습 과정 자체를 복잡하게 만들지는 않습니다. 따라서 GPU 자원이 여러 서버에 흩어져 있거나 클러스터 구성이 제한적인 환경이라면, 충분히 매력적인 방법론이라고 할 수 있습니다.
글을 맺으며
이번 연구가 보여주는 가장 중요한 메시지는, 이질적인 Instruction Mixture를 다룰 때 ‘어떻게 합칠 것인가’만큼 ‘어떻게 나눌 것인가’도 중요하다는 점입니다.
지금까지의 Weight Merging 연구는 주로 동일하거나 유사한 데이터로 학습된 모델을 어떻게 효과적으로 병합할 것인가에 초점을 맞춰 왔습니다. 반면 MERIT은 서로 다른 데이터 Partition으로 학습된 모델들을 대상으로, ‘어떤 분할이 더 나은 병합으로 이어지는지’를 정면으로 다루는데요. 특히 Conflict-aware Split이 병합 이후 모델 성능을 결정하는 중요한 요소임을 이론과 실험 양쪽에서 보여주었습니다.
결국 Instruction Tuning을 하나의 거대한 Mixture를 학습하는 문제로만 볼 것이 아니라, ‘어떤 데이터를 함께 학습시키고 어떤 데이터를 분리할 것인가’의 문제로도 바라볼 수 있습니다. 점점 커지는 Instruction Mixture와 분산된 컴퓨팅 환경을 고려하면, 데이터셋을 어떻게 나눌 것인가는 앞으로 더 중요한 설계 요소가 될 것입니다.
자세한 내용은 논문 전문(Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging)에서 확인하실 수 있습니다.