
독자 비전 인코더 HyperCLOVA X CLIP과 HyperCLOVA X SEED 4B
현대 전장은 드론 영상과 위성사진, 무전 음성, 작전 문서처럼 서로 다른 형태의 정보가 실시간으로 쏟아지고, 이를 신속한 의사결정으로 연결해야 하는 환경으로 빠르게 바뀌고 있습니다. 텍스트와 이미지, 영상 그리고 음성까지 동시에 이해하는 옴니모달 AI가 국방의 핵심 기술로 주목받는 이유죠.
팀네이버는 바로 이러한 환경에 최적화된 경량 옴니모달 언어모델 HyperCLOVA X SEED 4B와 그 기반이 되는 HyperCLOVA X CLIP을 개발했습니다. 올해 초 공개한 HyperCLOVA X 32B Think [1], HyperCLOVA X 8B Omni [2] 이후로도 지속적으로 연구개발을 이어가며, 모델의 ‘눈’과 ‘귀’에 해당하는 핵심 구성 요소를 하나씩 자체 기술로 완성한 결과인데요. 이번 모델에서 주목할 점은 비전 인코더의 가중치 초기화부터 학습까지 전 과정을 독자적으로 수행하고, 비디오 속 오디오 정보까지 함께 이해할 수 있는 오디오 인코더를 직접 개발해 탑재했다는 점입니다.
이러한 기술 독자성은 보안성과 현장성이 동시에 요구되는 국방 영역에서 그 가치가 더욱 분명해집니다. 특히 국방은 데이터 주권과 실시간성이 무엇보다 중요한데요. 외부망과 분리된 폐쇄망에서 그리고 드론이나 무인체계, 전술차량처럼 컴퓨팅 자원이 제한된 환경에서도 안정적으로 동작해야 합니다. 이런 현장일수록 외부 모델에 기대지 않고 우리 기술로 완성한 모델이어야 안심하고 들일 수 있습니다.
이번 글에서는 HyperCLOVA X SEED 4B가 어떻게 자주적인 옴니모달 AI 기술 스택을 쌓아 왔는지, 그리고 그 기술이 까다로운 국방 현장에서 어떤 가능성을 보이는지 차례로 살펴보겠습니다.
옴니모달을 이해하는 AI의 필요성
옴니모달 대형언어모델(Omni-modal LLM)은 이미지를 보고 설명하는 수준을 넘어, 문서와 차트, 영상과 소리까지 하나의 맥락에서 이해하는 방향으로 발전하고 있습니다. 문제는 이때 모델의 ‘눈’과 ‘귀’에 해당하는 인코더가 전체 성능과 활용 가능성을 크게 좌우하는데요.
한국어와 한국 환경을 잘 이해하는 모델을 만들기 위해서는 한국어 텍스트, 한국적 사물과 장소 그리고 이미지 속 한글 OCR까지 안정적으로 다룰 수 있어야 합니다. 또한 공공, 산업, 국방처럼 신뢰성이 중요한 영역에서는 외부 구성 요소에 대한 의존을 줄이고, 모델이 어떤 데이터와 구조로 만들어졌는지 설명할 수 있는 ‘기술 독자성’도 중요합니다.
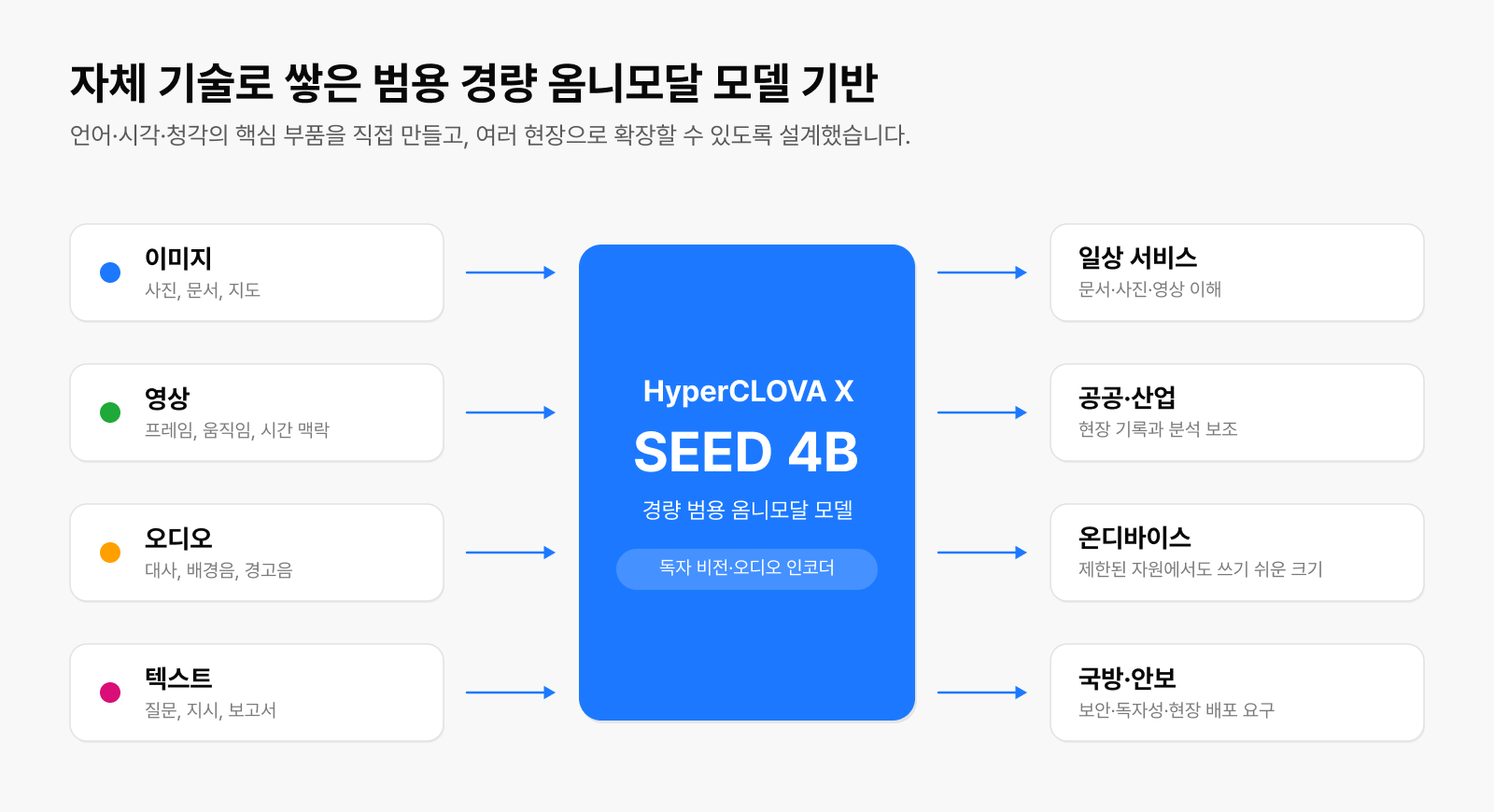
▲ HyperCLOVA X SEED 4B는 독자 인코더를 중심으로 다양한 현장으로 확장되는 경량 범용 옴니모달 모델입니다.
왜 4B인가: 작게 만들어 더 넓게 쓰기 위해
이미 더 큰 모델이 있는 상황에서 4B 모델을 내놓은 이유는 실제 사용 환경에 있습니다. 클라우드 환경에서는 큰 모델을 사용할 수 있지만, 모든 서비스와 현장이 충분한 연산 자원을 갖춘 것은 아닙니다. 스마트폰과 로봇, 제조 현장, CCTV 관제, 공공 및 국방 현장처럼 응답 지연과 장비 제약이 큰 환경에서는 작은 모델이 더 실용적인 선택이 될 수 있습니다.
물론 작다고 해서 성능을 포기할 수는 없습니다. HyperCLOVA X SEED 4B는 4B라는 크기와 고해상도 이미지 처리, 오디오 토큰 압축을 함께 고려했는데요. 목적은 ‘작은 모델’ 자체가 아니라, 현장에서 실제로 쓸 수 있는 ‘효율적인 모델’을 만드는 데 있습니다.

▲ 4B 경량화, Local Windowing, 오디오 토큰 압축을 함께 고려한 효율 설계.
독자 인코더 개발기: 눈과 귀를 만들다
비전 인코더는 모델의 ‘눈‘에 해당합니다. 이미지를 입력 받아 시각적 의미를 추출하고 이를 언어 모델이 이해할 수 있는 표현으로 바꾸는 역할이죠. 오디오 인코더는 모델의 ‘귀‘에 가깝습니다. 비디오 속 대사와 배경음, 효과음 같은 소리를 언어 모델이 이해할 수 있는 토큰으로 바꿔 줍니다.
HyperCLOVA X SEED 4B의 독자 인코더 개발은 크게 다음과 같은 세 단계로 진행되었습니다.
- CLIP Pre-training : 이미지와 텍스트의 관계를 처음부터 학습
- Further Vision Encoder Pre-training : 타겟보다 작은 LLM 을 사용하여 고효율 Vision Encoder – LLM Alignment 수행
- 오디오 인코더 개발 : 비디오 속 소리까지 이해하는 인코더 개발

▲ HyperCLOVA X SEED 4B의 전체 구조. 이미지·비디오·오디오·텍스트를 각각 처리한 뒤
하나의 언어 출력으로 연결합니다.
Stage 1. HyperCLOVA X CLIP: 가중치 초기화
HyperCLOVA X CLIP은 약 637M 파라미터 규모의 비전 인코더로 이미지와 텍스트를 하나의 임베딩 공간에 정렬하도록 학습했습니다. 여기서 가장 중요한 점은 외부 가중치를 전혀 가져오지 않고 모든 파라미터를 랜덤 초기화한 상태에서 출발했다는 것인데요.
일반적으로 비전 인코더는 이미 사전 학습된 모델을 가져와 추가 학습(fine-tuning)하는 방식을 널리 씁니다. 이미 학습된 표현력을 활용하면 빠르게 성능을 확보할 수 있기 때문이죠. 하지만 HyperCLOVA X CLIP은 그러한 외부 모델에 기대지 않고, 비전 인코더의 출발점부터 직접 만드는 길을 택했습니다. 기존 모델을 확장하거나 미세 조정한 것이 아니라 완전히 처음(from-scratch)부터 학습한 것이죠.
학습에는 약 30B seen samples 규모의 한국어·영어 이미지–텍스트 데이터를 활용했습니다. 이 선택은 한국 환경에서의 시각 이해에서 특히 중요한데요. 글로벌 비전 인코더는 영어 중심 데이터로 학습된 경우가 많아, 한국어 OCR이나 한국적 맥락이 담긴 이미지를 이해할 때 한계가 드러날 수 있기 때문입니다.
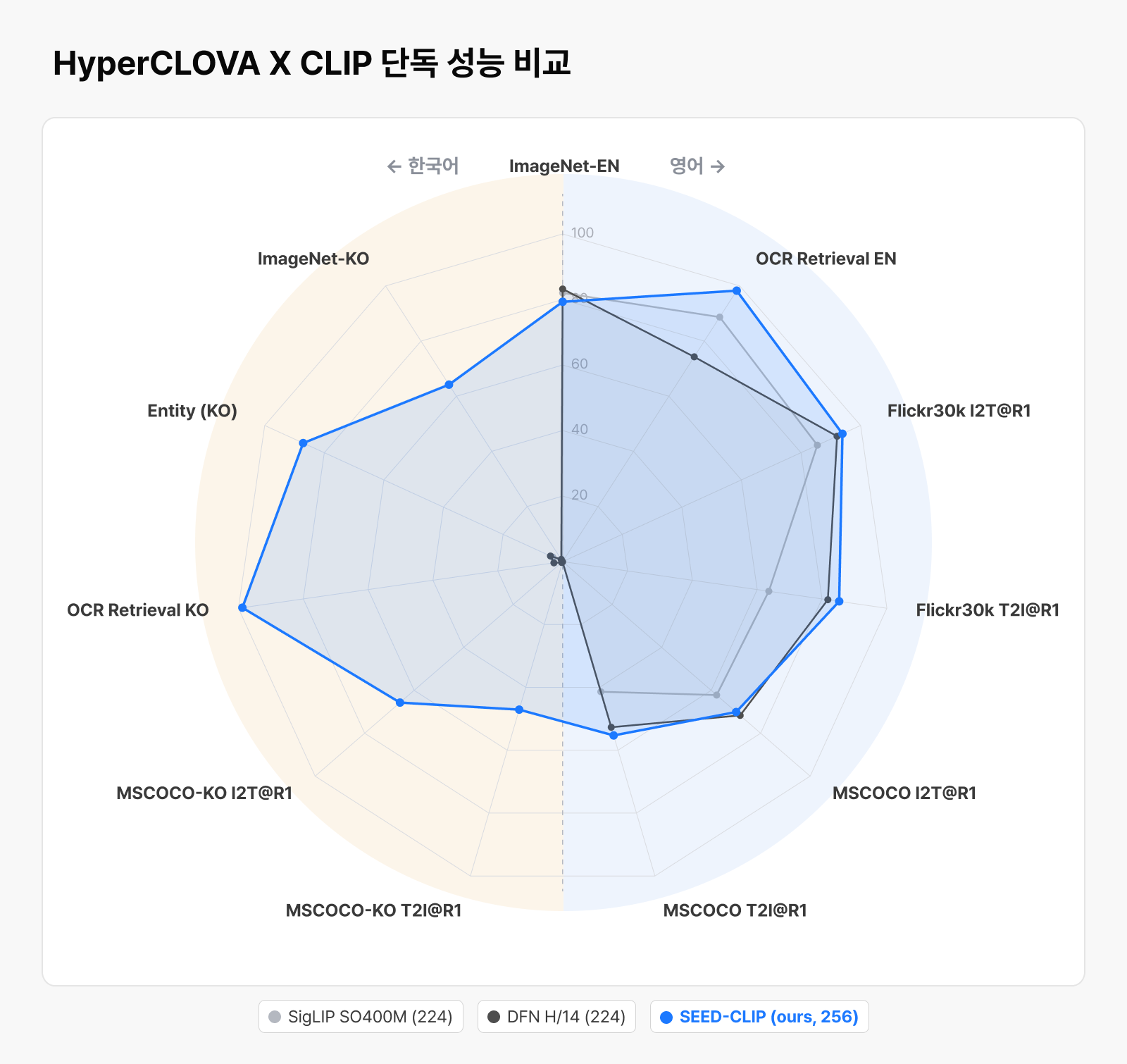
▲ HyperCLOVA X CLIP 단독 성능 비교. 영어 성능을 유지하면서 한국어 벤치마크에서 큰 개선을 보였습니다.
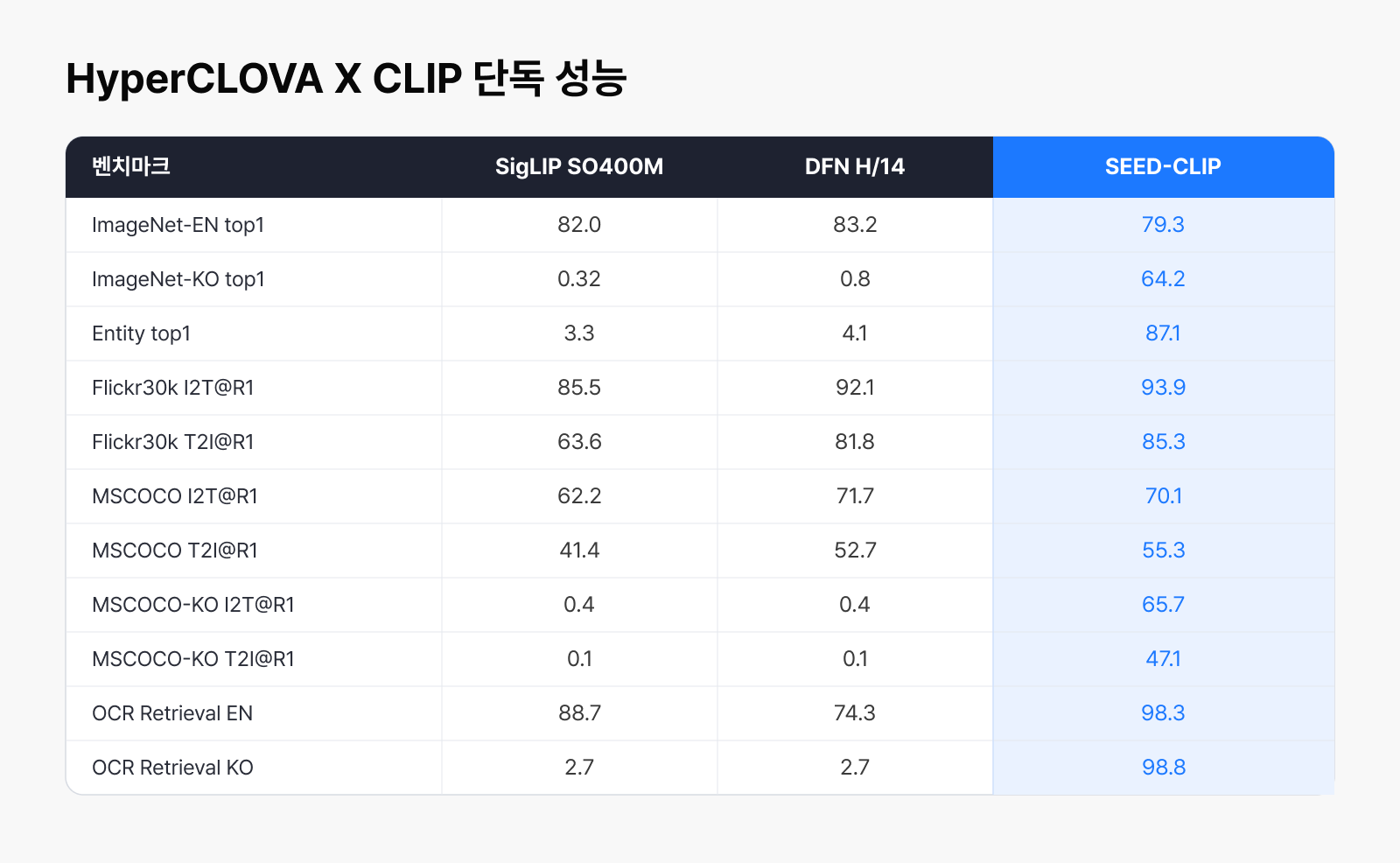
표에서 보듯 SigLIP, DFN과 같은 글로벌 인코더는 영어 중심 데이터로 학습되어 한국어 벤치마크에서 0에 가까운 수치를 보입니다. 영어 중심 데이터로 학습된 탓에 한국어와 한국 환경이 애초에 학습 범위 밖에 있었기 때문이죠. 기존 인코더가 사실상 다루지 못하던 영역인 셈입니다. HyperCLOVA X CLIP은 바로 이 미지원 영역을 새로 채우며, 영어 지표를 유지하면서도 ImageNet-KO, Entity, OCR Retrieval KO, MSCOCO-KO 계열 지표에서 큰 폭의 성능을 확보했는데요. 한국어와 한국 환경에 맞는 시각 표현을 직접 학습한 결과이자, 다양한 한국향 이미지를 이해하는 토대가 됩니다.
- ImageNet-KO : 이미지를 보고 그 대상이 무엇인지 한국어로 정확히 맞추는 능력을 평가
- Entity : 브랜드, 장소, 상품과 같이 한국 환경에서 자주 등장하는 객체를 얼마나 잘 인식하는지를 평가
- OCR Retrieval KO : 이미지 내 한국어 텍스트를 얼마나 정확하게 읽어내는지를 평가
- MSCOCO-KO: 이미지의 내용을 한국어로 얼마나 자연스럽고 정확하게 설명하는지를 평가
Stage 2. 언어모델이 실제로 필요로 하는 눈으로의 고도화
CLIP 사전학습만으로는 옴니모달 언어모델에 바로 적용하기에 부족한 부분이 있습니다. 특히, 사전학습된 비전 인코더는 이미지와 문장의 전반적인 의미를 맞추는 데에는 강합니다. 하지만 이미지 속 작은 글자를 읽거나 장면의 세부 요소를 빠짐없이 설명하는 능력은 추가 학습이 필요합니다.
그래서 비전 인코더를 단독으로만 학습하지 않고 임시로 경량 언어 모델과 연결해 비전언어모델 구조로 한 번 더 학습했습니다. 학습이 끝나면 이 과정에 사용한 언어 모델은 제거하고, 성능이 향상된 비전 인코더만 최종 모델에 탑재합니다. 쉽게 말해 비전 인코더를 더 잘 가르치기 위해 언어 모델을 ‘임시 교사’처럼 활용한 셈입니다. 이 과정에서 비전 인코더는 ‘언어 모델이 실제로 원하는 시각 정보가 무엇인지’를 자연스럽게 배우게 됩니다.
(이 과정에 도입된 더 자세한 기술 내용은 저희 연구결과 [3] 에서 찾아보실 수 있습니다.)
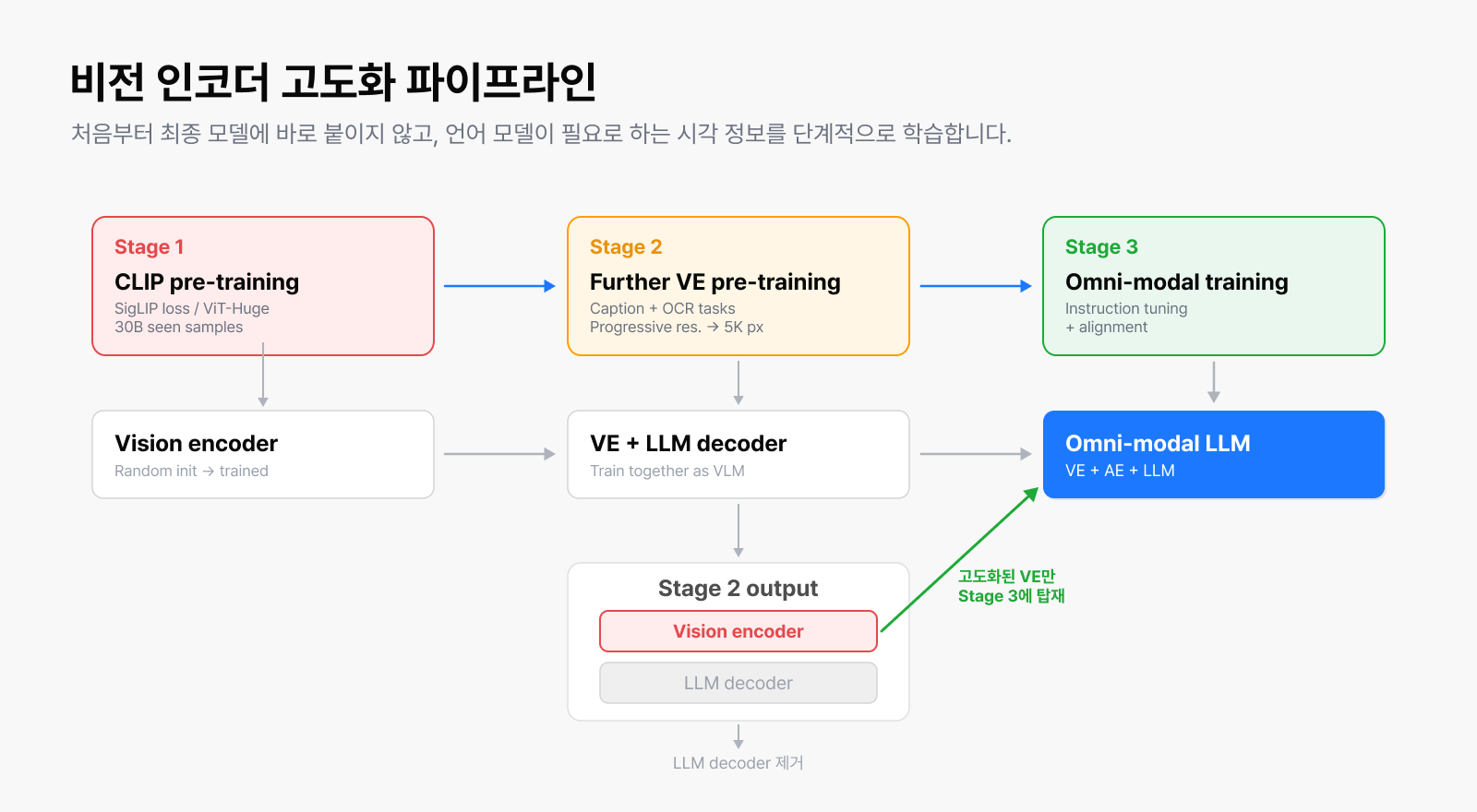
▲ 비전 인코더 학습 파이프라인. Stage 2에서 비전 인코더와 언어 모델을 함께 학습한 뒤
고도화된 비전 인코더만 최종 모델에 탑재합니다.
고해상도 이미지 처리를 위해서는 Progressive Resolution과 Local Windowing을 함께 적용했습니다. 처음부터 고해상도로 학습하면 비용이 크고 학습이 불안정해질 수 있어 낮은 해상도에서 기본 표현을 먼저 학습한 뒤 점진적으로 해상도를 높였습니다. 또한 모든 패치 간 관계를 한 번에 계산하는 대신 이미지를 작은 윈도우 단위로 나누어 각 윈도우 내부에서 먼저 어텐션을 수행하도록 했습니다.
Stage 3. 비디오 속 소리까지 이해하다 – 독자 오디오 인코더
많은 Video-LLM은 비디오를 이해한다고 말하지만 실제로는 오디오를 제외한 프레임만 처리하는 경우가 많습니다. 하지만 사용자는 영상을 보며 사람의 말과 배경음, 경고음까지 함께 묻곤 합니다. 그렇기 때문에 프레임만 봐서는 ‘이 영상에서 무슨 말이 나왔는지’에 답할 수 없습니다. HyperCLOVA X SEED 4B는 비디오 속 오디오 정보를 함께 다루기 위해 자체 오디오 인코더를 탑재했습니다.
- 학습 방식: CTC Loss (시간 정렬 정보 없이도 음성과 텍스트를 매칭해 학습할 수 있는 방법)
- 사용 데이터: LibriSpeech, Zeroth Korean 데이터셋으로 구성된 약 1,000시간 분량의 ASR 데이터
이렇게 학습한 오디오 인코더를 언어 모델에 통합하는 과정은 저희 선행 연구 [4]를 바탕으로 개발했습니다. 먼저 10Hz 단위로 오디오 특징을 추출한 뒤, average pooling을 적용해 2Hz까지 압축하는데요. 1분짜리 오디오를 기준으로 약 600개의 토큰을 약 120개로 줄이는 셈입니다. 덕분에 긴 비디오의 오디오 트랙도 언어 모델에 부담 없는 길이로 입력할 수 있게 되었습니다.
HyperCLOVA X SEED 4B의 학습 파이프라인
옴니모달 학습은 텍스트 사전학습을 마친 기반 모델 위에서 시작합니다. HyperCLOVA X SEED 4B의 LLM 디코더는 자체 개발한 언어 모델을 기반으로 하는데요. 텍스트 이해·생성 능력이 충분히 확보된 상태에서 옴니모달 파이프라인에 진입합니다. 전체 파이프라인은 Omni-modal Pre-Training → Omni-modal SFT → Long Chain-of-Thought & Video SFT → Omni-modal RLVR 순으로 이어집니다.
Omni-modal Pre-Training
이미지 정보를 언어 모델이 이해할 수 있는 형태로 연결하고, 비전-언어 모델의 기초 시각 이해 능력을 확보하는 단계입니다. 대규모 환경에서 높은 throughput을 확보하는 데 강점이 있어, 많은 양의 시각-언어 데이터를 안정적으로 학습시키는 데 적합한 Megatron Bridge를 활용했는데요. 먼저 alignment 단계에서 projector를 중심으로 이미지·언어 표현을 정렬한 뒤 full fine-tuning 단계에서 전체 파라미터를 학습했습니다.
이 과정에서 약 200M samples를 학습하며 도형 이해와 이미지 내 OCR, 개체를 식별하고 연결하는 entity 인식, 시각 정보와 지식의 결합 등 비전-언어 모델의 기반 역량을 폭넓게 익혔습니다. loss 그래프에서 보듯 학습은 안정적으로 진행되어 이후 고도화 단계의 탄탄한 기반이 되었습니다.
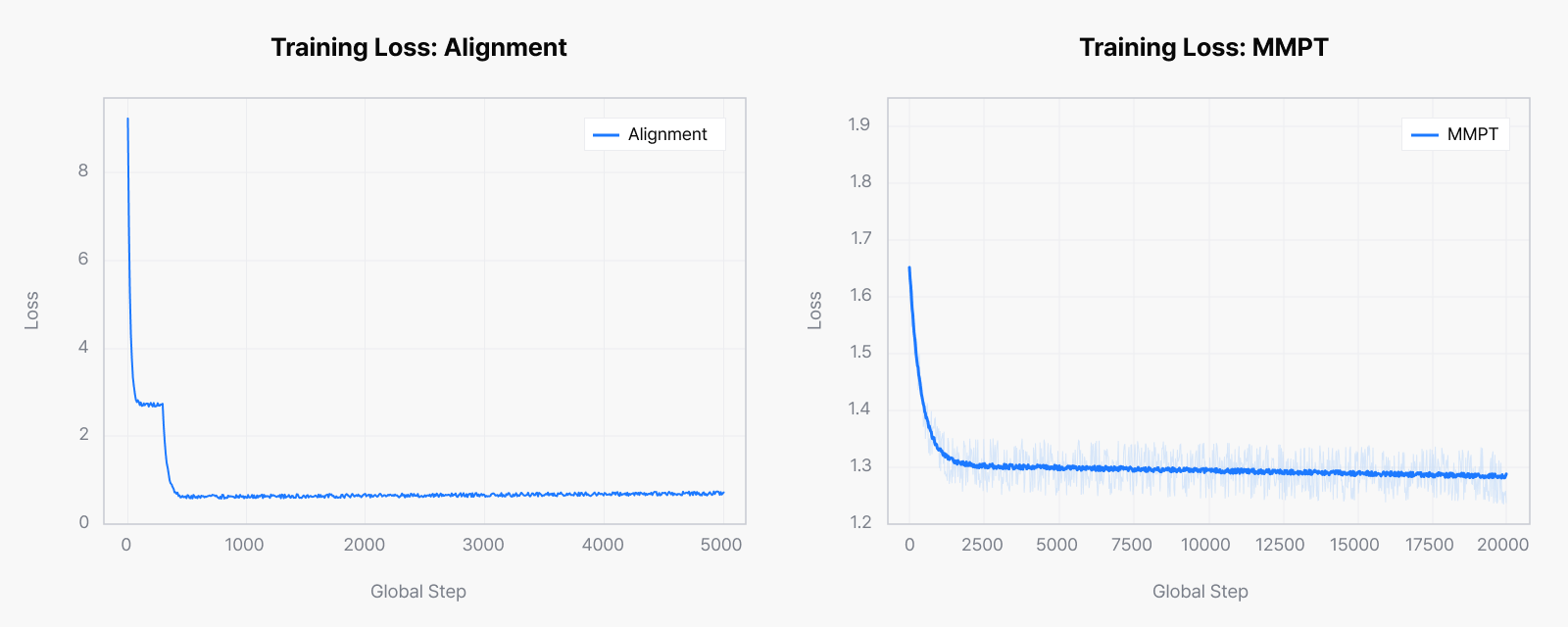
Omni-modal SFT
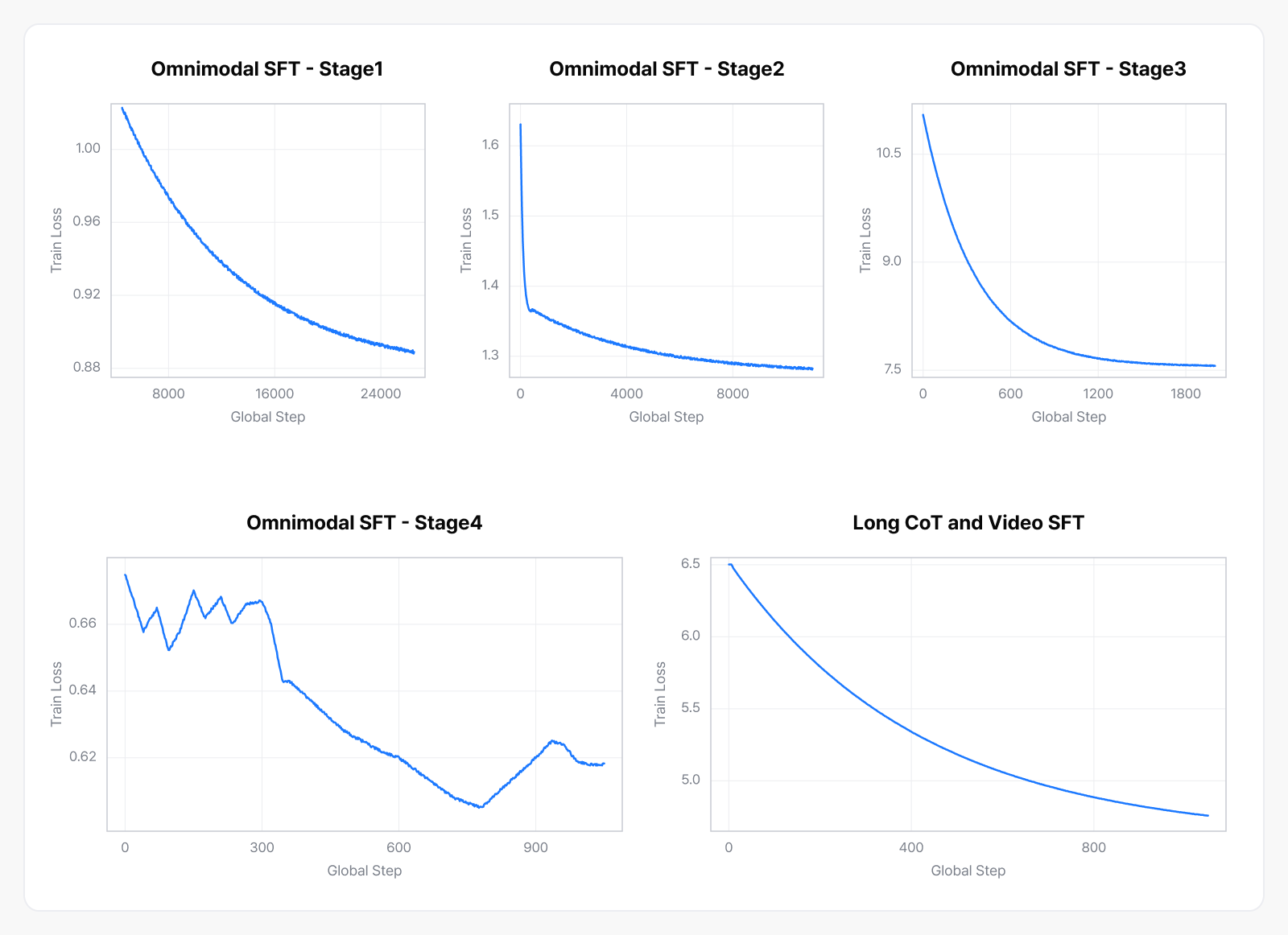
Omni-modal Pre-Training 에서 확보한 기초 시각 이해를 바탕으로 이번에는 사용자 질문에 정확히 답하는 instruction following 능력을 학습합니다. 캡셔닝 수준을 넘어 “이 차트에서 가장 높은 항목은?” 같은 구체적 지시를 이해하고 따라야 하는 단계죠. 이를 위해 옴니모달 데이터 비중을 단계적으로 높이고, 학습 목적별 phase를 5단계로 구분하는 curriculum learning 기법을 적용했습니다.
먼저 텍스트 instruction tuning 비중을 약 95%로 두어, 아직 instruction following에 익숙하지 않은 모델이 ‘지시를 이해하고 따르는 법’을 텍스트로 먼저 익히게 했습니다. 이어 옴니모달 비중을 약 75%로 높여 대량의 detailed captioning을 학습했는데요. 이미지 속 작은 텍스트와 배경 요소, 객체 간 관계까지 놓치지 않는 단계로, Omni-modal Pre-Training이 ‘넓게 보는 눈’이라면 이 과정은 ‘꼼꼼히 읽는 눈’을 만드는 셈입니다. 마지막으로 옴니모달 비중을 약 85%로 끌어올려 질의응답·문서 이해·차트 해석·비디오 요약 등 실제 시나리오를 아우르는 본격 instruction tuning을 수행했습니다. 이때 특정 태스크에 편향되면 다른 능력이 퇴화하기 때문에 태스크 비율을 지속적으로 조정하며 균형을 맞췄습니다.
학습 프레임워크: 유연함을 위한 선택
SFT부터는 프레임워크를 전환했습니다. Omni-modal Pre-Training에서는 높은 throughput이 핵심이라 Megatron Bridge를 썼지만, SFT부터는 이미지·비디오·오디오가 섞인 데이터를 다루고 데이터 구성·비율을 단계마다 빠르게 바꿔야 했기 때문인데요. 이에 Hugging Face Seq2SeqTrainer를 베이스로 옴니모달 학습에 필요한 기능을 직접 구현해 올렸습니다. HSDP(Hybrid Sharded Data Parallel)로 학습 속도를 높이고, 가변 길이 데이터를 효율적으로 학습하기 위한 dynamic batching, 대량의 비디오 학습을 위한 pre-load 파이프라인 등이 대표적입니다.
특히 데이터를 미리 고정된 형태로 변환해두지 않고 학습 시점에 원본을 직접 로딩·전처리하는 on-the-fly 방식이 핵심 설계였습니다. 덕분에 구성이나 비율을 바꿀 때 전처리를 다시 할 필요 없이 설정만 바꿔 곧바로 새 조합으로 학습할 수 있었고, ablation을 빠르게 반복해야 하는 SFT 단계에서 개발 속도에 큰 차이를 만들었습니다. 또한 샘플마다 이미지 수와 해상도가 달라 토큰 길이 편차가 큰데요. 스텝당 토큰 총량은 일정하게 유지하면서 배치 내 샘플 수를 동적으로 조절하는 dynamic batching으로 GPU 활용률과 학습 안정성을 함께 확보했습니다.
Long Chain-of-Thought & Video SFT
Omni-modal SFT까지 거치며 모델은 다양한 시각 태스크를 수행할 수 있게 되었습니다. 다만 복잡한 문제에서는 답을 바로 내기보다 내재적 사고 과정을 거친 뒤 응답하는 방식이 훨씬 효과적인데요. 이를 thinking mode라고 합니다.
Thinking mode와 Chain-of-Thought
Thinking mode의 핵심은 Chain-of-Thought(CoT)입니다. 답을 내기 전 사람처럼 사고 흐름을 단계적으로 전개하는 것이죠. 예를 들어 차트 수치를 비교한다면 “A는 35, B는 28이니 A가 7 높다”처럼 관찰 → 비교 → 결론을 명시적으로 거칩니다. 이런 단계적 추론은 수학, 차트 해석, 다이어그램 분석처럼 여러 단계의 판단이 필요한 태스크에서 특히 효과적입니다. 이를 학습시키기 위해 thinking process가 명시적으로 annotation된 고품질 데이터를 구축해, 모델이 관찰부터 결론까지의 전체 사고 과정을 학습하도록 했습니다.
비디오 학습: 데이터 설계와 엔지니어링
비디오는 학습 효율을 위해 길이 분포를 세심하게 통제했습니다. 짧은 영상 위주로 효율을 확보하되 약 15분 길이의 영상도 일정 비율 포함해 장시간 이해력을 함께 확보했고, 오디오까지 고려한 데이터를 넣어 시각·청각을 함께 쓰는 추론도 학습했습니다. 학습 환경은 Omni-modal SFT와 동일하지만, 비디오는 프레임 디코딩·오디오 추출·시간 정렬 등 전처리가 복잡하고 크기도 커서 별도의 엔지니어링이 필요했는데요. dynamic batching에서 다음 배치 비디오를 제때 준비하지 못하면 GPU가 노는 문제가 생기기 때문에, 비디오를 미리 pre-load하는 파이프라인을 설계·최적화해 길이 편차가 큰 상황에서도 GPU 활용률을 안정적으로 유지했습니다.
Omni-modal RLVR for Reasoning
RLVR 단계는 단순 시각 이해를 넘어 문제 해결·추론 능력을 실제로 활용하도록 확장하는 데 초점을 뒀습니다. 특히 문제 풀이, 차트 해석, 시각 기반 계산 같은 verifiable task 중심으로 추론을 강화했는데요. 학습은 vLLM·FSDP 기반 verl 프레임워크로 진행했습니다. 대규모 샘플 생성과 분산 학습을 동시에 수행할 수 있어 RLVR에 필요한 throughput과 rollout–update 사이클에 잘 맞기 때문입니다.
알고리즘은 GRPO 기반 DAPO를 적용했습니다. 그룹 내 샘플이 전부 정답이거나 전부 오답인 prompt는 유효한 gradient signal이 없어 제외했고, 비대칭 클리핑으로 안정성과 데이터 다양성을 높였습니다. 데이터는 옴니모달과 텍스트 전용을 1:1로 유지해 시각 정보 과의존이나 언어 추론 약화를 막고 두 modality의 추론을 균형 있게 키웠습니다. Reward는 정답 검증이 가능한 verifier로 정확성을 직접 반영하고, 여기에 format·language reward를 더해 정답을 넘어 질문의 형태와 요구에 맞는 응답을 유도했습니다.
또한 약 10만 개 prompt에 각 8회 rollout으로 80만 개 이상의 trajectory를 생성하고, filtering으로 선별한 샘플로 학습했습니다. 이를 통해 시각 기반 계산, 구조적 문제 해결, 옴니모달 추론 전반의 능력이 점진적으로 향상되었습니다. 학습은 단일 구간이 아니라 단계적으로 진행했으며, 중반부부터는 한국어 추론·표현 능력을 강화하기 위해 데이터 구성을 한국어 중심으로 재조정하고 language reward의 비중을 함께 높였습니다. 이 과정에서 학습 신호의 분포가 단계별로 달라지며, accuracy reward와 response length 곡선에서도 각 단계의 전환점이 구간으로 드러납니다. 전반적으로는 단계가 바뀌어도 정확도와 추론 길이가 꾸준하게 상승해, 추론 능력이 안정적으로 누적됨을 확인할 수 있습니다.
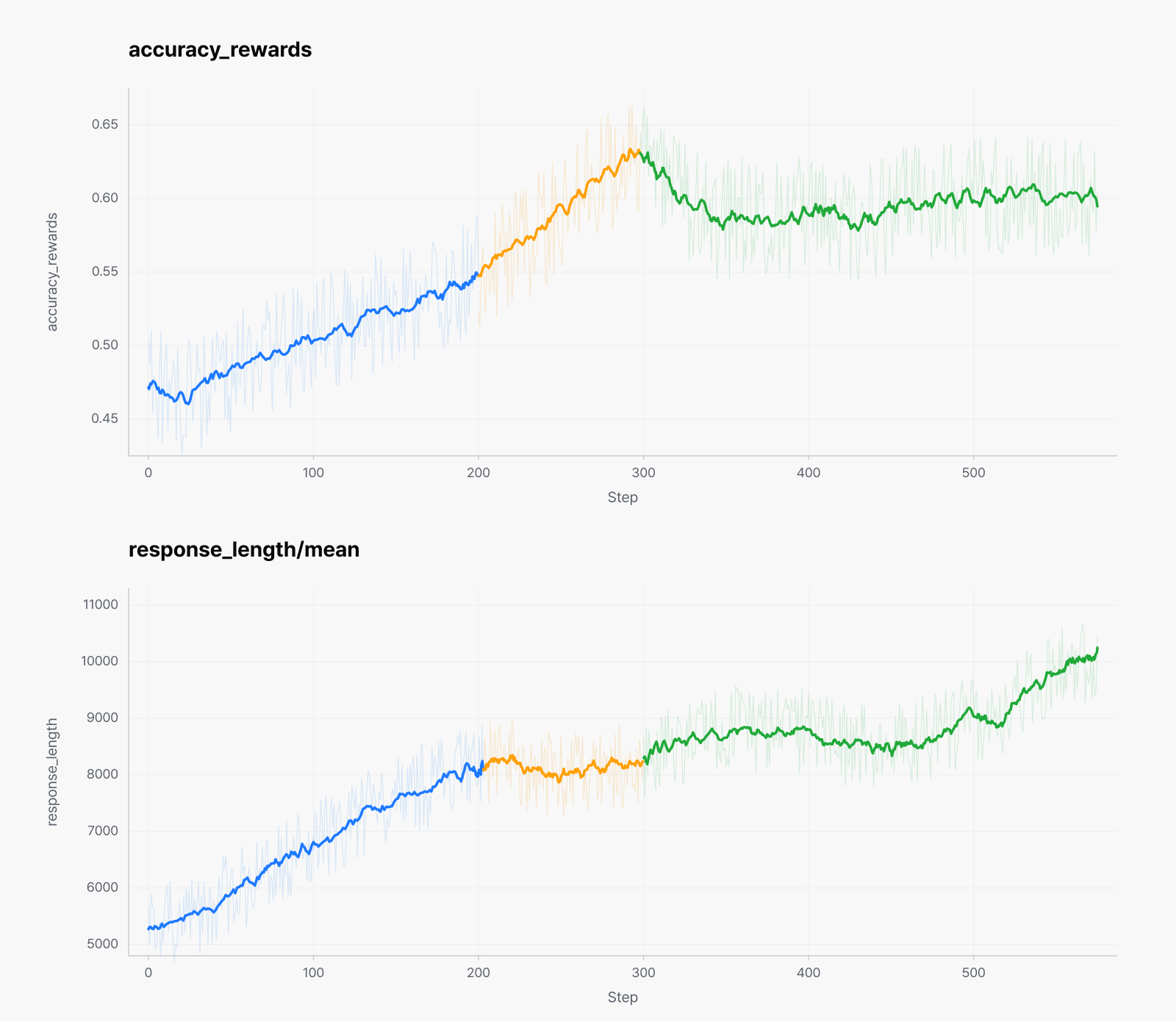
절반 크기로, 더 잘 보는 HyperCLOVA X SEED 4B
그렇다면 이렇게 학습한 모델은 실제로 어느 정도의 성능을 낼까요? 결국 자체 개발한 인코더가 실제 모델 성능으로 이어지는지가 관건인데요. HyperCLOVA X SEED 4B는 파라미터 수가 절반 수준임에도 기존 HyperCLOVA X SEED 8B Omni [2] 대비 여러 이미지·문서·비디오 이해 벤치마크에서 개선을 보였습니다.
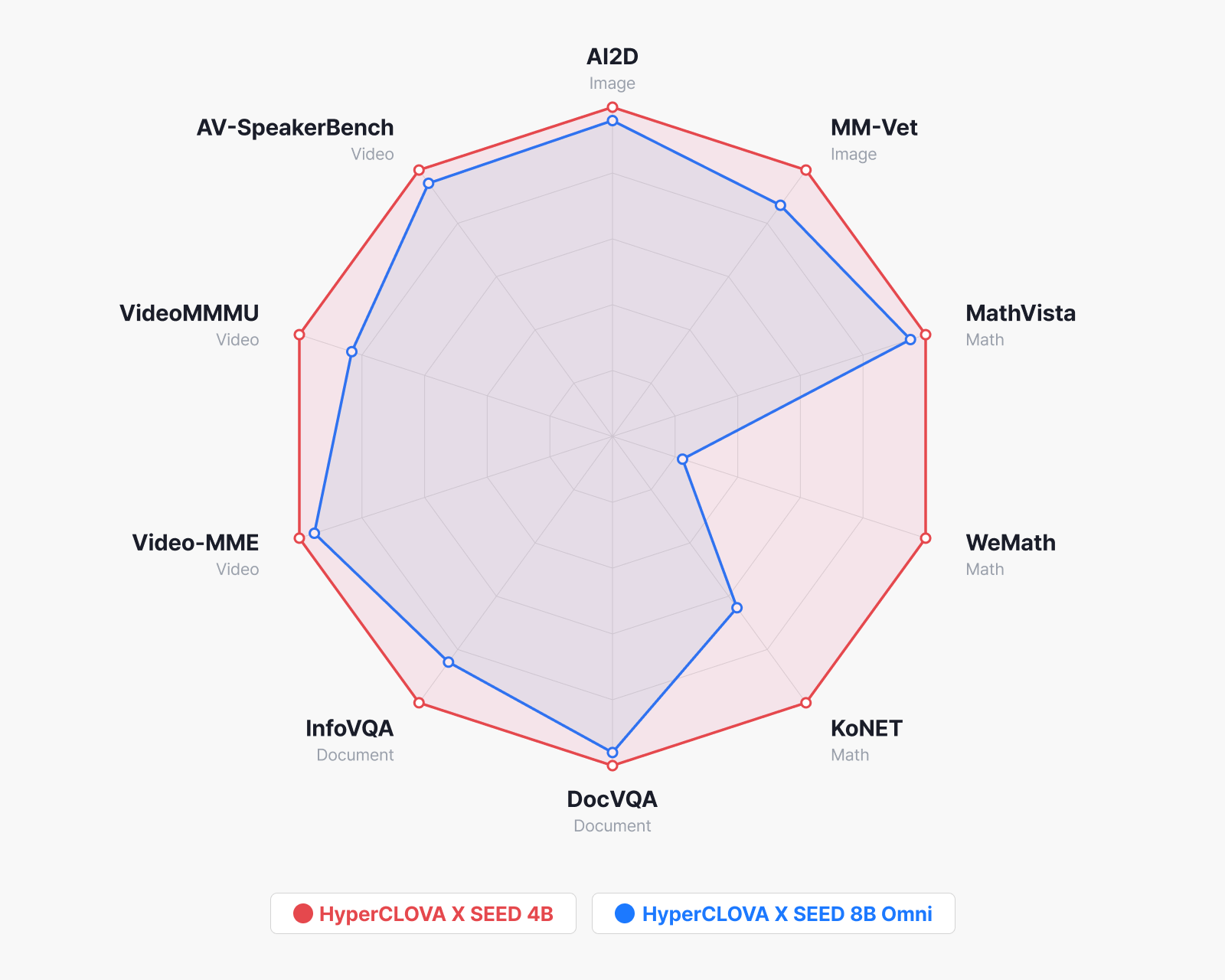
▲ 벤치마크 비교
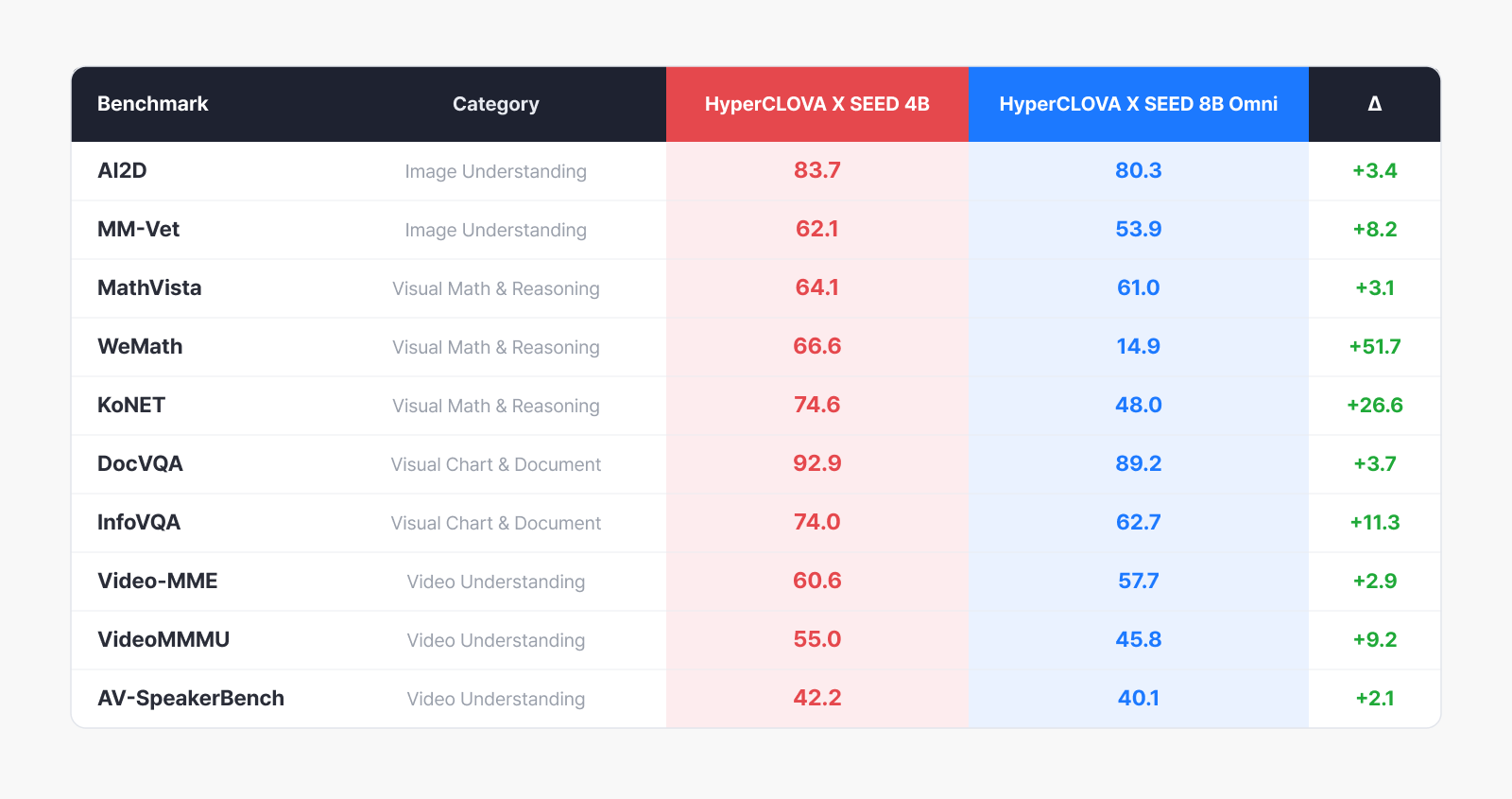 결과부터 보면, 이번 SEED 4B가 벤치마크 전체에서 HCX 8B Omni를 앞섰습니다. 파라미터 수가 절반인 모델이 단 하나의 예외도 없이 앞선 것이죠. 격차가 가장 두드러진 영역은 수학·추론입니다. 시각 정보를 기반으로 수학 문제를 풀어야 하는 WeMath에서는 +51.7, 한국어 수능 수준의 문제 풀이를 평가하는 KoNET에서는 +26.6의 차이를 보였는데요. 앞서 소개한 Long CoT 학습과 RLVR을 통해 모델이 단계적 추론 능력을 효과적으로 습득했음을 보여주는 결과입니다.
결과부터 보면, 이번 SEED 4B가 벤치마크 전체에서 HCX 8B Omni를 앞섰습니다. 파라미터 수가 절반인 모델이 단 하나의 예외도 없이 앞선 것이죠. 격차가 가장 두드러진 영역은 수학·추론입니다. 시각 정보를 기반으로 수학 문제를 풀어야 하는 WeMath에서는 +51.7, 한국어 수능 수준의 문제 풀이를 평가하는 KoNET에서는 +26.6의 차이를 보였는데요. 앞서 소개한 Long CoT 학습과 RLVR을 통해 모델이 단계적 추론 능력을 효과적으로 습득했음을 보여주는 결과입니다.
이미지 이해 영역에서도 AI2D(+3.4)와 MM-Vet(+8.2) 등에서 고르게 앞섰고, 문서·차트 이해를 평가하는 DocVQA(+3.7)와 InfoVQA(+11.3)에서도 4B 모델이 더 높은 성능을 기록했습니다. 이전 세대에서는 문서 속 밀집된 텍스트를 처리할 때 더 큰 언어 모델이 유리했지만, 자체 비전 인코더의 텍스트 추출 능력이 강화되면서 이 격차가 역전된 것으로 보입니다.
비디오 이해 벤치마크에서도 Video-MME(+2.9)와 VideoMMMU(+9.2), AV-SpeakerBench(+2.1) 전반에 걸쳐 개선이 확인되었습니다. 특히 AV-SpeakerBench는 비디오 속 speech 정보를 함께 고려해야 하는 벤치마크인데요. 자체 오디오 인코더가 시각 정보와 더불어 실질적으로 기여하고 있음을 보여주는 지표입니다.
그리고 이 결과에서 무엇보다 중요한 점은 이 모든 성능이 외부 인코더 없이 자체 개발 모듈만으로 달성되었다는 사실입니다.
HyperCLOVA X SEED 4B 종합 성능
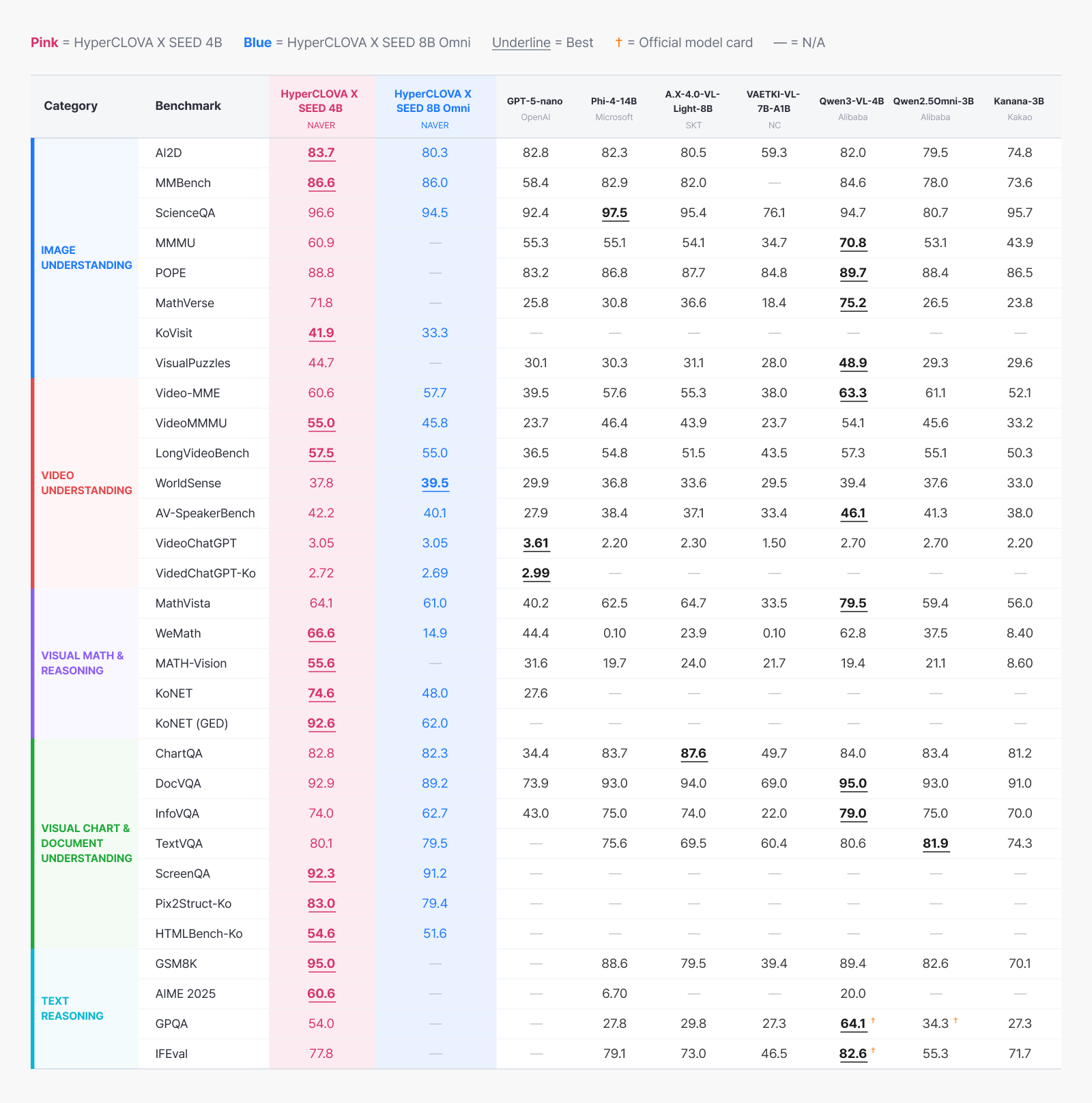
▲ 종합 벤치마크 비교. 내재화 비전/오디오 인코더를 탑재한 HyperCLOVA X SEED 4B가
전반적으로 균형잡힌 우수한 성능을 보입니다.
앞서 자체 8B 모델로 독자 인코더의 효과를 확인했다면, 이번에는 글로벌 모델들과 비교해 HyperCLOVA X SEED 4B의 경쟁력을 살펴보겠습니다. 비교 대상은 OpenAI GPT-5-nano, Microsoft Phi-4-14B, SKT A.X-4.0-VL-Light-8B, Alibaba Qwen3-VL-4B, Kakao Kanana-3B 등입니다.
가장 두드러지는 건 수학·추론입니다. 시각 기반 수학 문제인 WeMath에서 66.6으로 동급 Qwen3-VL-4B(62.8)와 14B Phi-4(0.10)를 모두 앞섰고, MATH-Vision도 55.6으로 비교 대상 가운데 가장 높았는데요. Long CoT와 RLVR로 확보한 단계적 추론이 수치로 이어진 결과입니다.
한국어에서는 격차가 더 뚜렷합니다. 수능 수준 KoNET에서 74.6, 검정고시 수준 KoNET(GED)에서 92.6을 기록했는데, 대부분의 글로벌 모델은 이 문제들에 제대로 대응조차 못합니다. Pix2Struct-Ko(83.0), HTMLBench-Ko(54.6), VideoChatGPT-Ko(2.72) 같은 한국어 문서·비디오 벤치마크도 마찬가지죠. 자체 비전 인코더를 한국어 데이터로 처음부터 학습한 덕분에 한국 환경 특화 능력이 자연스럽게 확보된 것입니다.
문서·차트 이해에서도 경쟁력이 분명합니다. DocVQA 92.9, InfoVQA 74.0, ScreenQA 92.3으로 4B 규모 최상위권이며, DocVQA·ScreenQA는 Qwen3-VL-4B(각각 95.0, —)와 비교해도 근접한 수준이죠.
이미지 이해는 AI2D(83.7), ScienceQA(96.6), POPE(88.8)에서 동급·상위 규모 모델과 대등하거나 앞섰습니다. 비디오에서도 Video-MME(60.6), VideoMMMU(55.0), LongVideoBench(57.5)로 고른 성능을 보였고, 특히 AV-SpeakerBench(42.2)는 Qwen3-VL-4B(46.1) 다음으로 높아 자체 오디오 인코더의 기여를 다시 확인할 수 있었습니다.
텍스트 추론도 눈여겨볼 만합니다. 비전-언어 모델이지만 GSM8K(95.0), AIME 2025(60.6), GPQA(54.0), IFEval(77.8) 등 순수 텍스트 벤치마크에서도 높은 성능을 유지하고 있는데요. 옴니모달 학습에서 텍스트 능력이 훼손되지 않도록 데이터 비율을 관리하고, 특히 RLVR에서 옴니모달과 텍스트를 1:1로 학습한 전략이 효과를 본 것으로 보입니다.
기술이 현장으로 향할 때: 국방에서 드러나는 까다로운 요구
여기까지는 HyperCLOVA X SEED 4B를 ‘어떻게 만들었는지’에 대한 이야기였습니다. 이제 이 기술이 ‘왜 중요한지’를 하나의 현장으로 옮겨 보겠습니다. 최근 공공·국방 영역에서는 보안성과 현장 배포 가능성, 옴니모달 상황 이해가 동시에 요구됩니다. 그렇기 때문에 국방은 독자 Omni-modal Model이 왜 필요한지를 설명하기에 가장 좋은 응용 현장입니다.
국방 현장에서는 이미지, 영상, 음성, 문서가 따로 존재하지 않습니다. 드론 영상과 위성사진, CCTV, 장비 사진, 전술 지도, 상황 보고가 한꺼번에 쏟아지죠. 사람이 모든 정보를 실시간으로 확인하기 어려운 환경에서 Omni-modal Model은 관심 지점 후보를 빠르게 선별하고, 모델이 본 내용을 자연어로 설명하며 후속 분석을 위한 초안을 제공할 수 있습니다.
▲ 국방 사례로 본 Omni-modal Model 활용 가능성.
객체 grounding, 변화 탐지, 장비 점검, 감시 영상 요약처럼 옴니모달 이해가 필요한 과제를 다룹니다.
아래 데모는 한국군사과학기술학회 발표자료에 포함된 시연 화면을 공개 블로그 형식으로 재구성한 것입니다. 긴 중간 reasoning은 덜어내고, 슬라이드에서 확인할 수 있는 최종 답변과 모델 출력 형식을 중심으로 정리했습니다.
국방 응용 데모: 모델은 어떻게 답할까
예시 1. 드론 뷰 객체 Grounding
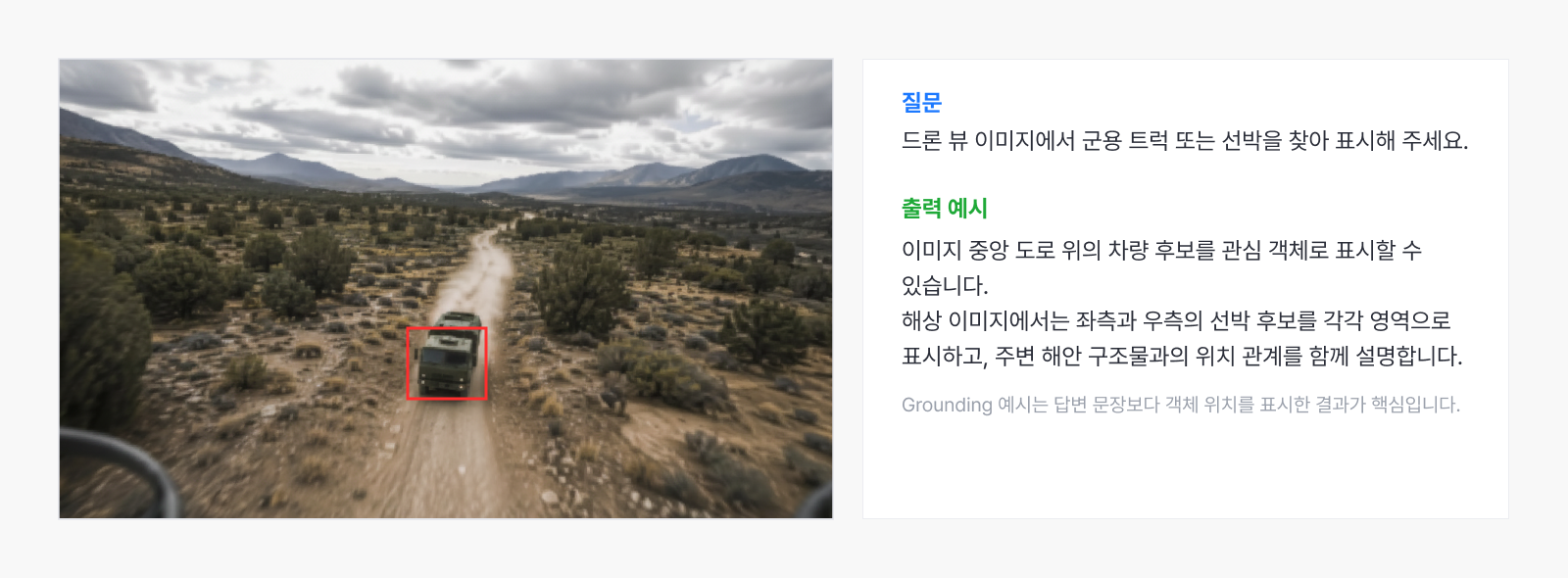
▲ 드론 뷰 이미지에서 관심 객체를 영역으로 표시하는 예시
예시 2. 위성사진 변화 탐지
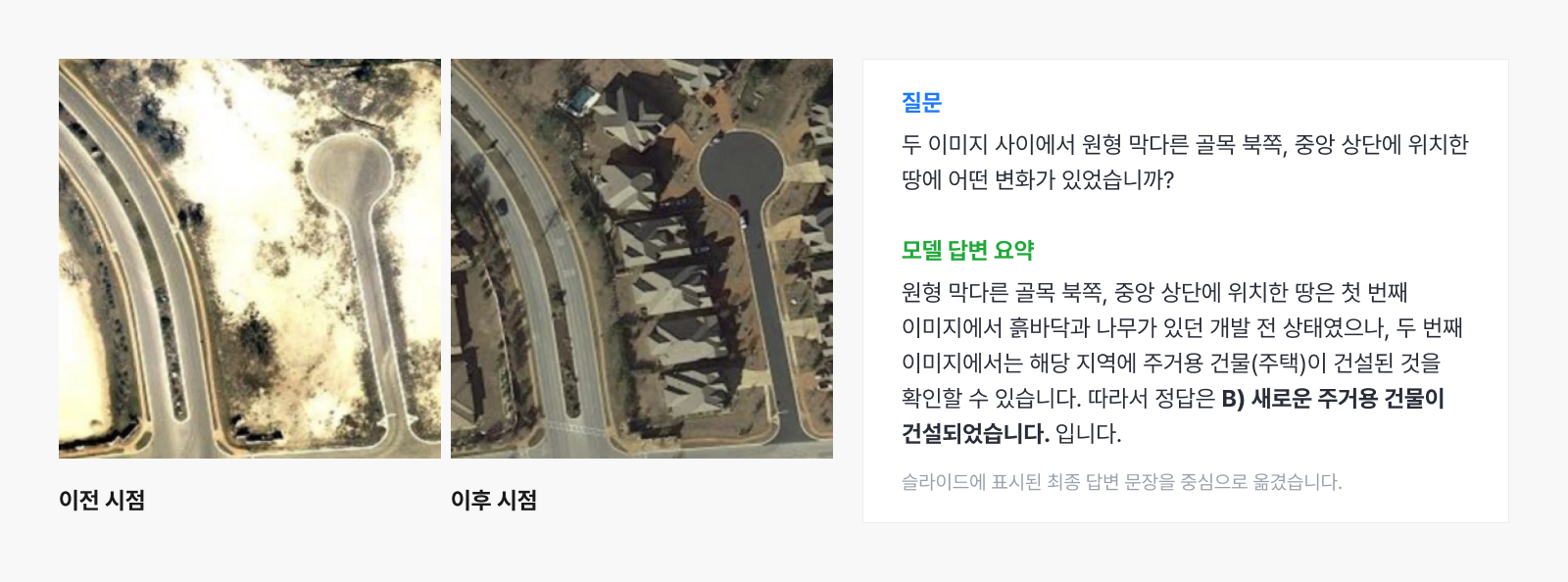
▲ 두 시점의 위성사진을 비교해 변화 유형과 판단 근거를 설명하는 예시
예시 3. 전쟁 시나리오 분석
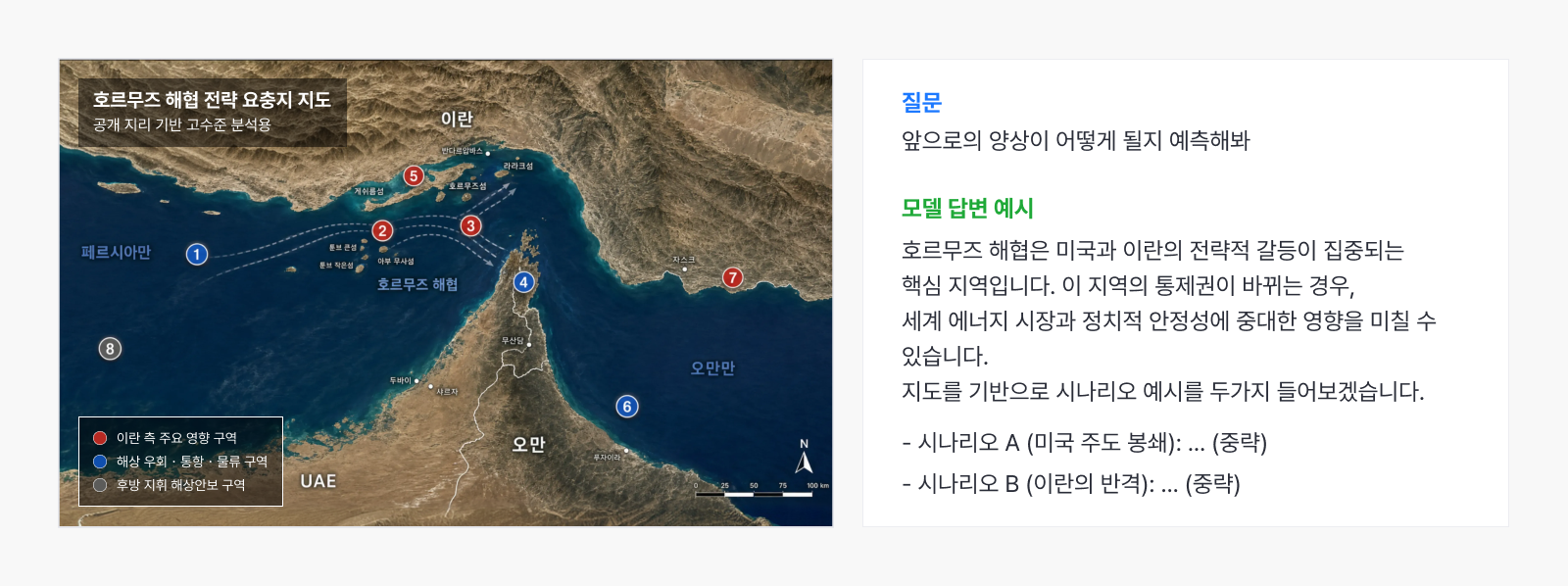
▲ 요충지 지도를 보고 시나리오를 분석하는 예시
예시 4. 생활관, 사격장 위험요소 판단
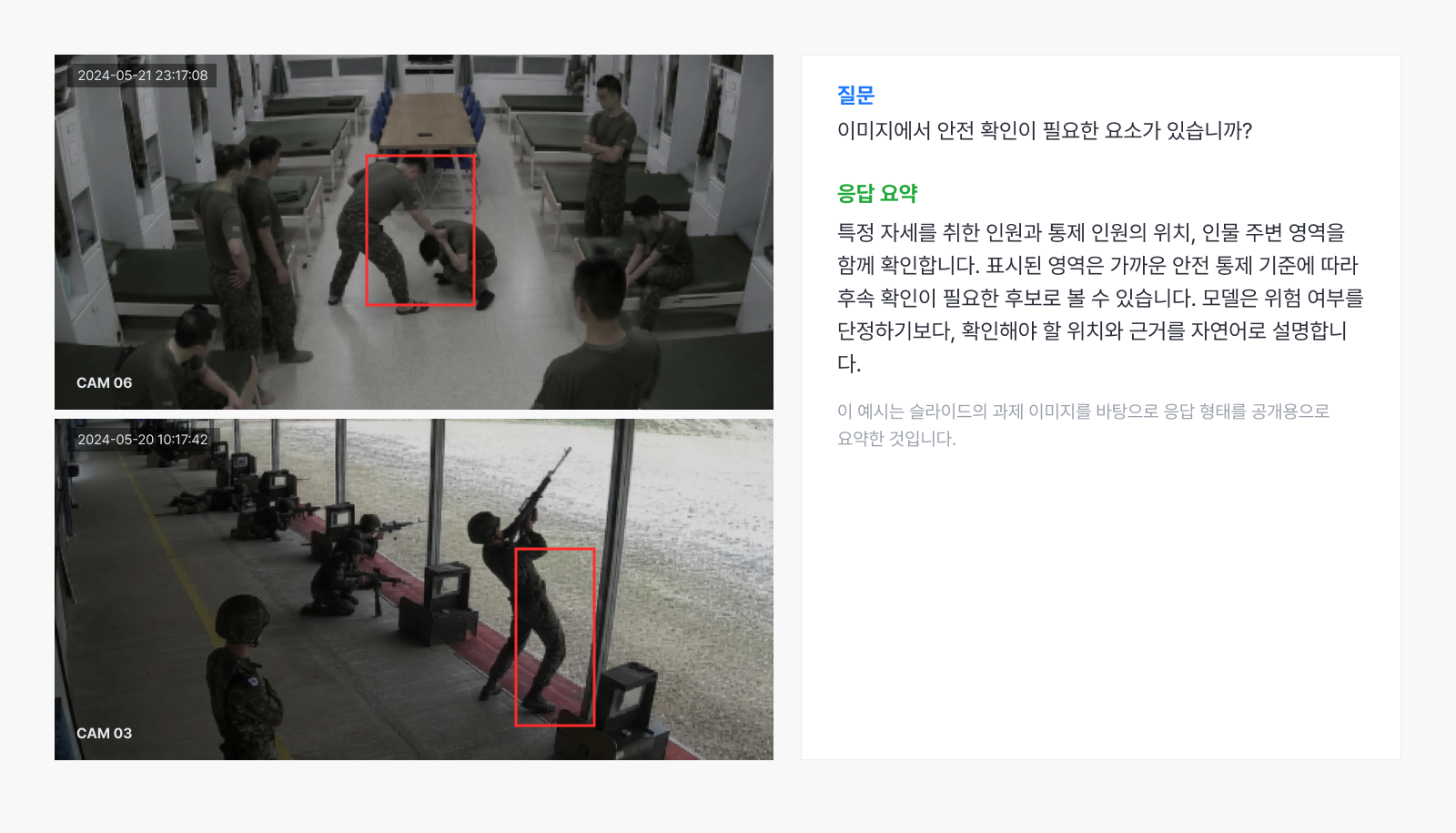
▲ 훈련장 이미지에서 후속 확인이 필요한 위험 후보를 설명하는 예시
예시 5. 군용 장비 인식과 비교 설명

▲군용 장비의 외형적 특징을 비교하고 표로 정리하는 예시
예시 6. 감시 영상 이상 징후 요약

▲ 감시 이미지에서 이상 징후 후보와 후속 확인 포인트를 정리하는 예시
이 시나리오들은 국방 영역에만 머물지 않습니다. 넓은 장면에서 관심 지점을 찾고, 두 시점의 변화를 비교하고, 장비 상태를 구조화해 설명하고, 긴 영상을 요약하는 능력은 공공 안전, 제조, 물류, 재난 대응 등으로도 얼마든지 확장될 수 있습니다. 저희가 국방 사례를 함께 소개하는 이유도 여기에 있습니다. 기술 독자성, 한국어와 한국 환경 이해, 제한된 자원에서의 효율 추론, 그리고 사람이 검토 가능한 설명 능력이 모두 요구되는 현장이기 때문입니다.
모델을 넘어, 데이터와 평가까지 내재화하다
자주적인 모델 개발에서 아키텍처는 절반의 이야기일 뿐입니다. 어떤 데이터를 어떻게 수집하고 정제했는지, 또 어떤 기준으로 모델을 평가했고 새 버전이 이전 버전보다 실제로 나아졌는지까지, 그 과정 전체가 체계적으로 관리되어야 하죠. 그래서 저희는 데이터 수집부터 학습과 버전 관리, 평가에 이르는 모델 개발의 전 주기를 직접 다룰 수 있는 체계를 갖춰 왔습니다.
특히 국방처럼 공개 데이터가 많지 않은 도메인에서는, 합성 데이터로 모델을 학습시키는 것이 현실적인 대안입니다. 그래서 저희는 LLM 기반 agent [5]로 데이터를 합성해 학습에 투입하는 파이프라인을 개발해 왔는데요.
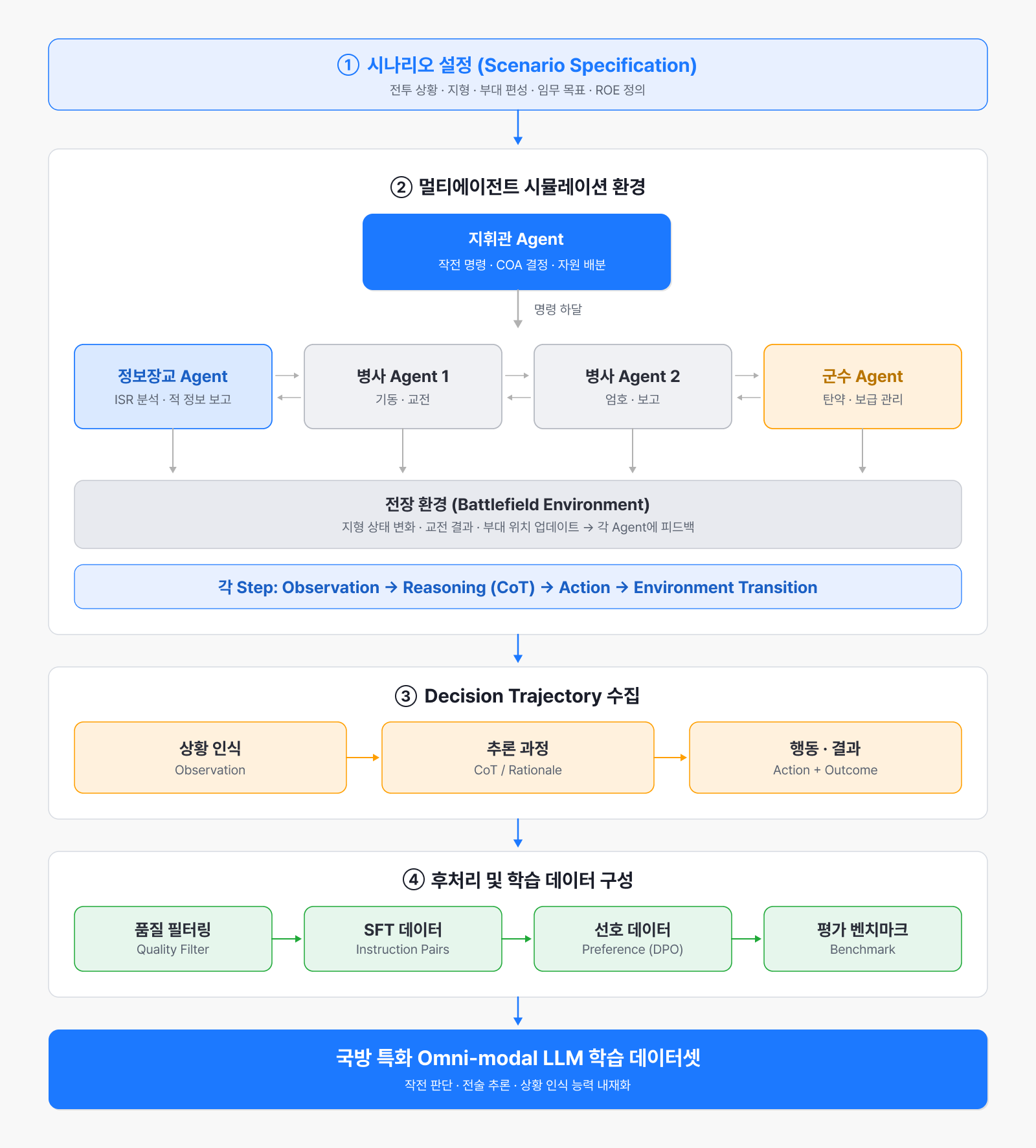
▲ Agentic Data Simulation을 통한 국방 합성 데이터 생성
방대한 데이터를 버저닝하고 관리하는 일에도 노하우가 필요한 만큼, 이를 위한 체계도 함께 마련해 두었습니다. 그중에서도 ‘어떤 데이터로 학습했는가’를 추적하는 일이 특히 중요한데요. 추적이 되지 않으면 성능 변화의 원인이 모델 구조에 있는지 데이터에 있는지 판단할 수 없기 때문이죠. 예를 들어 국방 도메인에서는 특정 버전의 모델이 교전 규칙(ROE)을 준수하는지 감사(audit)해야 하는 경우가 있는데, 이때 해당 모델을 학습시킨 데이터셋을 정확히 재현할 수 있어야 합니다.
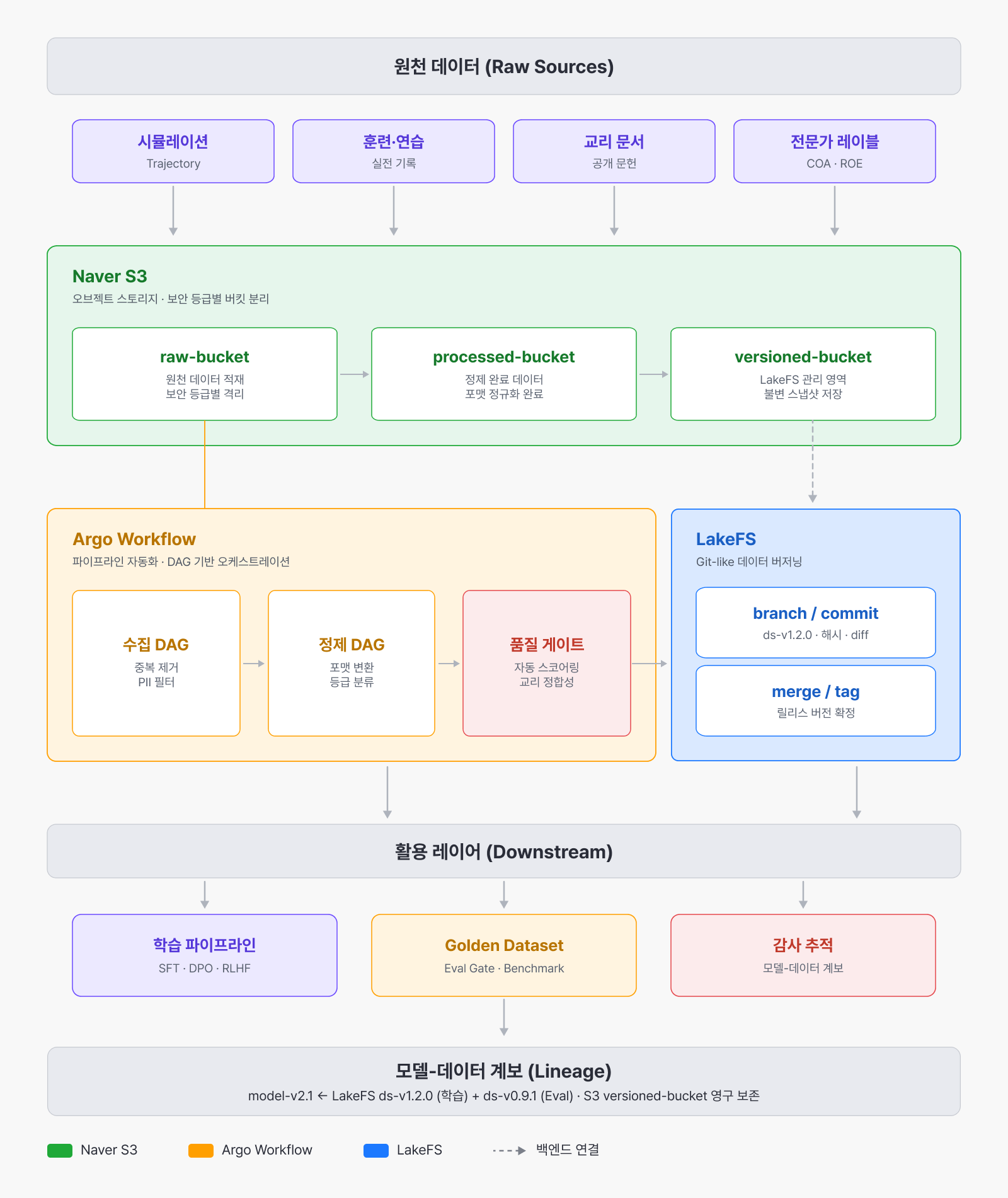
▲ 데이터 버저닝 및 관리 체계
마지막으로 모델 릴리즈와 버전 업데이트 단계에서는 새 버전이 기존 버전보다 개선되었음을 정량적으로 입증한 경우에만 릴리즈가 진행되도록 설계했습니다. 모델 아키텍처를 바꾸거나 학습 데이터를 더하고 빼면 성능이 전반적으로 향상될 수도 있지만, 때로는 특정 목적이나 과업에 한정된 개선에 그칠 수도 있는데요. 그래서 개발과 운영 과정에서 발생하는 성능 변화를 지속적으로 추적하기 위해 Eval Gate를 도입하고, 이를 통해 모델의 사용 목적별 성능을 보장하는 엄격한 검증 체계를 구축했습니다. 나아가 이 평가 체계를 고도화하는 과정에서 이미지·비디오·오디오를 포함한 다양한 옴니모달 벤치마크를 종합적으로 평가할 수 있는 Omni Evaluator [6] 를 개발하였습니다.

▲ 데이터 수집·학습·평가·운영 피드백이 반복되는 EvalOps Flywheel
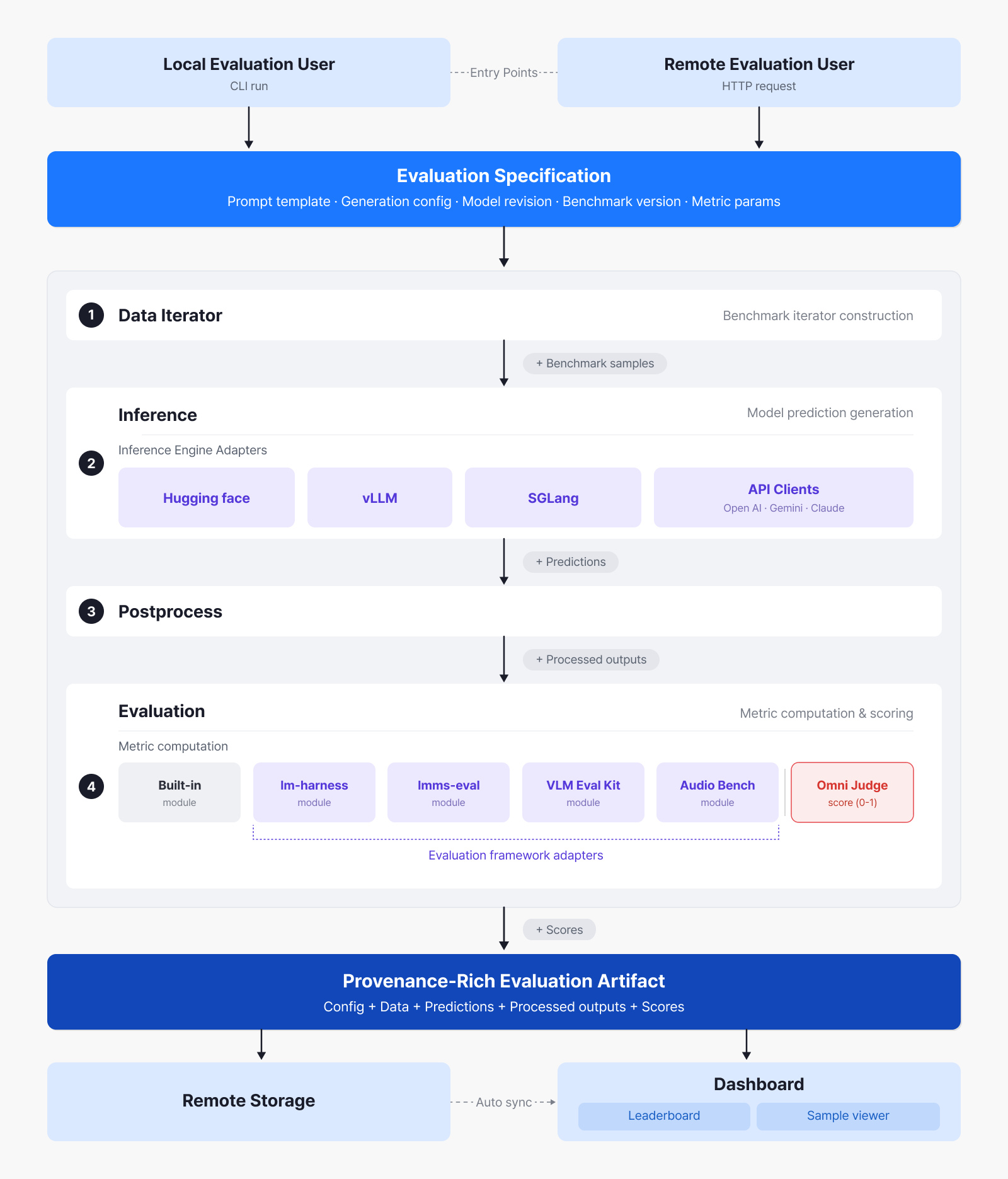
▲ Omni Evaluator
이렇게 데이터를 합성하고, 버전을 관리하고, 평가로 검증하는 과정은 서로 떨어져 있지 않습니다. 데이터 수집과 학습, 평가, 운영 피드백이 다시 데이터로 돌아오는 하나의 순환(EvalOps Flywheel)을 이루며, 버전이 거듭될수록 데이터와 평가 기준도 함께 정교해지죠. 모델뿐 아니라 이 순환 전체를 자체적으로 구축했다는 점은 공개 데이터가 부족하고 검증 기준이 엄격한 국방 같은 도메인일수록 더 큰 차이를 만듭니다.
글을 맺으며
HyperCLOVA X SEED 4B는 단순히 작은 모델을 만든 결과물이 아닙니다. 모델의 ‘눈’과 ‘귀’, 그리고 그 뒤를 받치는 데이터와 평가까지, AI를 이루는 구성 요소를 하나씩 우리 기술로 채워가는 긴 여정의 한 걸음입니다.
그 과정에서 저희는 비전 인코더를 외부 가중치 없이 직접 학습하고, 오디오 인코더를 자체 개발해 비디오 속 소리까지 함께 이해하도록 했으며, 고해상도 이미지와 긴 비디오를 효율적으로 처리하기 위한 구조를 적용했습니다. 그 결과는 분명한 숫자로 나타났습니다. 절반의 크기로 더 높은 성능을 냈고, 글로벌 모델들이 손대지 못한 한국어·한국 환경 과제에서 확실한 강점을 보였는데요. 무엇보다 이 능력은 보안과 현장성이 동시에 요구되는 국방처럼 가장 까다로운 현장에서 비로소 진가를 드러냅니다.
이 모든 노력이 향하는 곳은 하나입니다. 한국어와 한국 환경을 깊이 이해하면서도, 다양한 서비스와 현장으로 확장될 수 있는 ‘자주적 AI 기반’을 만드는 것이죠. 최근 공공·산업·국방 영역에서 요구되는 보안성과 설명 가능성, 현장 배포 가능성은 이러한 기술 내재화가 왜 필요한지를 한층 선명하게 보여줍니다. HyperCLOVA X SEED 4B는 다양한 현장에서 활용될 수 있는 범용 기반 모델이자 앞으로 더 많은 응용과 도메인 특화로 나아갈 출발점입니다. 저희는 이 모델이 더 많은 현장과 도메인으로 뻗어 나가도록, 자주적 AI의 다음 걸음을 계속 이어가겠습니다.
참고문헌
[1] “HyperCLOVA X 32B Think,” NAVER Cloud HyperCLOVA X Team, arXiv 2026. https://arxiv.org/abs/2601.03286
[2] “HyperCLOVA X 8B Omni,” NAVER Cloud HyperCLOVA X Team, arXiv 2026. https://arxiv.org/abs/2601.01792
[3] “On Efficient Language and Vision Assistants for Visually-Situated Natural Language Understanding: What Matters in Reading and Reasoning,” Geewook Kim and Minjoon Seo, EMNLP 2024. https://aclanthology.org/2024.emnlp-main.944/
[4] “Do Modern Video-LLMs Need to Listen? A Benchmark Audit and Scalable Remedy,” Geewook Kim and Minjoon Seo, Interspeech 2026 (to appear). https://arxiv.org/abs/2509.17901
[5] “Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation,” Shuo Tang, Xianghe Pang, Zexi Liu, Bohan Tang, Rui Ye, Tian Jin, Xiaowen Dong, Yanfeng Wang, and Siheng Chen, ACL 2025. https://aclanthology.org/2025.acl-long.1136/
[6] “Omni Evaluator,” GitHub repository, 2026. https://github.com/naver-ai/omni-evaluator