
LLM 경량화, 왜 필요할까?
최근 LLM(Large Language Model)의 성능 향상은 단순히 모델을 키우는 방향에서 점차 벗어나고 있습니다. 고품질 데이터의 확보, 소형 모델의 정밀도 향상, 그리고 서비스 비용 효율성을 고려한 학습 전략 등 새로운 접근 방식들이 주목받고 있습니다.
LLM을 기반으로 한 서비스가 빠르게 확산하면서 다양한 제약 조건도 함께 등장하고 있습니다. 어떤 서비스는 사용자가 체감하는 응답속도가 정해져 있거나 실시간이 요구되어 지연 시간(Latency)이 핵심인 경우가 있고, 또 다른 서비스는 약간의 지연 시간을 감수하더라도 대규모 트래픽 처리나 비용 절감을 위해 처리량(Throughput)이 우선으로 고려되는 경우도 있습니다. 이처럼 요구사항이 다변화됨에 따라, 이를 만족시킬 수 있는 LLM을 개발하는 것이 중요해졌지만, 다양한 모델을 모두 생산해서 만족시키기란 한 번 학습하는 데 막대한 비용이 소요되기에 어려운 것이 현실입니다.
결국 서비스에 적합한 구조와 크기를 갖춘 모델을 선별적으로 운영해야 하며, 동일한 파라미터 수를 가진 모델이라도 어떻게 학습되고 최적화되었는지에 따라 실제 운영 비용은 크게 달라질 수 있습니다. 문제는, 기존의 LLM을 새롭게 학습하는 데 들어가는 막대한 비용과 리소스입니다.
이러한 상황에서 HyperCLOVA X는 경량화와 고성능을 동시에 만족시키는 학습 전략, 즉 Pruning과 Knowledge Distillation을 결합한 접근법을 통해 현실적인 대안을 제시하고 있습니다.
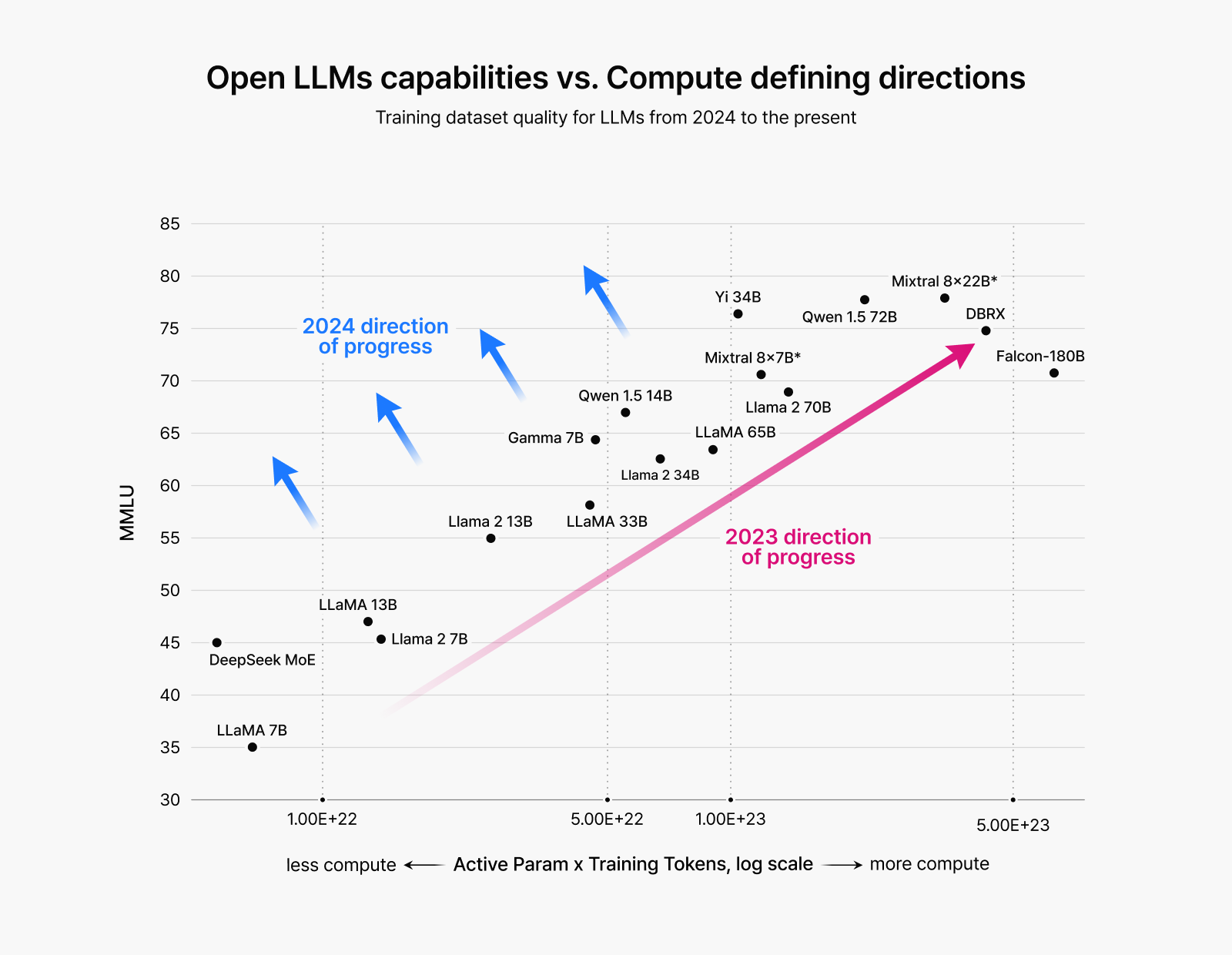
그림 1: 2023년까지는 모델을 키우는 방향의 대규모 모델 학습이 주를 이뤘으나,
2024년부터는 데이터 품질 향상을 통한 성능 개선 중심으로 전환
LLM 비용 절감의 핵심: Pruning과 Knowledge Distillation, 어떤 기술일까?
HyperCLOVA X가 선택한 두 가지 핵심 경량화 기술, Pruning과 Knowledge Distillation은 중요도가 낮은 파라미터를 가지치기(Pruning)하고, 큰 모델이 학습한 지식을 작은 모델에 전이(Distillation)하는 방식인데요, 이 두 기술은 각각 어떻게 LLM의 비용을 줄이면서도 효율을 유지할까요? 지금부터 그 원리를 자세히 살펴보겠습니다.
Pruning: 큰 모델을 가볍게 만드는 기술
LLM의 개발 비용을 절감하기 위해 경량화 관점에서 다양한 연구가 진행되었습니다. 그중에서 Pruning은 이미 학습된 모델의 파라미터를 중요도에 따라 구분하고, 중요도가 낮은 파라미터는 제거하는 방식으로 필요한 메모리의 양을 줄입니다. 더 나아가 제거된 파라미터가 연산에 포함되지 않도록 함으로써 연산량 또한 줄일 수 있습니다.
이러한 Pruning 방식에는 ‘제거된 파라미터가 얼마나 구조화(Structured)된 형태를 가지는가’에 따라 뉴런(Neuron) 단위로 중요도를 판단하여 파라미터를 제거하는 Structured Pruning부터 파라미터 하나하나의 중요도를 기준으로 가지치기하는 Unstructured Pruning까지 다양한 방식이 존재합니다.
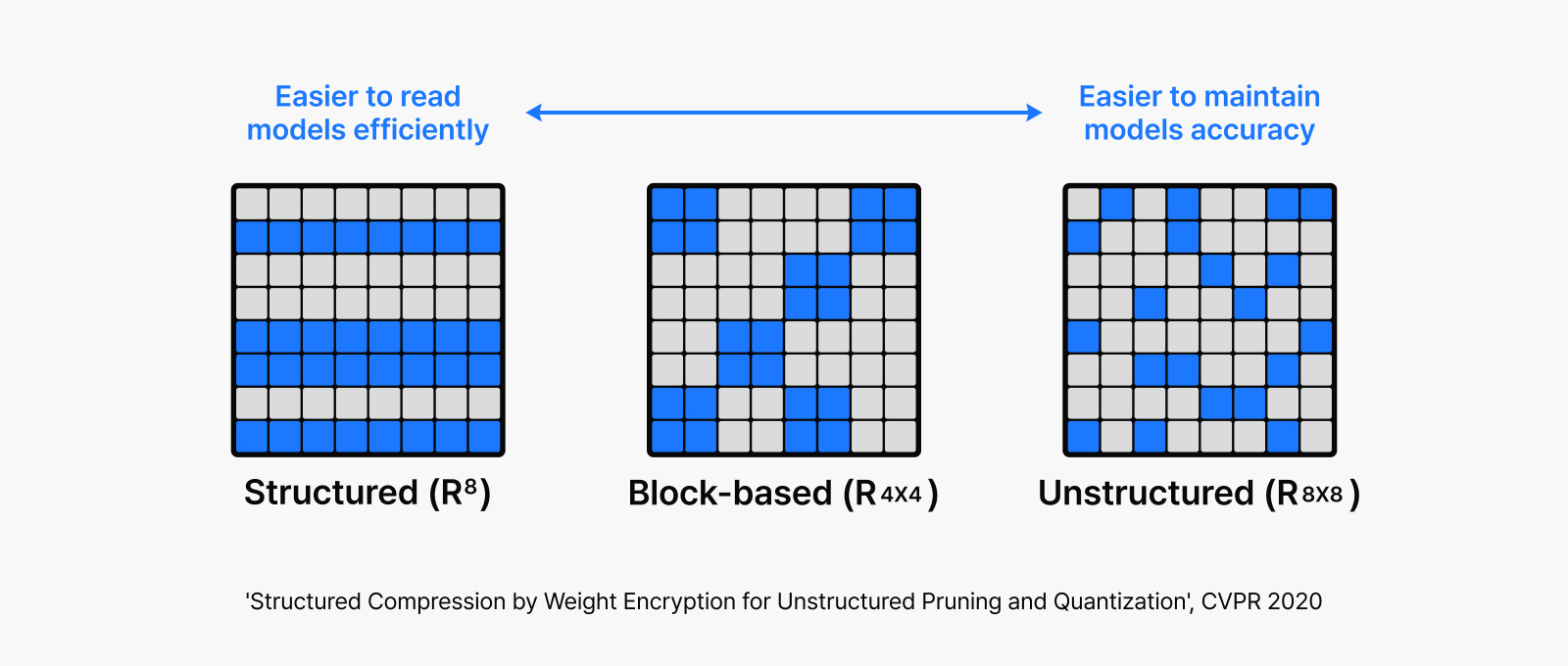
그림 2: 비정형 방식의 모델 경량화를 구조적으로 구현하기 위한 가중치 암호화 기반 압축 방법
Unstructured Pruning의 경우, 중요하지 않은 파라미터만 선택적으로 제거하기 때문에 위의 오른쪽 그림과 같이 군데군데 구멍이 뚫린 형태의 비정형 구조를 갖습니다. 이러한 구조는 모델 연산 시 하드웨어 가속을 어렵게 만드는 주요 원인이며, 하드웨어 차원에서 별도로 이를 지원하지 않는 이상 현재의 GPU Architecture에서는 Unstructured Pruning을 통해 실질적인 속도 향상을 기대하기 어렵습니다.
반면, 위 그림의 왼쪽 또는 아래 그림처럼 뉴런 단위로 Structured Pruning을 적용할 경우, 제거되지 않은 뉴런들만 모아 보다 적은 파라미터 수를 가진 연산 구조로 재구성할 수 있어 하드웨어 가속에 유리한 형태로 만들 수 있습니다.
이러한 장점에도 불구하고 Structured Pruning을 실제로 적용하기는 쉽지 않습니다. 구조화된 형태로 파라미터를 제거하다 보면 중요하지 않은 파라미터뿐만 아니라 중요한 파라미터까지 함께 제거될 가능성이 높기 때문입니다. 이로 인해 가지치기 이후 모델의 정확도가 크게 떨어질 수 있으며, 이는 Structured Pruning의 실용성을 제한하는 주요 요인입니다.
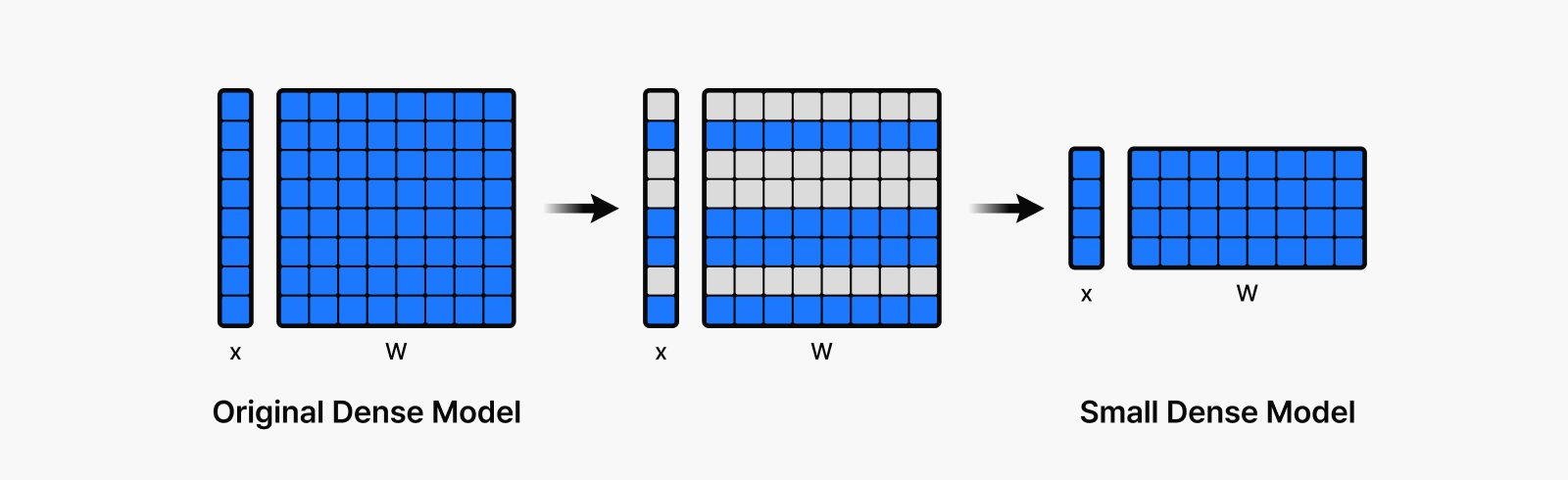
그림 3: 희소화를 거쳐 구조적으로 압축하고, 최종적으로 재배열된 경량 모델을 구성
Knowledge Distillation: 큰 모델이 배운 지식을 전이시키는 기술
그동안 Pruning으로 인해 저하된 LLM의 성능을 회복하기 위한 다양한 방법이 제안되었습니다. 특히, 모델 경량화로 발생하는 성능 손실을 보완하기 위한 연구가 활발히 진행되는 가운데, 최근에는 Knowledge Distillation이 LLM에서도 효과적인 방법으로 주목받고 있습니다.
Knowledge Distillation은 크고 똑똑한 Teacher 모델이 학습한 지식을 소형 Student 모델에 전이시키는 기법으로, Student 모델은 정답(Label)뿐 아니라 Teacher 모델의 Output 패턴(Logit 또는 출력 확률분포)도 학습합니다. 이렇게 하면 작은 모델도 크고 똑똑한 모델의 일반화 능력과 판단 기준을 어느 정도 모방할 수 있습니다.
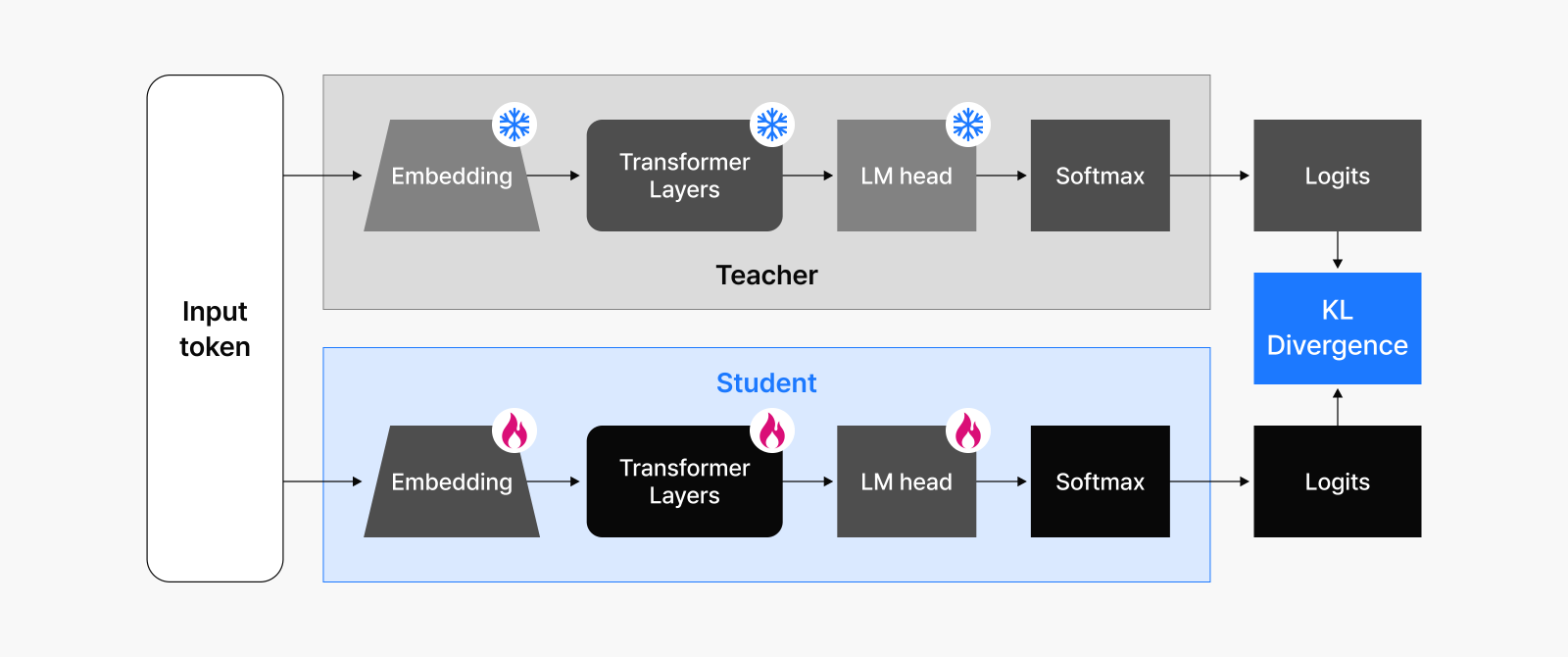
그림 4: Teacher 모델의 출력을 바탕으로 Student 모델이 지식을 모방해 학습하는 과정
Knowledge Distillation으로 학습된 소형 Student 모델은 Pruning 기법과 결합하면 더 큰 시너지를 낼 수 있습니다. 만약 크고 똑똑한 Teacher 모델을 가지치기하여 얻은 모델을 Student 모델로 사용한다면, 이 모델은 이미 Teacher 모델의 지식을 상당 부분 보존하고 있기 때문에 기존에 큰 비용이 들던 LLM 학습 방식에 비해 Distillation은 훨씬 빠르고 효율적으로 학습을 진행할 수 있습니다.
이처럼 Pruning은 모델을 작고 가볍게 만들고, Distillation은 그렇게 가벼워진 모델에 다시 지능을 불어넣는 역할을 합니다. HyperCLOVA X는 이 두 가지 기술을 조화롭게 결합하여, 낮은 비용으로도 높은 성능을 낼 수 있는 LLM 학습 전략을 확립했습니다. 이러한 전략은 단순한 기술 조합을 넘어, 서비스 요구 조건에 따라 최적화된 모델을 유연하게 생산할 수 있는 토대가 되어줍니다.
HyperCLOVA X의 경량화 학습 공정: 고효율 모델을 만드는 경량화 기술
HyperCLOVA X는 학습 단가 대비 성능이 높은 소형 모델을 생산하는 방안에 대해 지속적으로 고민하고 있습니다. 단순히 모델의 학습 비용을 줄인다는 측면을 넘어서, 서비스 요구 조건에 맞는 적절한 크기와 구조의 모델을 설계하고 적시에 제공하는 것은 단지 성능 최적화뿐 아니라 운영 비용의 효율화 관점에서도 매우 중요합니다.
하지만 서비스 요구 조건에 부합하는 다양한 LLM 모델을 적시에 생산하여 제공하기에 기존 방법으로는 시간과 자원, 인력 등 비용이 많이 들어갑니다. 작은 모델이라도 일정 수준의 성능을 확보하기 위해 최소 수조에서 많게는 수십조 단위의 토큰을 학습시키는 과정을 거쳐야 하기 때문인데요. 또한 모델의 크기가 작아질수록 GPU의 계산 능력을 높은 수준으로 사용하기 어렵기 때문에 아무리 작은 모델이라 하더라도 한 번 학습하는 데 큰 비용이 소요됩니다.
이에 HyperCLOVA X는 비용 효율적인 모델 학습 방법으로 Pruning과 Knowledge Distillation 기술을 활용하여, 기존 LLM 학습 방법보다 적은 시간과 GPU 자원으로도 좋은 성능의 모델을 효율적으로 학습할 수 있었습니다. 이러한 기술을 다듬어 이번 HyperCLOVAX-SEED-Text-Instruct-0.5B 모델에 적용했습니다.
[관련 내용 – AI 생태계에 씨앗을 뿌리다: 상업용 오픈소스 AI, HyperCLOVA X SEED]
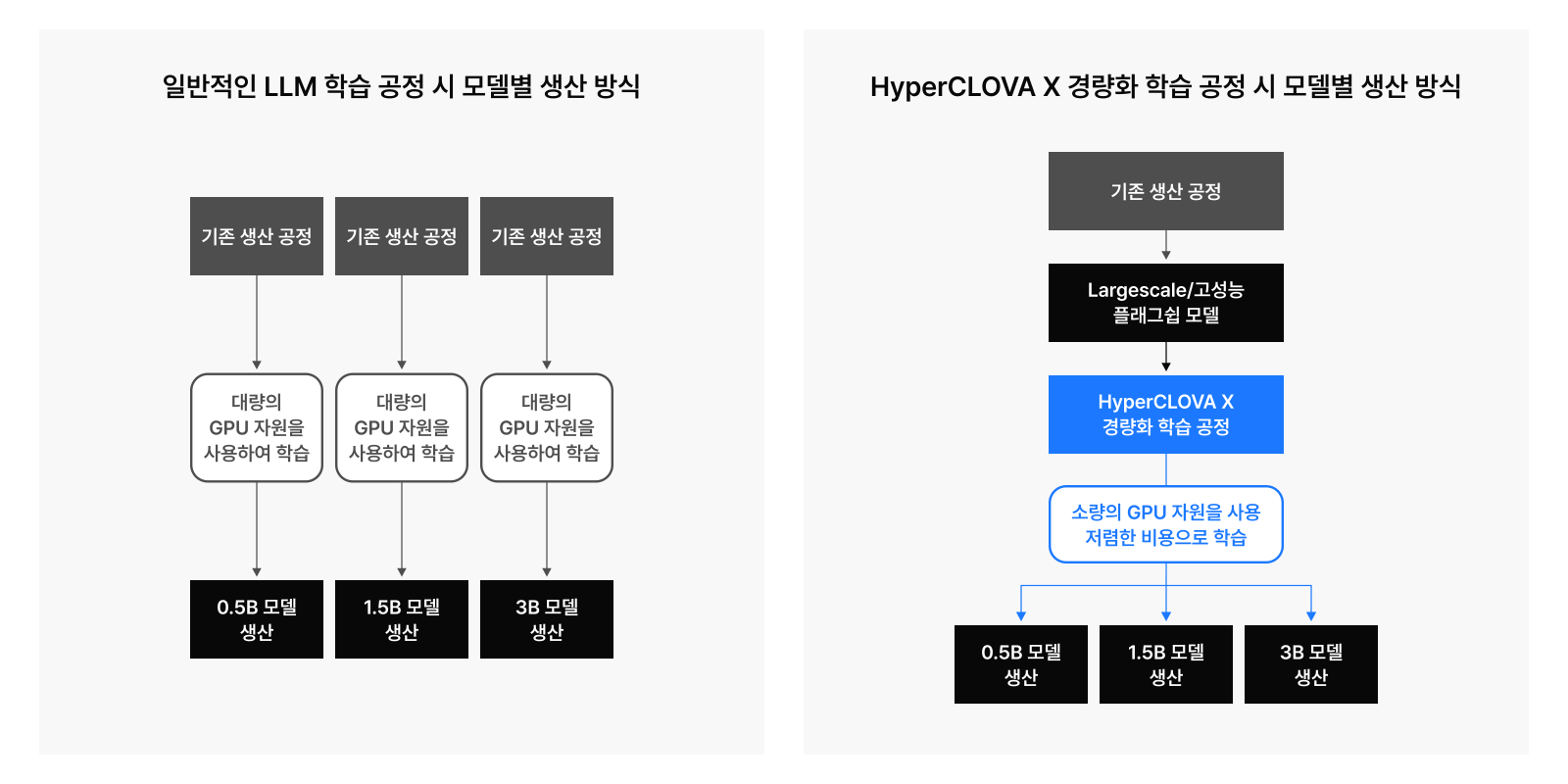
실제 사례: HyperCLOVAX-SEED-Text-Instruct-0.5B
HyperCLOVAX-SEED-Text-Instruct-0.5B 학습 효율은?
HyperCLOVAX-SEED-Text-Instruct-0.5B는 네이버의 경량화 기술이 실제로 어떤 성과를 낼 수 있는지 잘 보여주는 사례입니다. 유사한 파라미터 규모의 Qwen2.5-0.5B-Instruct와 비교했을 때, HyperCLOVA X는 현저히 낮은 리소스로 사전 학습(pre-training)을 마쳤습니다.
| 사전 학습 리소스 | HyperCLOVAX-SEED-Text-Instruct-0.5B | Qwen2.5‑0.5B‑Instruct |
| A100 GPU 시간 | 4,358 | 169,257 |
| 비용 (USD) | 6,537 | 253,886 |
실제 수치를 보면, HyperCLOVA X는 약 4,358 GPU 시간과 6,537달러의 비용으로 학습했으며, 이는 Qwen2.5-0.5B-Instruct가 요구한 169,257 GPU 시간과 253,886달러에 비해 39배 가까이 효율적인 수치입니다. 이러한 차이는 단순한 최적화 수준을 넘어, 모델 학습에 드는 자원과 비용 구조를 근본적으로 재설계할 수 있다는 가능성을 보여줍니다. HyperCLOVAX-SEED-Text-Instruct-0.5B 학습 비용은 Qwen2.5-0.5B-Instruct보다 저렴하지만, 성능은 절대 뒤지지 않습니다.
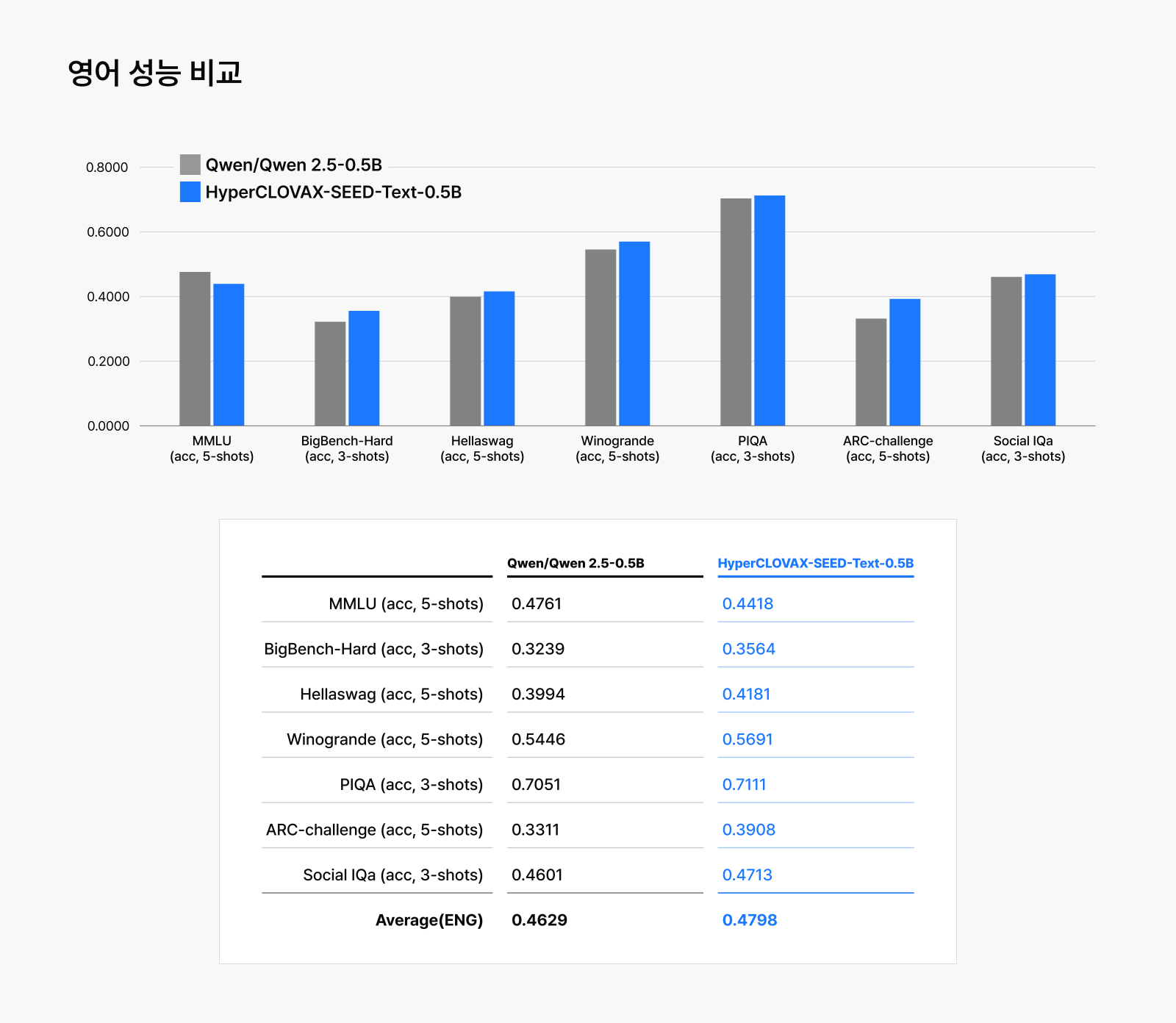
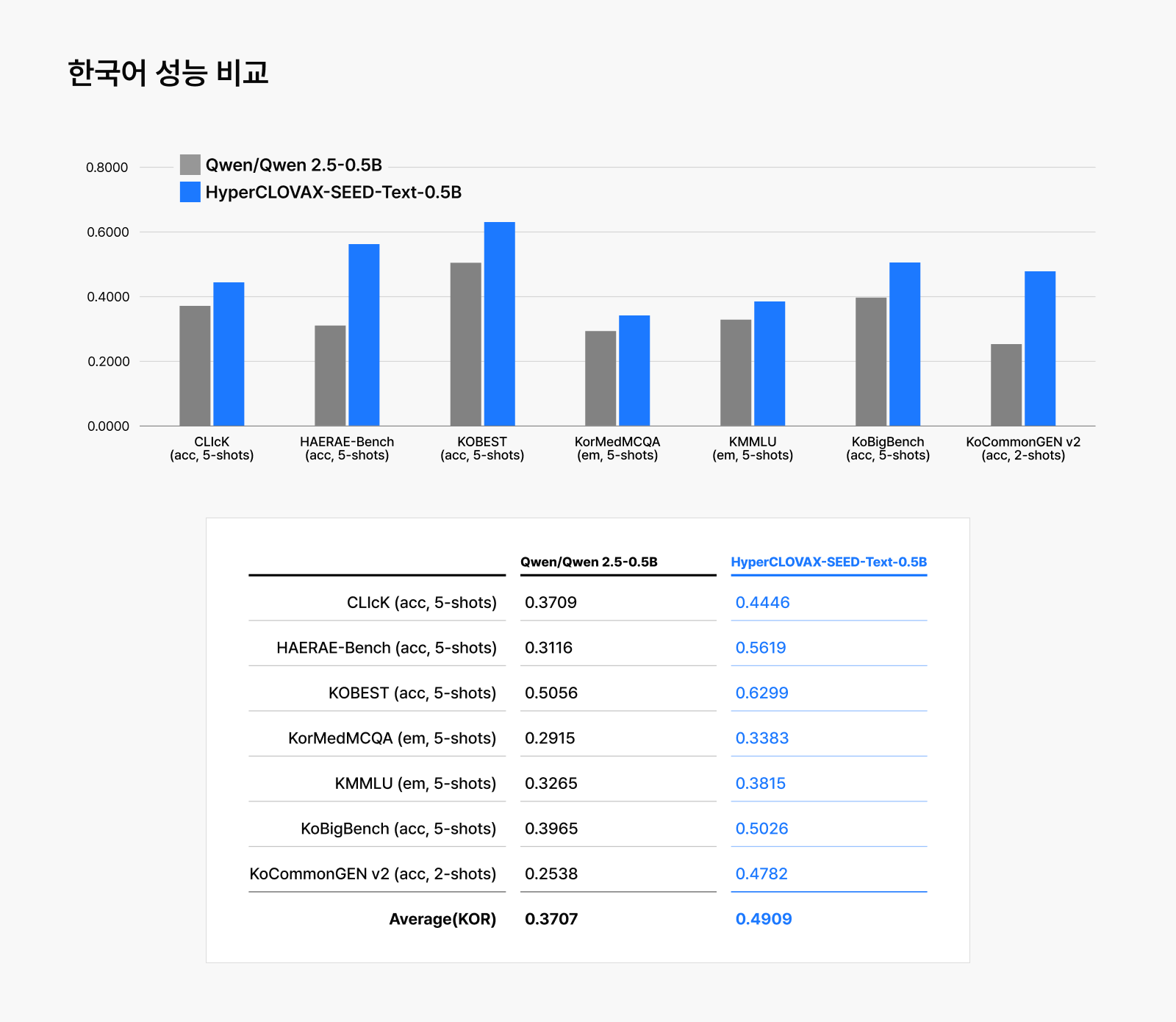
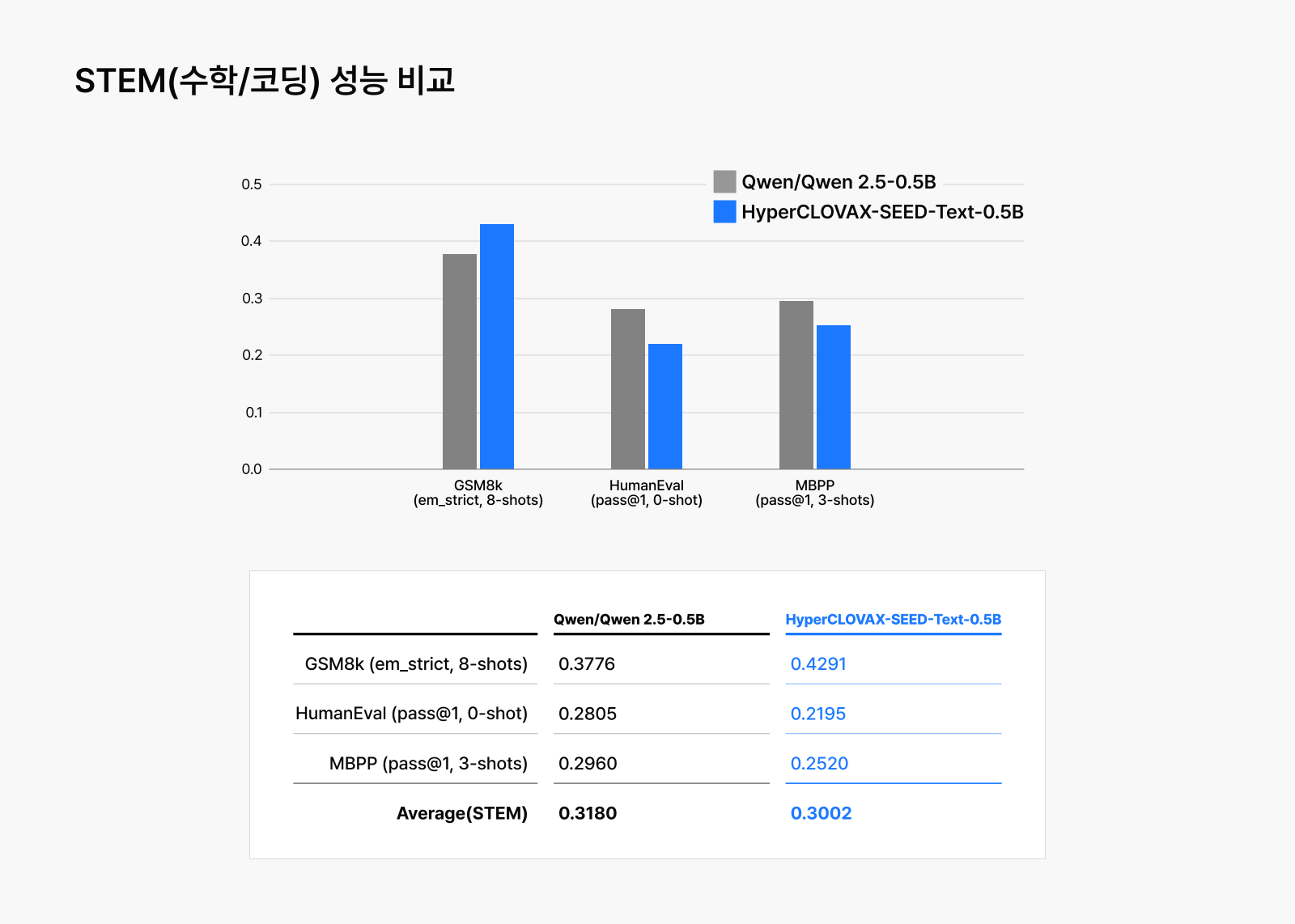
내부적으로 20개 이상의 내부ㆍ외부 평가 기준을 두어 학습된 모델의 능력을 판단했을 때, 네이버의 경량화 기술이 적용된 HyperCLOVA X SEED Text-Instruct-0.5B가 저렴한 비용으로 학습되었음에도 뛰어난 성능을 유지한다는 것을 볼 수 있습니다. LLM의 기초 능력을 평가하는 MMLU부터 한국어에 대한 여러 평가까지 동일한 크기의 Qwen2.5-0.5B-Instruct보다 대부분의 벤치마크에서 우수한 결과를 얻었습니다.
경량화 기술이 여는 HyperCLOVA X의 새로운 가능성
오늘날의 AI 시대에서 서비스는 속도와 효율, 그리고 유연성에 의해 결정됩니다. HyperCLOVA X는 Pruning과 Knowledge Distillation을 결합한 공정을 통해 작지만 충분한 성능을 지닌 LLM을 효율적으로 생산할 방안을 계속해서 모색하고 있습니다.
Pruning과 Knowledge Distillation 기반의 학습 전략은 단순한 모델 경량화 기술을 넘어, 여러 AI를 활용한 서비스에 맞춤화된 모델을 빠르고 효율적으로 제공할 수 있다는 점에서 높은 가능성을 드러냅니다. 네이버클라우드는 이 기술을 바탕으로 더 많은 산업 현장에서 AI가 실질적인 도구로 활용될 수 있도록 노력하고 있으며, 경량화 기술을 다양한 비즈니스 도메인에 유연하게 적용함으로써 클라우드 기반 AI 기술의 확장성과 실용성을 동시에 갖춘 경쟁력 있는 플랫폼으로 발전시켜 나가겠습니다.