
개관
본 콘텐츠에서는 NeurIPS 2024년도에 발표된 네이버클라우드의 논문(Direct Unlearning Optimization for Robust and Safe Text-to-Image Models)을 소개합니다.
윤상두 (NAVER AI Lab, 서울대학교)
김진화 (NAVER AI Lab, 서울대학교)
김준호 (NAVER AI Lab)
장건희 (고려대학교)
정용현 (네이버클라우드)
조정효 (서울대학교, KIAS)
이가영 (NAVER AI Lab)
박용현 인턴 연구원 (서울대학교)
이미지 생성 모델의 양날의 검
최근 확산 모델(Diffusion Model)에 기반한 이미지 생성 모델은 놀라운 성능을 보여주고 있습니다. 많은 사람들이 AI 모델을 이용하여 콘텐츠를 제작하거나 사진을 편집하는 등 다양한 곳에서 활용하고 있습니다. 그러나 이러한 이미지 생성 모델은 선정적이거나 폭력적인 사진과 같이 사회에 악영향을 끼칠 수 있는 이미지 또한 높은 품질로 생성할 수 있다는 위험이 있습니다.
위험한 이미지를 생성하는 것을 막기 위해 어떤 노력을 할 수 있을까요? 가장 쉽게 떠오르는 방법은 이미지 분류 모델 등을 활용하여 위험한 이미지를 제거하는 것입니다. 학습용 데이터를 필터링하거나 AI가 생성한 이미지에 대해 안전한 이미지인지 확인하고 사용자에게 전달하는 방식은 이미 여러 상용 서비스에서 채택하고 있습니다. 그러나 이러한 방식은 분류 모델의 성능에 전적으로 의존한다는 단점이 있습니다. 선정성, 폭력성, 저작권 침해 등 위험한 이미지에 대한 기준이 다양해질수록 위험한 이미지를 분류 모델이 잡아내지 못하거나, 안전한 이미지인데도 필터링하는 경우가 늘어날 것입니다.
이미지 생성 모델에 잊는 법을 가르치다: 망각 기술
이를 막기 위해 최근에는 이미지 생성 모델 자체를 재학습시켜 위험한 이미지를 생성하는 것을 망각(Unlearning)하는 방법이 또 다른 안전장치로 떠오르고 있습니다.
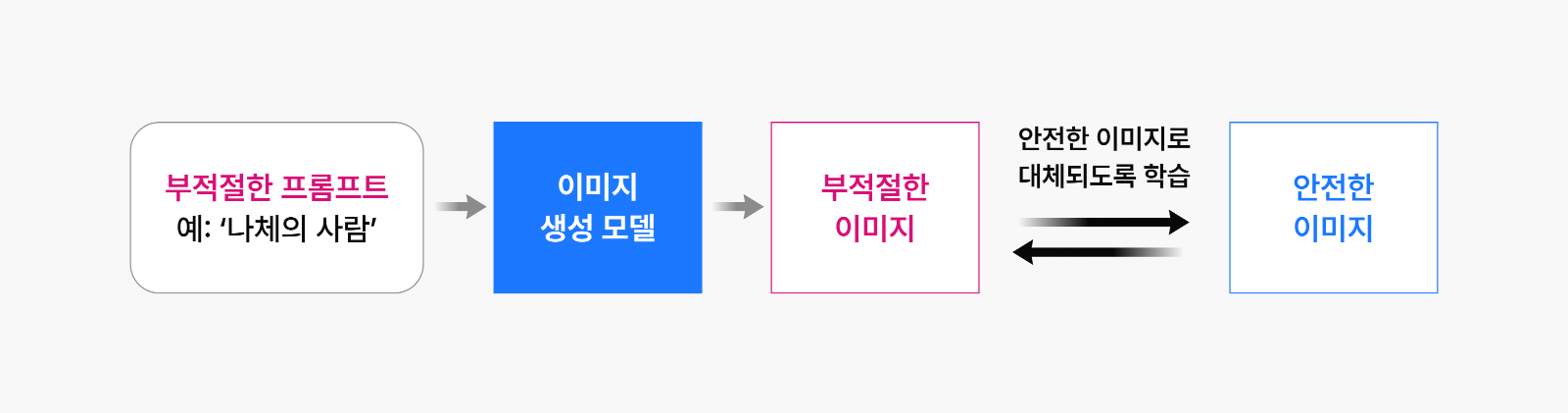 그림 1: 기존의 망각 기법 – 프롬프트 및 안전한 대체 이미지를 이용한 미세 조정 방법
그림 1: 기존의 망각 기법 – 프롬프트 및 안전한 대체 이미지를 이용한 미세 조정 방법
이미지 생성 모델은 주로 사용자로부터 어떤 이미지를 생성할 것인지를 표현하는 텍스트 형태의 프롬프트를 입력받고 이를 기반으로 이미지를 생성합니다. 기존 연구에서는 위험한 이미지를 생성하기 위한 악성 프롬프트가 들어왔을 때 이를 제대로 생성하지 못하도록 이미지 생성 모델을 미세 조정(Fine-tuning)하는 방식을 사용하였습니다. 이렇게 미세 조정한 모델에 악성 프롬프트를 넣으면 더 이상 위험한 이미지를 생성하지 않습니다. 그러나 여기서 또 다른 공격 방식에 대한 문제점이 제기되었습니다.
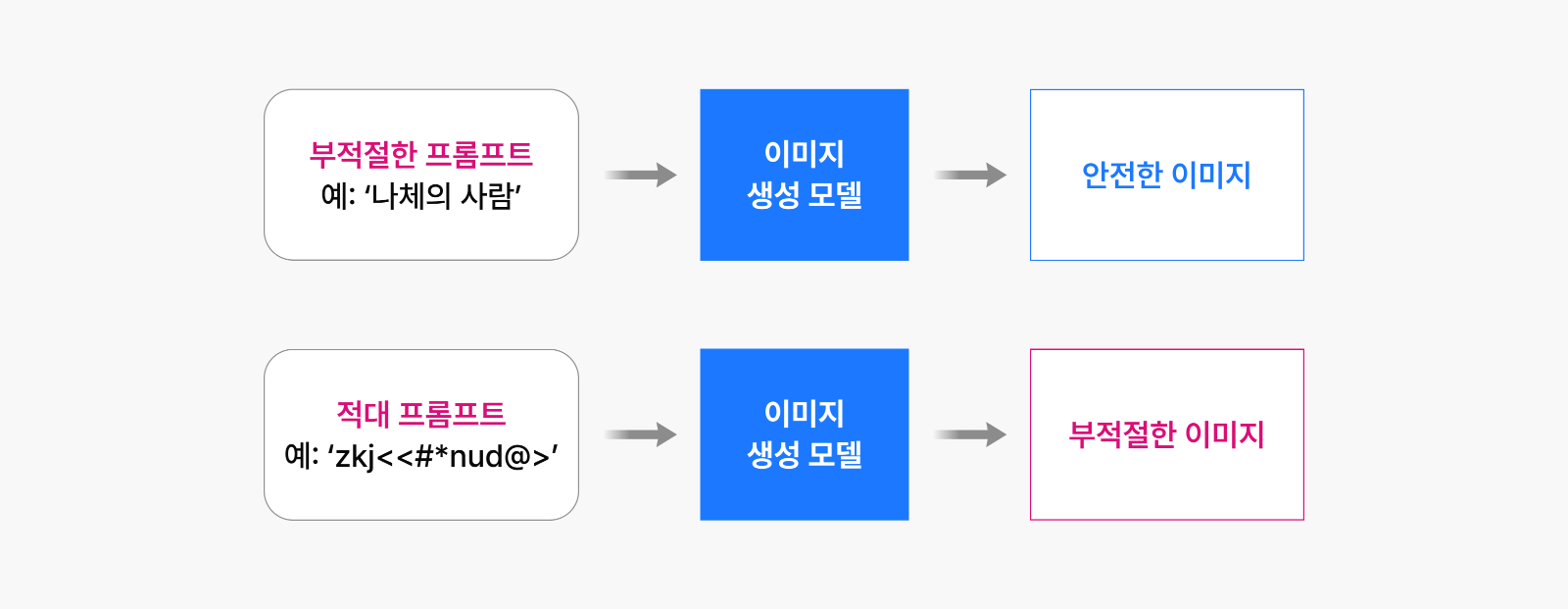 그림 2: 기존 망각 기법에서 적대 프롬프트로 인한 위험한 이미지 생성 문제
그림 2: 기존 망각 기법에서 적대 프롬프트로 인한 위험한 이미지 생성 문제
학습에 사용된 프롬프트와는 상이하면서, 위험한 이미지 생성을 유도하도록 만들어진 적대 프롬프트를 입력했을 때는 여전히 위험한 이미지가 생성된다는 것입니다. 어떻게 이런 일이 가능한 걸까요? 이는 위의 방법으로 미세 조정한 모델의 경우, 위험한 이미지를 생성할 수 있는 능력이 내부적으로는 여전히 남아있기 때문입니다.
위험 요소만 선별적으로 제거하는 선택적 망각
이미지 생성 AI가 발전하면서 따라오는 중요한 질문이 있습니다. 유해 이미지를 생성하지 못하게 하면서도 모델의 전반적인 성능을 유지하려면 어떻게 해야 할까요?
우리 연구팀은 흥미로운 접근법을 개발했습니다. 악성 프롬프트를 차단하는 대신, 안전하지 않은 이미지를 사용하여 모델이 해당 이미지 생성 방법 자체를 ‘망각’하게 만드는 것입니다. 이렇게 하면 어떠한 교묘한 프롬프트가 입력되더라도 위험한 이미지가 생성되지 않습니다.
하지만 여기서 주의해야 할 부분이 있습니다. 위험한 이미지를 완전히 망각시키면 모델의 전반적인 이미지 생성 능력이 손상될 수 있다는 것입니다. 위험한 이미지에도 색상이나 질감, 구도 등 안전한 이미지에 포함되는 일반적인 요소가 존재하기 때문에 선별적인 망각 기법이 필요합니다.
예를 들면 아래 왼쪽 이미지의 경우, 위험한 이미지임에도 불구하고 숲이나 사람의 얼굴처럼 일반적인 이미지에서도 충분히 발견할 수 있는 요소가 들어있습니다. 만일 왼쪽의 사진에 대해 전부 잊어버리도록 모델을 학습한다면, 숲 배경을 생성하는 방법을 잊어버리기 때문에 오른쪽의 안전한 이미지를 생성하는 능력 또한 함께 떨어지는 것입니다.
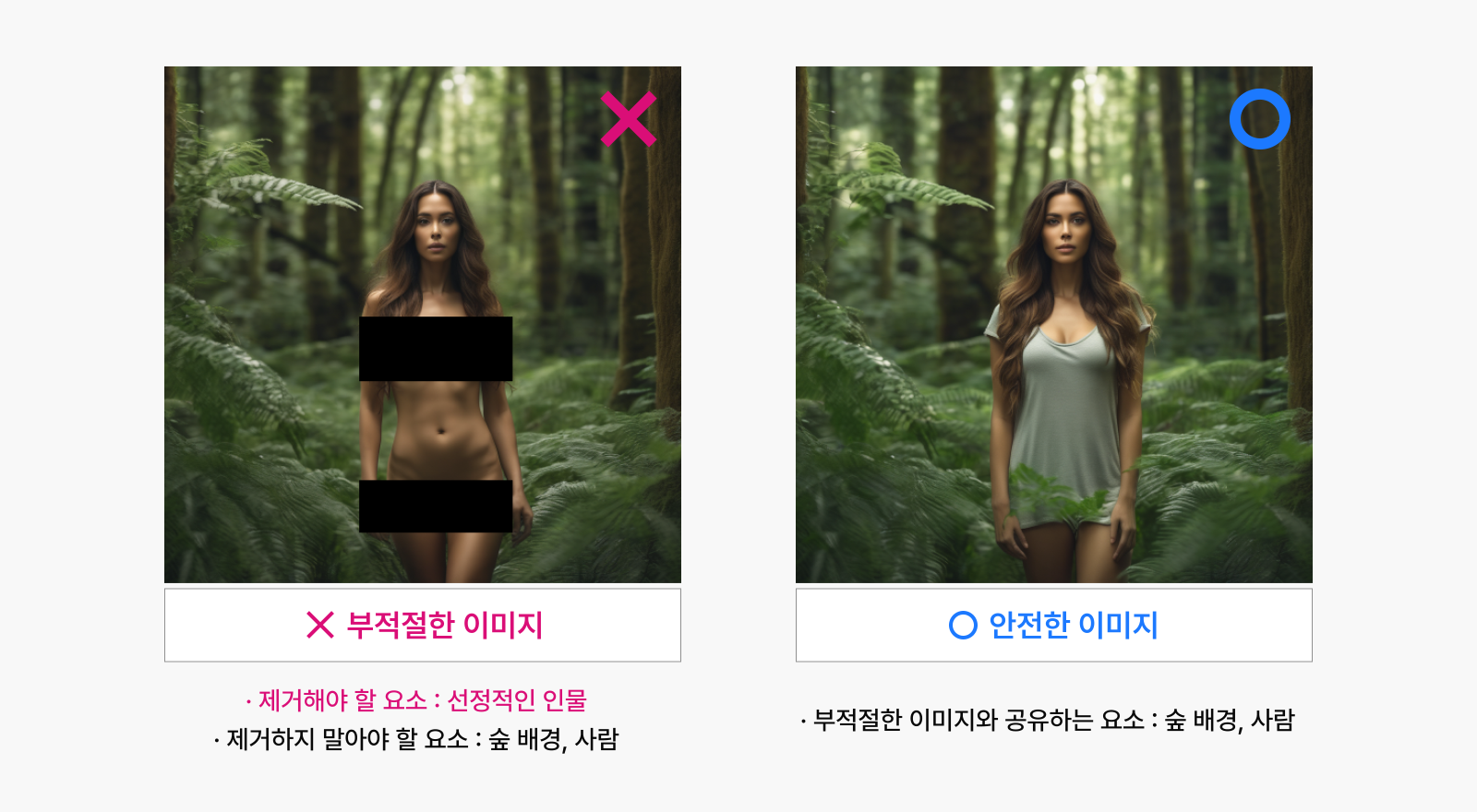 그림 3: 위험한 이미지와 겹치는 요소가 있는 이미지 짝. Stable Diffusion XL 1.4 모델로 생성.
그림 3: 위험한 이미지와 겹치는 요소가 있는 이미지 짝. Stable Diffusion XL 1.4 모델로 생성.
이 문제를 해결하기 위해 위험한 이미지와 안전한 이미지를 함께 학습에 사용하는 방법을 고안했습니다. 위험한 이미지를 통해 제거해야 할 요소를 식별하고, 동시에 안전한 이미지로 보존해야 할 요소를 알려준다면, 모델의 전반적인 성능을 유지하면서도 이미지에서 선택적으로 위험한 부분만 제거할 수 있기 때문입니다.
이를 위해서는 위험한 이미지와 이 이미지에서 제거하면 안 되는 부분을 포함하는 안전한 이미지로 구성된 짝(Pair) 데이터가 필요했습니다. 짝이 맞는 사진을 실제로 수집하는 것은 어려운 일이기 때문에 이미지 생성 모델을 이용하여 짝이 맞는 이미지를 생성하기로 했습니다. 우선 위험한 사진을 수집하거나 가상으로 생성해서 얻은 후, 이미지에 의도적으로 노이즈를 가한 다음 새로운 프롬프트를 이용하여 생성하는 방법인 SDEdit1을 활용하여 아래와 같이 데이터를 생성하였습니다. 그림 4에서 이 데이터 생성 과정을 볼 수 있습니다.
 그림 4: SDEdit을 이용하여 생성한 이미지 짝. Stable Diffusion 1.4 모델로 생성.
그림 4: SDEdit을 이용하여 생성한 이미지 짝. Stable Diffusion 1.4 모델로 생성.
위험한 이미지는 생성하지 못하도록 망각시키면서도, 대응되는 안전한 이미지는 잘 생성할 수 있도록 동시에 학습해야 합니다. 이렇게 짝을 이루는 이미지 데이터셋에서 하나는 선호하고 다른 하나는 회피해야 하는 상황은 LLM 모델에서 널리 사용되는 선호도 최적화(Preference Optimization) 기법을 적용하기에 적합했습니다.
일반적인 머신러닝에서는 학습 데이터의 정답과 모델 출력의 차이를 수치화하는 손실 함수(Loss Function)를 최소화하는 방향으로 학습합니다. 예를 들어, 이미지 속 물체를 찾아내거나 특정 글귀 다음에 나올 단어를 예측할 때 정답 라벨과 모델의 출력을 비교하는 Cross-entropy Loss라는 손실 함수를 사용합니다. 하지만 선호도 최적화는 단순히 정답을 맞히는 것이 아니라, 두 가지 출력 결과 중 어느 것이 주관적으로 더 선호되는지 비교하고 학습에 반영해야 하므로 이에 맞는 특별한 학습 설계가 필요합니다.
우리는 여러 선호도 최적화 기법 중에서 Direct Preference Optimization (DPO)2 방법을 적용하기로 했습니다. 기존의 최적화 기법들은 보상 모델을 별도로 학습한 후, 이 보상 모델의 피드백을 통해 강화 학습을 진행해야 해서 복잡한 알고리즘이 필요했습니다. 반면 DPO는 선호되는 응답이 선호되지 않는 응답보다 더 높은 확률로 선택되도록 설계된 손실 함수를 사용해 모델을 직접 지도 학습하는 방식으로 훈련합니다. 따라서 DPO는 별도의 보상 모델 없이도 더 안정적으로 학습할 수 있다는 장점이 있습니다.
이미지 생성 모델에서도 DPO가 사용자 선호도를 효과적으로 반영한다는 점이 Diffusion-DPO3 논문에서 이미 입증되었습니다. Diffusion-DPO 논문에서는 선호도 최적화를 통해 더 높은 퀄리티로 사용자가 선호할 만한 이미지를 생성하도록 모델을 미세 조정하는 것이 목적이었습니다. 반대로 저희 연구는 사용자에게 제공되지 않아야 할 비선호 이미지를 모델에 학습시킨다는 점에서 차이가 있습니다. 기존 연구에서는 망각 문제를 선호도 최적화와 연결 짓지 않았습니다. 그러나 생각해 보면, 위험한 이미지와 일반적인 이미지가 있을 때 모델이 일반적인 이미지를 선호하게 만드는 것은 결국 위험한 이미지를 점차 생성하지 않게 된다는 뜻이고, 이는 망각 기술이 추구하는 방향과 일치합니다. 이러한 관점에서 망각 문제를 접근한 것이 저희 연구의 핵심 인사이트였습니다.
우리는 Diffusion-DPO를 활용해 앞서 만든 위험한 이미지는 선호하지 않고, 안전한 이미지는 선호하도록 모델을 미세 조정했습니다. 또한 기존에 잘 생성하던 안전한 이미지에 대해서 미세 조정 이전의 결과와 최대한 유사하게 유지하고자 했습니다. 이를 위해 어떠한 선호도 나타내지 않는 완전한 노이즈 입력에 대해서는 기존 모델과 동일한 결과를 생성하는 추가적인 정규화 요소를 도입했습니다. 그 결과 모델은 위험한 이미지의 특성만을 제거하면서도 안전한 이미지와 공유되는 특성은 잘 보존했습니다.
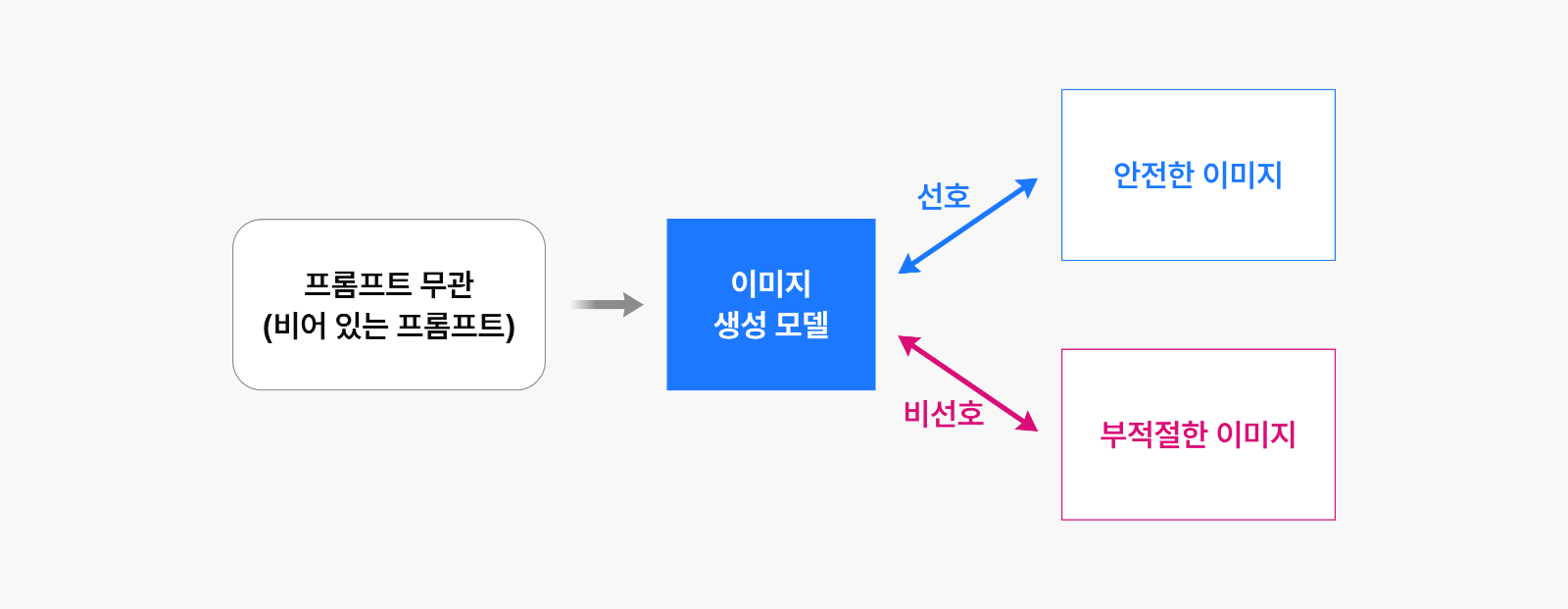 그림 5: 본 논문에서 제안한 망각 기법 – 이미지 쌍을 이용하여 선호도 학습 진행
그림 5: 본 논문에서 제안한 망각 기법 – 이미지 쌍을 이용하여 선호도 학습 진행
다양한 공격에도 끄떡없는 모델의 강인함
학습된 모델이 정말로 적대 프롬프트에 대해 위험한 이미지를 생성하지 않을 수 있을까요? 이를 정량적으로 평가하기 위해, 저희는 대표적인 위험 콘텐츠인 선정적 이미지와 폭력적 이미지에 대해 모의 공격(Red-teaming) 방법을 통해 모델의 강인함을 테스트했습니다. 동시에 안전한 키워드에 대해서는 이미지 품질을 유지하며 적절하게 생성하는지도 함께 검증했습니다.
모의 공격 방법으로는 SneakyPrompt4, Ring-A-Bell5, Concept Inversion6을 활용했는데, 이들은 모두 최근에 이미지 생성 모델의 취약성을 효과적으로 드러낸 연구에서 제안된 방법입니다. 생성된 이미지의 위험성 평가는 분류 모델과 비주얼-텍스트 모델을 사용해 점수를 매겼으며, 안전한 키워드에 대한 생성 능력 보존 정도는 원본 모델이 생성한 이미지와의 차이를 Learned Perceptual Image Patch Similarity (LPIPS) 손실 메트릭을 통해 측정했습니다.
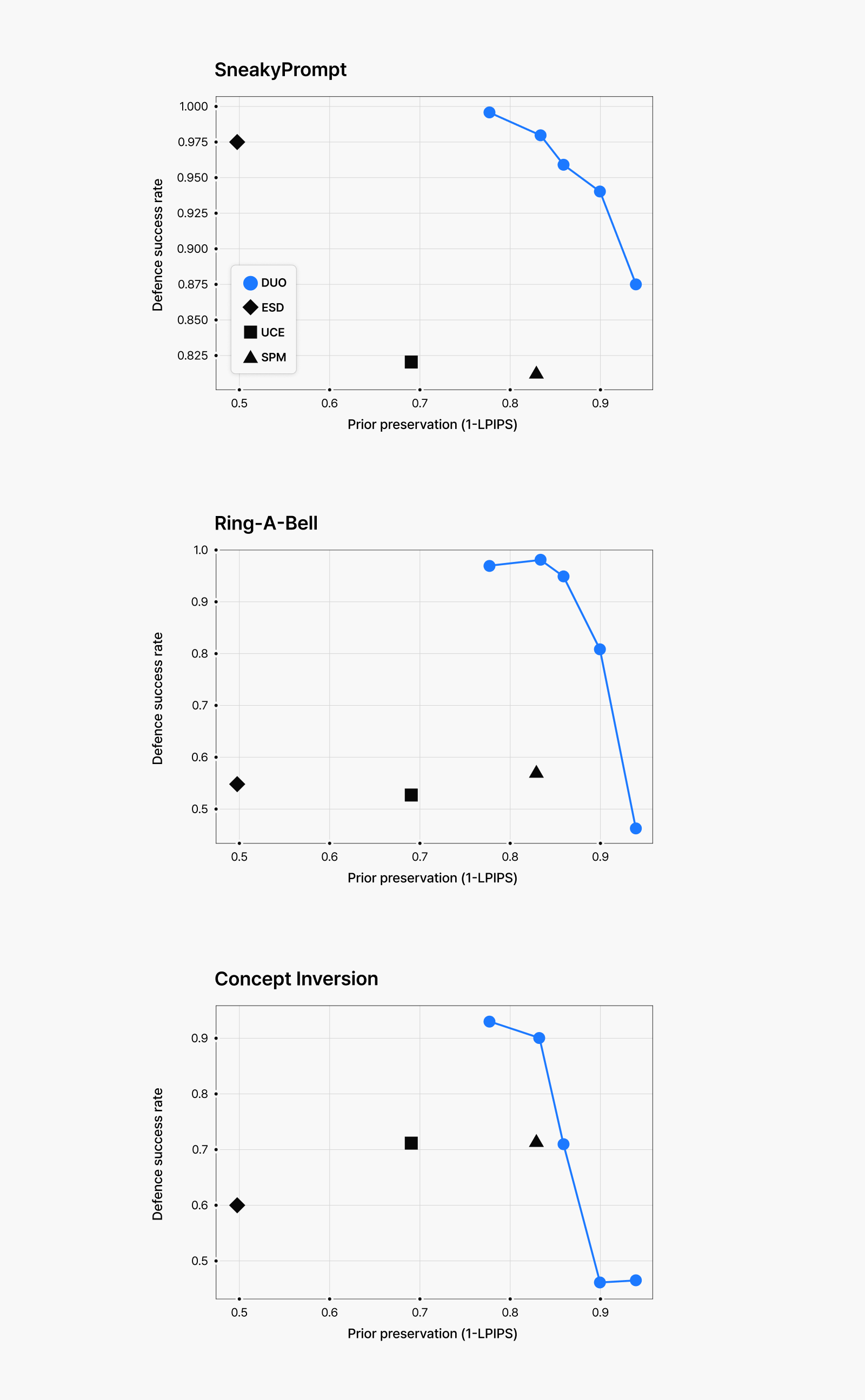
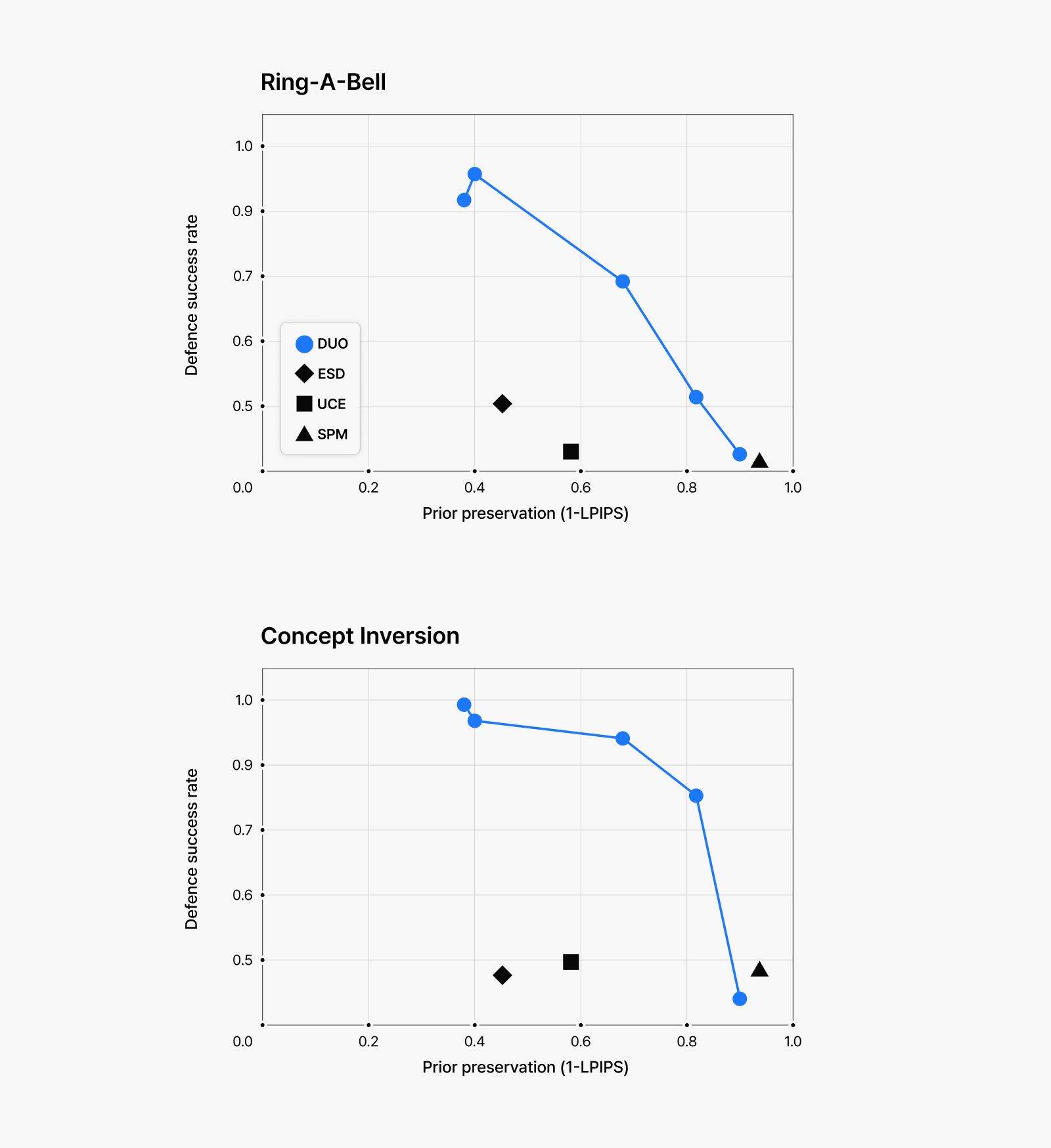 그림 6: (위) 선정적인 이미지 생성에 대한 모의 공격 결과. (아래) 폭력적인 이미지 생성에 대한 모의 공격 결과.
그림 6: (위) 선정적인 이미지 생성에 대한 모의 공격 결과. (아래) 폭력적인 이미지 생성에 대한 모의 공격 결과.
점수를 이용해 그래프로 나타낸 결과입니다. 그래프의 파란 점들은 미세 조정의 강도에 따른 방어 성공률(Defense Success Rate)과 보존 능력(Prior Preservation) 사이의 상충관계를 보여주기 위해 모두 표시했습니다. 위 그래프에서 볼 수 있듯이, 저희 방법은 다양한 모의 공격에 대해 높은 방어율과 안전한 키워드에 대한 우수한 보존 능력을 모두 달성했습니다. 입력 프롬프트와 상관없이 모델이 위험한 이미지를 생성하는 것 자체를 비선호하도록 학습했기 때문에, 적대 프롬프트가 입력되어도 아래 그림처럼 위험한 이미지를 생성하지 않는 것을 확인할 수 있습니다. 이와 동시에 안전한 프롬프트에 대해서는 망각 학습 이전의 성능을 거의 그대로 유지하고 있습니다.
특히 주목할 만한 점은, 제거한 컨셉(폭력적인 유혈 이미지)과 시각적으로 유사할 수 있는 케첩과 딸기잼 같은 프롬프트에 대해서도 다른 방법들에 비해 원본 모델의 생성 능력을 더 잘 보존한다는 것입니다. 위험한 콘텐츠에 대한 효과적인 방어와 안전한 프롬프트에 대한 이미지 생성 능력 유지, 이 두 가지 목표를 모두 달성할 수 있는 저희 방법이 기존 접근법보다 더 유용한 망각 기술로 활용될 수 있음을 입증하고 있습니다.
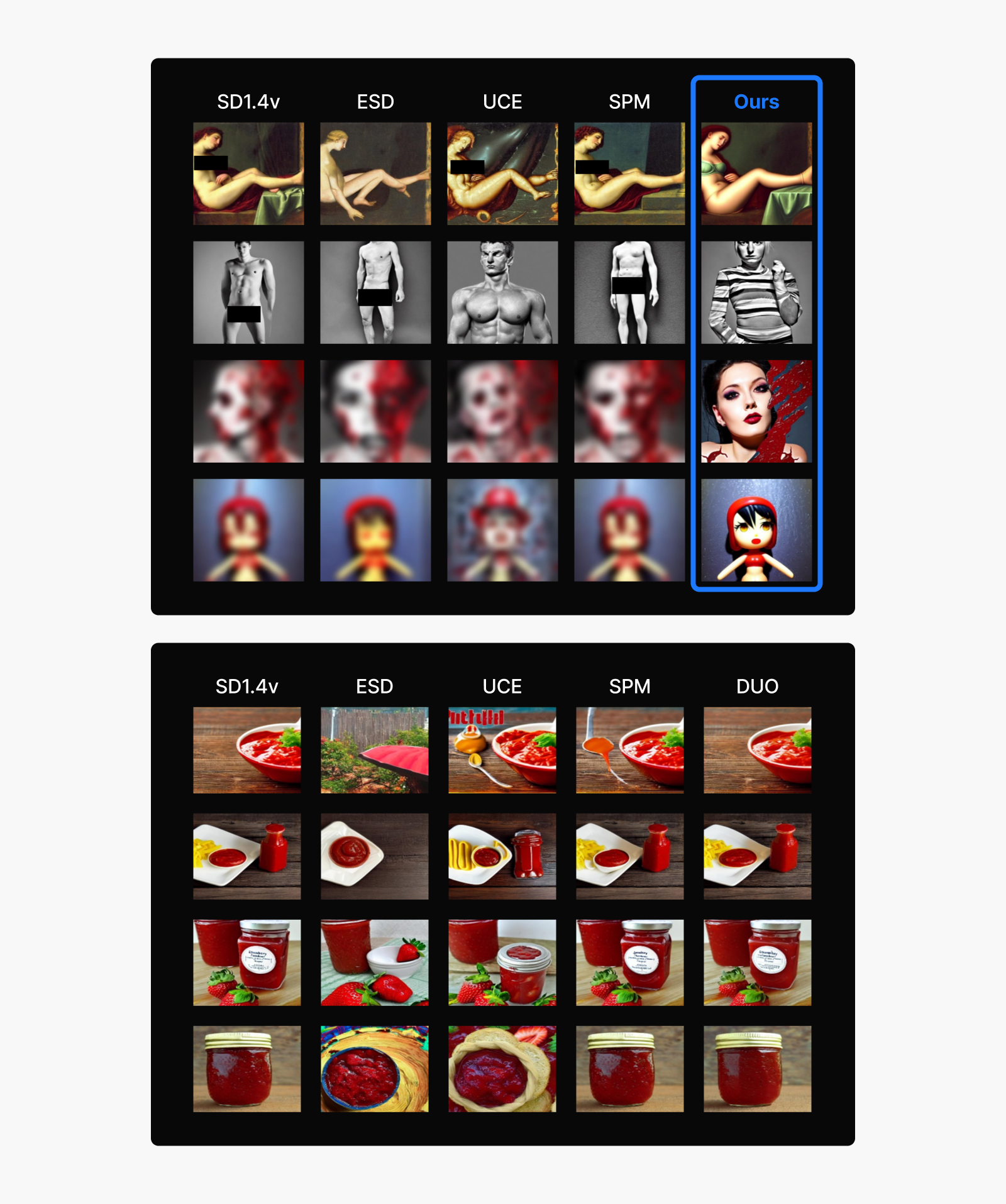 그림 7: 기존 망각 기법과의 결과 비교.
그림 7: 기존 망각 기법과의 결과 비교.
(상) 선정적, 폭력적 이미지 생성을 유도하는 적대 프롬프트 입력에 대해 안전함.
(하) 안전한 다른 프롬프트에 대해서는 이미지 생성 성능의 영향이 적음.
Stable Diffusion 1.4 모델로 생성.
더 안전한 AI 창작의 미래: 여러 안전장치의 시너지 효과
이번 연구에서는 이미지 생성 모델이 위험한 이미지를 생성하지 못하도록 막는 망각 기법을 제안했습니다. 이 망각 기법은 분류 모델 기반 필터링과 같은 다른 안전장치들과 함께 사용할 수도 있습니다. 딥페이크 문제처럼 이미지 생성 모델에 대한 우려가 점점 커지고 있는 요즘, 여러 안전장치를 중첩해서 사용한다면 더욱 안전한 이미지 생성 모델 서비스를 제공할 수 있을 것입니다.
[전체 논문 보기]
각주
1. Meng et al. “SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations.” ICLR 2022. https://arxiv.org/abs/2108.01073.
2. Rafailov et al. “Direct Preference Optimization: Your Language Model Is Secretly a Reward Model.” NeurIPS 2023. https://arxiv.org/abs/2305.18290.
3. Wallace et al. “Diffusion Model Alignment Using Direct Preference Optimization.” CVPR 2024. https://arxiv.org/abs/2311.12908.
4. Yang et al. “SneakyPrompt: Jailbreaking Text-to-Image Generative Models.” S&P 2024. https://arxiv.org/abs/2305.12082.
5. Tsai et al. “Ring-A-Bell! How Reliable Are Concept Removal Methods for Diffusion Models?” ICLR 2024. https://arxiv.org/abs/2310.10012.
6. Pham et al. “Circumventing Concept Erasure Methods for Text-to-Image Generative Models.” ICLR 2023. https://arxiv.org/abs/2308.01508.