
“네이버는 왜 이런 거 못 만듭니까?”
지난 5월, 한 유튜브 방송에서 누군가 이 질문을 던졌습니다. ‘왜 네이버는 NotebookLM 같은 건 못 만드냐’라는 도발적인 한마디. 이어진 대답은 “기술이 없어서가 아니라 리소스 우선순위에서 밀렸을 뿐”이었지만, 네이버 Audio LLM 팀은 억울함과 아쉬움이 뒤섞인 복잡한 감정을 느꼈습니다. 우선순위에서 밀린 건 맞지만, 이미 준비하고 있던 기술이기 때문이죠.
그래서 결심했습니다. “시간을 쪼개서라도, 우리가 가진 기술을 제대로 보여주자.”
그렇게 PodcastLM 프로젝트가 시작됐습니다. 지금부터 그 과정을 보여드릴게요.
Step 1: 자연스러운 대화 데이터를 어떻게 확보할까?
사람처럼 말하는 AI를 만들려면 먼저 고품질의 음성 대화 데이터를 모아야 합니다. 이를 위해 두 가지 방식을 사용했습니다.
- 대화를 직접 녹음하기
두 명의 팀원이 마주 앉아 실제 팟캐스트처럼 1:1 대화를 나눴습니다. 서로의 음성이 섞이지 않도록 각자의 채널로 분리해 녹음했고, 어색함도 잠시 대화가 이어질수록 몰입감은 더 깊어졌습니다. - 기존 콘텐츠에서 음성 추출하기
유튜브나 팟캐스트에 이미 출연 경험이 많은 분들은 새로 녹음할 필요가 없었습니다. 기존 영상에서 목소리만 깔끔하게 추출해 사용했죠.

[그림 1. 데이터 준비 프로세스]
하지만 아무 음성이나 사용할 수는 없었습니다. 데이터는 다음 기준을 만족해야 했어요.
- 한 사람의 목소리만 포함될 것
- 배경음이나 효과음, 겹치는 발화가 없을 것
- 음질은 가급적 고품질일 것
- 텍스트와 정확히 매칭될 것
이렇게 정제된 데이터를 팀원들이 나눠 정리하고, Audio LLM 학습에 활용했습니다.
Step 2: Voice Engine, 진짜처럼 말할 수 있을까?
이론상 가능하지만, 현실에선 첫 시도였습니다. 일반인의 자유 대화 데이터를 기반으로 Voice Engine을 학습시킨 건 처음이었기 때문이죠.
결과는 기대 이상이었습니다. 발음, 억양, 말투, 숨소리까지 실제 사람처럼 자연스럽게 구현됐기 때문이죠.
텍스트를 음성으로 변환하는 기술 자체는 새로운 개념이 아닙니다. 그러나 네이버의 Voice Engine이 한 차원 높은 품질의 음성을 구현할 수 있었던 이유는, 그동안 지속적으로 축적해 온 HyperCLOVA X Audio, Voice Model, UnitBIGVGAN 등 핵심 기반 기술이 견고하게 받쳐주었기 때문입니다. 겉으로 보기엔 단순한 ‘말하는 AI’처럼 보일 수 있지만, 그 이면에는 정교하게 설계된 여러 기술이 조용히 제자리를 지키며 각자의 역할을 충실히 수행해 온 것이죠.
 [그림 2. AI 음성을 구현하는 핵심 모델 및 역할]
[그림 2. AI 음성을 구현하는 핵심 모델 및 역할]
HyperCLOVA X Audio는 네이버 음성 AI 기술의 기반이 되는 백본(Backbone) 모델로, 기초적인 음성 언어 능력을 담당합니다. 백본은 자동차의 엔진에 비유할 수 있는데요, 엔진이 좋아야 차가 잘 달리듯, 백본이 강력할수록 다양한 작업에서 우수한 성능을 발휘할 수 있습니다.
Voice Model은 HyperCLOVA X Audio와 Voice Engine을 연결해 주는 중간 다리 역할을 합니다. 두 모델 간의 부족한 부분을 꼼꼼하게 메워, 전체 시스템을 더욱 견고하게 만들어 줍니다.
PodcastLM의 주인공 격인 Voice Engine은 감정, 숨소리, 억양까지 자연스럽게 표현할 수 있는 고도화된 TTS (Text-to-speech) 모델입니다.
마지막으로, UnitBIGVGAN은 Voice Engine이 생성한 목소리 토큰을 실제 음성 신호로 변환해 오디오 형태로 출력하는 역할을 합니다.
Step 3: 팟캐스트 나와라, 뚝딱!
하지만 PodcastLM은 단순히 Voice Engine만으로 완성된 프로젝트가 아니었습니다. 또 하나 중요한 요소가 있었죠. 바로 AI가 읽어줄 ‘대본’을 어떻게 만들 것인가였습니다. 사용자가 문서나 텍스트를 입력하면, LLM이 이를 분석해 실제 사람이 말하듯 자연스럽고 술술 읽히는 대본을 생성해야 했습니다.
여기서 핵심은 바로 프롬프팅(Prompting)입니다.
프롬프트에는 AI가 쉽게 이해하고 따라올 수 있도록 명확한 지시어(Instruction)를 담는 것이 중요하며, 동시에 사람의 말투처럼 자연스럽게 느껴지도록 설계해야 합니다. 이를 위해 Voice Engine의 실제 발화 스타일을 샘플로 프롬프트에 함께 넣는 방식을 사용했는데요, 이렇게 하면 대본이 훨씬 더 자연스러워집니다.
수많은 테스트를 거쳐 프롬프트를 정교하게 다듬었고, 이렇게 완성된 대본이 Audio LLM과 결합하면서 마침내 실제로 사람들이 말을 주고받는 듯한, 진짜 같은 팟캐스트가 탄생할 수 있었습니다.
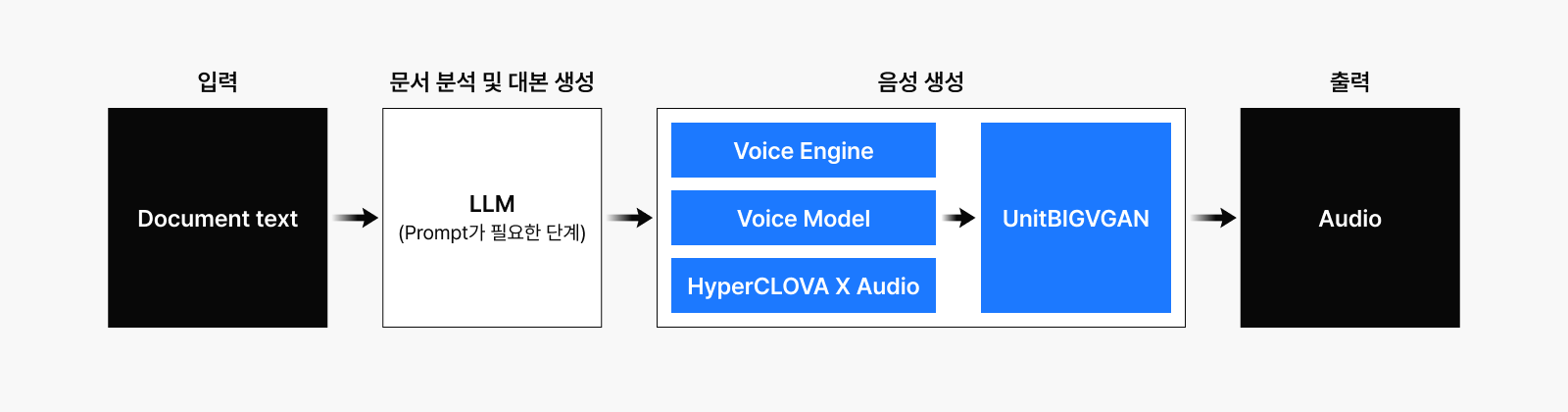
[그림 3. PodcastLM 구조도]
팀네이버는 해냈고, 해낼 것이다.
이번 PodcastLM 프로젝트는 단순한 기술 실험이 아니었습니다. 네이버가 가진 음성 생성 기술의 저력을 증명한 상징적인 프로젝트입니다. 누구보다 사용자 친화적인 AI를 만들기 위한 도전이자, 가능성의 서막이었죠.
하지만 이건 시작일 뿐입니다. 저희의 궁극적인 목표는 단순히 텍스트를 음성으로 바꾸는 기술을 넘어서 사람처럼 대화할 수 있는 지능형 Voice Agent를 만드는 것입니다. 문맥을 이해하고 감정을 파악하며, LLM의 추론 능력까지 더해진 더 인간적인 Multimodal Agent를 통해 AI와의 대화가 지금보다 훨씬 자연스럽고 따뜻해질 수 있을 거라 믿습니다.
이제는 기술을 얼마나 잘 만드느냐보다 그 기술이 어떻게 쓰이느냐가 더 중요한 시대입니다. 앞으로도 기술 중심이 아닌 사용자 경험 중심에서 고민하며, 우리의 정서와 문화, 일상에 자연스럽게 녹아드는 팀네이버만의 AI 경험을 만들어가겠습니다.
Podcast로 들어보기
아래 오디오는 본문 내용을 기반으로 PodcastLM 시스템을 통해 자동 생성되었습니다.
AI 호스트와 패널이 대화 형식으로 내용을 자연스럽게 전달하며, 사용된 음성은 네이버 문학범 님과 네이버클라우드 이주현 님의 실제 목소리를 기반으로 구현되었습니다.