
세상은 끊임없이 움직이고 우리의 시각은 그 장면들을 실시간으로 포착합니다. 영상은 단순한 이미지의 나열이 아닌, 시간의 흐름 속에서 전개되는 이야기가 모여 이루어집니다. HyperCLOVA X는 이제 이 움직이는 세상을 이해하고자 합니다.
HyperCLOVA X Video로 나아가면서, 우리는 이미지 이해를 넘어 복잡한 시공간 속의 상호작용과 변화를 포착할 수 있습니다. 이는 마치 영화의 기적을 경험하는 것처럼, 기계가 시간 속에서 일어나는 사건들을 면밀히 분석하고 이해하는 능력을 갖추게 되는 것을 의미합니다. 팀네이버는 이러한 성과를 이루기 위해 다양한 영상 데이터와 최신 AI 기술을 결합하여, 새로운 지평을 열고 있습니다.
이전에 소개해 드린 ‘HyperCLOVA X Vision: 눈을 뜨다‘에 보내주신 뜨거운 관심에 힘입어, 이번 글에서는 HyperCLOVA X Video가 어떻게 시간에 따라 변화하는 연속적인 장면들을 이해하고 어떤 혁신을 구현하는지 살펴보겠습니다.
[관련 내용 – ‘HyperCLOVA X Vision: 눈을 뜨다‘ 보러 가기]
HyperCLOVA X Video 기술 소개
HyperCLOVA X Video는 기존의 VLM(Vision-Language Model) 구조를 바탕으로, 영상의 다이나믹한 특성을 효과적으로 이해하기 위해 설계된 모델입니다. 프레임 속에서 펼쳐지는 복잡한 이야기와 상호작용을 보다 능동적으로 분석할 수 있도록 진화하여 다양한 영상 데이터에서 풍부한 시나리오를 학습했습니다. HyperCLOVA X Video는 장면 인식을 넘어선 깊이 있는 이해를 제공합니다. 효율적인 아키텍처를 구축하여, 장면의 전환, 움직임의 흐름, 그리고 그에 따른 맥락 변화를 자원 효율적으로 정확하게 포착할 수 있습니다.
네이버는 이미지 처리에서 쌓아온 전문성과 데이터를 바탕으로 영상 내의 멀티모달 정보를 하나로 통합할 수 있는 능력을 HyperCLOVA X Video에 적용하였는데요. 영상 속 다양한 시각적 요소를 통합적으로 처리하여 보다 사실적이고 정교한 이해를 구현했습니다. 특히, 한국어 기반의 비디오에서 뛰어난 성능을 발휘할 수 있는 모델로 자리 잡았습니다. 이제 교육, 콘텐츠, 보안 등 다양한 분야에서 그 잠재력을 발휘하며, 우리가 영상 속에서 보고 듣는 모든 것을 새로운 시각으로 해석할 수 있는 길을 열어가고 있습니다.
HyperCLOVA X Video의 능력
HyperCLOVA X Video의 다양한 능력을 소개합니다. 이전에는 단일 이미지 분석만 가능했던 기능들이 이제 동영상에서도 작동하는 것을 확인할 수 있었습니다. 아래에서 주요 분야별로 어떤 작업을 수행할 수 있는지 살펴보겠습니다.
1. 비디오 캡셔닝
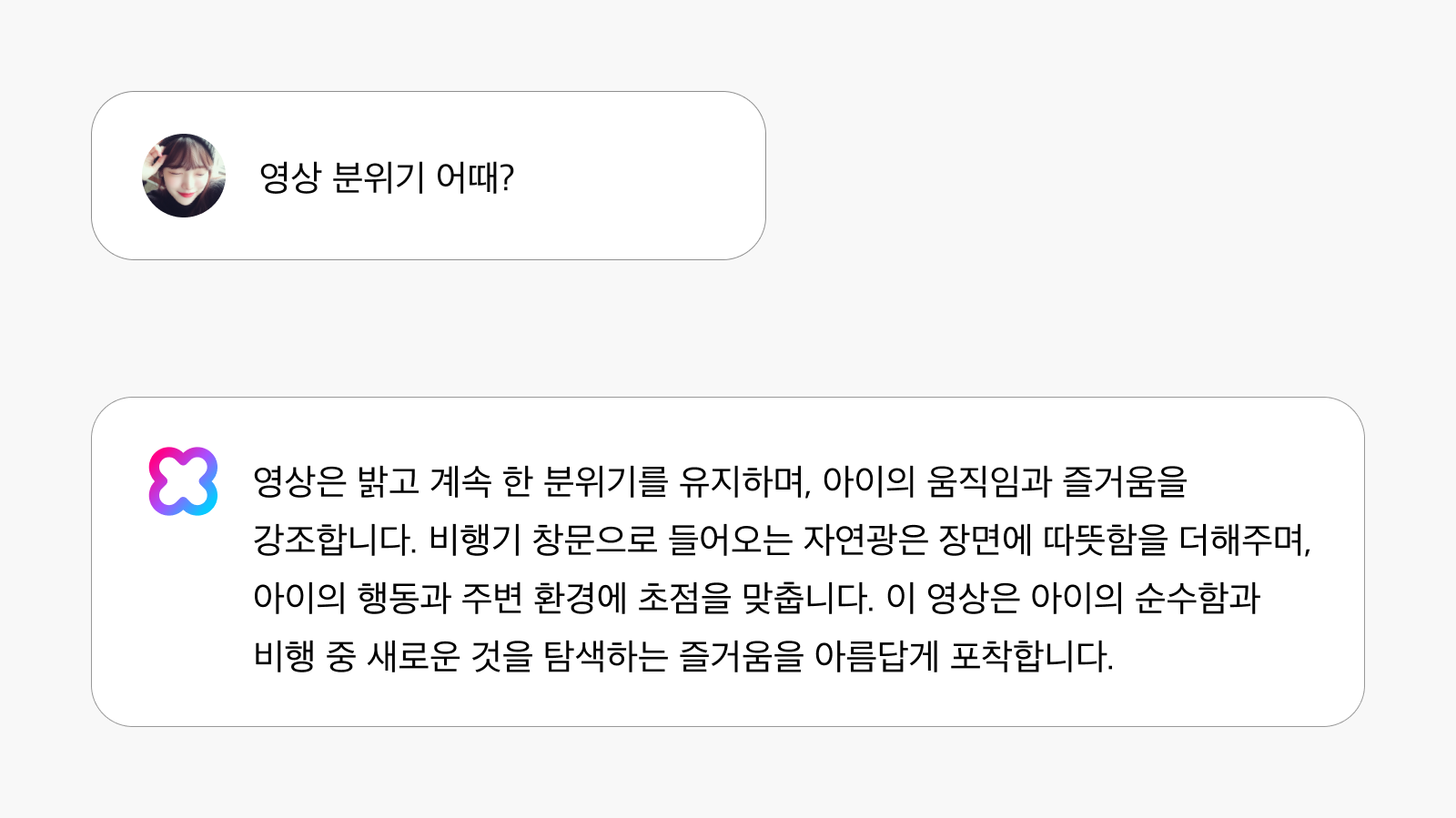
비디오 캡셔닝은 영상 콘텐츠의 내용을 상세하게 설명하는 텍스트를 생성하는 AI 기술입니다. 단순히 비디오에 등장하는 객체를 나열하는 것을 넘어 시간에 따른 행동, 사건, 상호작용 및 맥락을 포함하여 풍부하고 자연스러운 설명을 제공합니다.
{kind=link}
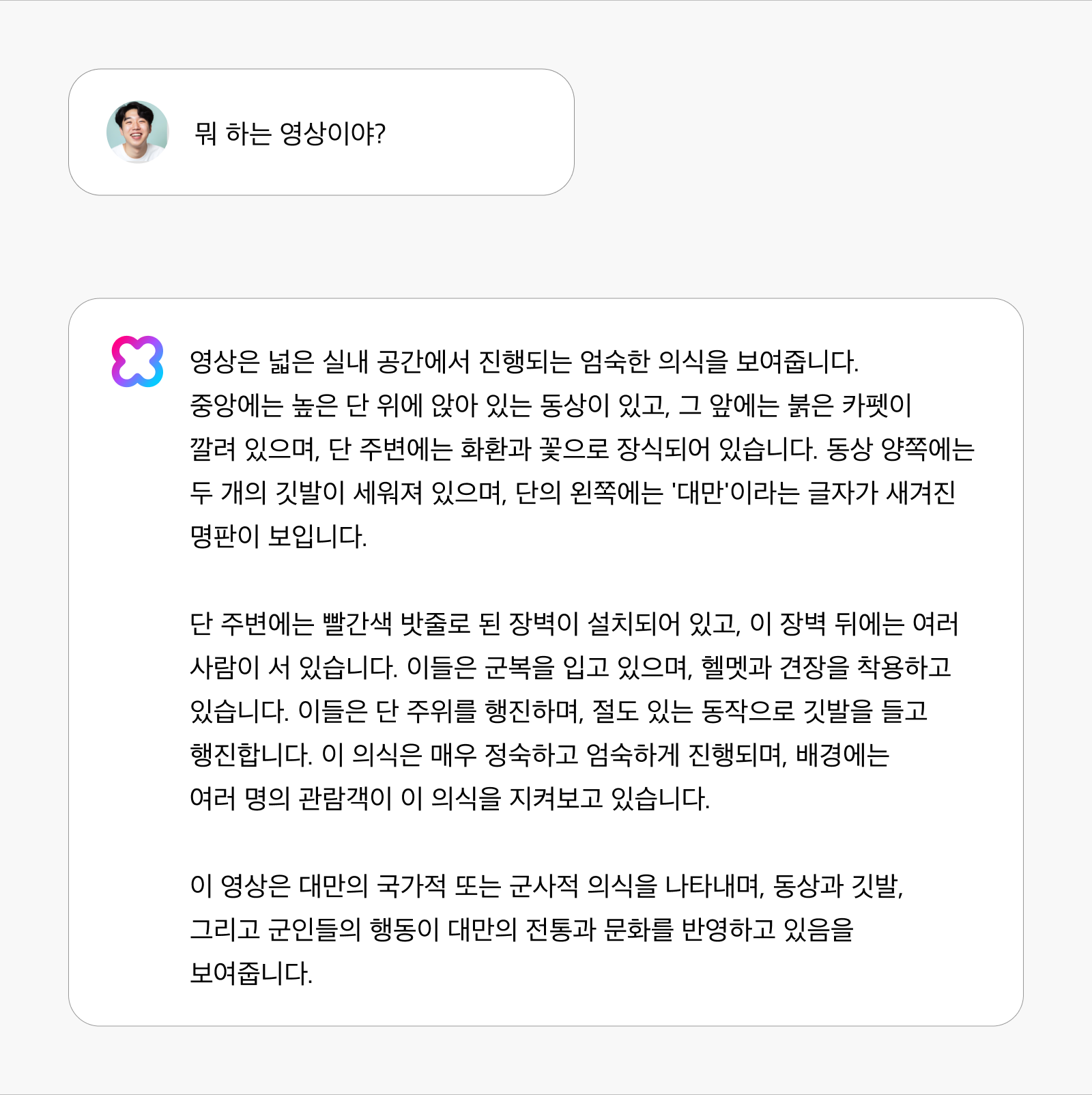
별도의 객체 인식 모델을 사용하지 않음에도 불구하고 비디오의 세세한 부분까지도 비교적 정확하게 인식하고 묘사할 수 있습니다. 예를 들어 특정 국가의 사회적 관습을 정확히 인식하고 설명할 수 있습니다. 아래의 영상을 보고 대만의 국가적 또는 군사적 의식을 나타내고 있다는 것을 정확히 설명하고 있습니다. 대만의 전통과 문화를 반영하고 있다는 것까지도 파악할 수 있어 문화적 상황에 대한 이해도가 높습니다.
2. 추론
HyperCLOVA X의 고유 능력을 활용하여 상황에 대해 추론하거나 다음 단계를 예측할 수 있습니다. 이 추론 능력으로 여러 동적인 변화를 직접적으로 이해할 수 있게 됩니다.
다음 행동 예측
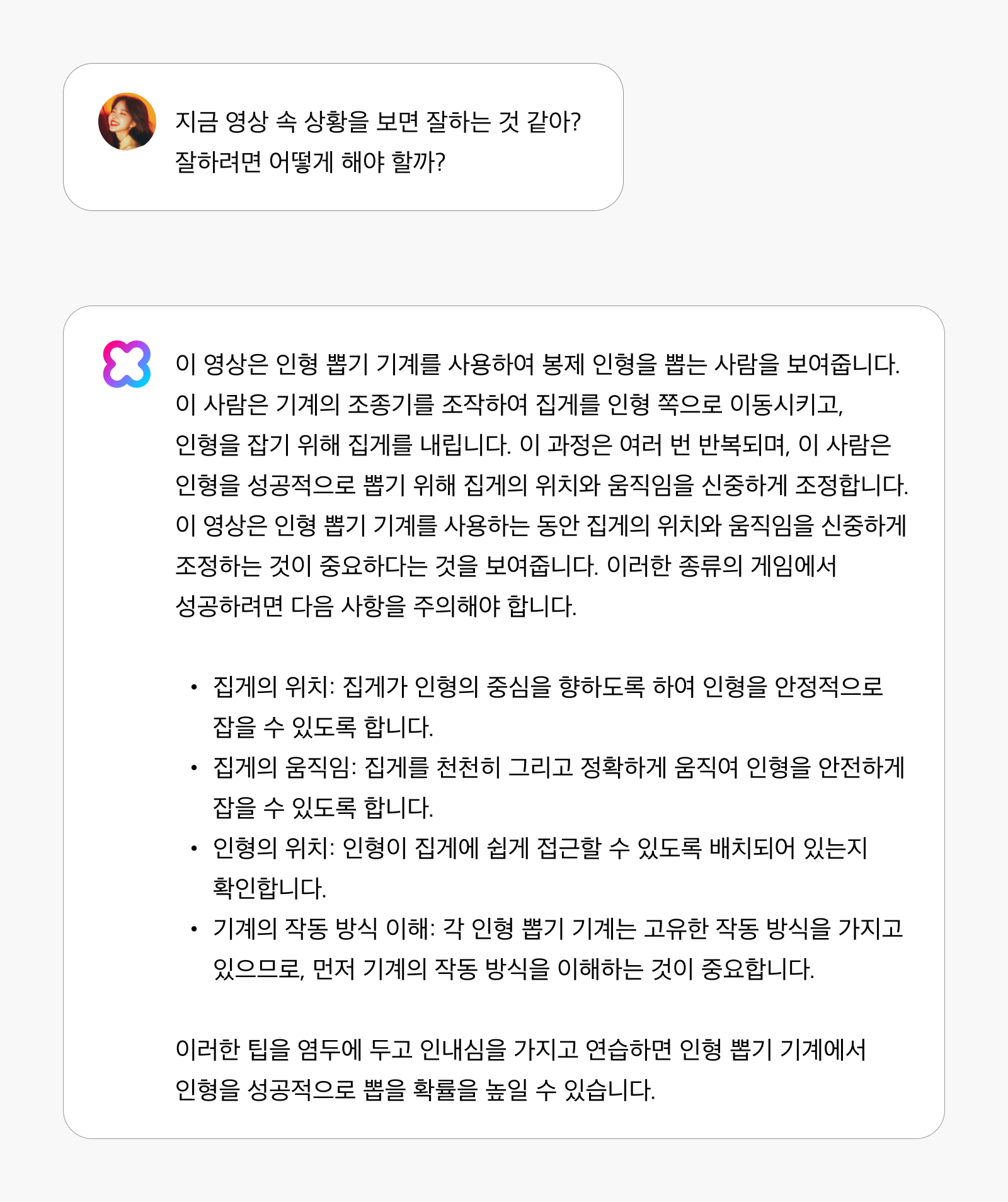
현재까지의 영상 내용을 분석하여 앞으로의 전개나 최적의 행동 방향을 예측합니다. HyperCLOVA X Video는 화면 속 행동을 관찰하는 것에서 한 걸음 더 나아가, 분석을 바탕으로 사용자에게 성공 확률을 높이는 구체적인 전략을 제시합니다.
예를 들어, “지금 영상 속 상황을 보면 잘하는 것 같아? 잘하려면 어떻게 해야 할까?”라는 질문에 게임에서 성공하기 위한 전략을 조언해 줄 수 있습니다.
의도 및 목적 추론
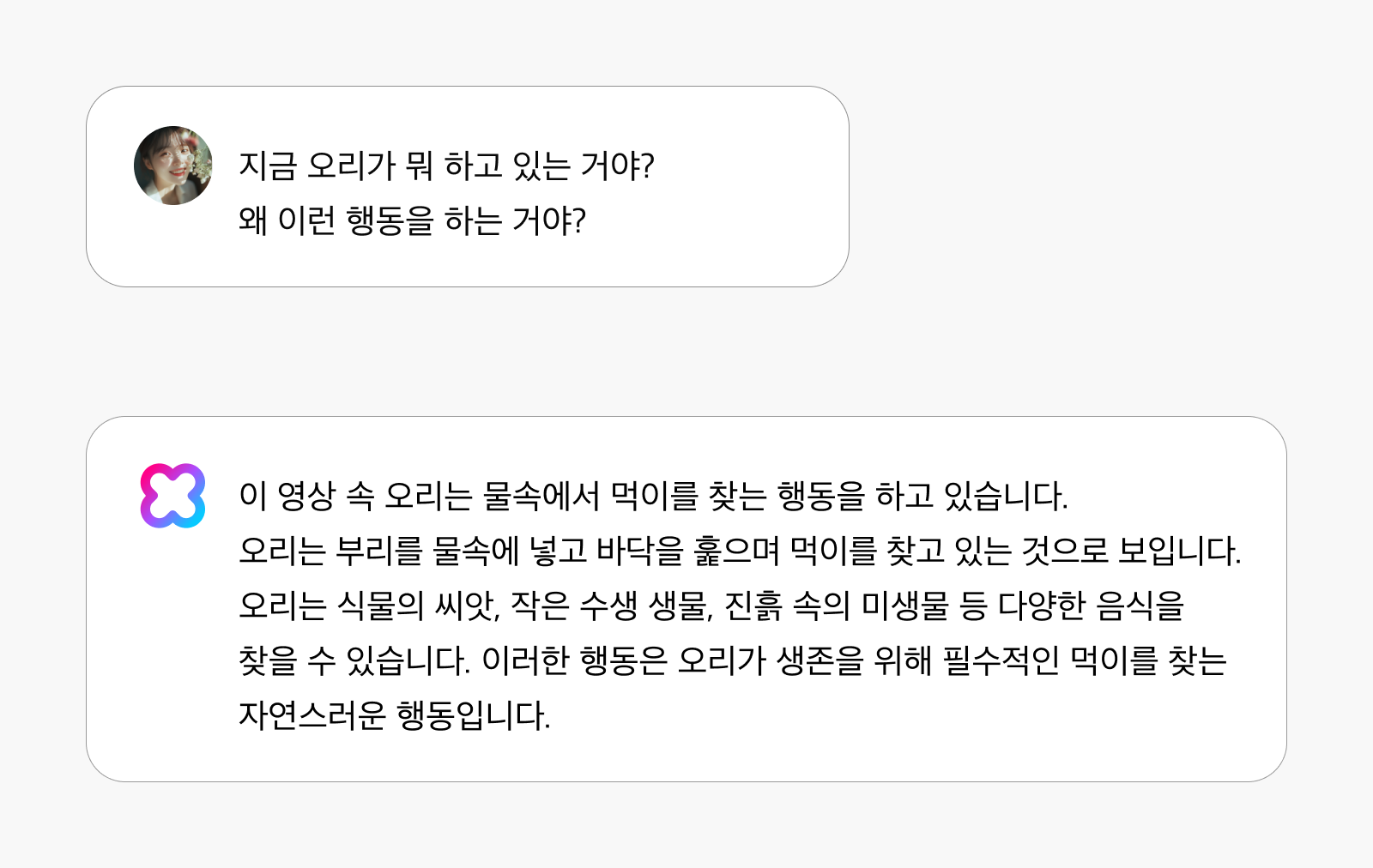
영상 속에 등장하는 생물이나 인물의 행동을 관찰하여 그들의 의도나 목적을 추론합니다. HyperCLOVA X Video는 겉으로 보이는 행동만 파악하는 것이 아니라, 그 행동의 이유와 본질적인 목적까지 이해합니다.
예를 들어, “지금 오리가 뭐 하고 있는 거야? 왜 이런 행동을 하는 거야?”라는 질문에 “이 영상 속 오리는 물속에서 먹이를 찾는 행동을 하고 있습니다. 오리는 부리를 물속에 넣고 바닥을 훑으며 먹이를 찾고 있는 것으로 보입니다. 오리는 식물의 씨앗, 작은 수생 생물, 진흙 속의 미생물 등 다양한 음식을 찾을 수 있습니다. 이러한 행동은 오리가 생존을 위해 필수적인 먹이를 찾는 자연스러운 행동입니다“라고 답변할 수 있습니다.
3. 개체 인식 (사람, 장소, 제품, 음식)
개체 인식 능력은 비디오 속에서 의미를 가진 다양한 요소들을 식별하고 이해하는 것을 의미합니다. HyperCLOVA X Video는 영상 속 세상을 마치 우리처럼 세밀하게 바라볼 수 있어요. 이 기술이 보여주는 놀라운 능력을 살펴보겠습니다:
장소 및 문화적 맥락 인식
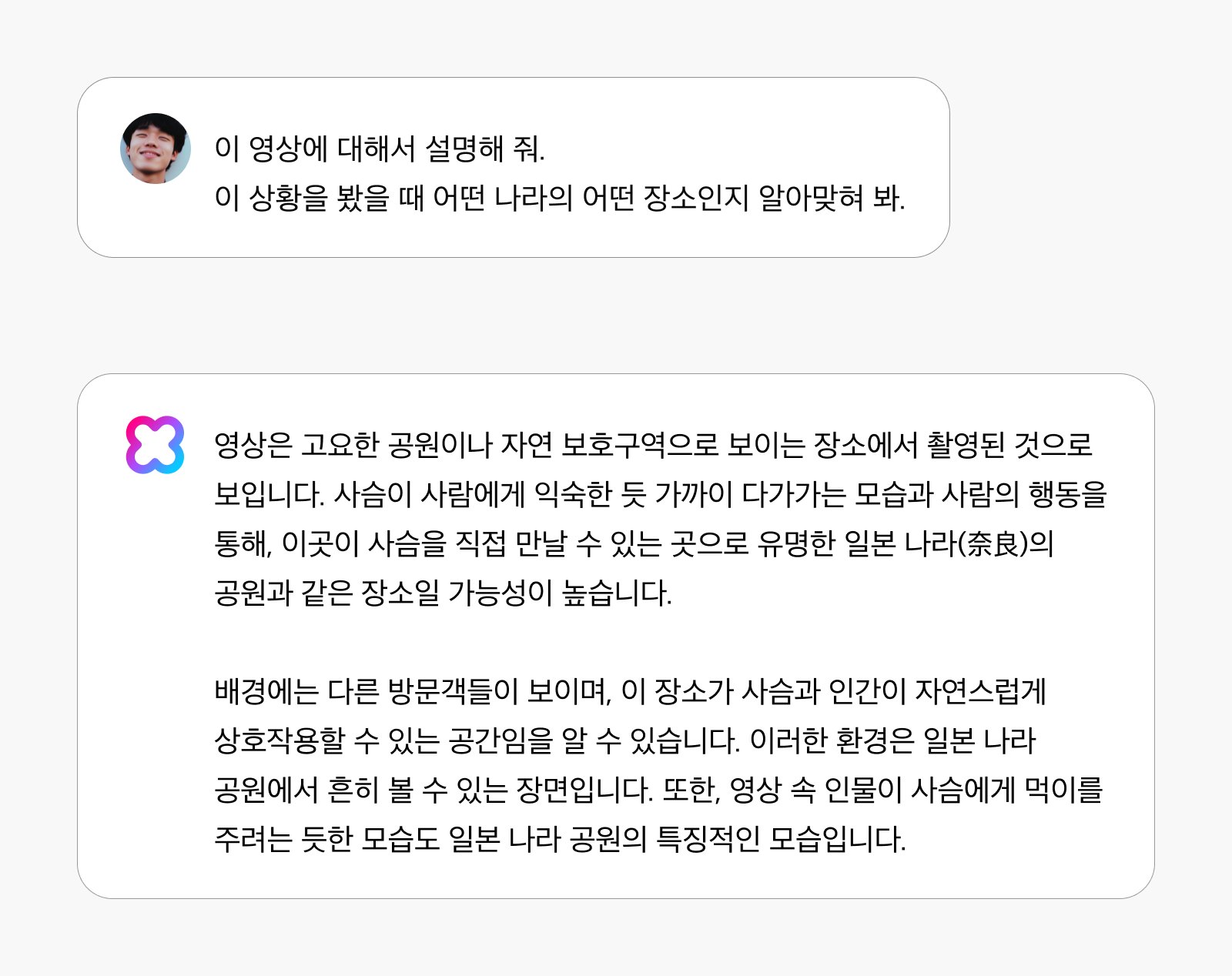
특정 장소나 환경의 문화적 특성을 인식하고 판별합니다. 예를 들어, “이 영상에 대해서 설명해 줘. 이 상황을 봤을 때 어떤 나라의 어떤 장소인지 알아맞혀 봐“라는 질문에 “이 영상은 고요한 공원이나 자연 보호구역으로 보이는 장소에서 촬영된 것으로 보입니다. 사슴이 사람에게 익숙한 듯 가까이 다가가는 모습과 사람의 행동을 통해 이곳이 사슴을 직접 만날 수 있는 곳으로 유명한 일본 나라(奈良)의 공원과 같은 장소일 가능성이 높습니다.”라고 답변할 수 있습니다. 영상 속 동물의 행동 패턴, 환경적 특징, 사람들의 상호작용 방식 등을 종합적으로 분석하여 구체적인 장소를 식별합니다.
랜드마크 및 관광지 인식
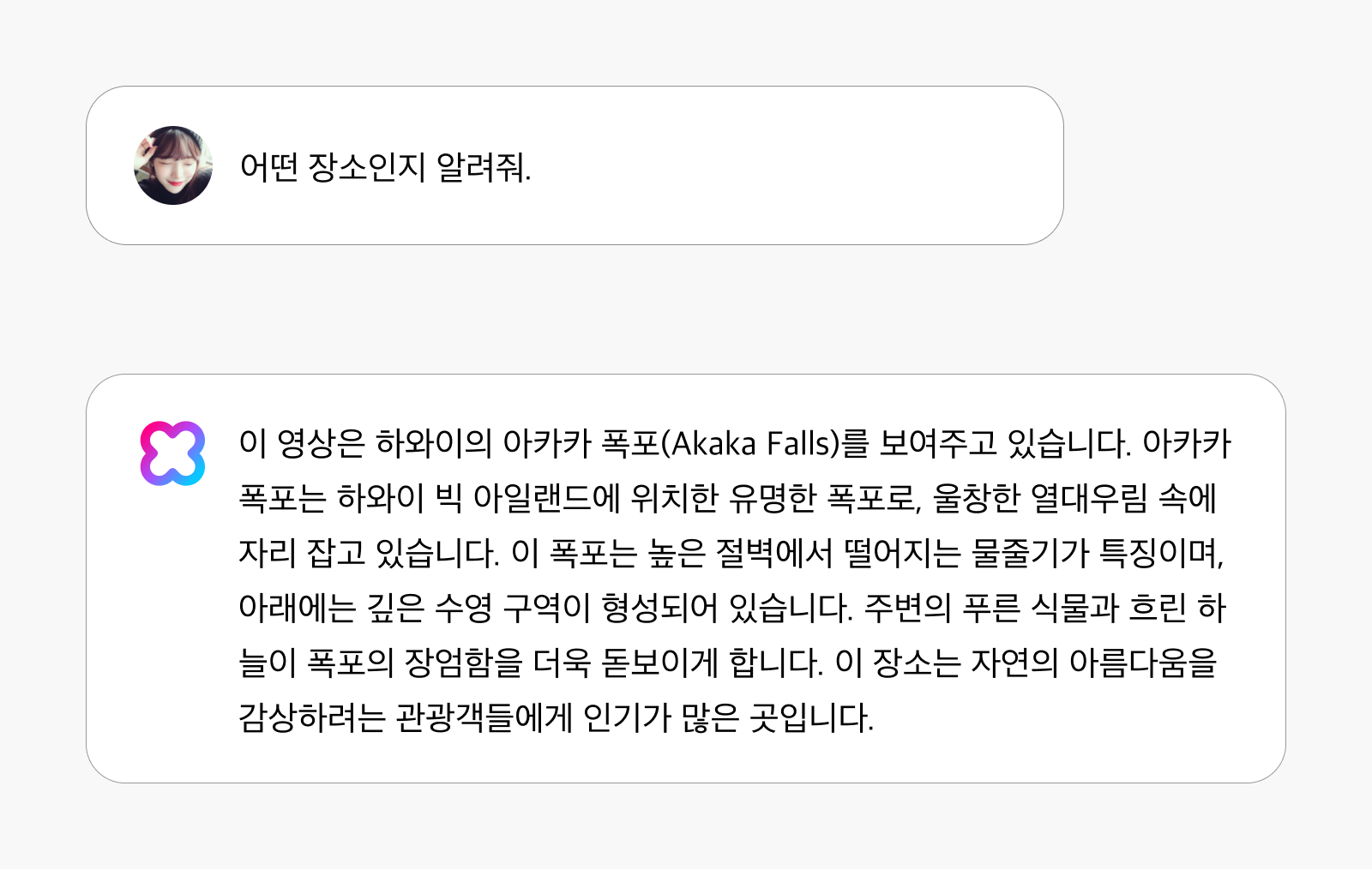
유명 건축물이나 관광지를 식별하고 관련 정보를 제공합니다. 영상 속 장소를 감지하며, 이름과 함께 역사적 배경, 문화적 의미, 특별한 가치까지 포괄적으로 설명해 줍니다. 마치 영상 속 여행지에 직접 가본 경험 많은 여행 가이드처럼, 장소에 얽힌 풍부한 맥락과 이야기를 들려줄 수 있습니다.
4. 공간 및 시간에 대한 이해
HyperCLOVA X Video는 영상 속 시간과 공간을 정확히 파악하는 능력을 갖추고 있어 다양한 실무 환경에서 실질적인 가치를 제공합니다.
영상 속 시간 파악
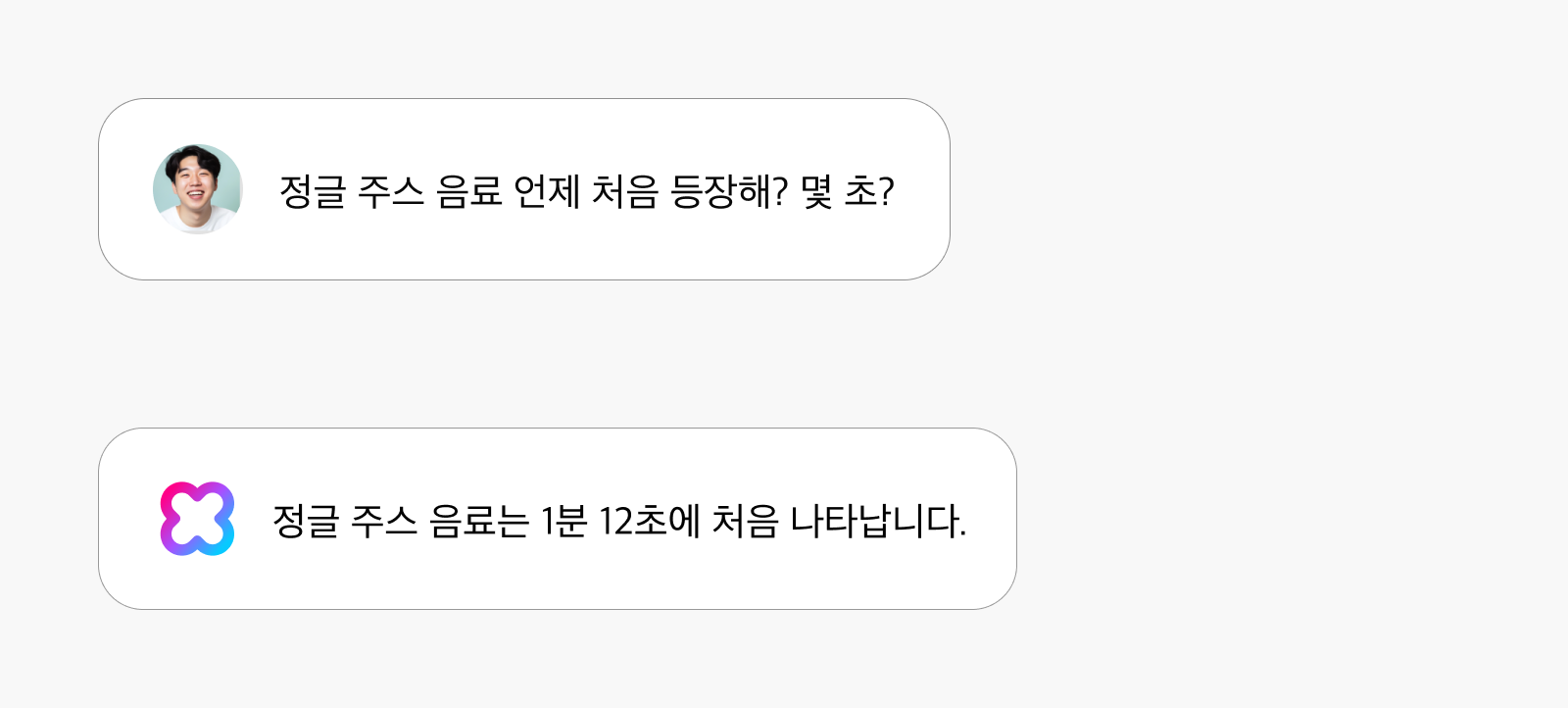
영상 속에서 특정 장면이나 순간을 찾는 일은 시간이 오래 걸리는 작업인데요, HyperCLOVA X Video는 이런 수고를 덜어줍니다. 긴 영상에서 특정 객체, 인물, 행동이 등장하는 정확한 지점을 찾아주기 때문이죠. 예를 들어, “정글 주스 음료 언제 처음 등장해? 몇 초?”라는 질문에 “정글 주스 음료는 1분 12초에 처음 나타납니다.”라고 정확하게 답변할 수 있습니다. 이 능력은 콘텐츠 검색, 편집, 타임스탬프 생성 등에 유용하게 활용됩니다.
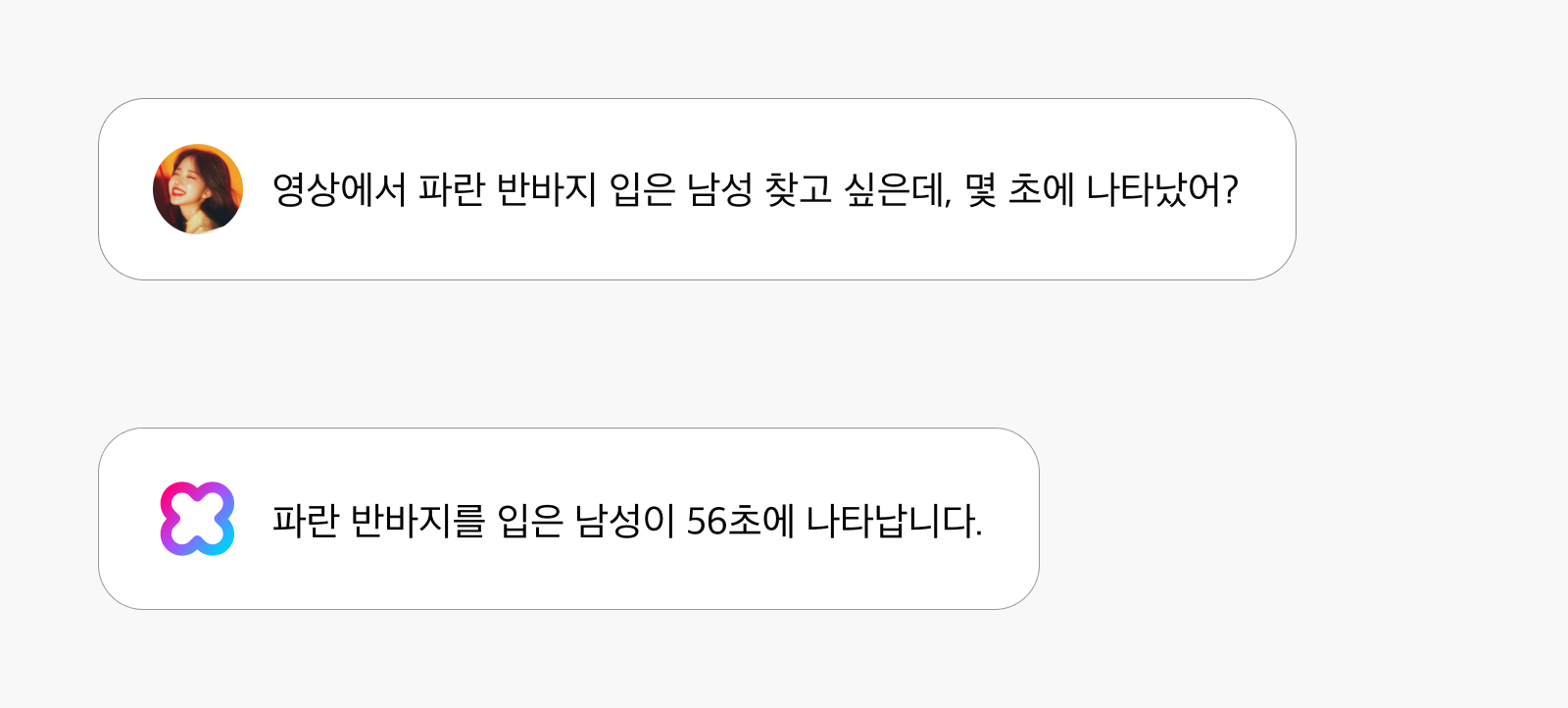
“영상에서 파란 반바지 입은 남성 찾고 싶은데, 몇 초에 나타났어?”라는 질문에 “파란 반바지를 입은 남성이 56초에 나타납니다.”라고 답변할 수 있습니다. 이는 대용량 영상에서 필요한 장면을 빠르게 찾아내는 데 도움이 됩니다.
영상 속 시간을 정확히 찾아내는 이 기능으로 어떤 분야의 전문가들에게 도움이 될지 살펴볼까요? 먼저, 콘텐츠 제작자들의 일이 훨씬 편해질 거예요. 이제 긴 영상을 처음부터 끝까지 들여다볼 필요 없이, 원하는 장면이 어디 있는지 금방 찾아낼 수도 있죠. 마케팅 담당자들도 광고 속 브랜드 노출 시간을 정확히 파악해 광고 효과를 더 정확하게 분석할 수 있어요. 행동 연구를 하는 연구자라면, 특정 행동이 발생하는 순간을 자동으로 기록해 분석의 정확도를 높일 수 있답니다.
다공간적 맥락 이해
이 능력은 시간 위치 파악을 넘어 공간적 맥락까지 이해할 수 있습니다. “영상 편집을 하려고 하는데, 아기가 기어서 다시 돌아가는 구간을 찾고 싶어. 몇 초부터 아기가 다시 기어가?”라는 질문에 “아기가 다시 기어가기 시작하는 구간은 8초부터입니다.”라고 답할 수 있습니다. 이는 아기의 이동 방향 변화와 공간적 위치 변화를 파악했기에 가능한 답변입니다.
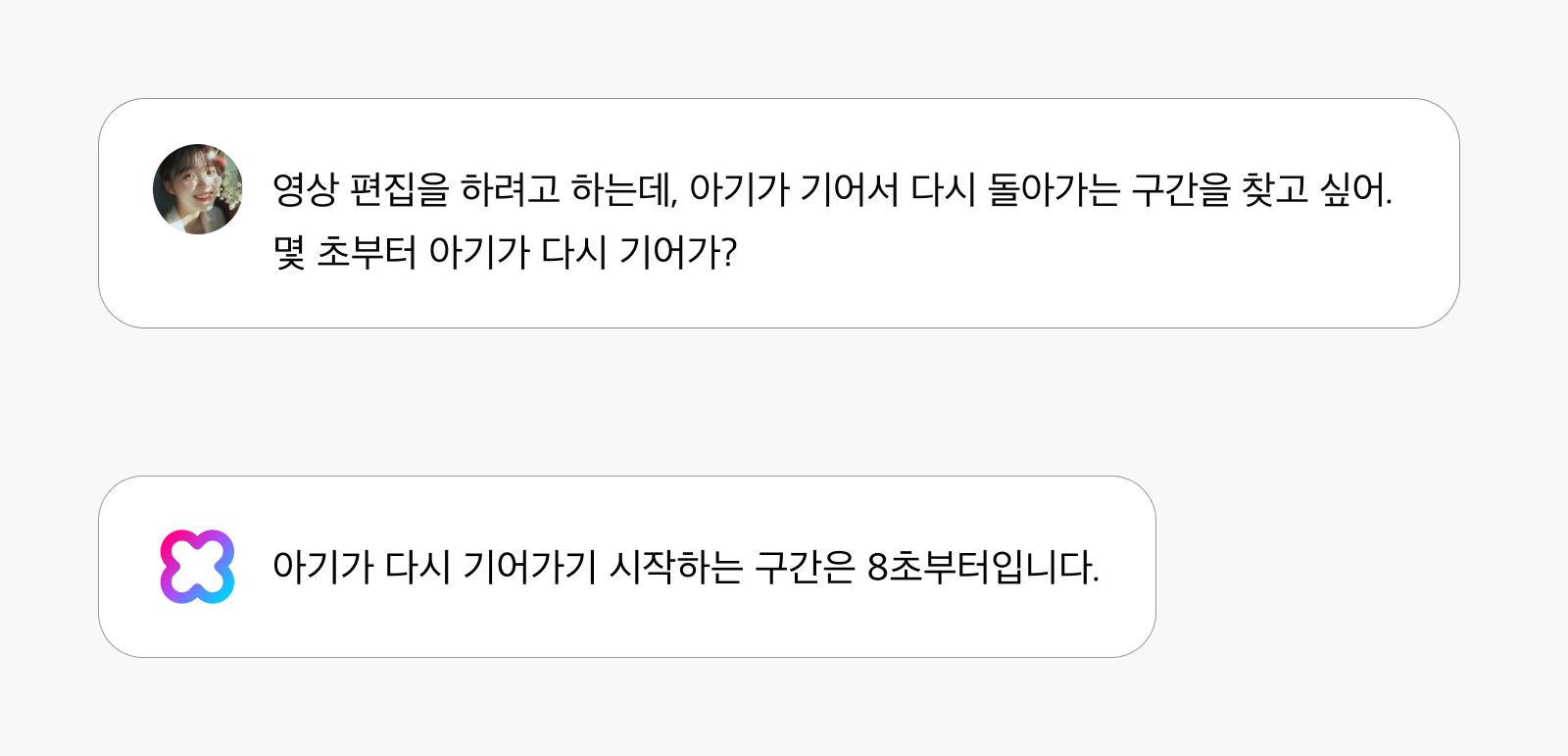
이러한 시공간을 통합한 이해 능력은 영상 편집자의 스토리텔링, 건축가의 공간 분석, 자율주행 시스템 개발 등 다양한 분야에서 응용이 가능합니다. 특히 보안 시스템에서는 특정 공간에서의 움직임 패턴을 인식하여 이상 행동을 감지하는 데 활용될 수 있으며, 스포츠 분석에서는 선수들의 공간 점유율과 이동 경로를 자동으로 추적하는 데 사용될 수 있습니다.
5. 영상으로 새로운 이야기 만들기
HyperCLOVA X Video는 영상을 분석할 뿐만 아니라, 영상을 바탕으로 완전히 새로운 창작물을 만들어내는 재능도 가지고 있습니다.
영상에서 영감을 얻은 창작물 생성
분석이나 인식에서 나아가, 영상을 창의적 영감의 원천으로 활용하여 완전히 새로운 콘텐츠를 만들어낼 수 있습니다. “내가 찍은 브이로그인데, 음성 내레이션을 넣고 싶어. 이 비디오를 보고 내레이션을 작성해 줄 수 있어?”라는 요청에 일반적인 장면 묘사가 아닌, 감성적이고 이야기가 있는 내레이션을 제작합니다.
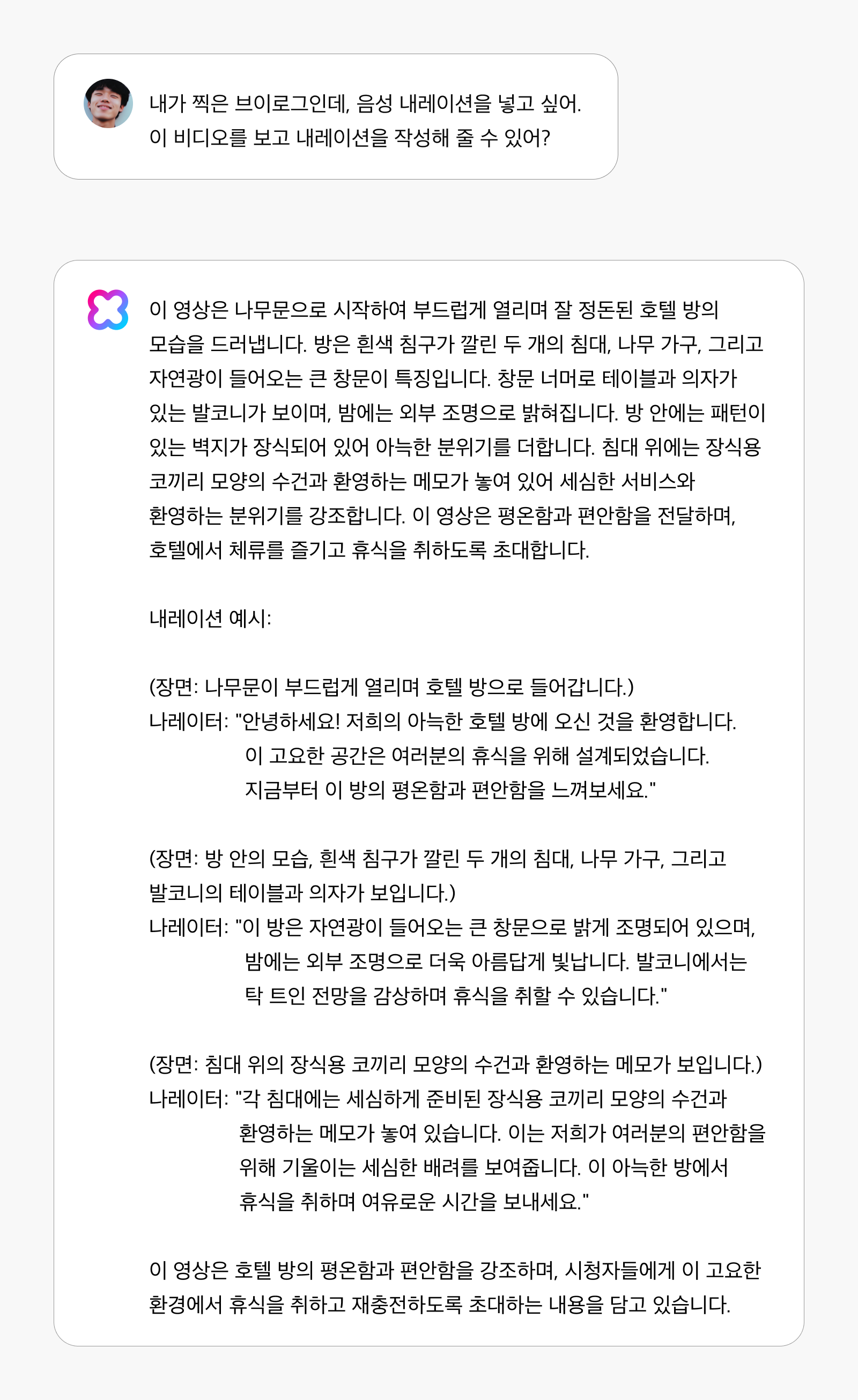
이는 앞서 설명한 인식 및 분석 기능들과 달리, AI가 ‘해석‘과 ‘창작‘의 영역으로 확장되었음을 보여줍니다. 여행 영상에서 시적인 여행 에세이를 작성하거나, 일상 순간에서 감성적인 스토리를 만들어내는 등 인간의 창의적 영역에서 협업 파트너로 기능합니다. 또한 영상의 감정, 분위기, 스타일을 읽어내 어울리는 배경 음악을 골라주거나, 영상에 딱 맞는 홍보 문구를 만들어주는 등 콘텐츠 제작자들의 실질적인 작업 시간을 줄여줄 수 있습니다.
덕분에 크리에이터들은 반복적인 작업에서 벗어나 더 핵심적인 창작 활동에 집중할 가능성이 열리게 되죠. HyperCLOVA X Video가 가진 창작 능력은 콘텐츠 제작 현장에서 크리에이터들이 일하는 방식을 더 효율적으로 바꾸는 데 기여할 것으로 기대됩니다.
지금까지 HyperCLOVA X Video의 다양한 능력들을 살펴보았습니다. 비디오 캡셔닝부터 추론, 개체 인식, 공간 및 시간 이해, 창의적 응용에 이르기까지 각 영역에서 보여주는 성능은 실제 업무와 일상에서 다양한 가능성을 열어줍니다. 이러한 능력을 객관적으로 측정할 수 있는 지표는 무엇일까요?
HyperCLOVA X Video 정량 지표
이제 HyperCLOVA X Video의 성능을 수치로 확인해 보겠습니다. 팀네이버는 내부적으로 40개 이상의 다양한 지표를 통해 모델의 성능을 꼼꼼히 추적하고 있는데요, 여기서는 여러분이 쉽게 이해하실 수 있도록 두 가지 핵심 벤치마크를 중심으로 소개해 드리겠습니다.
먼저 글로벌 표준이라 할 수 있는 공개 벤치마크에서의 성능입니다. 특히 OpenAI의 GPT-4V와 직접 비교가 가능한 지표들을 중심으로 살펴보겠습니다.
Public Benchmarks
| GPT-4V | HyperCLOVA X Video | ||
| VideoMME | 59.9 | 61.4 | |
| ActivityNet-QA | 57 | 55.2 | |
| MVBench | AC | 39 | 38.5 |
| AL | 40.5 | 44.5 | |
| AP | 63.5 | 68 | |
| CO | 52 | 72 | |
| CI | 11 | 46 | |
| EN | 31 | 35.5 | |
| FP | 47.5 | 43.5 | |
| MA | 22.5 | 72.5 | |
| MC | 12 | 44 | |
| MD | 12 | 34 | |
| OI | 59 | 68.5 | |
| OS | 29.5 | 36 | |
| ST | 83.5 | 93 | |
| SC | 45 | 63.5 | |
| UA | 73.5 | 84 |
Private Benchmark (네이버TV CLIP 이해) 성능
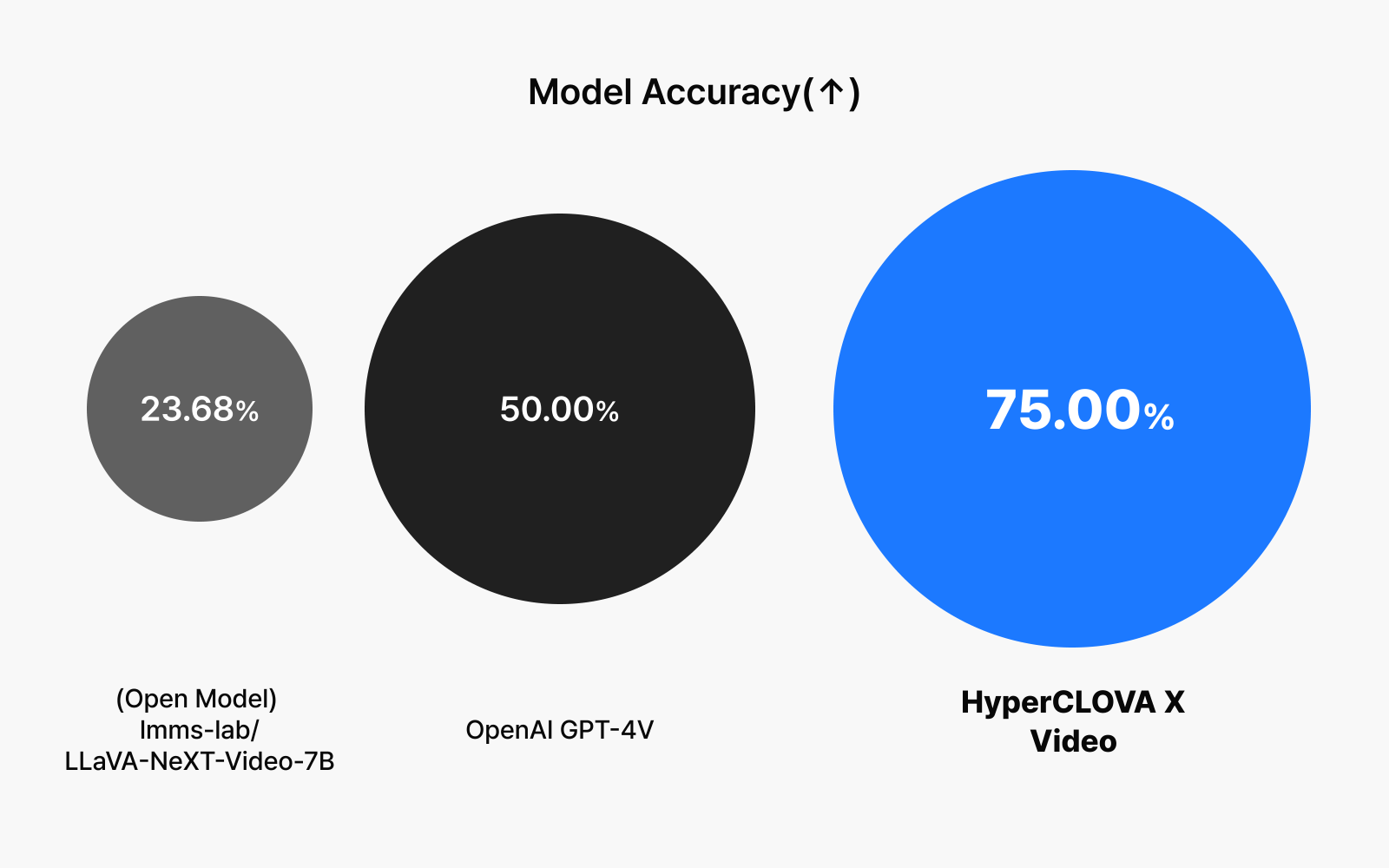
| Model | Accuracy (↑) |
| (Open Model) lmms-lab/LLaVA-NeXT-Video-7B | 23.68% |
| OpenAI GPT-4V | 50.0% |
| HyperCLOVA X Video | 75.00% |
한국 콘텐츠에 특화된 모델의 강점을 제대로 평가하기 위해, 네이버 TV의 다양한 클립 영상을 대상으로 고난도 벤치마크를 수행했습니다. 그 결과 HyperCLOVA X Video는 75%라는 높은 정확도를 기록하는 뛰어난 성과를 보였습니다. 이러한 결과는 HyperCLOVA X Video 모델이 앞으로 네이버 내외의 다양한 한국 콘텐츠 처리와 이해에 탁월한 강점을 발휘할 수 있음을 보여줍니다. 앞으로도 팀네이버는 올해 상반기에 걸쳐 모델의 성능을 점진적으로 향상할 계획입니다.
미래를 여는 HyperCLOVA X Video: 우리 문화를 이해하는 소버린 AI
영상 이해 기술은 이제 개별 이미지의 한계를 뛰어넘어 수백만 개의 프레임을 더 깊이 있게 해석하는 시대로 접어들고 있습니다. 가까운 미래에는 두 시간짜리 영화를 통째로 이해하거나, 실시간으로 들어오는 스트리밍 영상을 즉시 해석하는 기술이 사용될 것으로 보입니다. 이런 발전으로 AI는 독립적으로 움직이면서 실시간 상황에 민첩하게 대응할 수 있게 될 거예요.
HyperCLOVA X Video는 이런 발전을 통해 SF 영화에서나 보던 로봇처럼, 실제 우리 일상에서 도움을 주는 존재가 되어가고 있습니다. 텍스트 AI와 마찬가지로, 영상 이해 AI도 다양한 지역과 문화적 배경을 이해할 수 있어야 해요. 특히 영상 속 문화적 요소를 정확히 해석하는 능력이 더욱 중요해질 겁니다. 팀네이버는 이런 과제를 해결하기 위해 풍부한 한국어 영상 데이터를 확보하고 있어 유리한 위치에 있습니다. 이는 더 안전하고 유용한 AI를 만드는 데 큰 도움이 될 것입니다.
[관련 내용 – ‘소버린 AI : AI 시대 네이버의 새로운 도전과 과제‘ 보러 가기]
마치며
네이버의 HyperCLOVA X는 사람과의 대화에서 시각을 통한 이해로 나아가고 있습니다. 다양한 문화적 배경을 가진 사람들이 AI와 더 쉽게 소통할 수 있도록 계속 노력하고 있습니다. 앞으로 HyperCLOVA X가 우리의 일상에 자연스럽게 녹아들어, 많은 사람들의 생활을 더 편리하게 만들어 주길 기대합니다.