
지난 LLM 서빙의 모든 것 1부에서는 LLM이 어떻게 동작하고 이때 토큰과 GPU가 왜 중요한지 살펴보았습니다. 이번 2부에서는 사용자의 프롬프트가 서버에서 어떻게 흘러가고, 답변은 어떤 경로로 생성되며, 그 과정에서 메모리(KV 캐시)가 왜 결정적인 변수가 되는지 단계별로 다루고자 합니다. 서빙 성능의 두 축인 지연 시간(Latency)과 처리량(Throughput)을 중심으로 LLM 서빙의 핵심 과제인 ‘어떻게 더 많은 요청을 더 빠르게 처리할 것인가‘에 대한 실마리를 함께 찾아보겠습니다.
LLM 서빙의 핵심 성능 지표: 지연 시간과 처리량
LLM 서비스는 단순히 모델을 띄우는 것을 넘어, 사용자 경험과 시스템 효율을 함께 만족시켜야 합니다. 이때 가장 중요한 지표가 지연 시간(Latency)과 처리량(Throughput)입니다.
지연 시간(Latency)
지연 시간은 사용자가 요청을 보낸 순간부터 응답을 받기까지의 시간, 즉 체감 응답 속도입니다. LLM의 지연 시간은 보통 두 부분으로 나누어 볼 수 있습니다.
- Time to First Token (TTFT): 첫 토큰이 화면에 나타나기까지 걸리는 시간으로 프롬프트를 해석하는 초반 계산이 크게 영향을 미칩니다.
- Time Per Output Token (TPOT): 첫 토큰 이후 각 토큰을 생성하는 데 걸리는 평균 시간. 전체 응답 시간은 대략 TTFT + (TPOT × 생성 토큰 수)로 볼 수 있어, 답변이 길수록 시간이 늘어납니다.
처리량(Throughput)
처리량은 일정 시간 동안 얼마나 많은 작업을 처리했는지를 나타내며, LLM 서빙에서는 주로 초당 생성 토큰 수(tokens/sec)로 표현합니다. 처리량이 높을수록 시스템에서 더 많은 동시 사용자를 효율적으로 다룰 수 있습니다.
지연 시간과 처리량의 상충 관계
지연 시간과 처리량은 종종 상충 관계에 있습니다. 한 사용자에게 지연 시간을 극단적으로 낮추기 위해 시스템 자원을 집중할수록 다른 사용자는 더 오래 기다리게 되어 전체 처리량이 떨어집니다. 반대로 여러 요청을 한 번에 처리(Batching)해 처리량을 최대화하면, 개별 요청의 대기 시간이 길어져 지연 시간이 증가할 수 있습니다. 따라서 안정적인 LLM 서비스를 위해서는 목표와 환경에 맞춰 두 지표의 균형을 정교하게 설계해야 합니다.
빠른 추론의 비밀, KV 캐시와 메모리 사용량
디코딩 단계에서 새로운 토큰을 생성할 때마다 과거의 정보를 처음부터 다시 계산한다면 매우 비효율적일 것입니다. 이 문제를 해결하기 위해 LLM은 KV 캐시(KV Cache)라는 메커니즘을 사용합니다. KV 캐시는 어텐션(Attention)에서 한 번 계산해 둔 중간 결과물인 키(K)와 값(V)을 GPU 메모리에 저장해 두는 일종의 ‘메모장‘입니다. 이후 토큰을 생성할 때는 과거의 모든 정보를 다시 계산할 필요 없이, 이 메모장에 저장된 KV 캐시 값을 재활용하여 훨씬 빠르게 다음 계산을 수행할 수 있습니다.
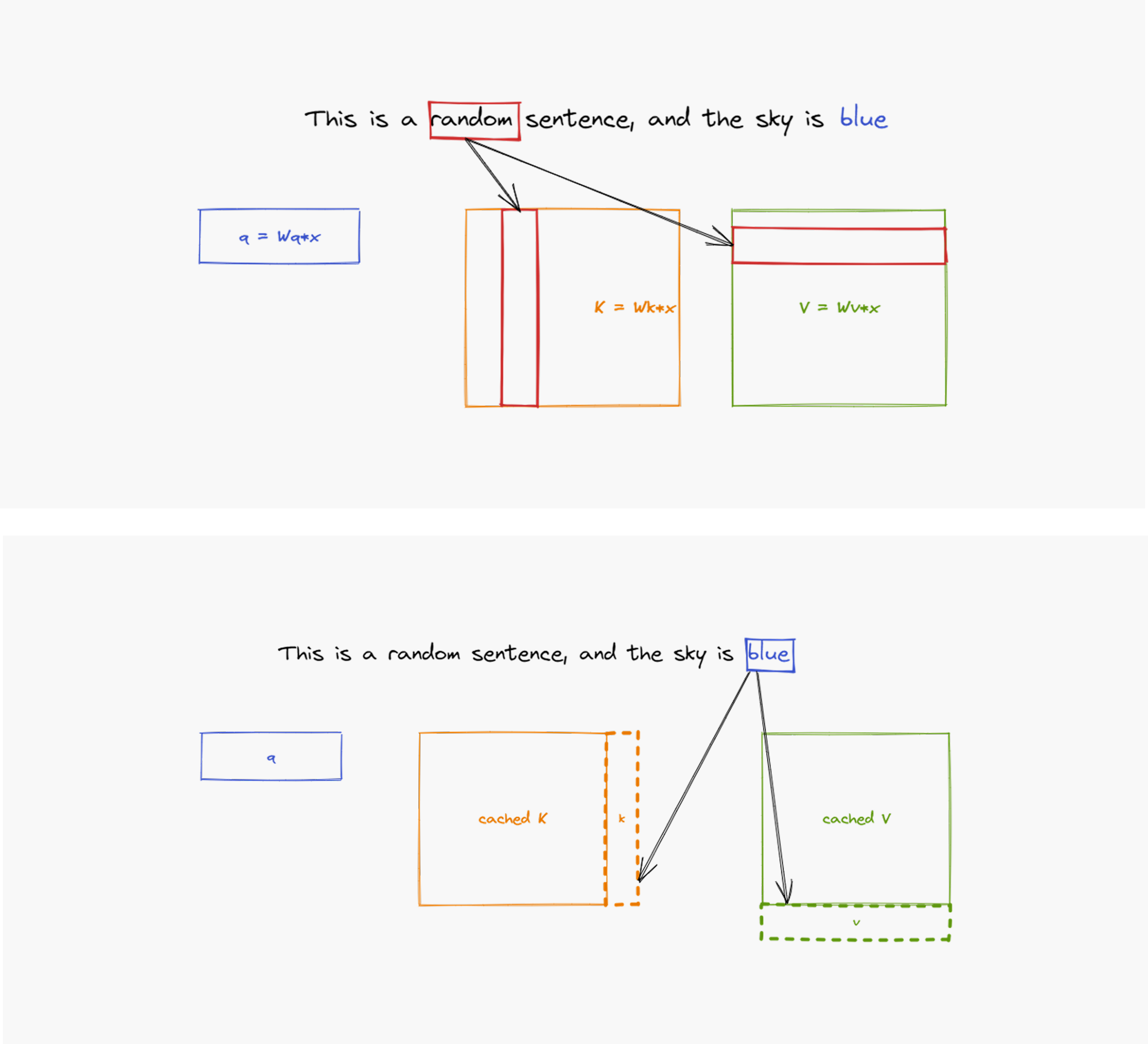
[그림 1]: 레이어마다 각 토큰의 연산을 캐시에 저장해 다음 토큰 연산 시 재연산하지 않도록 함
(출처: What is the KV cache?)
모델이 클수록 느려지는 이유
모델이 클수록 추론이 느려지는 이유는 메모리 대역폭과 사용량과 직결됩니다. 큰 모델일수록 고대역폭 메모리(HBM)에서 읽어야 할 매개변수(Weights)가 늘어나고, 더 많은 레이어와 더 큰 히든 사이즈 때문에 생성 및 유지해야 할 KV 캐시도 함께 커집니다. 결국 토큰을 생성할 때마다 메모리에서 읽고 써야 하는 데이터가 급격히 증가하므로, 디코딩 속도가 떨어질 수밖에 없습니다.
캐시 비용
물론 KV 캐시 자체도 비용이 듭니다. 캐시는 GPU 메모리를 상당히 점유하며, 대략 아래와 같이 추정할 수 있습니다.
KV Cache 메모리 (Bytes) ≈ [배치 크기] x [시퀀스 길이] x [레이어 수] x [히든 사이즈] x 2 (K, V) x [데이터 타입 크기]
- 배치 크기: 동시에 처리하는 요청의 수
- 시퀀스 길이: 입력 프롬프트 토큰 수 + 생성될 토큰 수
- 레이어 수: 모델의 깊이
- 히든 사이즈: 모델의 내부 표현 벡터 크기
- 데이터 타입 크기: BF16의 경우 2 Bytes
이 수식과 모델의 매개변수가 차지하는 메모리 크기를 알면, 우리는 한정된 GPU 메모리 안에 수용할 수 있는 총 토큰 양(배치 크기 × 시퀀스 길이)을 가늠할 수 있습니다. 요약하면, 총 GPU 메모리 사용량 ≈ 모델 매개변수 크기 + KV 캐시 메모리이며, 이 합이 커질수록 처리 가능한 동시 요청 수와 시퀀스 길이에 제약이 생기고, 지연 시간에도 직접적인 영향을 미칩니다.
배치 크기와 시퀀스 길이의 상충 관계
따라서 배치 크기와 시퀀스 길이 사이에는 불가피한 상충 관계가 발생합니다. 한정된 GPU 메모리 안에서
- 동시 처리량을 늘리기 위해 배치 크기를 키우면, 각 요청에 할당할 수 있는 평균 시퀀스 길이가 줄어듭니다.
- 긴 문서 요약처럼 긴 시퀀스가 필요한 작업을 지원하려면, 반대로 배치 크기를 줄여 동시에 처리할 수 있는 사용자 수를 감소시킵니다.
정해진 부피의 상자에 물건을 담는다고 생각해 보세요. 짧은 시퀀스는 작은 물건과 같아 여러 개를 한 상자(배치)에 함께 넣어도 여유가 남지만, 긴 시퀀스는 부피가 큰 물건이라 상자에 몇 개만 담을 수 있어, 동시에 처리할 수 있는 요청 수(배치 크기)가 줄어듭니다. 상자의 크기(GPU 메모리)가 고정되어 있다면, 큰 물건을 여러 개 동시에 담는 것은 구조적으로 불가능하죠.
함께 처리하기: Batching의 장점과 한계
GPU의 병렬 처리 능력을 극대화하기 위해 LLM 서빙 시스템은 여러 사용자의 요청을 모아 동시에 계산하는 배칭(Batching)을 활용합니다. 일반적으로 배치 크기가 커질수록 GPU 활용도가 높아져 전체 처리량(Throughput)이 올라가는 장점이 있습니다.
다만, 배치 크기를 무한정 키울 수는 없습니다. 다음의 두 가지 명확한 한계가 존재하죠.
한계 1: 물리적인 GPU 메모리
첫 번째 한계는 GPU 메모리입니다. 배치 크기를 늘리면 매 토큰 생성 단계의 메모리 접근 패턴이 바뀌고, 모델의 매개변수 총량은 고정되어 있어도 동시에 처리하는 요청 수만큼 KV 캐시의 크기와 읽기 양이 배치 크기에 비례해 증가합니다. 결국 늘어난 KV 캐시가 GPU 메모리 용량을 초과하여, 배치 크기에는 물리적 상한이 생깁니다.
한계 2: 응답 속도 요구사항 (Latency SLO)
두 번째 한계는 서비스 응답 속도 요구사항(Service-level Objective, SLO)입니다. 더 많은 요청을 동시에 처리하면 생성 단계마다 읽고 써야 하는 KV 캐시가 증가합니다. 이에 따라 하나의 배치에서 처리하는 토큰 수는 늘어나지만, 한 배치를 처리하는 데 걸리는 시간도 덩달아 늘어납니다.
다음 부분에서는 지연 시간과 처리량에 대한 상충 관계를 더 자세히 살펴보겠습니다.
LLM 성능, Goodput이 말해준다
처리량(Throughput)과 응답 속도(Latency)는 서로 상충 관계에 있죠. 그렇다면 둘을 한 번에, 현실적으로 재는 방법은 없을까요? 여기서 나온 개념이 Goodput입니다. Goodput은 서비스 지연 기준(SLO)을 통과한 응답만 집계해 일정 시간에 실제 전달된 유효 응답량을 보여줍니다. 말 그대로 ‘빠르고, 많이‘를 동시에 묻는 실전 성능 지표입니다.
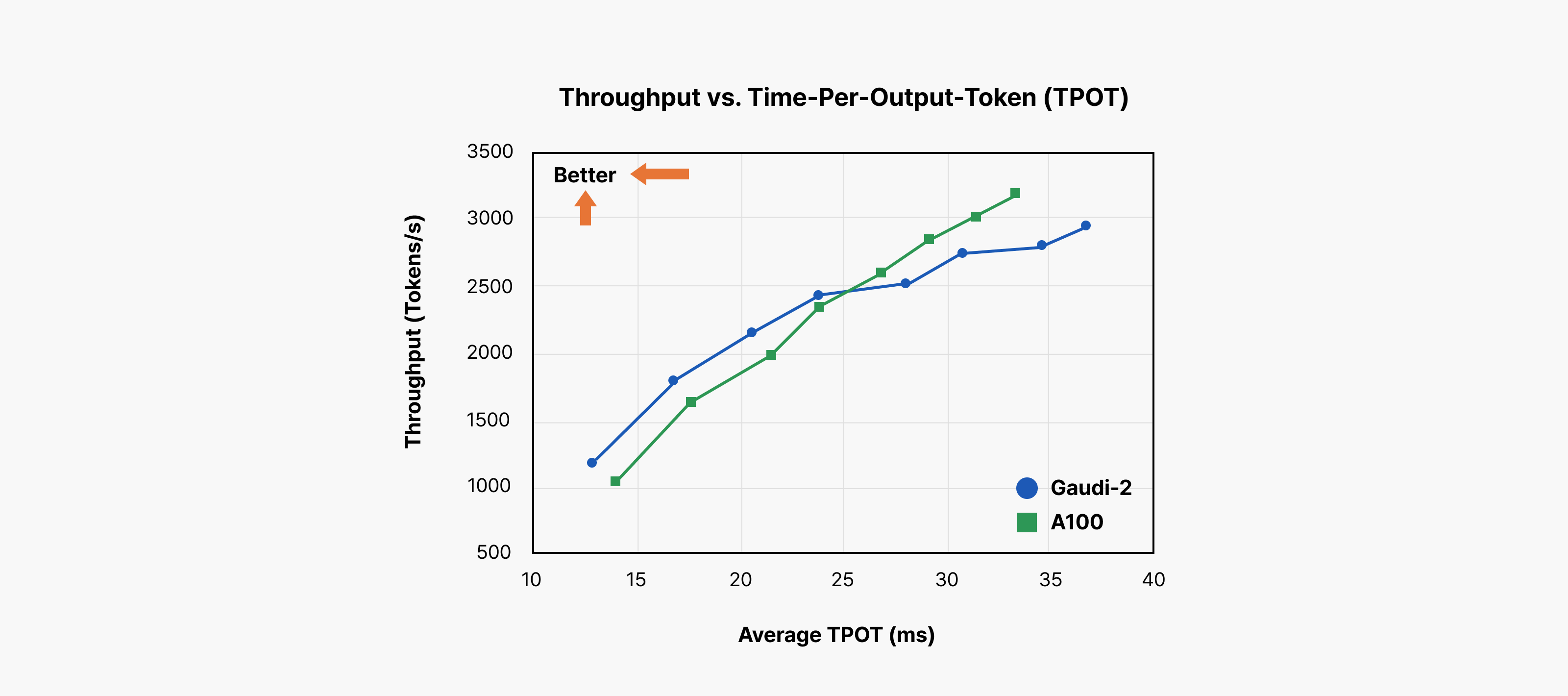
[그림 2]: 처리량 vs. 토큰 간 지연 시간 (출처: Intel Gaudi Introduction)
위 차트는 LLM 서빙 시스템이 실제로 얼마나 잘 동작하는지를 한눈에 보여주는 그림입니다.
- X축은 토큰 간 지연 시간(Time per Output Token, TPOT)으로, 한 토큰을 생성하는 데 걸리는 평균 시간을 의미합니다. Inter-token Latency (ITL)라고도 부르며 이 값이 왼쪽으로 갈수록 토큰이 더 빨리 생성된다는 것을 의미합니다.
- Y축은 출력 처리량(Output Token Throughput)으로 시스템이 1초 동안 생성할 수 있는 토큰의 총량을 뜻하고, 위로 갈수록 더 많은 요청을 감당하고 있다는 뜻입니다.
이상적인 시스템은 차트의 왼쪽 위에 위치해야 합니다. 즉, 응답 속도는 빠르면서(Low Latency) 동시에 많은 사용자를 처리(High Throughput)해야 합니다.
Goodput이란?
Goodput은 바로 이 개념을 수치화한 것입니다. Goodput은 단순히 ‘이론상 최대 처리량‘이 아닙니다. 우리가 정해둔 응답 속도 기준(SLO)을 지키면서 얻어낸 처리량을 의미합니다. 다시 말해 ‘사용자 경험을 해치지 않고 얻어낸 처리량‘이죠.
예를 들어, 우리 서비스가 사용자 경험을 위해 ‘토큰 생성 시간은 평균 20ms를 넘지 않아야 한다‘라는 SLO를 설정했다고 가정해 봅시다. 이 경우, 차트의 X축 20ms 지점에 수직선을 하나 그릴 수 있습니다. 그리고 각 하드웨어/구성의 성능 곡선이 그 선과 만나는 Y 값이 곧 그 시스템이 이 SLO 안에서 낼 수 있는 Goodput입니다. 그 이상으로 처리량을 올릴 수는 있겠지만, 그때부터는 20ms를 넘겨버리므로 사용자에게는 느리게 보입니다. 이 부분은 처리량은 늘었어도 ‘좋은 처리량‘이 아니므로, 흔히 Badput으로 간주합니다.
시퀀스 길이와 Goodput의 상관관계
또 한 가지 꼭 봐야 할 포인트가 있습니다. Goodput은 모델 크기뿐 아니라 시퀀스 길이에 따라서도 크게 변한다는 점입니다. 대화가 길어지거나, 긴 문서를 요약하거나, 여러 턴이 누적되는 시나리오에서는 시퀀스가 길어집니다. 그러면 토큰을 생성할 때마다 읽어야 하는 KV 캐시도 그만큼 커집니다. KV 캐시가 커지면 한 토큰을 만드는 데 걸리는 시간(ITL)이 자연스럽게 늘어나고, 차트에서는 전체 곡선이 오른쪽으로 밀려 보이게 되죠. 그 결과, 똑같은 20ms SLO 선을 기준으로 봤을 때 만날 수 있는 Y 값, 즉 Goodput이 더 낮아집니다.
성능 비교하기
LLM 서비스의 성능을 비교할 때는 항상 동일한 조건에서 비교하는지 물어봐야 합니다.
- 이 수치는 어떤 Latency SLO에서 측정한 건가?
- 어떤 시퀀스 길이로 테스트한 건가?
같은 모델이라도 이 조건에 따라 차트상 위치가 달라지고, 따라서 우리가 실제 서비스에서 체감할 성능도 달라지기 때문입니다.
Goodput 최적화 전략: 연산 제약과 메모리 제약의 병목 이해하기
LLM 서빙 시스템을 빠르게 만들고 싶다면 가장 먼저 해야 할 일은 ‘지금 이 시스템이 어디에서 느려지고 있는가?’를 정확히 짚는 것입니다. LLM 추론의 성능 저하 원인은 크게 두 가지로 나눌 수 있습니다.
- 연산 제약(Compute-bound)
GPU 코어 등 연산 장치의 계산 속도가 전체 성능을 좌우하는 상태입니다. 처리할 연산량이 너무 많아서 GPU가 계속 일하고 있음에도 작업이 금방 끝나지 않는 경우, 말 그대로 ‘계산이 너무 많아서‘ 느린 경우죠. - 메모리 제약(Memory-bound)
이번에는 반대 상황입니다. GPU는 계산할 준비가 다 돼 있는데, 정작 계산에 필요한 데이터를 메모리에서 가져오느라 시간을 허비하는 경우입니다. 데이터를 읽고 쓰는 속도, 특히 HBM 대역폭이 성능을 좌우하는 상태로, ‘연산기는 쉬고 있는데 데이터가 안 온다‘라는 게 핵심입니다.
LLM 추론의 두 단계는 이 두 가지 특성을 명확하게 보여줍니다.
- 프리필 단계는 대표적인 연산 제약(Compute-bound) 구간입니다. 사용자가 입력한 프롬프트 전체를 한 번에 처리하면서 대규모 행렬 곱 연산을 병렬로 수행합니다. 이때는 GPU가 얼마나 많은 연산을 동시에 처리할 수 있는지가 곧 성능입니다.
- 디코딩 단계는 반대로 메모리 제약(Memory-bound) 구간에 놓이기 쉽습니다. 토큰을 하나씩 생성하므로 계산 자체는 프리필보다 훨씬 가볍지만, 그때마다 모델의 큰 매개변수와 지금까지 쌓인 KV 캐시를 메모리에서 계속 읽어와야 합니다. 즉 연산보다 메모리에서 데이터를 가져오는 시간이 성능을 좌우하게 되므로, 이 구간에서는 메모리 대역폭과 캐시 관리 전략이 연산 성능보다 더 중요해집니다.
결국 Goodput을 높이려면 ‘현재 워크로드가 연산에 막혀 있는가, 아니면 메모리에 막혀 있는가‘를 먼저 구분해야 합니다. 그래야 연산량을 줄일지, KV Cache를 압축/공유할지, 배칭 전략을 바꿀지 같은 다음 선택이 명확해집니다.
병목 해결 전략
병목의 정체를 알았으니, 이제 각 병목을 해결하기 위한 접근법을 살펴보겠습니다.
초고속 메모리(HBM)
LLM 추론에서 디코딩 단계가 메모리 제약(Memory-bound) 상태라는 점은, 왜 LLM용 GPU에 고대역폭 메모리(High Bandwidth Memory, HBM) 같은 초고성능 메모리가 필요한지를 잘 보여줍니다.
토큰 하나를 생성하는 짧은 순간에도 GPU는 수십~수백 기가바이트(GB)에 달하는 모델의 매개변수와 KV 캐시를 HBM에서 읽어와야 합니다. 이때 HBM의 데이터 전송 속도가 곧 토큰 생성 속도(Inter-token Latency, ITL)를 결정합니다. 즉, 아무리 계산 속도가 빨라져도 메모리에서 데이터를 충분히 빨리 공급받지 못한다면, 전체 성능은 그 한계에 갇히게 됩니다.
여기서 주목할 점은 배치 크기가 커질 때, 모델 가중치(Weight)와 KV 캐시가 메모리에 미치는 영향이 전혀 다르다는 것입니다. 모델 가중치는 배치 크기와 상관없이 읽어야 하는 총량이 고정되어 있어, 그 비용을 배치를 통해 어느 정도 분담할 수 있습니다. 하지만 KV 캐시는 배치 크기에 정비례하여 커지기 때문에 그 메모리 I/O 부담은 분담되지 않고 계속해서 증가하여 시스템의 한계점을 결정짓는 주된 요인이 되죠.
특수 연산 장치(Systolic Array)
프리필 단계의 연산 제약(Compute-bound) 특성을 해결하기 위해 최신 AI 가속기들은 행렬 연산 전용 하드웨어를 탑재하고 있습니다. 대표적인 예가 바로 시스톨릭 어레이(Systolic Array) 구조입니다. 데이터가 규칙적으로 흐르며 연산이 연속적으로 이루어지는 방식으로, 대규모 행렬 곱셈을 매우 효율적으로 수행할 수 있습니다.
NVIDIA의 텐서 코어(Tensor Core) 역시 이러한 시스톨릭 어레이 기반 설계를 활용한 대표적인 기술로, 일반 GPU 코어보다 훨씬 높은 행렬 연산 처리량을 자랑합니다. 그 결과, 특히 프리필 단계의 처리 속도를 크게 끌어올릴 수 있습니다.
병렬 처리(Parallel Processing)
단일 GPU의 성능만으로 원하는 Goodput을 달성하기 어려울 때 사용되는 핵심 전략은 다중 GPU 병렬 처리(Parallel Processing)입니다. 여러 GPU를 함께 사용하면 단순히 연산 능력이 늘어날 뿐만 아니라, 총 메모리 대역폭도 비약적으로 증가합니다.
하나의 LLM을 4개의 GPU에 분산해 올린다고 가정해 봅시다. 각 GPU는 전체 모델의 ¼만 담당하고, 추론 시 4개의 HBM에서 동시에 데이터를 읽어옵니다. 이론적으로는 메모리 접근 속도가 4배 빨라지는 셈이죠. 이렇게 늘어난 메모리 대역폭은 특히 디코딩 단계처럼 메모리 병목이 심한 구간에서 지연 시간(Latency)을 단축하는 데 큰 효과를 발휘합니다.
그러나 병렬 처리에는 한계와 주의점도 있습니다. 여러 GPU가 동시에 동작하려면 GPU 간 통신이 필수적인데, 이때의 통신 대역폭(NVLink 등)이 새로운 병목으로 작용할 수 있습니다. 또한 데이터 동기화 과정에서 추가 연산이 필요하므로, GPU의 수가 늘어난다고 해서 성능이 그에 비례해 직선적으로 향상되지는 않습니다.
알고리즘 개선
하드웨어와 시스템 기법 외에도 알고리즘 측면의 개선은 LLM 추론 가속에서 매우 중요한 역할을 합니다. 대표 사례인 Speculative Decoding은 작고 빠른 모델이 먼저 여러 토큰을 미리 생성하면, 더 크고 정확한 모델이 그 예측 토큰을 병렬로 검증하고 수정하는 방식입니다. 즉, ‘속도 내는 초안‘을 작은 모델이 만들고, ‘정밀한 확정‘을 큰 모델이 병렬로 처리해 전체 응답 시간을 단축하는 아이디어죠.
이 외에도 조건부 계산(필요한 연산만 선택적으로 수행), 중간 계산 재사용을 통한 캐시 최적화, 디코딩ㆍ샘플링 전략 조정 등 다양한 추론 가속 기법이 활발히 연구ㆍ적용되고 있습니다. 모든 기법의 공통 목표는 명확합니다: Latency와 Throughput 사이의 상충 관계를 최적화하여 동일한 자원으로 더 높은 Goodput을 확보하는 것이죠.
이러한 알고리즘적 개선은 하드웨어ㆍ시스템 최적화와 결합할 때 가장 큰 효과를 냅니다.
Speculative Decoding 관련 테크 블로그 보러 가기
최종 목표는 ‘비용 효율성(Tokens per Dollar)’
지금까지 속도와 처리량을 높이는 여러 기술을 살펴봤지만, 실제 운영 관점에서는 성능만큼이나 비용이 중요합니다. 아무리 성능이 뛰어나도 운영 비용이 지나치게 높으면 실용적이지 않기 때문입니다.
따라서 LLM 서빙 최적화의 궁극적 목표는 달러당 처리 가능한 토큰 수(Tokens per Dollar)를 극대화하는 것입니다. 이 지표는 시스템의 처리 성능(초당 토큰 생성량)과 전체 운영 비용(하드웨어, 전기, 인프라 등의 비용)을 함께 반영하는 효율성 척도입니다.
즉, 단순히 가장 빠른 GPU를 고르는 것이 아니라, 우리가 정한 Goodput 목표를 가장 적은 비용으로 달성할 수 있는 하드웨어와 소프트웨어의 조합을 찾는 것이 핵심 과제입니다.
참고 자료
LLM 서빙을 보다 깊이 이해하고 싶다면, 아래 자료들을 함께 참고해 보시길 추천해 드립니다.
TensorEconomics. “LLM Inference Economics from First Principles.”
https://www.tensoreconomics.com/p/llm-inference-economics-from-first
SemiAnalysis. “InferenceMAX™: Open Source Inference Benchmarking.” https://newsletter.semianalysis.com/p/inferencemax-open-source-inference