
이전 글 “토큰 한 알의 질주: LLM 서빙의 모든 것” 시리즈에서는 LLM이 실제 서비스 환경에서 어떻게 빠르고 안정적으로 동작하는지, 그리고 사용자의 요청이 서버를 거쳐 응답으로 생성되는 전 과정을 살펴봤습니다. 이번 글에서는 이를 이어받아, 텍스트는 물론 이미지와 음성까지 함께 처리하는 국내 최초 옴니모델 HyperCLOVA X SEED 8B Omni로 이야기를 확장합니다. 실제 환경에서 서비스를 안정적으로 제공하기 위해 서빙 구조를 어떻게 설계하고 성능을 최적화했는지 그 과정을 공유하고자 합니다.
왜 옴니모달인가
우리의 일상은 텍스트만으로 이루어지지 않습니다. 우리는 대화를 나눌 때 말의 내용뿐 아니라 목소리의 높낮이, 표정, 대화의 맥락, 주변 환경의 시각적 정보까지 함께 이해합니다. 그리고 응답할 때도 목소리와 표정, 상황에 맞는 표현을 자연스럽게 담아 전달하죠. 이처럼 현실 세계의 소통은 여러 형태의 정보를 동시에 주고받는 데 가깝습니다. 그래서 AI가 실제 환경에서 실질적인 기능을 수행하기 위해서는 텍스트를 넘어 시각 정보와 음성 정보 등 다양한 모달리티를 함께 이해하고 생성할 수 있어야 합니다.
이러한 필요성 속에서 등장한 개념이 바로 옴니모달(Omnimodal)입니다. 옴니모달 모델은 이미지, 음성, 텍스트처럼 서로 다른 데이터를 하나의 의미 공간에서 학습합니다. 덕분에 여러 정보를 따로 처리하는 것이 아니라 통합적으로 이해하고 생성할 수 있습니다. 구체적으로 사용자가 입력한 이미지와 음성은 Encoder를 통해 모델이 이해할 수 있는 표현으로 변환되고, Decoder를 통해 상황에 맞는 형태의 응답으로 생성됩니다. 즉 텍스트 중심의 응답을 넘어 이미지와 음성까지 포함한 더 풍부한 상호작용이 가능해지는 것이죠.
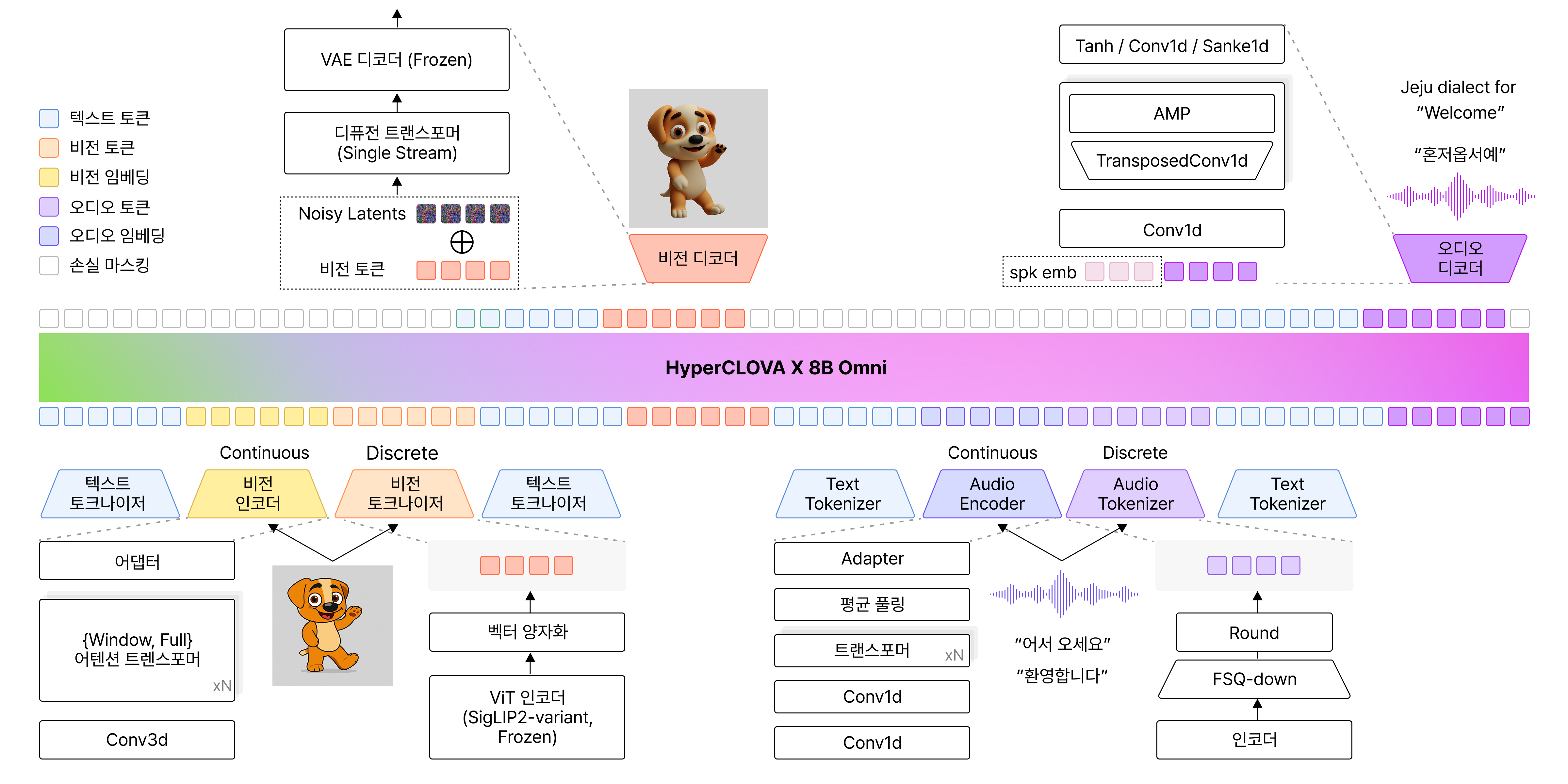 ▲ NAVER Cloud HyperCLOVA X Team, “HyperCLOVA X 8B Omni,” arXiv:2601.01792, Jan. 2026
▲ NAVER Cloud HyperCLOVA X Team, “HyperCLOVA X 8B Omni,” arXiv:2601.01792, Jan. 2026
팀네이버는 이러한 흐름에 맞춰 옴니모달 모델인 HyperCLOVA X SEED 8B Omni를 개발했습니다. (자세한 내용은 HyperCLOVA X OMNI: 국가대표 AI, 옴니모델을 향한 여정을 참고해 주세요.) 그렇다면 팀네이버는 옴니모달 모델을 실제 서비스 환경에서 빠르고 안정적으로 제공하기 위해 어떤 방식으로 서빙 구조를 설계하고, 최적화 작업을 진행했을까요?
시스템 설계: Encoder, Decoder, LLM 분리 전략
분리 구조의 필요성
HyperCLOVA X SEED 8B Omni는 Encoder와 Decoder가 하나로 통합된 구조를 가진 단일 모델입니다. 하지만 이 구조를 서비스 환경에 그대로 적용하기에는 자원 효율 측면에서 한계가 있었습니다. 예를 들어 영상과 관련된 요청만 들어오는 상황에서는 음성 처리와 관련된 영역이 GPU 내에서 아무 동작 없이 메모리만 차지하게 됩니다. 또한 영상 요청이 증가해 서버를 확장해야 할 때에도, 실제로는 영상 처리만 필요하지만 음성 처리 영역까지 함께 확장되면서 사용하지 않는 자원까지 같이 늘어납니다.
자원과 비용 낭비 외에 또 다른 문제도 있었습니다. Encoder, Decoder, LLM이 하나의 서버 안에서 동작하다 보니 GPU 자원을 서로 차지하려고 경쟁하는 상황이 발생했고, 이는 전체적인 성능 저하로 이어졌습니다. 이러한 문제를 해결하기 위해 각 기능을 하나의 구조에 묶어두는 대신 Encoder, Decoder, LLM을 각각 독립된 서버로 분리하는 방식을 선택했습니다.
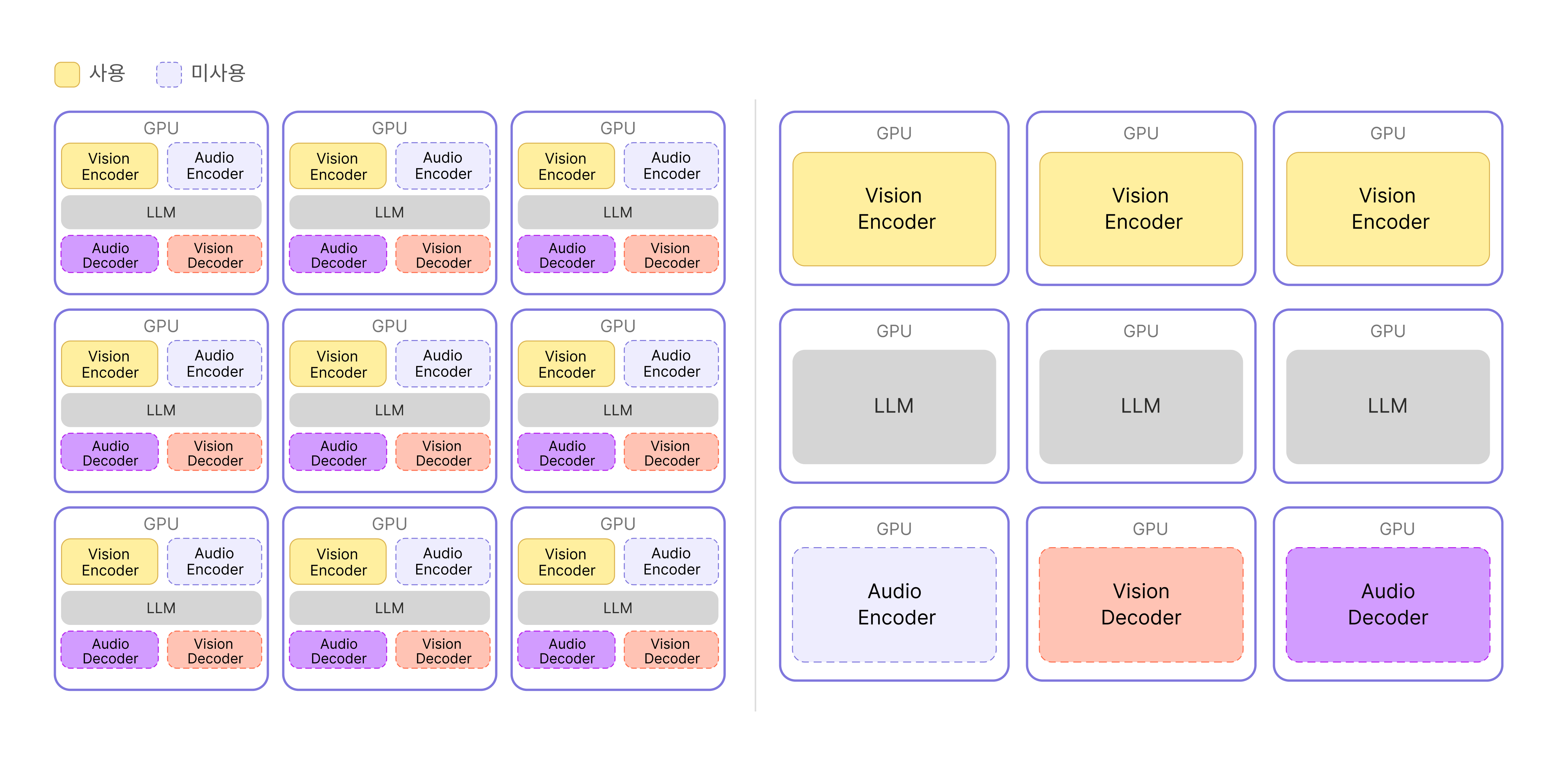 ▲ (좌) 기존 구조. (우) Encoder, Decoder, LLM을 분리한 구조
▲ (좌) 기존 구조. (우) Encoder, Decoder, LLM을 분리한 구조
위 그림을 보면 차이를 더 쉽게 이해할 수 있는데요. 왼쪽의 기존 구조에서는 사용하지 않는 기능이 GPU 공간을 차지하면서 자원이 비효율적으로 사용됩니다. 또한 Vision Encoder와 LLM이 하나의 GPU에서 자원을 두고 경쟁하죠. 반면 Encoder, Decoder, LLM을 분리한 구조에서는 각 기능이 GPU 자원을 온전히 활용할 수 있고, 필요한 기능만 선택적으로 확장할 수 있어 자원 낭비를 크게 줄일 수 있습니다.
Orchestration 방식 선택
구조를 분리한 이후 다음 과제는 각 컴포넌트를 어떻게 연결할 것인가였습니다. 각 기능을 독립된 실행 환경인 컨테이너로 구성하고, Kubernetes로 자동으로 관리·배포하는 운영 방식이 산업 전반에서 널리 사용되는 표준에 가까워 큰 이견이 없었는데요. 다만 시스템 아키텍처 관점에서는 API Gateway 기반 Service Chaining 방식과 중앙 Orchestrator 방식 중 어느 것을 선택할지 고민이 필요했습니다.
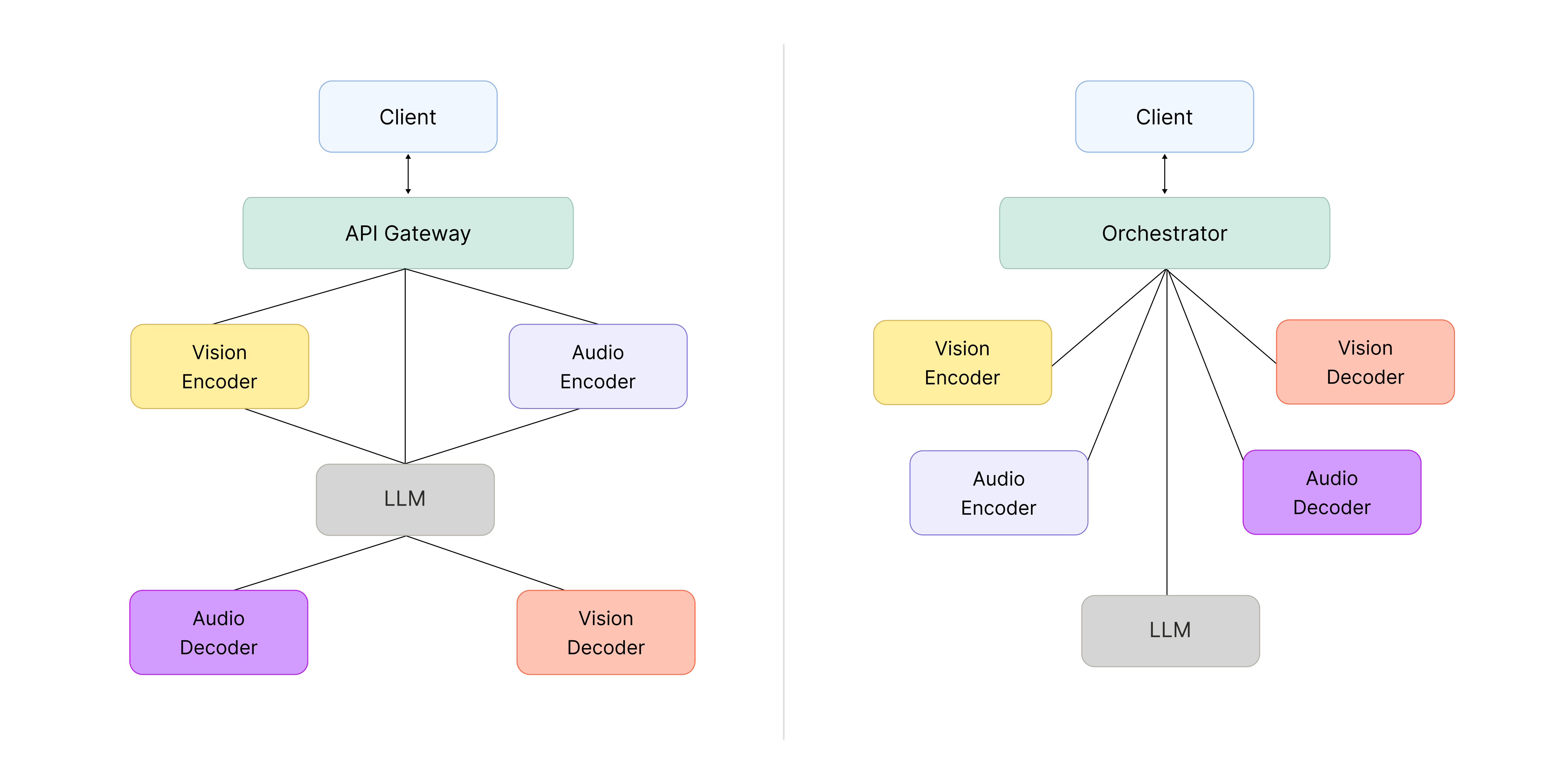
▲ (좌) API Gateway와 Service Chaining. (우) 중앙 Orchestrator 방식
- API Gateway 기반 Service Chaining 방식
Service Chaining 방식은 새로운 기능을 추가할 때 기존 기능들을 조합해 시스템을 확장할 수 있다는 점에서 유연성이 높은 구조입니다. 하지만 이번 경우에는 옴니모델 자체가 원래 하나의 구조로 통합되어 있기 때문에 Encoder와 Decoder가 LLM에 강하게 결합되어 있어 추가적인 연결을 통해 확장할 필요성이 크지 않았습니다. 또한 개발 기간이 짧은 상황에서 기능 간 호출이 분산된 구조를 선택할 경우, 문제가 발생했을 때 호출 흐름을 추적하며 디버깅하는 과정이 복잡해지고, 이는 곧 전체 개발 속도 저하로 이어질 수 있다는 리스크가 있습니다.
- 중앙 Orchestrator 방식
반면 중앙 Orchestrator 방식은 모든 흐름이 하나의 지점에 집중되는 구조이기 때문에, 해당 지점에 문제가 생기면 전체 시스템에 영향을 줄 수 있는 ‘단일 장애 지점(SPOF)’ 위험이 존재합니다. 그럼에도 불구하고 로직이 한곳에 모여 있어 흐름을 한눈에 파악할 수 있고, 문제 발생 시 원인을 빠르게 특정하고 대응할 수 있어 개발 속도가 빠르다는 확실한 장점이 있습니다.
최종적으로 중앙 Orchestrator를 도입하되, Orchestrator에 가능한 한 적은 책임만 부여해 장애 요인을 최소화하는 방향을 선택했습니다.
컴포넌트 간 인터페이스 설계
이와 같이 LLM, Encoder, Decoder를 분리한 구조에서는 각 컴포넌트 간 데이터를 어떻게 주고받을 것인지가 중요한 설계 요소가 됩니다. 이에 따라 서버 간 통신 방식과 데이터 포맷을 명확히 정의하는 데 집중하며 각 서버 컴포넌트의 API 스펙을 설계했습니다.
먼저 LLM 서버의 경우, 호환성을 고려해 현재 업계에서 가장 폭넓게 사용되는 OpenAI Chat Completion API를 그대로 채택했습니다. Orchestrator 역시 동일한 API 스펙을 따르도록 구성해 클라이언트와 LLM 사이에서 별도의 변환 없이 요청을 전달할 수 있도록 했습니다. 이때 Orchestrator는 입력 데이터의 형태에 따라 Encoder와 Decoder를 호출하고, 각 단계의 결과를 다시 OpenAI Chat Completion API 형식으로 조립하는 역할을 수행합니다.
반면 Encoder와 Decoder는 처리하는 데이터의 특성이 다르기 때문에 각각의 역할에 맞는 API를 별도로 설계했는데요. Encoder는 이미지나 오디오와 같은 원본 데이터를 입력으로 받아 LLM이 이해할 수 있는 형태, 즉 토큰 ID나 임베딩 벡터로 변환해 반환합니다. Decoder는 반대로 LLM이 생성한 토큰 ID를 입력으로 받아 이를 기반으로 최종 이미지나 오디오를 생성합니다.
한편 Encoder에서 생성된 임베딩을 LLM에 전달하는 과정에서는 추가적인 설계가 필요했습니다. 초기에는 모델 내부에서 플러그인으로 이를 처리하려 했지만, 임베딩 전달 경로가 복잡해지면서 코드 관리와 디버깅이 어려워지는 문제가 있었습니다. 그래서 우리는 구조를 더 단순하게 가져가기로 했습니다. Encoder에서 생성된 임베딩을 Data Plane을 통해 LLM 서버로 전달하고, 이를 LLM이 처리하는 입력 벡터(토큰을 변환한 임베딩)와 결합해 모델 입력으로 직접 주입하는 방식입니다. 이러한 구조를 통해 데이터 흐름을 더욱 명확하게 유지하면서도 복잡도를 낮출 수 있었습니다.
이제 Data Plane을 통해 데이터가 실제로 어떻게 전달되는지 자세히 살펴보겠습니다.
Data Plane으로 Object Storage를 선택한 이유
위에서 설명한 인터페이스를 기반으로, 중간 산출물을 실제로 어떻게 전달할 것인지에 대한 설계도 필요했습니다. 옴니모달 서빙에서는 임베딩 벡터와 토큰 ID 같은 중간 산출물이 Encoder, LLM, Decoder 사이에서 어떻게 전달되는지가 성능을 좌우합니다. 앞서 설명한 것처럼 영상과 음성 데이터는 Encoder를 거치면서 이런 형태로 변환되는데, 저희는 이 중간 산출물을 잠깐 쓰고 버리는 임시 정보로 보지 않았습니다. 대신 여러 서버가 함께 일하는 환경에서도 필요할 때 다시 꺼내 쓸 수 있고, 여러 단계에서 함께 사용할 수 있는 하나의 자산으로 보았습니다.
그래서 선택한 것이 시스템 안에서 데이터가 실제로 이동하고 저장되는 공용 통로, 즉 Object Storage(OBS)를 Data Plane으로 활용하는 방식입니다. 이를 통해 여러 컴포넌트 간 데이터 전달과 캐싱을 하나의 공통 경로로 통합하고자 했습니다. 구현 방식은 간단합니다. Encoder 산출물을 파일 형태로 직렬화해 OBS에 업로드하고 이후 단계에서는 실제 데이터 자체를 직접 전달하는 대신, 데이터가 어디 있는지 알려주는 주소표만 전달합니다. Object Key는 저장된 파일의 이름표 같은 것이고, Presigned URL은 일정 시간 동안만 접근할 수 있는 임시 링크인 것이죠. 이후 LLM이나 Decoder는 이 주소를 보고 필요할 때 저장소에서 데이터를 직접 가져옵니다.
이 구조를 통해 다음과 같은 장점을 얻을 수 있었습니다.
- 산출물의 크기나 형식과 관계없이 동일한 인터페이스로 처리할 수 있다.
- 데이터가 특정 서버에 종속되지 않기 때문에 여러 서버가 나눠서 일하는 환경에서도 유연하게 동작한다.
- 여러 턴으로 이어지는 대화에서는 이미 생성된 중간 결과를 다시 활용할 수 있어 같은 계산을 반복하지 않아도 되고, 시간과 자원을 절약할 수 있다.
- 모두가 같은 Object Storage를 함께 사용하기 때문에 요청이 처음과 다른 서버로 가더라도 동일한 데이터를 안정적으로 다시 불러올 수 있다.
결과적으로 Object Storage는 단순한 저장소 이상의 역할을 했습니다. 옴니모달 서빙에서 중간 산출물을 안정적으로 관리하고, 필요할 때 재사용할 수 있게 해주는 핵심 Data Plane으로 자리 잡게 되었습니다.
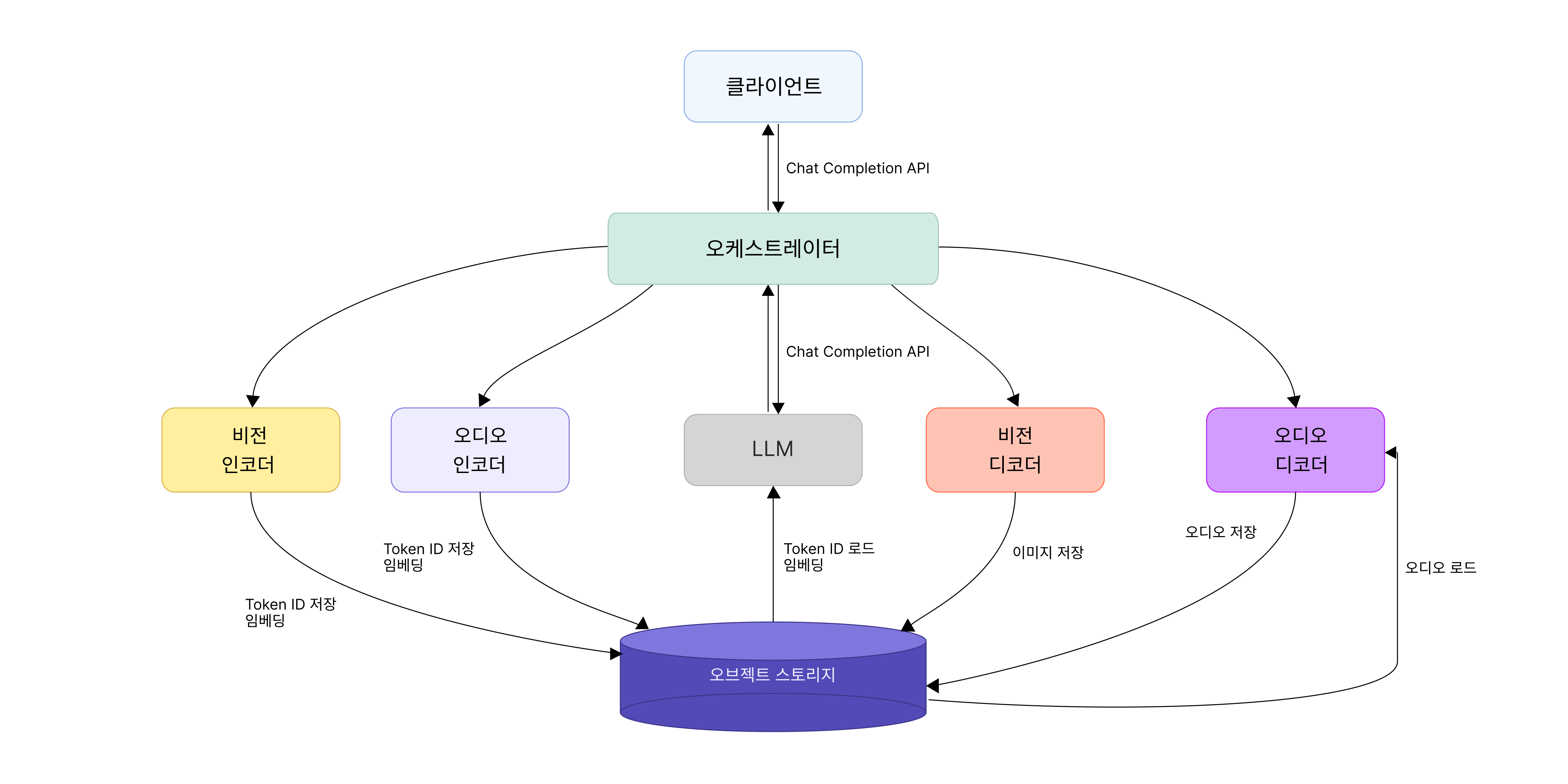
▲ 옴니모델 서빙을 위한 시스템 아키텍처
llm-d를 통해 KV 캐시 재사용을 극대화하는 방법
llm-d 도입 배경
vLLM은 단일 서버 환경에서는 뛰어난 성능을 보이지만, 여러 서버로 확장된 분산 환경에서는 이전 계산 결과를 저장해두고 다시 활용함으로써 LLM의 속도를 높이는 KV 캐시 재사용 효과를 충분히 활용하기 어려웠습니다.
LLM은 프롬프트를 처리할 때 이전 토큰의 계산 결과를 KV 캐시로 저장하고, 동일한 prefix가 다시 들어오면 이를 재사용해 연산을 줄입니다. 하지만 문제는 KV 캐시가 각 서버의 로컬 메모리에만 저장된다는 점입니다. 이 때문에 동일한 prefix를 가진 요청이라도 서로 다른 서버로 분산되면 캐시를 재사용하지 못하고 다시 계산해야 합니다. 그 결과 서버 수를 늘려도 기대했던 만큼의 성능 향상이 따라오지 않았는데요. 결국 중요한 것은 요청을 나누는 것이 아니라, 이미 필요한 문맥(prefix)을 가지고 있는 서버로 요청을 보내는 것이었습니다.
- Prefix: 입력 프롬프트의 앞부분 중 여러 요청에서 반복되는 공통 텍스트
예: 시스템 프롬프트나 이전 대화 내용처럼 반복적으로 포함되는 부분
이를 해결하기 위해 도입한 것이 llm-d입니다. llm-d는 각 서버의 KV 캐시 상태와 현재 부하를 함께 고려해 요청을 라우팅하는 스케줄러로, 동일한 prefix를 가진 요청을 가능한 한 같은 서버로 보내 캐시 재사용을 극대화합니다.
llm-d 도입을 위한 과제
물론 도입 과정이 순탄하지만은 않았습니다. 실제 서비스 환경에 적용하기 위해서는 라우팅 구조와 요청 처리 방식 전반에서 몇 가지 구조적인 문제를 먼저 해결해야 했습니다.
우리가 마주한 과제는 크게 세 가지였습니다.
- 모델 서버마다 서로 다른 진입점을 사용하고 있어 공통 라우팅 정책 적용이 어려웠던 점
- 요청 바디의 모델 정보를 기준으로 목적지를 결정해야 했지만 이를 위한 라우팅 기능이 제공되지 않았던 점
- 캐시 활용도뿐 아니라 서버 부하까지 함께 고려해야 했던 점
또한 초기 llm-d는 Hugging Face 중심으로 설계되었기 때문에, 사내 Omni 모델을 적용하기 위해 관련 코드를 직접 수정해야 했습니다. 결국 llm-d 도입은 기능 연동이 아니라, 서비스 환경의 제약을 하나씩 해결해 가며 구조를 맞춰가는 작업에 가까웠습니다.
1) 단일 Gateway 기반의 공통 라우팅 구조로 전환
가장 먼저 해결해야 했던 문제는 모델 서버마다 나뉘어 있던 진입점(Ingress) 구조였습니다.
기존 구조에서는 진입점이 분산되어 있어 KV 캐시 상태를 고려한 라우팅 정책을 일관되게 적용하기 어려웠고, 운영 복잡도 또한 높아지는 문제가 있었습니다. 이를 해결하기 위해 여러 모델 서버가 하나의 진입점을 공유하는 단일 Gateway 구조로 통합했습니다. 이에 따라 라우팅 정책을 중앙에서 관리할 수 있게 되었고, 이후 llm-d 기반 라우팅을 안정적으로 적용할 수 있는 기반을 마련했습니다.
2) Body 기반 모델 라우팅
다음 과제는 요청을 어떤 모델로 보낼지 결정하는 것이었는데요.
우리 환경에서는 요청 바디에 포함된 모델 이름을 기준으로 모델 서버 그룹(InferencePool)을 선택해야 했지만, llm-d는 이러한 Body 기반 라우팅을 기본적으로 지원하지 않았습니다.
이를 해결하기 위해 요청을 가공하고 라우팅을 제어하는 구성 요소인 EnvoyFilter와 HttpRoute를 활용했습니다. 동작 방식은 다음과 같습니다.
- 1단계: EnvoyFilter가 요청 바디에서 모델 정보를 추출해 직접 구현한 ModelResolver로 전달
- 2단계: ModelResolver가 해당 정보를 헤더에 추가
- 3단계: 이후 HttpRoute가 이 헤더 값을 기준으로 적절한 모델 서버 그룹으로 라우팅
3) 분산 환경에서의 모델 서버 선택 전략
모델을 선택한 이후에도 같은 모델을 처리하는 서버 그룹(InferencePool) 내에서 어떤 서버로 요청을 보낼 것인지가 중요했습니다. 각 서버의 부하 상태까지 함께 고려해야 했기 때문에 캐시 활용도가 높은 서버를 선택하는 것만으로는 충분하지 않았습니다. 이를 위해 KV 캐시 활용도와 서버 부하(Queue)를 각각 반영하도록 항목과 가중치를 조정했습니다.
- weight: 3.0 – pluginRef: kv-cache-utilization-scorer
- weight: 2.0 – pluginRef: queue-scorer
- weight: 2.0 – pluginRef: max-score-picker
각 가중치 항목의 역할은 다음과 같습니다.
- kv-cache-utilization-scorer: 해당 서버가 이미 유사한 요청을 처리한 이력이 있어 KV 캐시를 재사용할 가능성이 높은지를 평가. 성능 개선에 가장 큰 영향을 주는 요소이기 때문에 가중치를 3.0으로 가장 높게 설정
- queue-scorer: 현재 요청 대기열 길이를 기반으로 서버의 부하 상태를 반영
- max-score-picker: 최종 점수를 기준으로 가장 적합한 서버를 선택
llm-d는 각 서버(레플리카)를 여러 기준으로 평가한 뒤 가중치를 반영해 점수를 계산하고, 가장 높은 점수를 가진 서버를 선택하는데요. 위와 같은 기준을 통해 캐시를 재사용할 수 있는 서버를 우선적으로 선택하면서도 서버 부하를 함께 고려해 특정 서버로 요청이 몰리는 것을 방지하는 균형 잡힌 라우팅 전략을 세울 수 있었습니다.
지금까지 설명한 개선 사항을 전체 흐름으로 보면 아래와 같습니다.
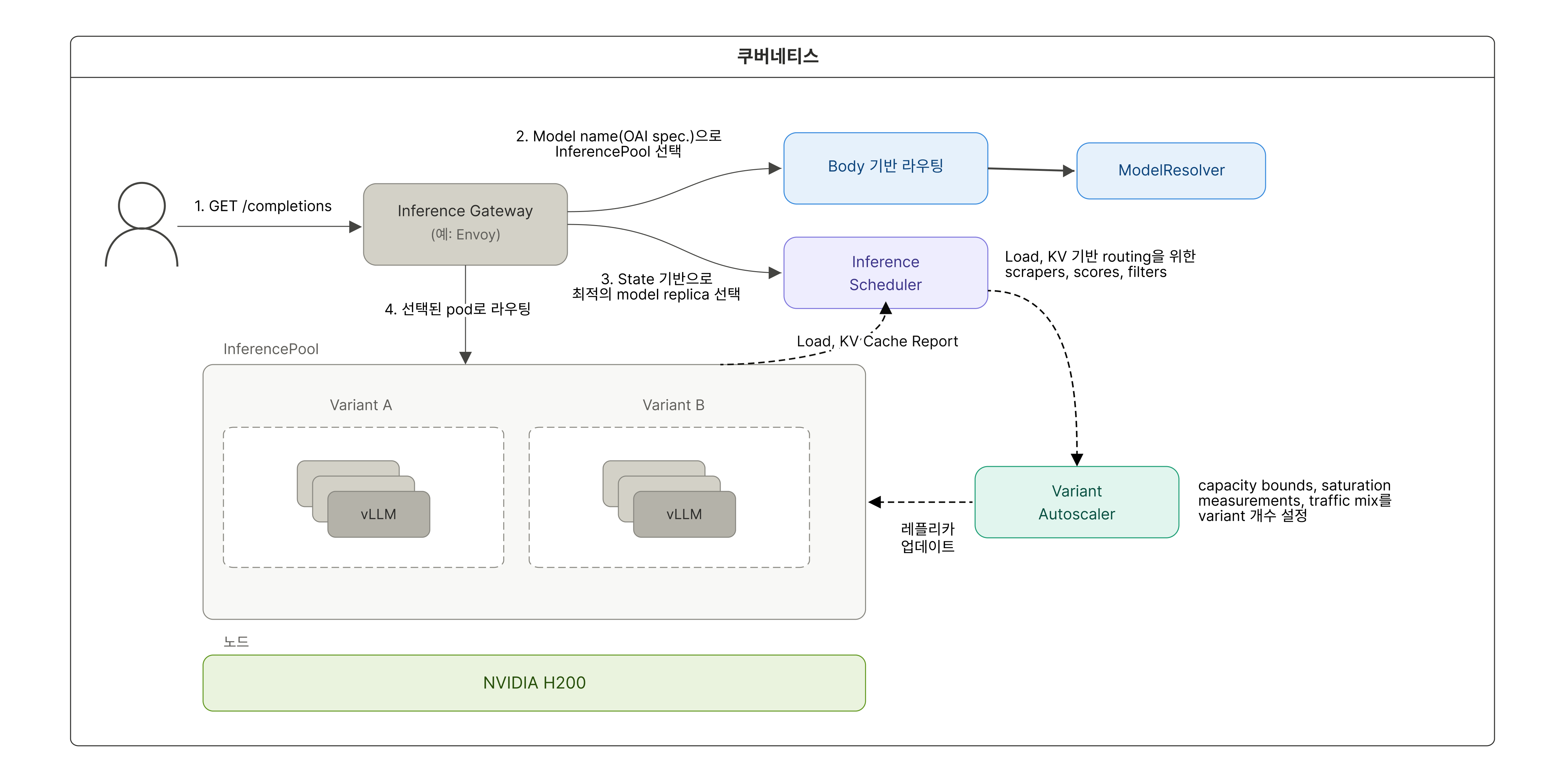
▲ llm-d를 적용한 분산 추론 아키텍처
llm-d 적용 결과
지금까지의 개선을 통해 llm-d를 실제 서빙 환경에 안정적으로 적용할 수 있었습니다. 그 결과 처리량은 2.1배 향상되었고 KV 캐시 활용도도 기존 25~45%에서 90% 이상으로 크게 개선되었습니다. 이 과정에서 도출한 개선 사항 또한 오픈소스에도 직접 기여해 반영했습니다.
Encoder/Decoder 연산 최적화
시스템 구조 설계와 분산 최적화 이후, Encoder와 Decoder 각 컴포넌트의 연산 시간 자체에 대한 최적화를 추가로 진행하였습니다. 각 컴포넌트의 연산 특성은 다음과 같습니다.
- 비전/오디오 Encoder, LLM 프리필: 입력을 일괄 처리하는 compute-bound 연산
- LLM 디코드: 토큰마다 전체 가중치를 로드해야 하는 memory-bound 연산
- Vision Decoder: KV 캐시 없이 8K 시퀀스를 프리필로 N회 반복하는 compute-bound 연산
- Audio Decoder: 프리필 1회로 처리되는 compute-bound 연산
Vision Encoder: Conv3D 784회 → 1회
OmniServe는 HyperCLOVA X SEED 8B Omni의 멀티모달 추론 시스템입니다.
초기에 숫자 표현 형식(dtype)이 맞지 않아 어텐션 연산을 빠르게 처리해 주는 기능인 FlashAttention2가 비활성화된 상태였습니다. 다시 말해 고속도로가 뚫려 있는데 진입로가 막혀서 일반 도로로만 다니고 있었던 것이죠. dtype을 올바르게 맞춰주자 FlashAttention2가 정상 동작했고, 이 상태에서 이미지 한 장의 Vision Encoder forward pass는 43ms가 소요되었는데요. 여기서 한 단계 더 줄인 과정을 공유합니다.
PatchEmbed가 병목이었다
프로파일링 결과, 전체 연산 중 68%가 이미지를 AI가 이해할 수 있도록 작은 패치로 나눈 뒤, 각 패치를 벡터로 변환하는 첫 번째 단계인 PatchEmbed에서 소비되고 있었습니다.
문제는 처리 방식이었습니다. 이미지를 14×14 크기의 작은 패치로 나눈 뒤 패치마다 Conv3D를 따로 호출하고 있었습니다. Conv3D는 이미지의 특징을 추출하는 연산인데, 사진 전체에 한 번 적용하면 될 필터를 수백 개의 조각에 나눠 각각 적용하고 있는 셈이었습니다.
고해상도 이미지의 경우 패치 수가 최대 784개까지 늘어나는데, 각 패치가 너무 작아서 실제 연산보다 GPU 커널을 실행하는 오버헤드가 더 커지는 문제가 발생했습니다. GPU에게 일을 시킬 때마다 메모리 할당, 명령 전달 같은 준비 작업이 필요한데요, 이게 마치 편의점에서 물건 하나 살 때마다 줄을 새로 서는 것과 같습니다. 계산 자체는 1초면 끝나는데 줄 서는 데 30초가 걸리는 상황을, 784번이나 반복하고 있었던 거죠.
해결책은 단순했는데요. 패치들을 다시 하나의 형태로 묶은 뒤 단일 Conv3D 연산으로 한 번에 처리했습니다. 즉 흩어져 있던 784개의 작업을 한 번에 모아서 처리하도록 바꾼 셈입니다. 그 결과 전체 forward pass는 약 4배 가까이 개선되었습니다.
참고로 비디오에선 효과가 미미했습니다. 해상도 제한과 Temporal Chunking(비디오의 프레임들을 시간순으로 묶어서 처리하는 방식)으로 인해 패치 수 자체가 많지 않았기 때문입니다.
Vision Decoder 최적화
Vision Decoder는 이미지를 생성하는 컴포넌트로, 내부적으로 DiT(Diffusion Transformer) 구조를 사용합니다. DiT는 이미지를 토큰 단위로 다루는 트랜스포머 기반의 Diffusion 모델입니다.
Diffusion을 먼저 간단히 살펴보면, 학습 단계에서는 이미지에 노이즈를 점점 추가해 완전히 망가뜨리는 과정을 시뮬레이션하면서, 동시에 모델이 각 단계에서 노이즈를 얼마나 제거해야 하는지를 학습합니다. 추론 단계에서는 순수한 노이즈에서 시작해, 학습된 방법대로 노이즈를 조금씩 제거하는 과정을 반복하며 이미지를 복원합니다.
이로 인해 Vision Decoder는 두 가지 구조적 특징을 가지게 되는데요.
- 고정된 긴 시퀀스: 입력 이미지 크기에 해당하는 약 9000 토큰을 항상 처리해야 합니다.
- 반복 연산: 이미지 한 장을 생성하기 위해 동일한 연산을 여러 단계에 걸쳐 반복합니다.
이 두 가지 특성이 맞물려, Vision Decoder는 대표적인 compute-bound 컴포넌트가 됩니다. 즉 처리해야 할 연산량이 많아 GPU의 계산 성능이 병목이 되는 상황인 것이죠. 이러한 병목 현상을 해소하는 방법은 크게 두 가지입니다. 연산량 자체를 줄이거나, 하드웨어를 추가해 병렬 처리하는 것입니다. 저희는 두 방향 모두를 적용했습니다.
Stage 1. 연산량 감소: Diffusion step 수 축소

▲ Diffusion step별 이미지 변화
가장 먼저 시도한 것은 연산량 자체를 줄이는 접근이었습니다. Diffusion 모델은 step 수가 많을수록 더 정교한 이미지를 생성할 수 있지만 그만큼 연산도 반복됩니다. 그래서 저희는 step 수를 줄였을 때 품질이 얼마나 유지되는지 정성 평가를 진행했습니다. 그 결과 step을 50에서 25로 줄여도 출력 이미지 품질에 유의미한 차이가 없음을 확인했습니다. 이에 따라 운영 기준을 25 step으로 조정했고, 결과적으로 약 2배의 연산량 감소를 달성할 수 있었습니다.
Stage 2. Ulysses Sequence Parallelism(USP)으로 병렬 처리하기
연산량을 줄이는 것과 동시에 GPU를 추가해 작업을 나누는 병렬화 전략도 함께 적용했는데요. 병렬화 방식에는 TP(Tensor Parallelism), SP(Sequence Parallelism), PP(Pipeline Parallelism) 등 여러 방법이 있습니다.
이 중에서 Vision Decoder처럼 9K 수준의 긴 고정 시퀀스를 처리해야 할 때에는 입력 시퀀스를 GPU 수만큼 나눠 처리하는 SP가 적합합니다. 즉 한 GPU가 9,000개를 처리하던 것을 여러 GPU가 나눠 처리하는 구조인 것이죠. 이 중에서도 저희는 통신 오버헤드를 최소화하기 위해 SP 계열 중 비교적 통신량이 적은 USP(Ulysses Sequence Parallelism)를 선택했습니다.
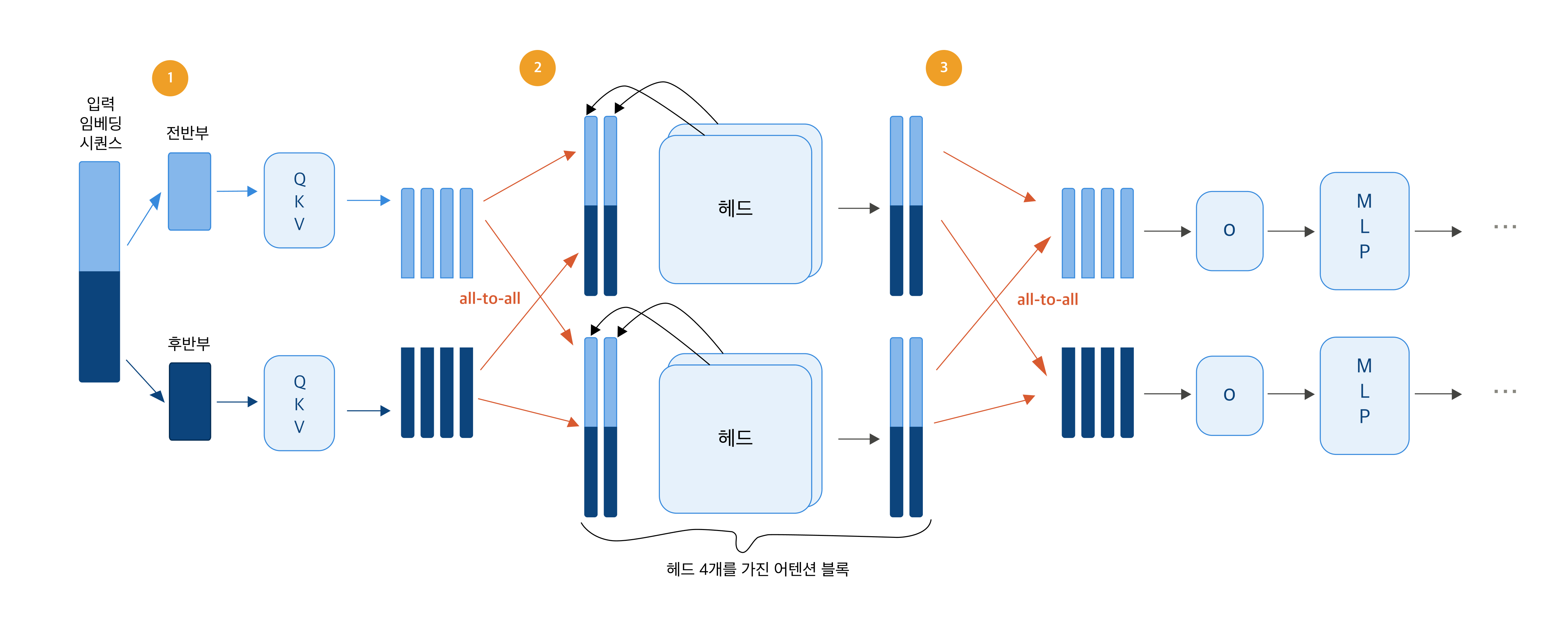 ▲“Ulysses: Unlocking Low-Latency, High-Throughput Inference for Long-Context LLMs”
▲“Ulysses: Unlocking Low-Latency, High-Throughput Inference for Long-Context LLMs”
출처: Snowflake Engineering Blog
USP의 동작 방식은 위의 그림과 같습니다. 2개의 GPU를 기준으로 USP가 어떻게 동작하는지 살펴보겠습니다.
1) 시퀀스 분할: 각자 알아서 계산
9,000개 토큰짜리 긴 이미지 정보를 GPU 혼자 처리하면 느립니다. 그래서 9,000개의 토큰을 GPU 1과 GPU 2가 절반씩 나눠 처리합니다. GPU 1은 앞 4,500개, GPU 2는 뒤 4,500개를 맡아 각 GPU는 자신이 맡은 구간에 대해 QKV를 독립적으로 계산합니다.
- QKV: 각 토큰이 무엇인지, 무엇을 찾는지, 무엇을 줄 수 있는지를 나타내는 세 가지 벡터
2) All-to-All 통신: 전체 문맥 공유 후 어텐션 계산
앞뒤 토큰이 서로 어떤 관계인지 파악하는 단계인 어텐션 계산에서는 모든 토큰 간의 관계를 알아야 합니다. 그래서 이 단계에서 단 한 번, GPU 간에 QKV 정보를 모두 교환하는데요. 이것을 All-to-All 통신이라고 합니다. 이후 각 GPU는 전체 내용을 여러 관점에서 동시에 분석하는데, 서로 다른 관점(Attention Head)을 맡아 병렬로 어텐션을 계산합니다.
3) All-to-All 통신: 출력 합산, 결과 정리 후 마무리
어텐션이 끝나면 다시 한번 GPU끼리 결과를 교환해(All-to-All 통신) 각자 원래 맡았던 토큰 구간 기준으로 출력값(o)을 모읍니다. 이후 MLP 각 토큰을 독립적으로 변환하는 연산 단계인 MLP 단계는 별도의 통신 없이 독립적으로 처리합니다.
이처럼 USP는 All-to-All 통신을 어텐션 전후로 단 2회만 수행하면 됩니다. 이 구조 덕분에 GPU 수가 늘어나도 통신 횟수는 그대로 유지되고, 한 번에 주고받는 양도 GPU 수에 비례해 줄어듭니다. 덕분에 긴 시퀀스에서도 통신 오버헤드를 최소화하면서 효율적인 병렬화가 가능한 것이죠.
실제 적용 결과 4-GPU 환경에서 최대 3.4배의 응답 시간(Latency) 개선을 확인했습니다. GPU 1대로 처리하던 이미지 생성 시간이 이론상 최대치인 4배에 근접한 수준으로 줄어든 것으로, 통신 설계를 단순하게 유지한 덕분에 GPU를 늘린 효과를 거의 온전히 속도 향상으로 연결할 수 있었습니다.
성능 최적화 결과 요약
일련의 최적화를 통해 각 컴포넌트에서 유의미한 응답 시간을 개선했습니다. llm-d의 prefix-aware routing으로는 3배, Vision Encoder는 약 4배, Vision Decoder는 약 3.4배 향상되었습니다.
이번 작업은 단순한 응답 속도 개선을 넘어, 분산 추론 환경에서 성능·자원 효율·확장성을 함께 확보할 수 있는 서빙 기반을 마련했다는 데 의미가 있습니다. 앞으로도 실제 서비스 환경에서 마주하는 문제들과 이를 해결하는 과정에서 얻은 인사이트를 지속적으로 공유해 나가겠습니다.
참고 자료
HyperCLOVA X 8B Omni Serving을 조금 더 깊이 이해하고 싶다면 아래 자료도 함께 참고해 보시길 바랍니다.
모델: HyperCLOVA X SEED 8B Omni on Hugging Face
서빙 코드: OmniServe GitHub 저장소