
개관
AI에 시험지를 건네면 어떤 일이 벌어질까요? 생성형 AI가 점점 더 똑똑해지면서 사람들은 AI 모델을 두고 정말 사람처럼 문제를 풀 수 있는지 궁금해합니다. 최신 모델이 실제로 어느 수준까지 발전했는지, 우리가 익히 아는 수능 같은 공식 시험 환경에서도 실력을 발휘하는지 알고 싶어하는데요.
네이버클라우드는 이러한 호기심을 실험으로 옮겼습니다. 2025 NAACL에서 발표한 논문 「Evaluating Multimodal Generative AI with Korean Educational Standards」에서는 한국 교육 체계를 기반으로 한 새로운 AI 평가 벤치마크, KoNET을 선보였습니다.
앞서 공개한 HyperCLOVA X THINK 포스팅에서는 KoNET에 포함된 수능 문항을 활용해 모델의 추론(Thinking) 능력을 직접 확인한 바 있습니다. 이 사례는 KoNET이 단순히 새 벤치마크를 넘어, AI 모델 성능을 객관적으로 비교·평가할 수 있는 유용한 도구임을 보여줍니다. HyperCLOVA X THINK에 대한 자세한 내용은 해당 테크 블로그에서 확인할 수 있습니다.
KoNET은 한국 교육 기준에 맞춘 실제 시험 문항을 바탕으로, 생성형 AI가 현실적인 조건에서 학습·추론 능력을 얼마나 충실히 발휘하는지 정밀하게 평가하도록 설계되었습니다. 이를 통해 모델의 강점과 한계를 구체적으로 파악할 수 있으며, 향후 한국어 교육 환경에 최적화된 AI 연구와 발전을 이끌 중요한 기준점이 될 것입니다.
AI, 수능에 도전하다
연구팀은 한국의 초·중·고 검정고시와 대학수학능력시험(수능)에 출제된 모든 문항을 이미지 형태로 변환하여 텍스트 전용 LLM과 텍스트와 비전을 통합한 MLLM(멀티모달 LLM)을 평가했습니다.
결과는 다소 의외였습니다. 교육 단계가 올라갈수록 (초등 → 중등 → 고등 → 수능) 성능이 떨어지는 흐름은 예측했지만, 정작 난도가 가장 높은 수능에서의 점수 하락 폭은 기대보다 훨씬 컸죠. 최신 모델이라도 시험장의 ‘현실 난이도’를 온전히 넘기는 쉽지 않다는 사실이 드러난 셈입니다.
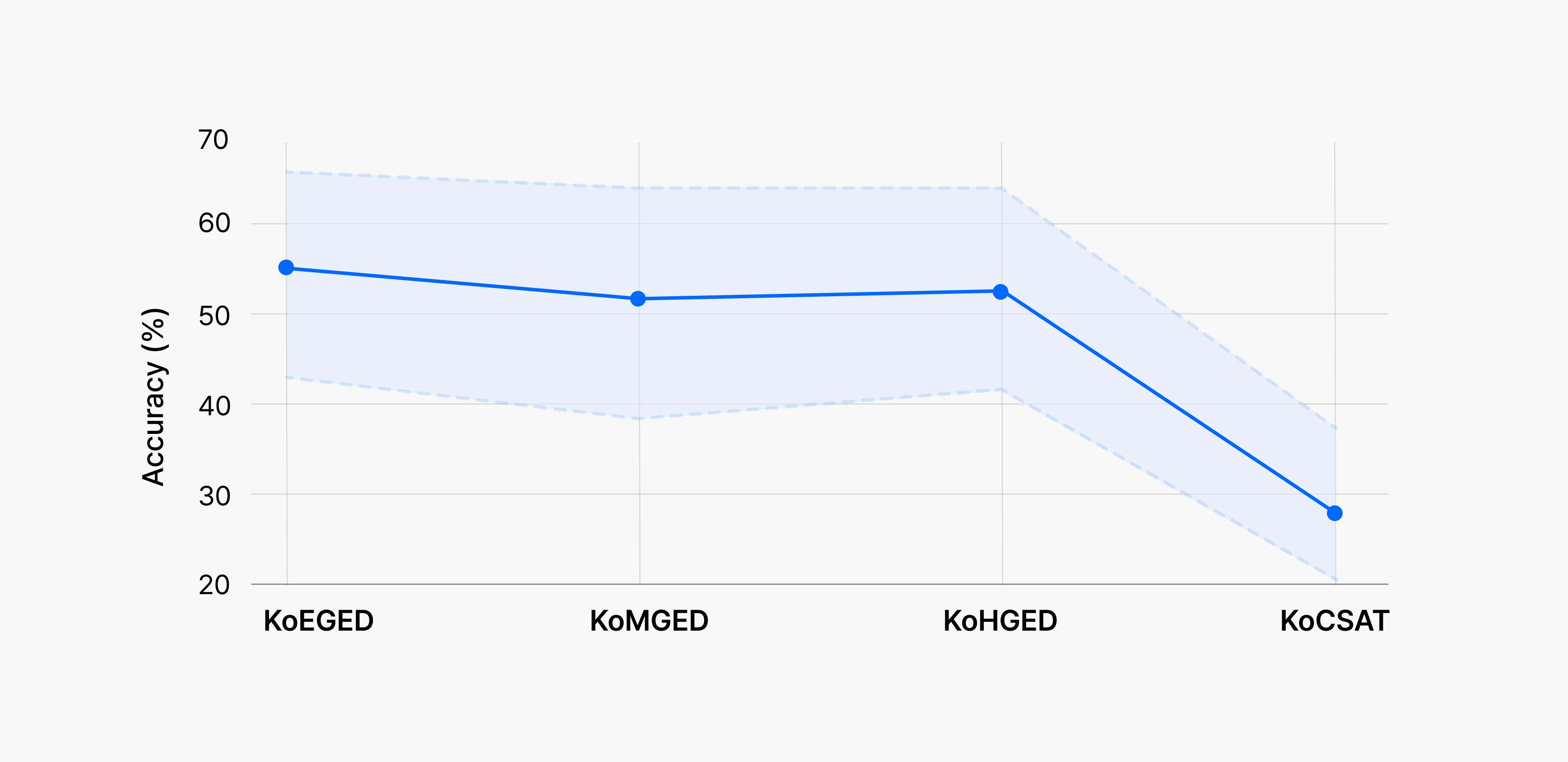
KoEGED: 초등 검정고시, koMGED: 중등 검정고시, KoHGED: 고등 검정고시, KoCSAT: 대학수학능력검정시험
흥미로운 사실은 또 있습니다. 모델이 크다고 해서 무조건 성능이 뛰어난 것은 아니었다는 점입니다. 오히려 네이버클라우드의 HyperCLOVA X, LG의 EXAONE처럼 한국어와 교육·문화 맥락에 최적화된 모델은 동급 파라미터 규모의 해외 모델을 앞서는 결과를 여럿 보여줬습니다. 영어 중심 벤치마크만으로는 보이지 않던 차이가 KoNET에서는 선명하게 드러났고, 결국 각 나라의 고유한 특성을 반영한 학습 데이터셋과 평가 기준이 필요하다는 점이 분명해졌습니다.
벤치마크 KoNET 소개
KoNET은 초등·중등·고등 검정고시와 수능 등 네 가지 한국 공식 시험으로 구성됩니다.
- 검정고시: 2023년 시행된 1·2차 시험 문항 전체
- 수능: 2024학년도 대학수학능력시험 전 과목(국어, 수학, 영어, 한국사, 사회탐구, 과학탐구, 직업탐구, 제2외국어)
시험지와 최대한 유사하게 문제와 선택지, 시각적 요소를 하나의 이미지에 담아 현실적인 환경을 구현했습니다. 최근 멀티모달 모델을 평가하는 방식이 지문과 문제를 이미지 형태로 제공하는 흐름과도 닿아 있습니다.
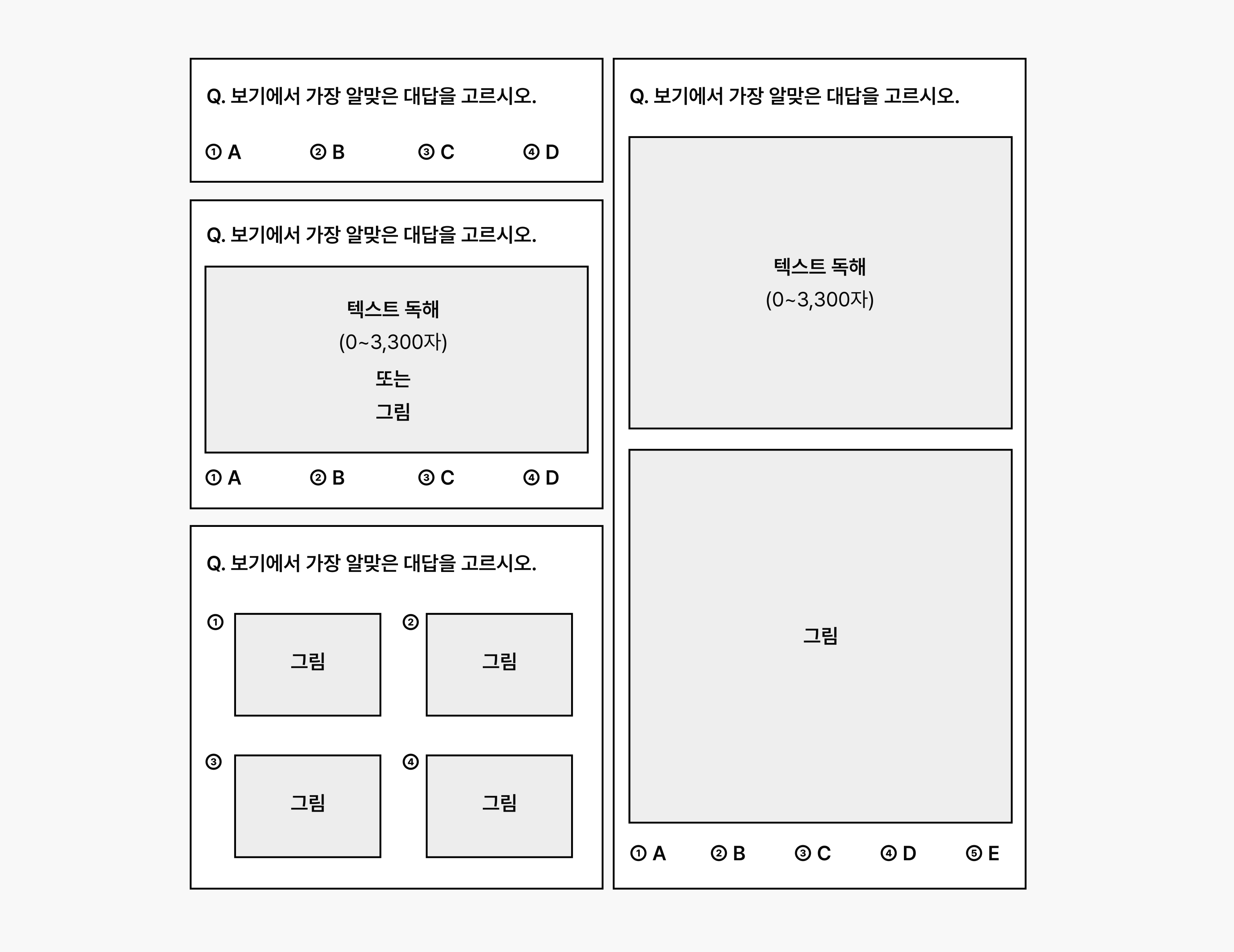
KoNET 시험지 예시
수능 질문 이미지
특히 수능은 실제 약 50만 명 수험생의 오답률 데이터가 일부 반영되어, AI와 인간의 실전 체감 난이도를 객관적으로 비교할 수 있었습니다. 더불어 독일어와 프랑스어, 중국어 등 제2외국어 평가도 포함되어 한국어를 넘어 다언어 상황에서도 모델이 어느 정도 성능을 내는지 함께 살폈습니다.
마지막으로, 데이터셋 생성 코드를 GitHub에 공개해 연구자와 실무자가 손쉽게 접근하고 활용할 수 있도록 했습니다.
리더보드에서 본 성능
수치로 보는 성능은 어떨까요?
- GPT-4o와 Claude 3.5 Sonnet 같은 상용 API 기반 멀티모달 모델(MLLM)은 평균 80% 이상의 성과를 기록하며 안정적인 성능을 보여주었습니다. 반면, 최신 오픈소스 LLM과 MLLM은 모델 크기와 주 사용 언어에 따라 성능 편차가 뚜렷했습니다.
- 예를 들어, EXAONE-3.0-7.8B 모델은 비슷한 파라미터 크기의 글로벌 모델들을 앞서는 정확도를 기록했고, Qwen2-72B 같은 대형 모델도 꾸준히 따라잡는 모습을 보였지만, 여전히 한국어 벤치마크에서는 상용 API 기반 모델에 뒤처지는 결과를 보였습니다.
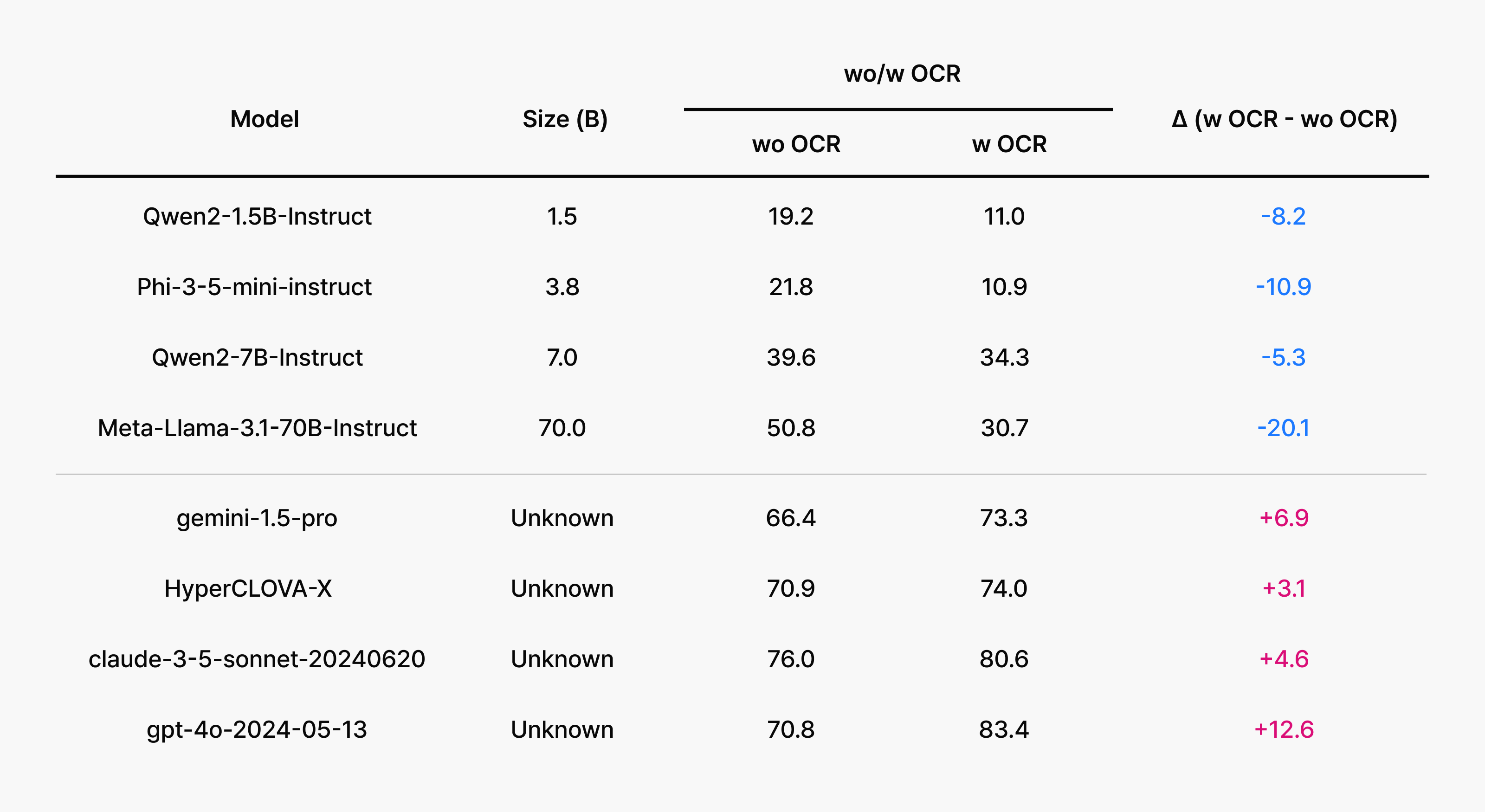
- 또 하나 눈에 띄는 점은, 오픈소스 MLLM 모델들이 한국어 OCR과 텍스트 인식에서 특히 약점을 드러냈다는 것입니다. 반대로, LLM+OCR 파이프라인은 비교적 안정적이고 꾸준한 성능을 유지했습니다.
핵심은, 수능처럼 문항과 선택지가 한 장의 이미지로 주어지는 환경에서 OCR 기술과 한국어 특화 전처리가 승부를 갈랐다는 점입니다. OCR이 흔들리면 지문을 놓치거나 잘못 읽어 추론력이 좋아도 정답까지 닿지 못하는 병목이 생깁니다.
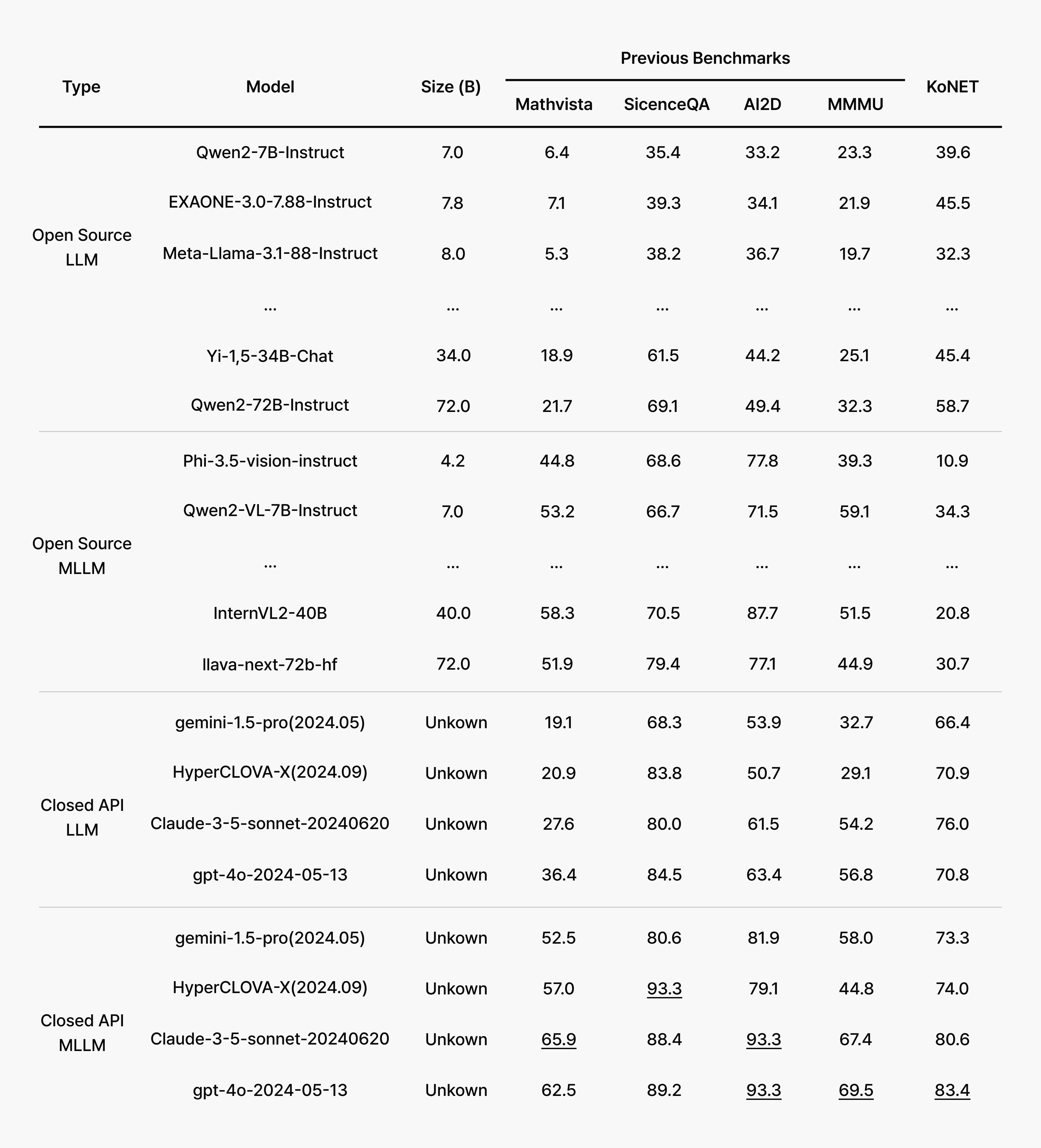
분석 1: 멀티모달 AI, 실제로 수능 문제를 잘 풀까?
KoNET에서는 단순히 텍스트만 잘 이해한다고 좋은 성적을 얻을 수는 없습니다. 도표, 그림, 캡션 등 문제 속 시각 정보와 한국어 텍스트를 함께 묶어 이해하고 결합해야 하죠. 하지만 오픈소스 멀티모달 모델은 OCR(문자 인식) 단계에서 흔들리면서, 지문을 잘못 읽거나 일부를 놓쳐 후속 추론이 틀어지는 경우가 잦았습니다. 그래서 LLM에 별도의 OCR 엔진을 결합한 파이프라인이 오히려 더 견실한 점수를 내는 경우도 반복적으로 관찰됐죠.
반면 GPT-4o나 Claude와같이 상용 API를 기반으로 하는 모델은 내장된 OCR과 레이아웃 이해가 탄탄해 문항과 선택지가 한 장의 이미지로 주어지는 환경에서도 맥락을 비교적 정확히 복원하며 일관된 성능을 보여주었습니다.
분석 2: Chain-of-Thought(CoT) 프롬프트, 실제로 효과가 있을까?
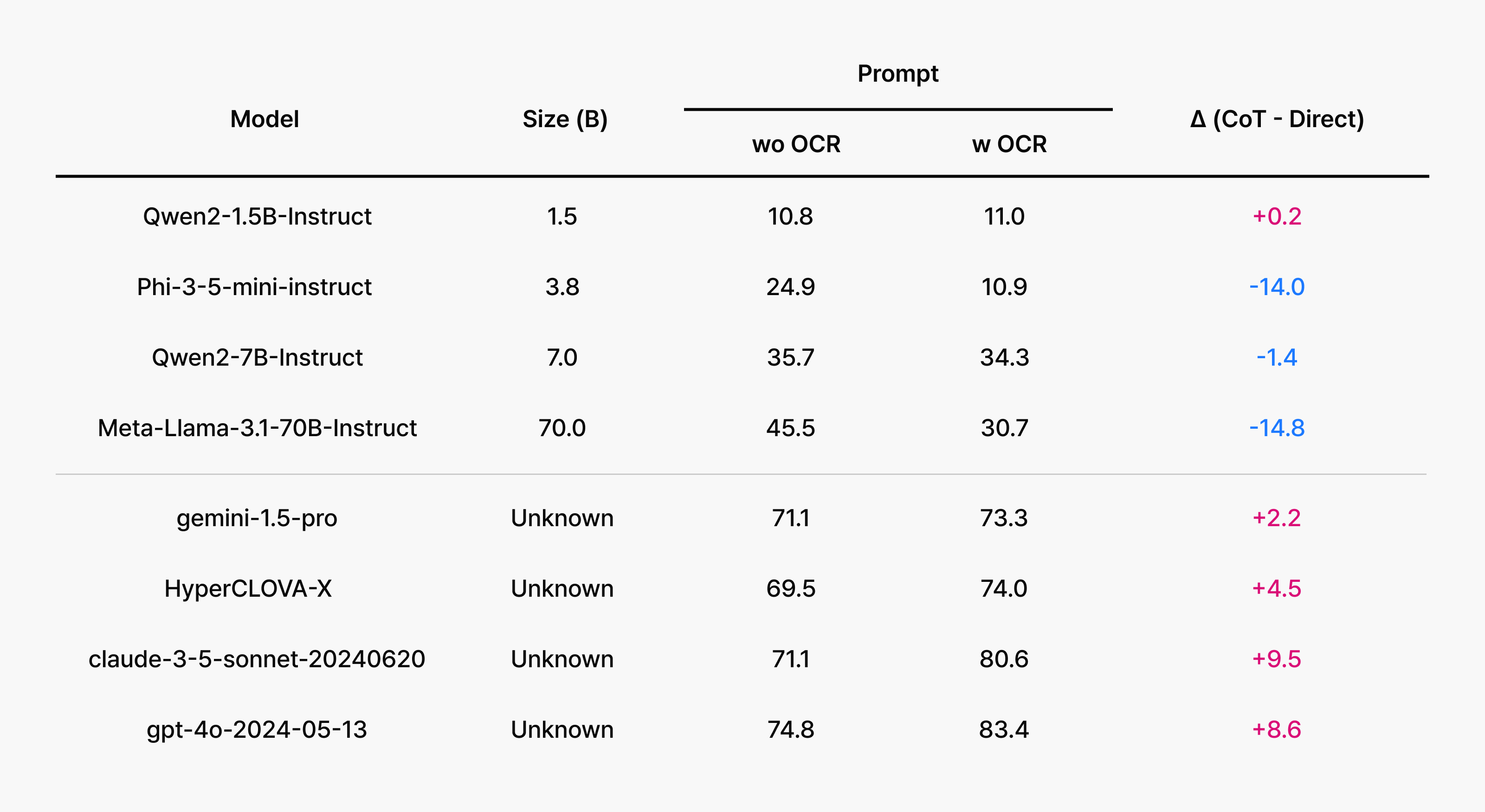
CoT(Chain-of-Thought) 프롬프트는 모델이 풀이 과정을 단계적으로 전개하도록 유도합니다. 간단한 VQA(시각 질의응답)를 넘어 복잡한 문항으로 갈수록 효과가 두드러지죠. 실험에서도 이 경향이 명확했습니다. 예를 들어 GPT-4o는 CoT만 적용해도 성적이 약 10%p 상승했습니다. 오픈소스 모델은 모델별로 상승 폭이 달랐지만, 난도가 높아질수록 CoT의 이점이 뚜렷해지는 모습이 공통적으로 관찰되었습니다. 요약하면, 풀이 과정을 단계적으로 드러내도록 유도하면 성능이 오른다는 것입니다.
분석 3: 수험생 vs. AI, 오답률도 다를까?
이번 연구에서 특히 눈길을 끈 부분은 AI 모델의 오류 패턴을 실제 수험생들의 오답률과 직접 비교할 수 있었다는 점이었습니다.
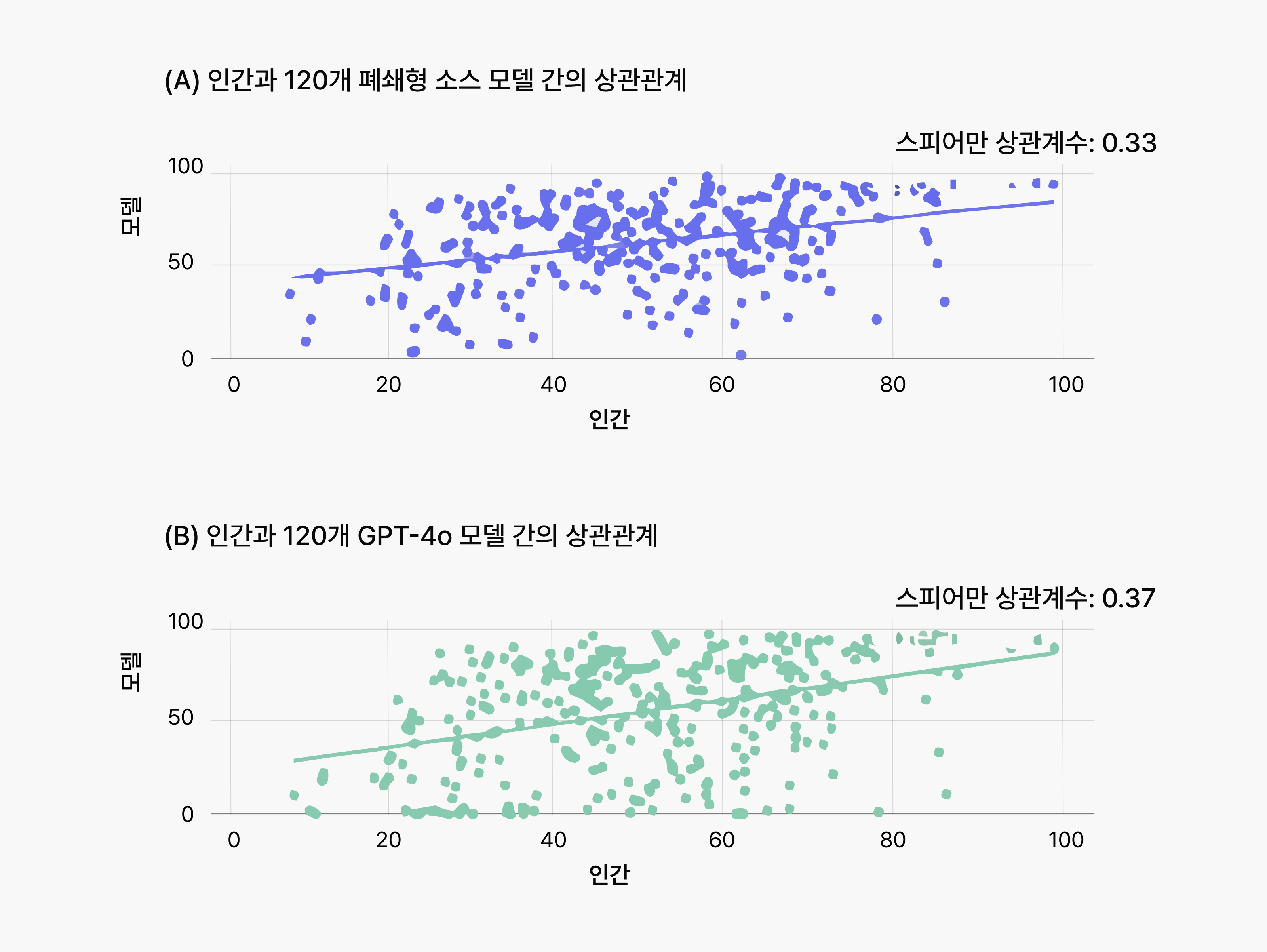
재미있게도 AI는 반복적이거나 집중력이 필요한 독해형 문제에서는 상대적으로 안정적인 성과를 보였지만, 배경지식이나 한국의 문화·역사 맥락이 필요한 문제에서는 인간이 더 뛰어난 면모를 보였습니다. 즉, AI와 사람이 잘하는 문제의 유형 자체가 달랐던 것이죠. 실제 분석 결과, 두 집단 간의 오답률 상관계수는 약 0.33~0.37로 그리 높지 않았습니다. 다시 말해, AI와 인간이 실수하는 지점은 크게 겹치지 않는다는 의미입니다.
이 결과를 시각화한 아래 그림의 x축은 실제 수험생들의 오답률, y축은 AI 모델의 오답률을 나타냅니다. 각 점은 하나의 문제를 의미하는데, 만약 점이 대각선에 가깝게 분포한다면 ‘인간과 AI가 비슷한 난이도로 느낀 문제’라는 뜻이 됩니다. 그러나 실제로는 상당수의 점이 대각선에서 벗어나 있었고, 이는 인간과 AI의 수능 문제를 바라보는 난이도의 관점이 다르다는 사실을 잘 보여주었습니다.
주요 결과를 정리해 보자면 아래와 같습니다.
- AI는 반복적이거나 집중력이 필요한 독해형 문제에서 상대적으로 안정적이었습니다.
- 사람은 배경지식·문화·역사 맥락을 요구하는 문제에서 우위를 보였습니다.
- 두 집단의 낮은 오답률 상관계수(약 0.33~0.37)는 실수하는 지점 자체가 크게 겹치지 않는다는 것을 의미합니다.
- 대각선에 점들이 촘촘히 모일수록 인간과 AI의 난이도 체감이 유사하다는 뜻인데, 실제로는 많은 점이 그 선을 벗어나 흩어져 있어 두 집단의 난이도 지형이 다름을 선명하게 보여줍니다.
또 하나 주목할 만한 지점은, 저희가 단순히 모델의 기본 출력만 본 것이 아니라, 여러 페르소나(persona)를 부여하여 오답률을 측정했다는 것입니다. 예를 들어 모델에게 “선생님”, “교수”, “학자”, “학생” 등 다양한 인격을 프롬프트로 설정하고, 추론 변수를 조절해 다양한 응답을 모은 뒤 오답률을 계산했습니다. 마치 서로 다른 학습 태도와 사고방식을 지닌 여러 수험생을 비교하듯, 현실에 가까운 군집 비교가 가능했죠.
무엇보다 KoNET은 문항마다 실제 수험생의 오답률을 함께 담고 있습니다. 덕분에 단순히 점수만 비교하는 데서 그치지 않고, 어떤 유형·지문에서 AI와 인간의 판단이 엇갈렸는지, 그 차이가 추론 과정, 배경지식, 레이아웃 해석 중 어디에서 비롯되는지까지 정량적으로 짚어볼 수 있죠. 말하자면 ‘맞았다/틀렸다’의 이분법을 넘어, 왜 그리고 어디서 반응이 달라졌는지를 객관적 지표로 설명할 수 있게 해주는 장치이고, 이 점이 KoNET의 연구적 의의를 크게 높여줍니다.
글을 마치며
이번 연구가 가장 선명하게 일깨워준 것은 한국어와 한국 교육 현실에 맞는 벤치마크의 필요성입니다. 영어 중심의 기존 지표만으로는 국내 실제 환경에서 AI가 어디에서 강점을 보이고, 어디서 한계를 드러내는지 충분히 판단하기 어렵다는 사실을 다시 확인했죠.
실무의 개발·운영 과정에서도 마찬가지였습니다. 한국어 OCR 기술과 독해 역량을 갖추면서 한국 교육 데이터를 활용하여 추가로 튜닝하는 것이 성능 향상의 결정적 변수가 된다는 점을 현장에서 체감했습니다.
그런 의미에서 KoNET과 같은 시도는 연구와 산업 현장을 이어주는 든든한 가교이자, 앞으로 국내 AI 경쟁력 강화를 이끌 중요한 기준점이 될 것이라 믿습니다.
자세한 연구 내용은 논문 전문에서 확인하실 수 있습니다.