
최근 대규모 언어 모델(Large Language Model, LLM)이 기술 산업의 핵심 주제로 자리 잡았습니다. 자연스러운 질의응답, 장문 요약, 코드와 이미지 생성 등 눈에 보이는 성과는 인상적이죠. 하지만 이 놀라운 기술이 실제 서비스에서 실시간으로 작동하는 메커니즘, 그 뒷단의 과정을 생각해 보신 적이 있나요?
사용자가 채팅창에 질문을 입력해 엔터를 누르는 순간부터 화면에 첫 응답이 나타나기까지, 이 짧은 시간 안에 ‘LLM 서빙(Serving)’이라 불리는 정교하고 복합적인 체계가 돌아갑니다. 본 글에서는 그 서빙 아키텍처를 구조적으로 해부해, 데이터 흐름과 시스템 구성, 지연ㆍ비용ㆍ안정성의 절충까지 한눈에 이해할 수 있도록 정리했습니다.
이 글은 LLM을 처음 도입하는 분은 물론, 모델은 익숙하지만 서비스 적용 시 고려해야 할 요소를 점검하려는 분께도 실무적인 기준점을 제공할 것입니다.
LLM, 언어를 이해하는 모델의 등장
서빙 아키텍처를 살펴보기 전에 LLM이 무엇인지 간단히 짚고 넘어가겠습니다. LLM은 방대한 텍스트로 학습해 문장 속 맥락ㆍ의존관계ㆍ논리 전개를 통계적으로 익힌 인공신경망입니다. 비유하자면, 끝없는 자료를 읽으며 언어의 규칙과 습관을 체득한 조교와 같습니다.
우리가 질문을 던지면 모델은 주어진 문맥을 기준으로 다음에 올 단어의 확률을 계산해 가장 자연스러운 조합으로 문장을 이어 갑니다. 핵심은 ‘암기’가 아니라 ‘패턴 학습’입니다. 이 특성 덕분에 요약과 번역, 질의응답은 물론, 일정 수준의 추론이 필요한 작업까지 사람처럼 매끄럽게 수행해 보이는 것이죠.
언어의 기본 단위, 토큰이란?
LLM이 언어를 다루는 방식은 사람이 글을 읽는 방식과 조금 다릅니다. 모델은 문장 전체를 한꺼번에 ‘이해’하지 않고, 먼저 텍스트를 ‘토큰(Token)’이라는 작은 조각으로 잘게 나누죠. 예를 들어 ‘나는 오늘 학교에 간다’라는 문장은 다음처럼 여러 토큰으로 분해될 수 있습니다.
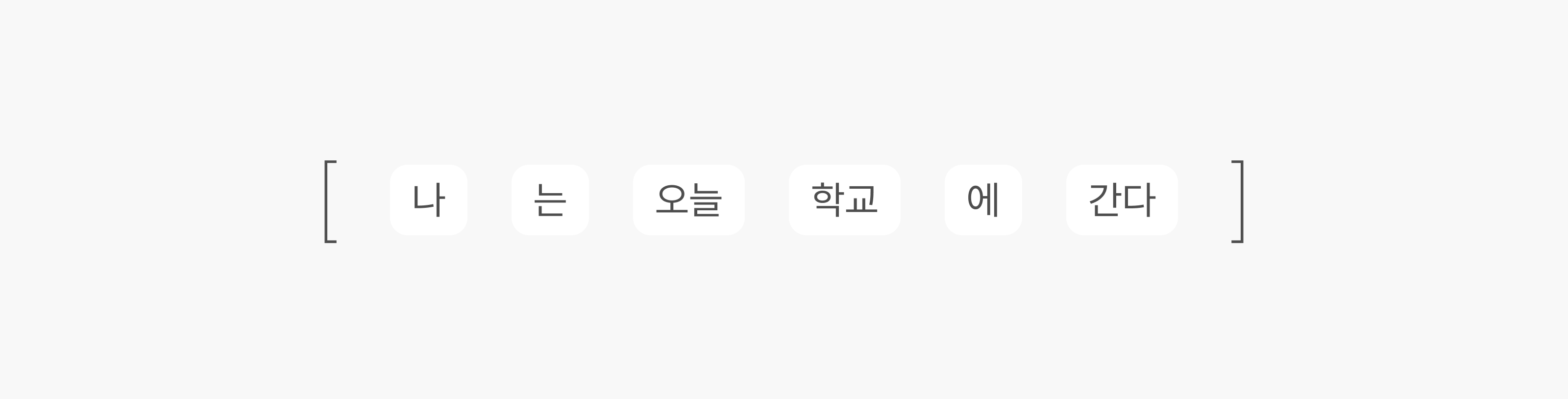
이후 모델은 미리 정의된 어휘집(Vocabulary)에서 각 토큰에 대응하는 정수 ID를 찾아 연산에 사용합니다. 위의 문장은 대략 다음과 같은 숫자 시퀀스로 변환됩니다.

중요한 점은, 단어와 토큰이 항상 1:1로 대응하지 않는다는 것입니다. ‘인공지능’이 [‘인공’, ‘지능’]처럼 둘로 쪼개질 수도 있고, 영어의 Serving은 [‘serv’, ‘ing’]처럼 더 작은 단위로 쪼개지기도 합니다. 반대로 자주 쓰이는 표현은 한 덩어리 토큰으로 묶이기도 하죠.
텍스트가 아닌 음성이나 이미지 역시 모델이 처리할 수 있도록 별도의 규칙으로 토큰화(Tokenization) 되어 숫자 시퀀스로 바뀝니다.
우리가 모델에 질문을 입력하면, 가장 먼저 일어나는 일도 바로 이 토큰화입니다. 즉, LLM은 사람이 친 문장을 자신이 계산할 수 있는 공통 언어(숫자 토큰의 열)로 변환한 뒤, 그 시퀀스를 따라 다음에 올 토큰의 확률을 계산해 답을 구성합니다. 이렇게 토큰 단위로 세계를 바라보는 덕분에 모델은 긴 문맥 속 의존관계까지 안정적으로 추적할 수 있는 것이죠.
우리는 LLM과 어떻게 대화할까?
그렇다면 우리는 이 똑똑한 모델과 어떻게 상호작용 할까요? 전체적인 과정은 다음과 같습니다.
- 프롬프트 입력(Prompt)
사용자가 질문ㆍ지시ㆍ맥락 등을 텍스트로 전달합니다. 이 한 문장이 모델이 해야 할 과업을 정의합니다. - 토큰화(Tokenization)
사용자가 입력한 문장을 모델이 계산할 수 있는 토큰의 시퀀스로 변환합니다. 각 토큰을 어휘집의 정수 ID와 매핑하여 수치 연산의 재료로 활용합니다. - 추론(Inference)
모델은 주어진 토큰들을 해석해 다음에 올 토큰의 확률 분포를 계산합니다. 가장 그럴듯한 토큰을 뽑고 다시 문맥에 붙여, 이 과정을 반복하면서 답변을 생성합니다. - 디토큰화(Detokenization)
생성된 토큰 시퀀스를 다시 사람이 읽을 수 있는 텍스트로 변환하여 화면에 출력합니다.
이 모든 과정이 눈 깜짝할 사이에 이루어지기 때문에 우리는 마치 LLM과 실시간으로 대화하는 것처럼 느낍니다. 하지만 사용자가 LLM에 하는 말을 처리하는 과정과 LLM이 답변하는 과정의 연산 방식은 크게 다릅니다.
이어지는 다음 부분에서는 LLM 추론에서 두 단계를 어떻게 계산하고, 성능과 지연이 왜 달라지는지 쉽게 풀어보겠습니다.
LLM 추론의 두 단계: Prefill과 Decoding
LLM이 한 번의 답변을 만들어 내는 과정은 Prefill과 Decoding 두 단계로 나뉩니다. 성능 최적화를 위해서는 이 둘의 차이를 정확히 이해하는 것이 관건입니다.
1) Prefill: 입력을 한꺼번에 해석하는 구간
사용자가 ‘대한민국의 수도는 어디인가요?’처럼 6개 토큰으로 된 질문을 넣으면, 모델은 이 6개 토큰을 동시에 처리합니다. 이 단계는 대규모 병렬화가 가능해 GPU의 코어를 넓게 활용할 수 있고, 프롬프트가 길어져도 상대적으로 빠르게 끝납니다. 말 그대로 ‘질문 전체의 구조와 의도를 한 번에 파악’하는 구간입니다.
2) Decoding: 답을 토큰 단위로 생성하는 구간
Prefill 이후에는 모델이 답을 토큰을 하나씩 순차적으로 생성합니다. 예를 들어 ‘서울입니다’를 출력할 때 먼저 ‘서울’을 만들고, 그 결과를 포함한 문맥을 다시 입력으로 삼아 ‘입니다’를 예측하는 것이죠. 이 과정은 본질적으로 순차적이어서, n번째 토큰을 만들기 전에는 반드시 n-1번째 토큰의 계산이 끝나 있어야 합니다.
여기서 병목이 생깁니다. 토큰이 생성될 때마다 모델의 거대한 파라미터와 지금까지의 대화 맥락을 담은 Key-value (KV) 캐시를 GPU의 고대역폭 메모리(HBM)에서 반복적으로 읽어야 합니다. KV 캐시는 어텐션(Attention) 메커니즘의 중간 계산 결과물인 Key(K)와 Value(V)를 GPU 메모리에 저장해두는 일종의 ‘메모장’입니다. 이 비용이 토큰 수만큼 누적되기 때문에, Decoding이 LLM 추론 속도를 좌우하는 핵심 병목이 됩니다.
LLM의 심장, 왜 GPU인가
LLM이 다음 토큰을 예측하는 추론(Inference)은 방대한 수치 연산의 연속입니다. 여기서 GPU가 왜 필수적인지 이해하려면 인공신경망의 기본 단위인 뉴런(Neuron)부터 보아야 합니다.
뉴런은 여러 입력 x에 각기 다른 가중치 w를 곱해 모두 더하고, 편향 𝑏를 더한 뒤, 그 결과에 활성화 함수 𝑓를 적용해 출력합니다.
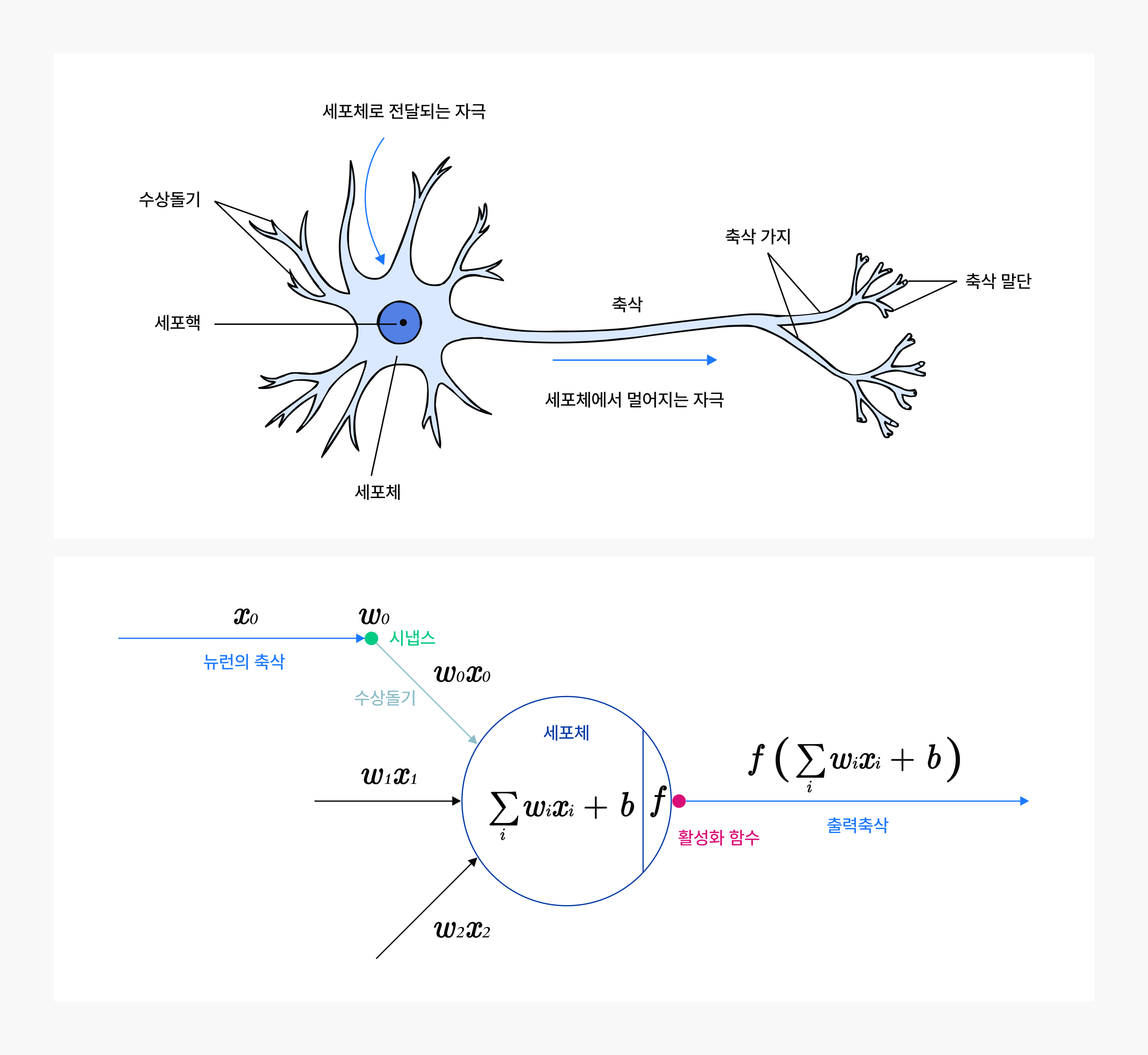
[그림 1: 생물학적 뉴런(위)과 뉴런의 수학적 모델(아래)]
출처: CS231n: Deep Learning for Computer Vision
이 뉴런이 층(Layer) 단위로 수천, 수만 개씩 겹겹이 연결된 것이 LLM입니다. 한 층의 출력은 다음 층의 입력이 되고, 이 과정이 깊이 방향으로 반복되죠. 중요한 점은, 층 전체의 연산이 ‘큰 행렬 곱셈’ 하나로 표현된다는 사실입니다. 행렬은 숫자를 가로,세로 격자로 배열한 표입니다. 신경망의 한 층에서 일어나는 수많은 곱셈과 덧셈은, 결국 큰 행렬 두 개를 한 번 곱하는 계산으로 묶어 표현할 수 있죠.
우리가 흔히 말하는 LLM의 파라미터 수는 곧 이 가중치 행렬들을 이루는 원소의 총합을 뜻합니다. 예를 들어 70억(7B) 파라미터 모델은 가중치 행렬들에 70억 개의 숫자가 들어 있다는 의미이며, 추론은 이 거대한 수치들을 동원해 층마다 행렬 곱셈을 반복해 나가는 과정입니다. 다시 말해, LLM의 계산 복잡도와 속도는 곧 얼마나 큰 행렬을 얼마나 자주, 얼마나 빠르게 곱하느냐에 의해 결정됩니다.
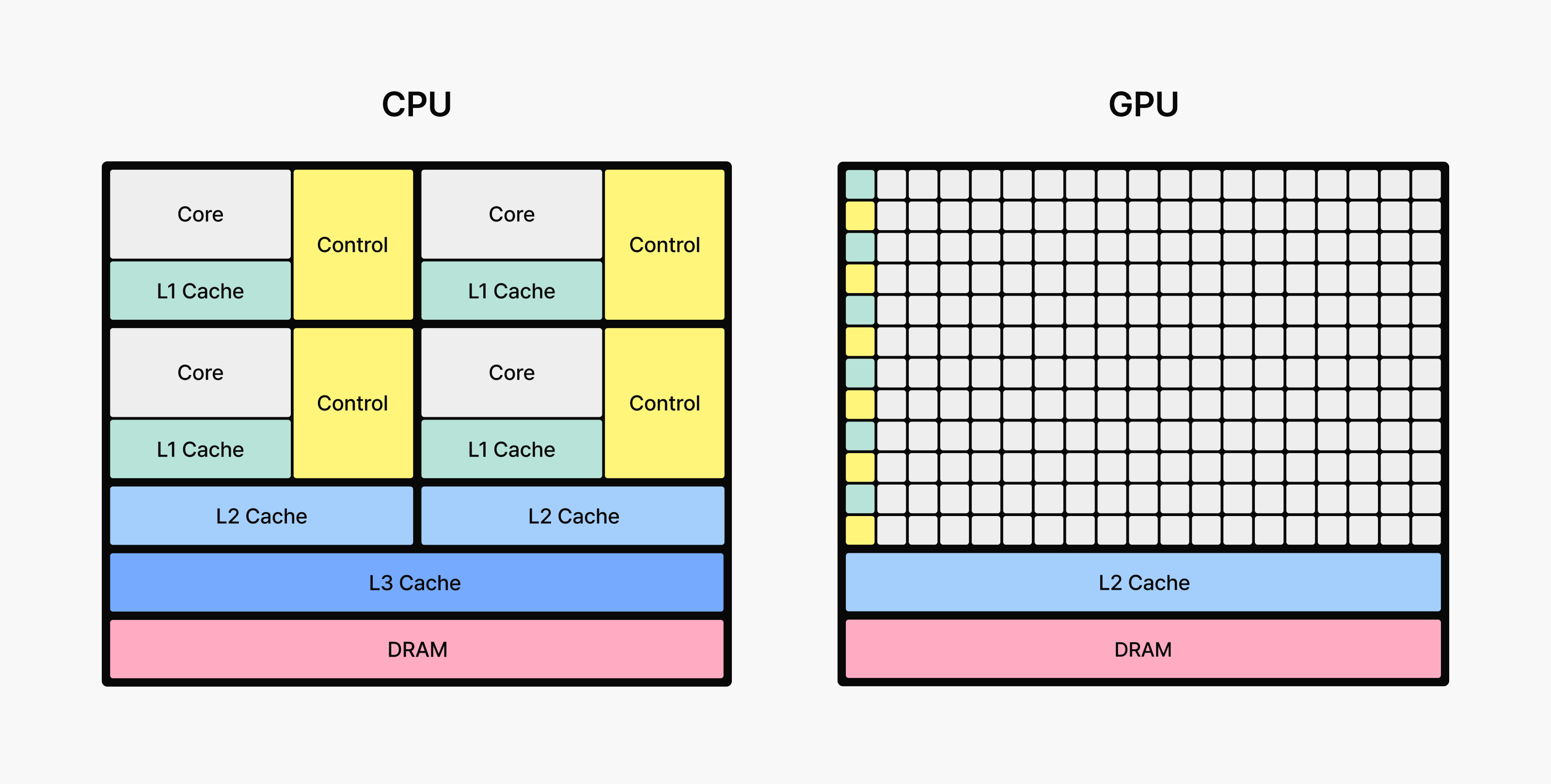
[그림 2: 데이터 처리에 더 많은 트랜지스터를 사용하는 GPU]
출처: NVIDIA CUDA C++ Programming Guide
이처럼 단순하지만 반복이 많은 계산을 대규모로 동시에 처리하는 데 특화된 하드웨어가 GPU(Graphics Processing Unit)입니다. 원래는 3D 그래픽을 위해 설계됐지만, 수천 개의 연산 코어가 동일한 연산을 병렬로 수행할 수 있어 대형 행렬 연산에서 탁월한 성능을 발휘합니다. LLM처럼 거대한 가중치 행렬을 계속 곱하고 더해야 하는 모델을 빠르고 효율적으로 구동하려면, GPU가 사실상 필수적입니다.
비유하자면, CPU가 다양한 일을 순차적으로 처리하는 소수의 전문가라면, GPU는 단순 연산을 동시에 수행하는 거대한 작업팀에 가깝습니다. LLM 추론의 병목이 바로 이 행렬 곱셈에 있으므로, 많은 코어를 동원해 병렬 처리하는 GPU가 속도와 처리량을 좌우합니다.
최근에는 한 걸음 더 나아가, 행렬 연산만을 전담하는 전용 회로를 AI 가속기에 포함하는 흐름이 확산하고 있습니다. 대표적으로 시스톨릭 어레이(Systolic Array) 구조는 데이터를 규칙적으로 흘려보내며 곱셈, 덧셈을 연속 수행하도록 설계된 ‘행렬 연산 전용 파이프라인’입니다. 구글의 TPU 매트릭스 유닛, NVIDIA Tensor Core 등은 이러한 전용 구조를 활용해, 일반 GPU 코어 대비 훨씬 높은 행렬 처리 효율을 제공합니다. 결과적으로, 동일한 전력과 면적에서 더 많은 연산을 수행해 LLM 추론의 지연과 비용을 크게 낮출 수 있습니다.
마무리하며
이번 LLM 서빙의 모든 것 1편에서는 LLM이 어떻게 동작하며 토큰이란 무엇인지, GPU가 왜 필수인지 짚었습니다. 이어질 LLM 서빙의 모든 것 2편에서는 서빙 성능의 핵심 지표인 지연 시간(Latency)과 처리량(Throughput)을 소개하고, LLM이 사용자 요청을 실제로 어떻게 처리하는지 내부 동작을 자세히 풀어보겠습니다.
기대해 주세요!