
This post introduces a NAVER Cloud paper, Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging, that will be presented at ICML 2026—the most prestigious conference in machine learning and AI—this July in Seoul, Korea.
Choi Minsik (NAVER Cloud*, Korea University)
Kim Geewook (NAVER Cloud, KAIST)
* Internship
A new perspective on conflicting datasets
The standard recipe for building multimodal large language models (MLLMs) is converging on post-training with an instruction mixture—training data that blends many kinds of instruction-and-response data at ever-larger scale. As the range of abilities a model has to handle grows—perception, reasoning, OCR, document understanding, video understanding—so does the number and variety of datasets used to train it.
But feeding data of different kinds into a single training run doesn’t always produce good results. If anything, two problems become more pronounced as the scale grows.
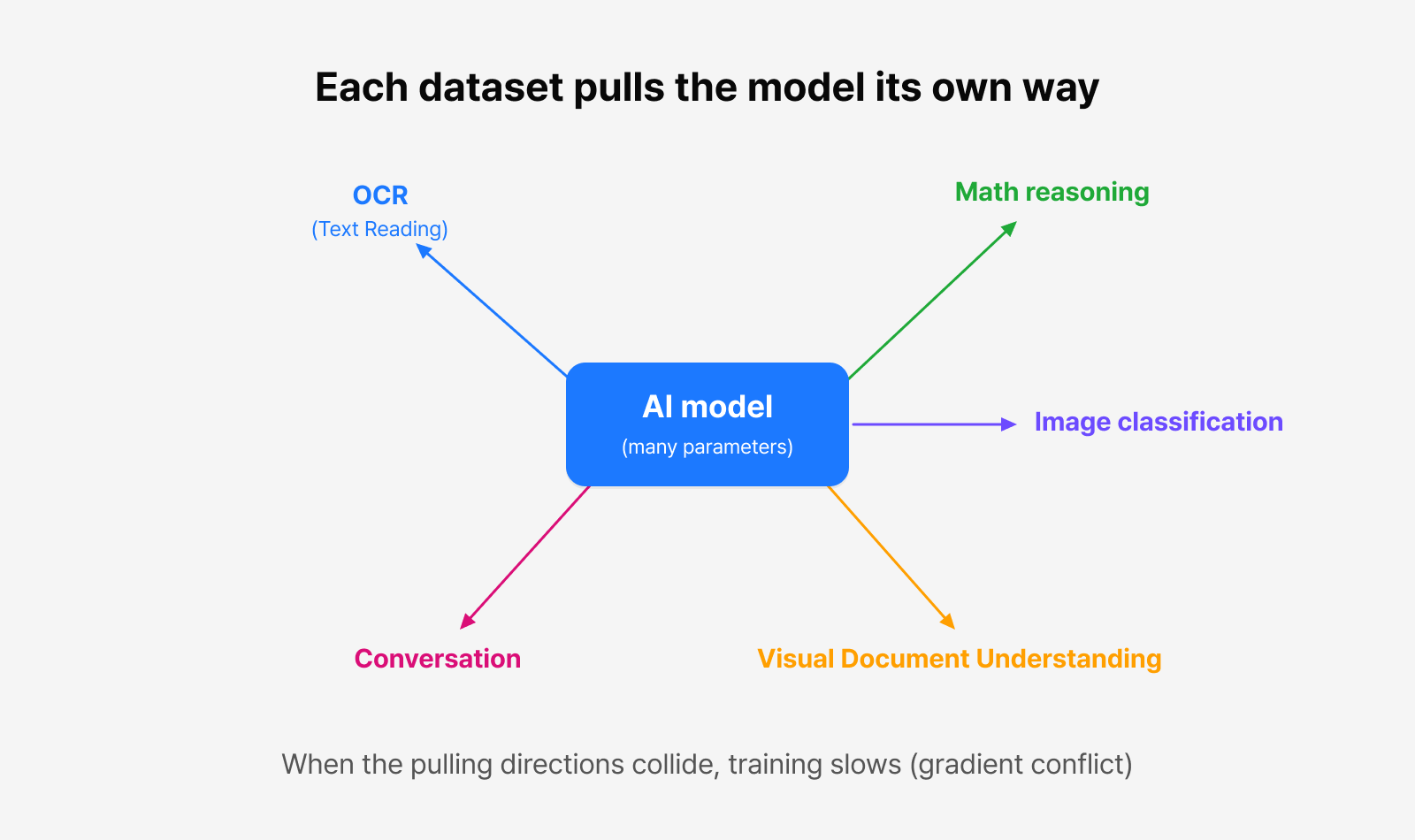
Figure 1. Gradient conflict arises when different datasets pull the model in different directions
First: conflict between datasets (gradient conflict)
When tasks with different goals compete inside a single model, you get negative transfer: training that makes the model better at one thing erodes its ability at another. It’s like several people pushing the same cart in different directions, and the result is lower training efficiency and weaker final performance.
Second: heavy communication cost
Joint training—the usual approach of training on all the data at once—has to synchronize gradients across GPUs with an all-reduce operation at every step, gathering the update directions each GPU computed into one shared direction. That effectively assumes a large cluster densely wired with ultra-fast interconnects like NVLink. So in settings where GPUs are spread across many servers or resources are fragmented, this approach can be inefficient or simply infeasible.
MERIT (Merge-Ready Instruction Tuning), the method introduced in our paper, tackles both problems at once. The core idea is surprisingly simple:
“Before you merge datasets, first split them well.”
MERIT first analyzes the relationships between datasets, groups similar ones together, fine-tunes each group independently, and then performs weight merging just once at the end—averaging the resulting models’ weights into one. Throughout training the groups never communicate, yet the end result is a single unified model.
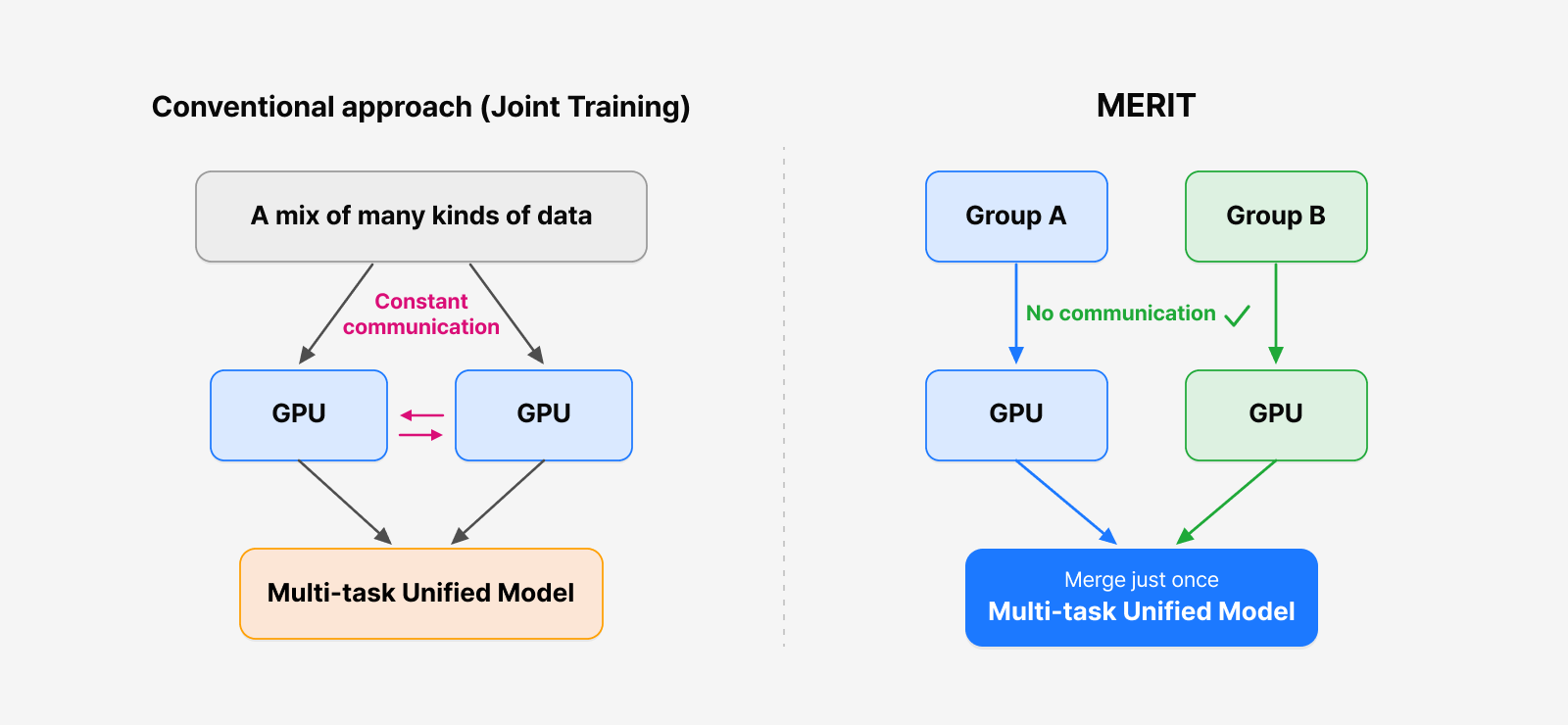
Figure 2. Conventional joint training, which synchronizes gradients at every step (left), versus MERIT, which trains each group independently and merges only once (right).
Why split first and merge later?
Conventional multimodal instruction tuning—training a model to follow a wide range of instructions—typically blends many datasets into one giant mixture and trains on a single cluster, continuously synchronizing gradients. Under this setup, conflict between datasets has been treated as a gradient-conflict problem: at every step, different data pull the model in opposing directions.
But does all the data really have to be trained together at once?
Our work argues the opposite: that properly separating datasets before training matters more. We first analyze the structure of gradient conflict between datasets, pull strongly conflicting datasets into separate groups, and bundle together datasets that share a similar training direction. Each group is fine-tuned independently with no communication between them, and once training is done we merge just once with token-weighted averaging—a weighted average proportional to how much data each group used.
This approach works because of merge-ready initialization—a starting point that’s well suited to merging. Post-training of modern MLLMs usually starts from a strong, already well-aligned checkpoint (for example, a model that has gone through the LLaVA training recipe). Models that start from such a well-aligned point tend to stay within a flat basin during fine-tuning—a broad, gently sloped region of low loss. Put simply, even when they’re trained on different datasets, the models still sit in similar regions of parameter space. So even though each group is trained independently, plain weight averaging—a simple element-wise average of each model’s weights at the end—can merge them naturally into one model. This echoes a phenomenon seen in the Model Soups line of work, where averaging multiple models yielded better performance.
The MERIT pipeline
Looking more closely, MERIT breaks down into five stages.
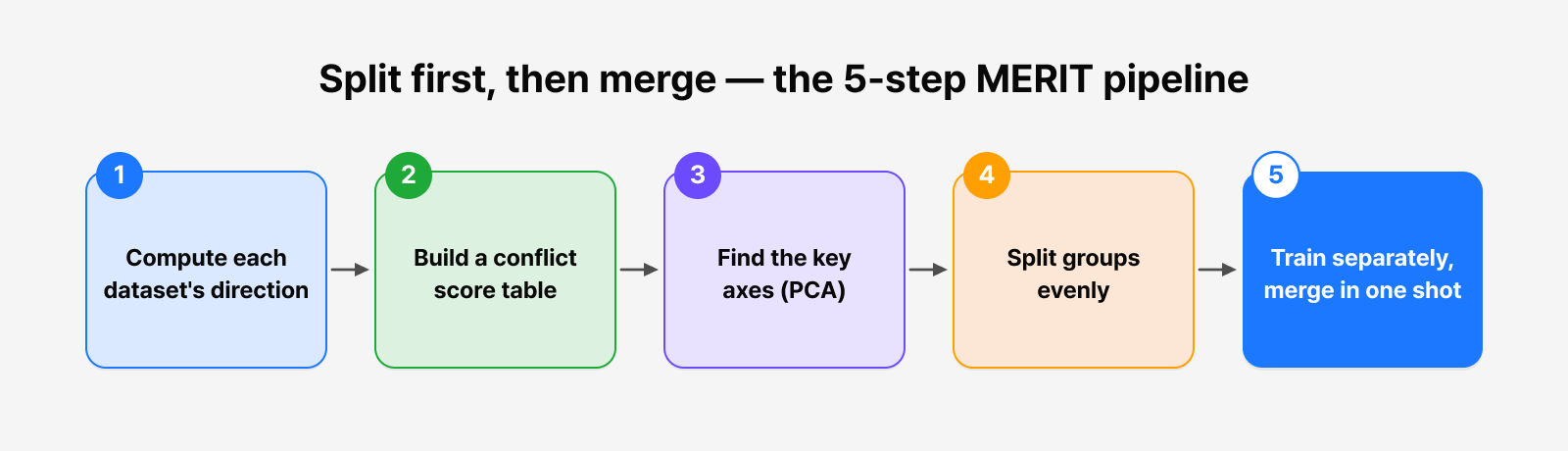
Figure 3. MERIT’s five-stage pipeline: gradient estimation → conflict matrix → PCA → balanced partitioning → independent training and merging
1. Computing each dataset’s direction: Dataset-level gradient estimation
For each dataset, we sample about 200 examples and compute a gradient at the merge-ready initialization point that represents that dataset. In effect, it summarizes “which direction does this dataset pull the model?” as a single arrow. You might wonder whether 200 samples is enough, but empirically we found the gradient direction enters a stable, converged regime starting at around 160–200 samples.
2. Building a conflict score table: A cosine-similarity-based conflict matrix
Next, for each pair of datasets we use cosine similarity to measure how similar their gradient directions are.
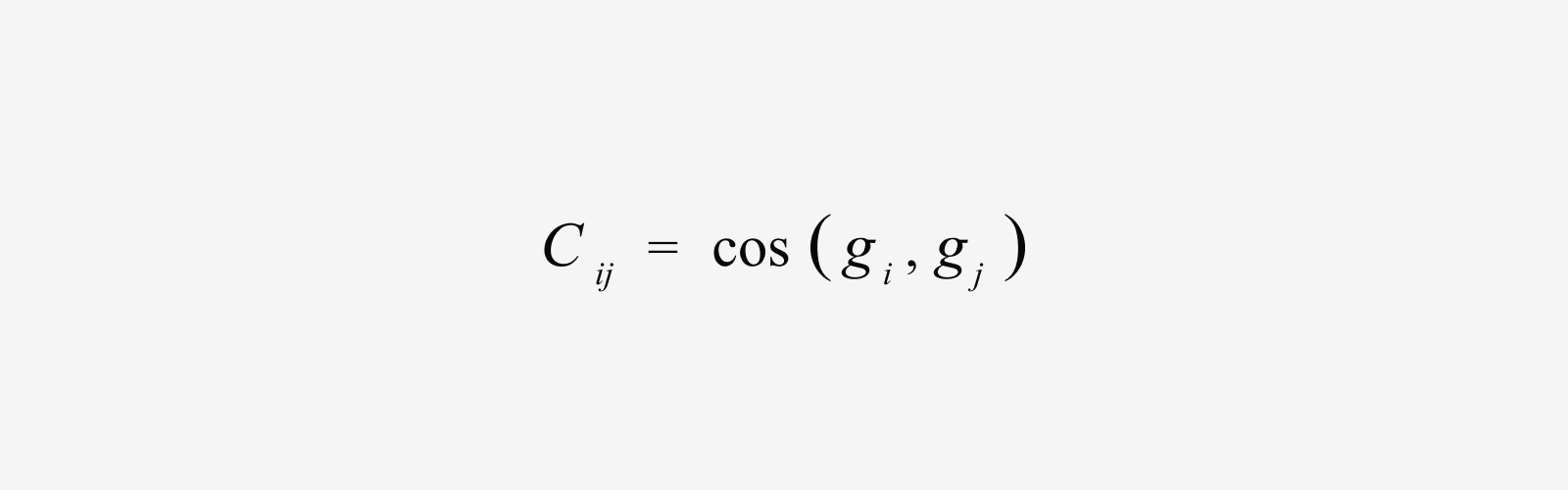
A higher value means the two datasets update the model in similar directions, so training them together is likely to produce little conflict. A low or negative value means they pull the model in opposing directions, making gradient conflict more likely. Think of it as a table that puts a number on whether two datasets face the same way or turn their backs on each other.
3. Finding the key axes: Extracting dominant conflict axes with PCA
We then apply PCA to the conflict matrix C to extract the top r eigenvectors—the principal components, or representative axes—that best explain where datasets disagree. Each dataset is then placed in a new space defined by these axes, where each axis points in the direction of greatest disagreement between datasets. Put simply, it shows which topics the datasets diverge on most. This lets us summarize a vast web of conflicts as a few representative directions.
4. Splitting groups evenly: Balanced conflict-aware partitioning
We recursively split the datasets based on their PCA coordinates. Splitting purely by the sign (+/−) of a coordinate can pile too much data into one group, so we designed MERIT’s algorithm to keep each group’s size as balanced as possible.
Repeating this recursively divides the datasets ever more finely: one split yields 2 groups, a second yields 4, a third yields 8. Datasets with similar characteristics end up in the same group, while conflicting datasets are naturally separated.
5. Train separately, merge in one shot: Independent training and a single merge
Once the datasets are divided into groups, we fine-tune each group independently from the same initial checkpoint. No communication takes place between groups during this stage.
When training is finished, we merge the models from each group into one. This happens just once, using token-weighted averaging—a weighted average proportional to the amount of data.
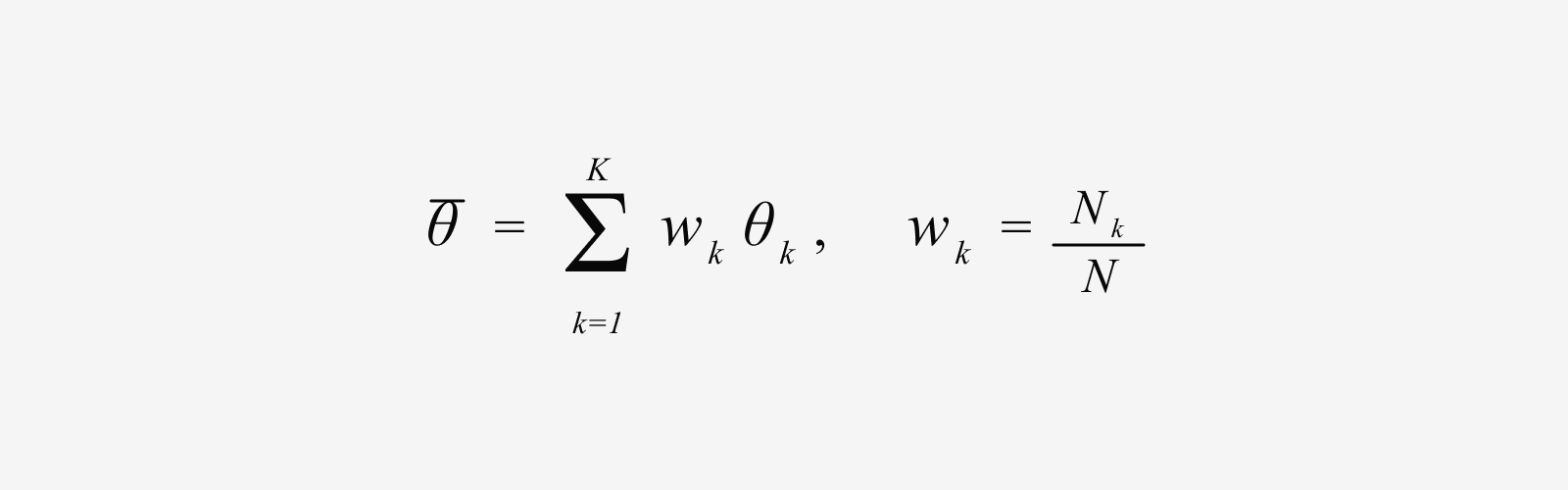
Here, Nk is the number of tokens group k used for training. The important point is that MERIT does not train on more data than existing methods. We kept the total number of training tokens identical for MERIT and conventional joint training. So if MERIT performs better, the reason isn’t extra training—it’s the training strategy itself: splitting the data by its conflict pattern and then merging it back together.
The heart of MERIT: Why does averaging the models preserve performance?
Going a little deeper, MERIT’s effectiveness can be explained from the perspective of the loss landscape. Loss is a measure of how wrong the model is, and training proceeds in the direction that lowers it. We assumed that the models trained on each group all sit within a similar-performance solution region (a flat basin). A flat basin is a relatively broad, flat region where performance barely changes even when the model parameters shift a little.
For a model checkpoint θₖ in the same flat basin, approximating the loss as a local quadratic shows that the weighted-average model’s loss is less than or equal to the weighted average of the individual models’ losses. The gap works out to the curvature-weighted variance below.
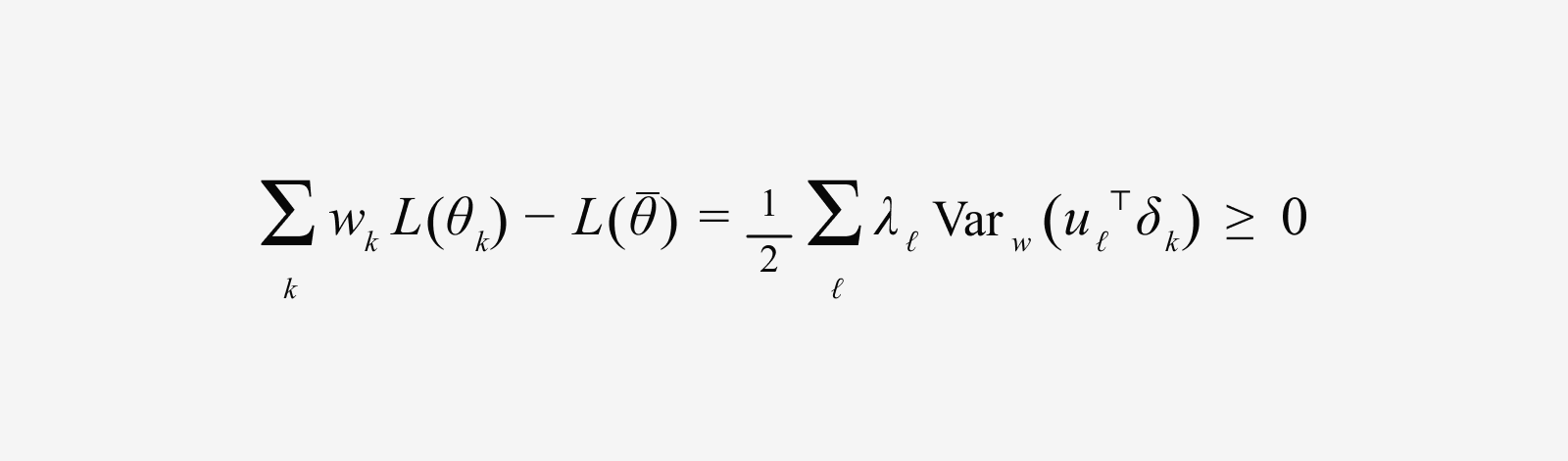
Here, λℓ is an eigenvalue of the Hessian—it captures how strongly a given direction affects model performance. The larger λ is, the more even a small change in that direction can shift performance. uℓ is the corresponding eigenvector—the direction of a particular change in the model’s parameter space.
What this means is intuitive: in directions where λℓ is large—that is, high-curvature directions where performance changes sharply—the more differently the models move, the greater the gain from merging. Put simply, when each model has learned different information along directions that strongly affect performance, merging can preserve each model’s strengths while smoothing out bias and conflict.

Figure 4. Even when individual models scatter off in the wrong directions, the weighted average cancels out that variation and converges on a better single point.
MERIT’s PCA-based splitting takes advantage of exactly this. When groups are split along the main gradient conflicts between datasets, each group learns updates in different directions. Merging these models then averages out those differences, effectively reducing unwanted variation—especially along the high-curvature directions where performance is most sensitive.
You can think of merging as a kind of curvature-aware spectral filter. In conventional joint training, the updates from every dataset interact throughout training; MERIT instead trains independently first and then, during merging, averages out the differences that arise along high-curvature directions. Merging acts a bit like an editor pulling together a debate full of conflicting opinions: among the differences each independently trained model picked up, the disagreements along the directions that most affect performance get smoothed away. The result is that conflict between datasets is eased while the information each model learned is consolidated into one. In short, MERIT eases gradient conflict without any communication during training, and improves performance through merging.
Experimental results
1. Controlled ablation: Where do MERIT’s gains come from?
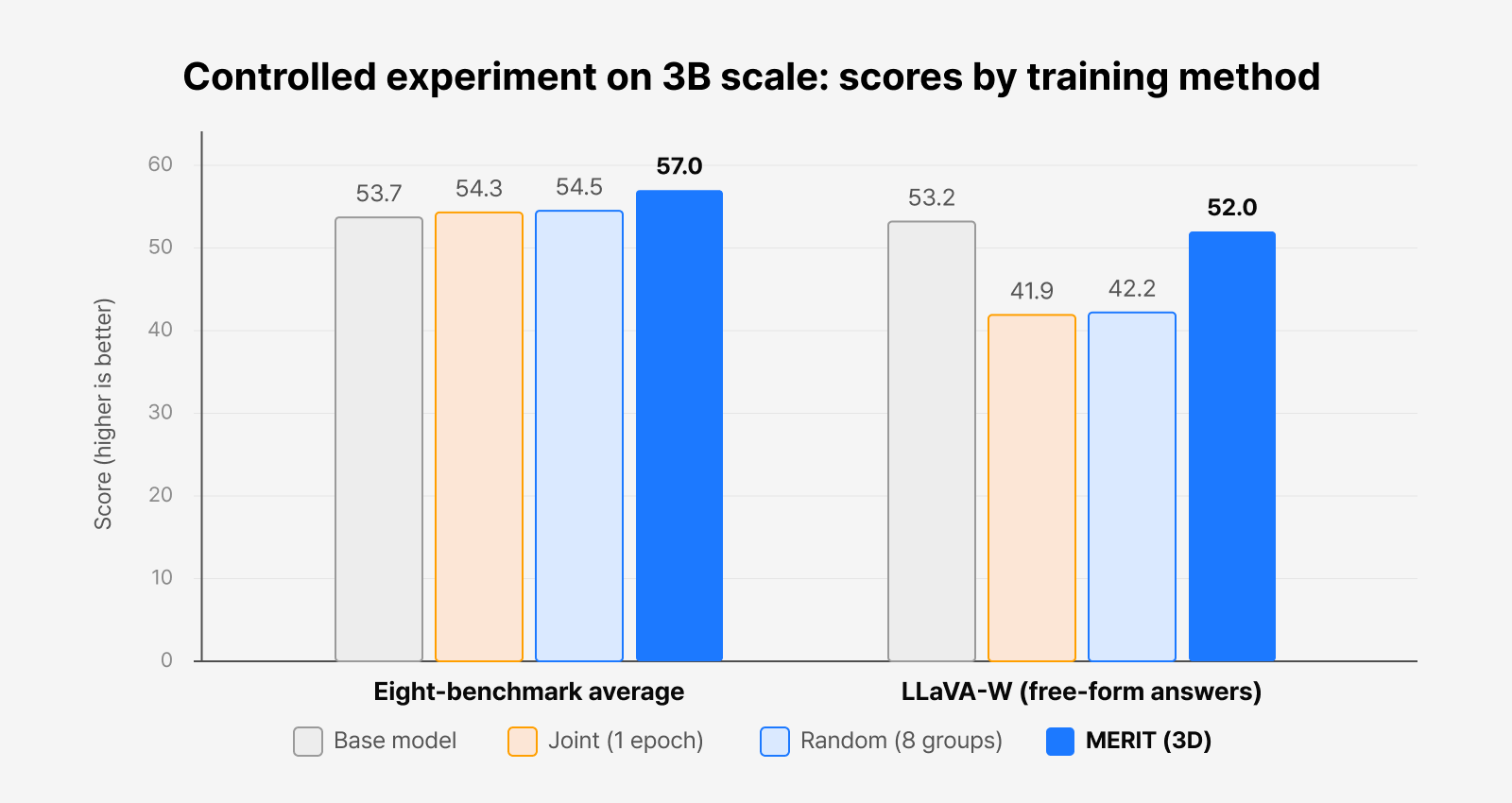
Figure 5. The 3B controlled experiment. MERIT (3D) scores highest on the eight-benchmark average, and on free-form answers (LLaVA-W) it holds near the original level while joint training collapses.
In experiments with Qwen2.5-VL-3B on 136 Vision-FLAN tasks, one of the most interesting findings was that even a plain random split—dividing datasets at random and then merging—modestly outperformed conventional joint training. This shows that thanks to merge-ready initialization—the easy-to-merge starting point—weight merging itself delivers some gain no matter how you split the data.
But once you apply a conflict-aware split—dividing datasets with their conflicts in mind—the gap widens considerably. A random split only divides the models’ differences with no control, whereas MERIT splits along the main conflict axes, steering those differences in the direction where merging helps most.
The effect is especially clear on free-form response evaluations like LLaVA-W. Joint training’s score falls into the 41.9–42.8 range, whereas MERIT scores 52.0—much closer to the original model’s 53.2. It effectively cushions the performance drop that comes from training on many datasets at once. This is closely tied to the short-answer collapse we’ll describe later. The full results are in the table below.
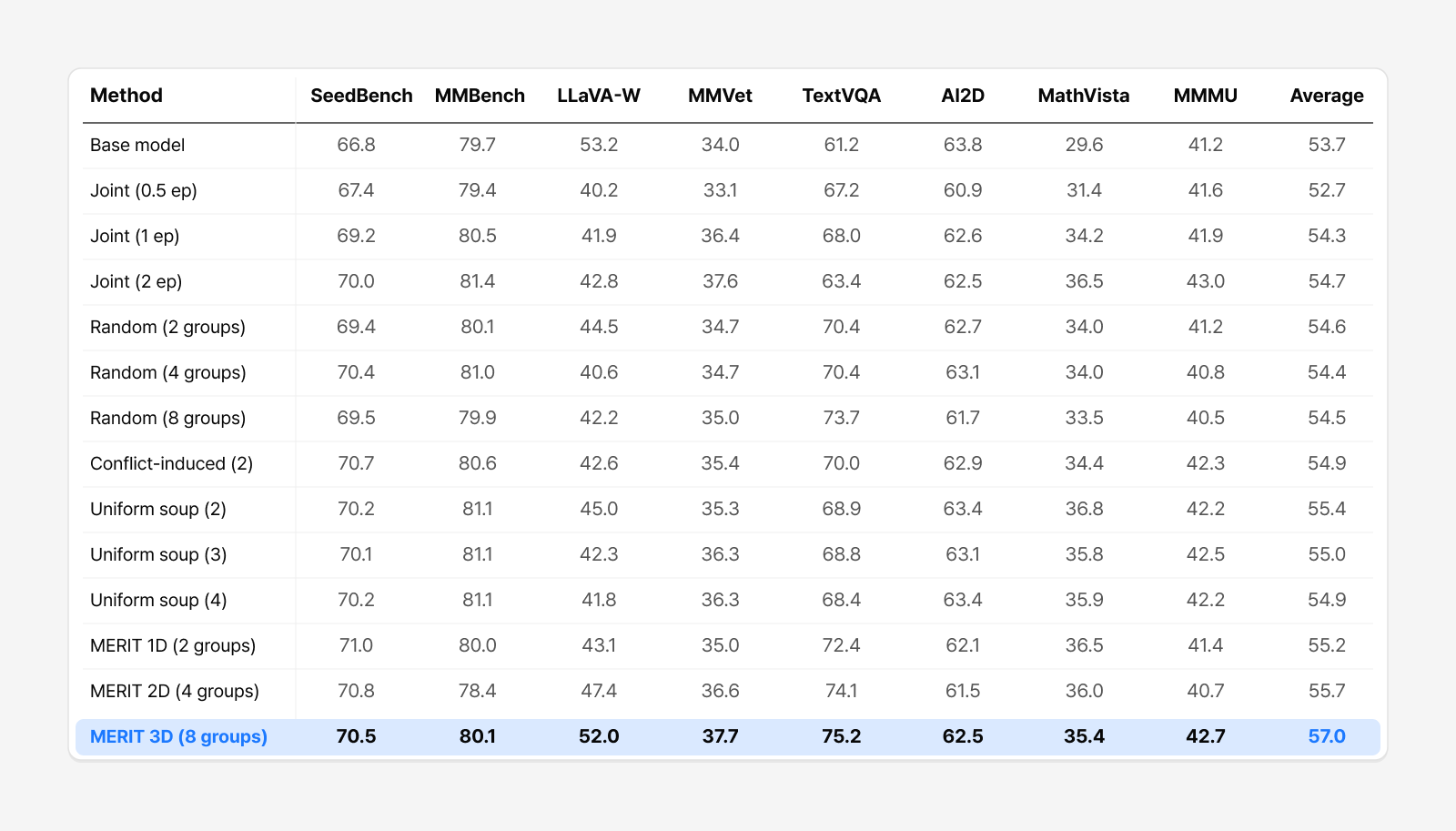
Table 1. Full results of the 3B controlled experiment (Table 2 in the paper; Qwen2.5-VL-3B, 136 Vision-FLAN tasks). Bold = best average.
2. Large-scale MLLM setting: Does the effect hold as model and data scale up?
The previous experiment verified MERIT’s effect in a controlled setting; here we looked at whether the same trend holds with a larger model and more data. We saw a similar trend in a larger-scale setup using Qwen2.5-7B and a 1.6M mixture.
With the same data budget (0.7M + 1.6M), Joint FFT and MERIT have similar overall averages (54.9 → 55.4), but meaningful differences show up in the individual benchmarks. MERIT scored higher on items where free-form responses and complex reasoning matter, such as MMVet (32.5 → 35.1) and MathVista (32.9 → 35.4). On text-rich evaluations, it dipped slightly.
This trend held in the scaled-up 3.6M setting too. MERIT’s overall average improved from 60.9 to 61.5, and the gap was even starker on LLaVA-W, which evaluates free-form responses. Joint FFT’s score dropped sharply from 67.1 to 50.2, whereas MERIT held at 66.2 and preserved nearly all of the original model’s performance. This shows that the “style preservation” effect seen in the earlier controlled study holds at large scale too.
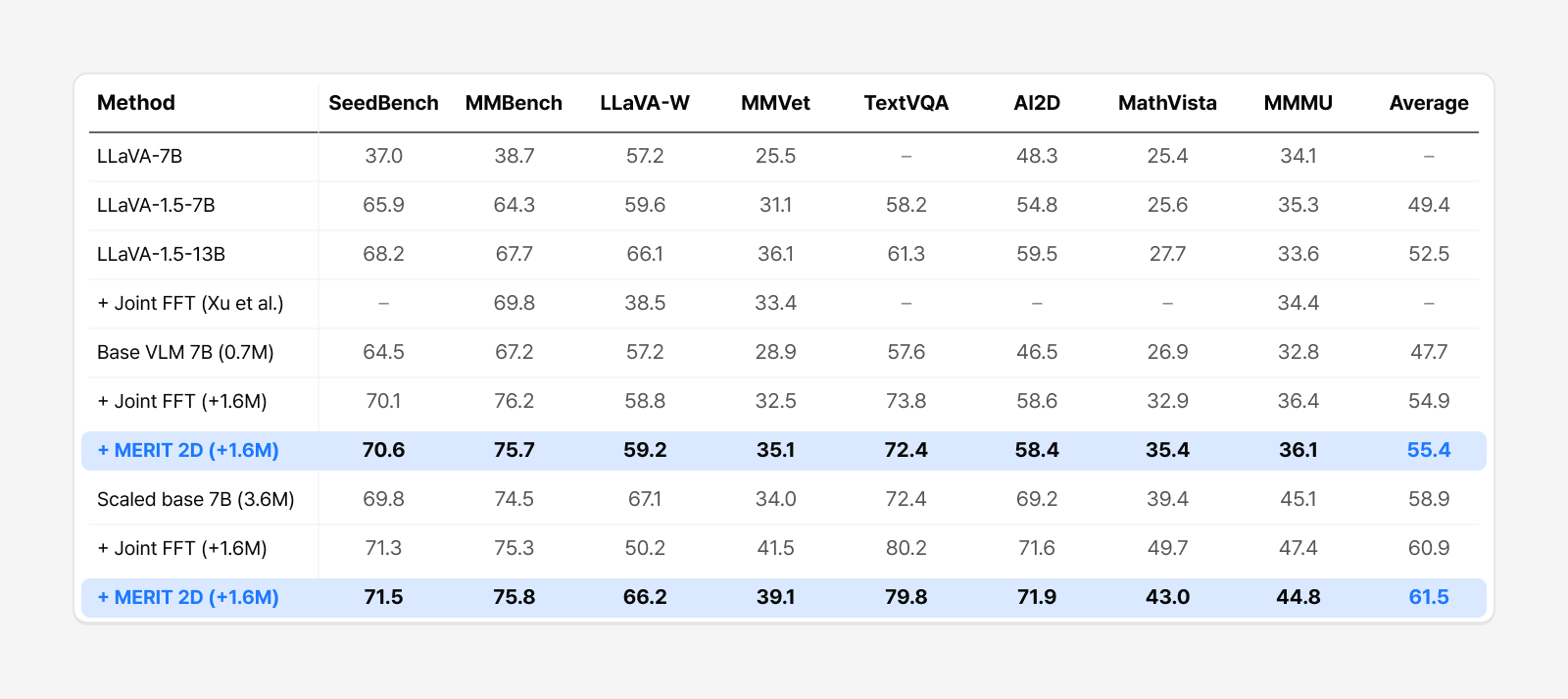
Table 2. Full results of the 7B experiment (Table 3 in the paper). Joint FFT vs. MERIT (2D) at the same training budget, across two base models.
3. Text-only instruction tuning: MERIT’s effect holds for text models too
We applied the same pipeline to pure text-only instruction tuning, using Qwen2.5-3B and a FLAN mixture. MERIT (2D) scored 58.4 on average across eight text benchmarks—ahead of joint training (1 epoch, 57.6) and, at half the training budget, matching or beating both the double-trained joint training (2 epochs, 58.3) and random split (58.2–58.3). MERIT’s gains, in other words, aren’t unique to a particular multimodal setting. A conflict-aware splitting strategy works just as well for text-based instruction tuning, reaching performance equal to or better than conventional training with less compute.
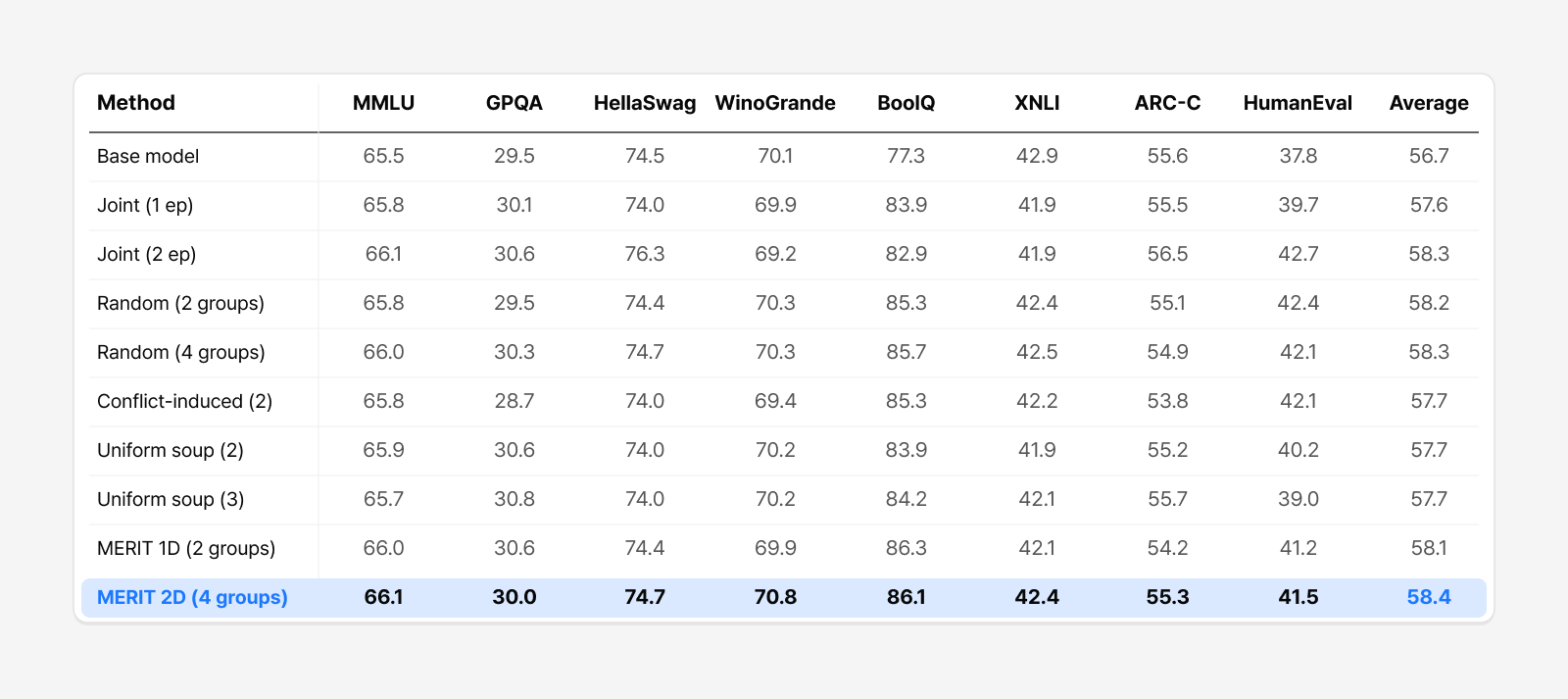
Table 3. Full results for text-only instruction tuning (Table 4 in the paper; Qwen2.5-3B, 66 FLAN tasks).
Two details worth a closer look
1. Why short-answer collapse disappears
On benchmarks like LLaVA-W, which evaluate not just a response’s usefulness but also user preference and response style, joint training often produces responses that converge toward an overly short, simple form (short-answer collapse). This is understood to happen when short-form tasks like Vision-FLAN compete with conversational tasks in the same training run: one side prefers concise answers while the other calls for rich explanation and interaction, so the two clash during training.
MERIT, by contrast, separates these into different groups from the start, so each style is trained while kept independent. As a result, conversational ability is better preserved even after the final merge, and the diversity and richness of responses tend to hold up too.
2. A note on practicality
MERIT requires one preprocessing step before training. If that step were too heavy it would undercut the method’s practicality, so we measured its cost too. In our 3B experiments, gradient extraction took about an hour and a half and computing the similarity matrix about 30 minutes—well within reason compared to the actual training time. And adding m new datasets doesn’t require rerunning the whole pipeline: you only need to compute the cross-similarity with the existing datasets, which costs about O(Tm) (where T is the number of existing datasets and m the number of newly added ones). That makes it especially handy in practice, where you run many data ablations while swapping data in and out. In short, MERIT adds just one lightweight preprocessing cost and doesn’t complicate the training process itself. So in settings where GPU resources are scattered across servers or cluster configurations are limited, it’s a genuinely attractive approach.
Closing thoughts
The most important message of this work is that when you handle a heterogeneous instruction mixture, how you merge the data matters—but how you split it matters just as much.
Weight merging research so far has mostly focused on how to effectively merge models trained on identical or similar data. MERIT instead takes on models trained on different data partitions and tackles head-on the question of which split leads to a better merge. We showed—both theoretically and experimentally—that a conflict-aware split is a key factor in determining post-merge model performance.
Ultimately, instruction tuning doesn’t have to be seen only as the problem of training on one giant mixture; it can also be seen as a question of which data to train together and which to keep apart. As instruction mixtures keep growing and compute environments become more distributed, how to split datasets will only become a more important design choice.
You can find the full details in the paper, Decentralized Instruction Tuning: Conflict-Aware Splitting and Weight Merging.