
Why LLM compression matters
Recent trends in LLM performance improvement have moved away from simply scaling model size. Instead, new approaches are gaining momentum: ensuring high-quality training data, improving the precision of smaller models, and prioritizing cost efficiency during training.
As LLM-driven services grow at unprecedented speed, new constraints are emerging. Some services prioritize latency because user response speed is critical or they require real-time interaction. Other services can tolerate slightly higher response times but need massive throughput to handle large-scale traffic or reduce operational costs. As these demands become increasingly diverse, it’s essential to develop LLMs that can satisfy all these varied requirements. The challenge is that creating different models for every use case isn’t practical because the one-time training cost for each model is enormous.
For organizations, it comes down to selecting and deploying models with the right architecture and size for their specific services—knowing that operational costs can vary dramatically even between models with identical parameter counts depending on how a model is trained and optimized. The core issue is the immense cost and resources needed to retrain existing LLMs.
This is where HyperCLOVA X makes a difference. We’ve developed a training strategy that achieves both efficiency and high performance—a practical solution that integrates pruning and knowledge distillation.
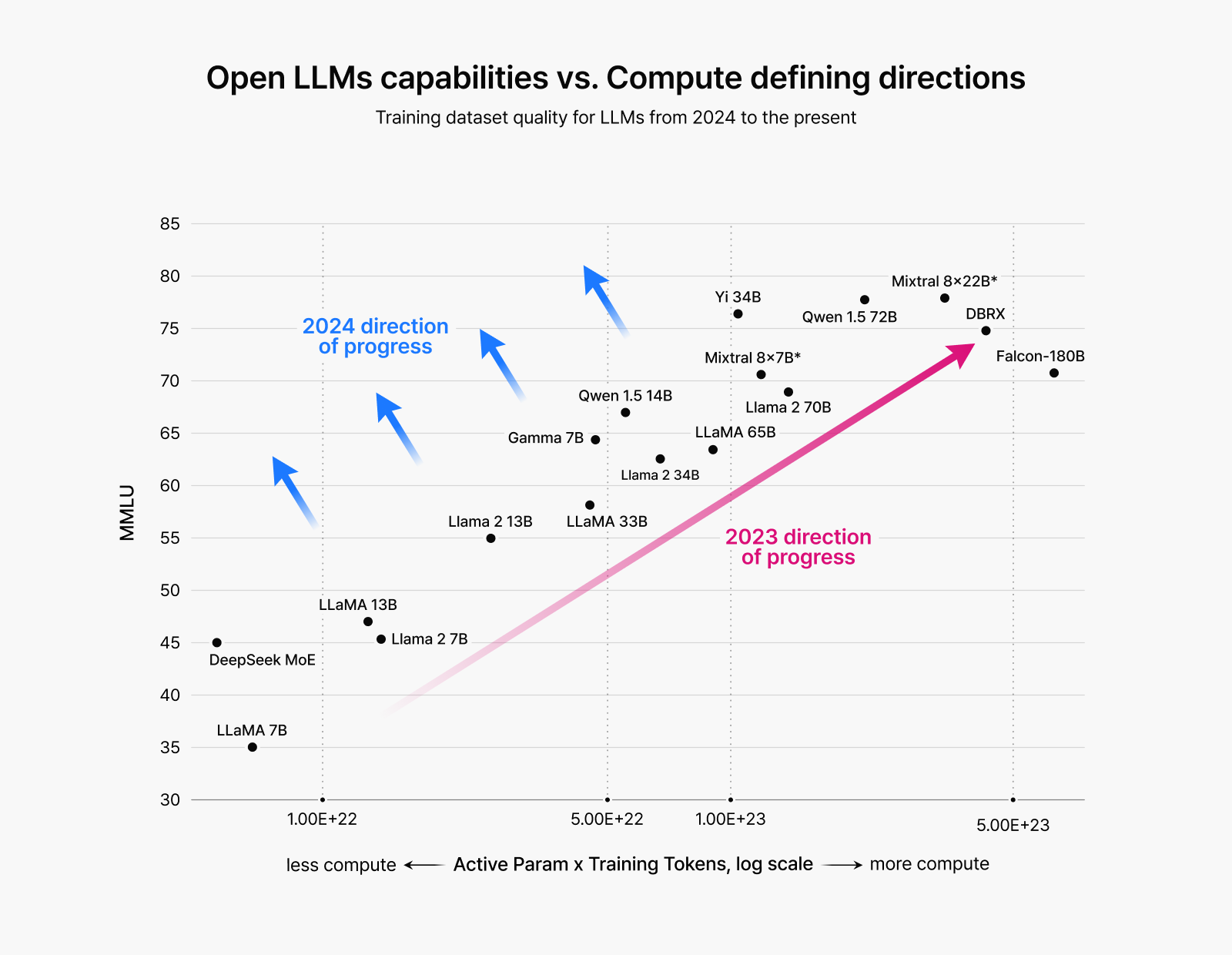
▲ The shift in LLM development approach: Until 2023, the mainstream approach centered on large-scale training with bigger models. From 2024, the focus shifted to performance-centered development through enhanced data quality.
Core techniques for LLM cost reduction: Pruning and knowledge distillation
For HyperCLOVA X, we identified two critical model optimization techniques—pruning and knowledge distillation. Pruning eliminates less important parameters while knowledge distillation transfers intelligence from larger models to more compact ones. But how exactly do they reduce costs while maintaining performance? Let’s explore the principles behind each approach.
Pruning: Making larger models lightweight
Much research has focused on reducing LLM development costs through model compression. One such approach is pruning, which determines the importance of parameters in an already-trained model and removes those with low importance to reduce memory requirements. You can also exclude these removed parameters from computation, decreasing processing overhead.
The pruning method varies depending on how you structure parameter removal. Structured pruning removes parameters by entire neuron units, while unstructured pruning evaluates the importance of each individual parameter.
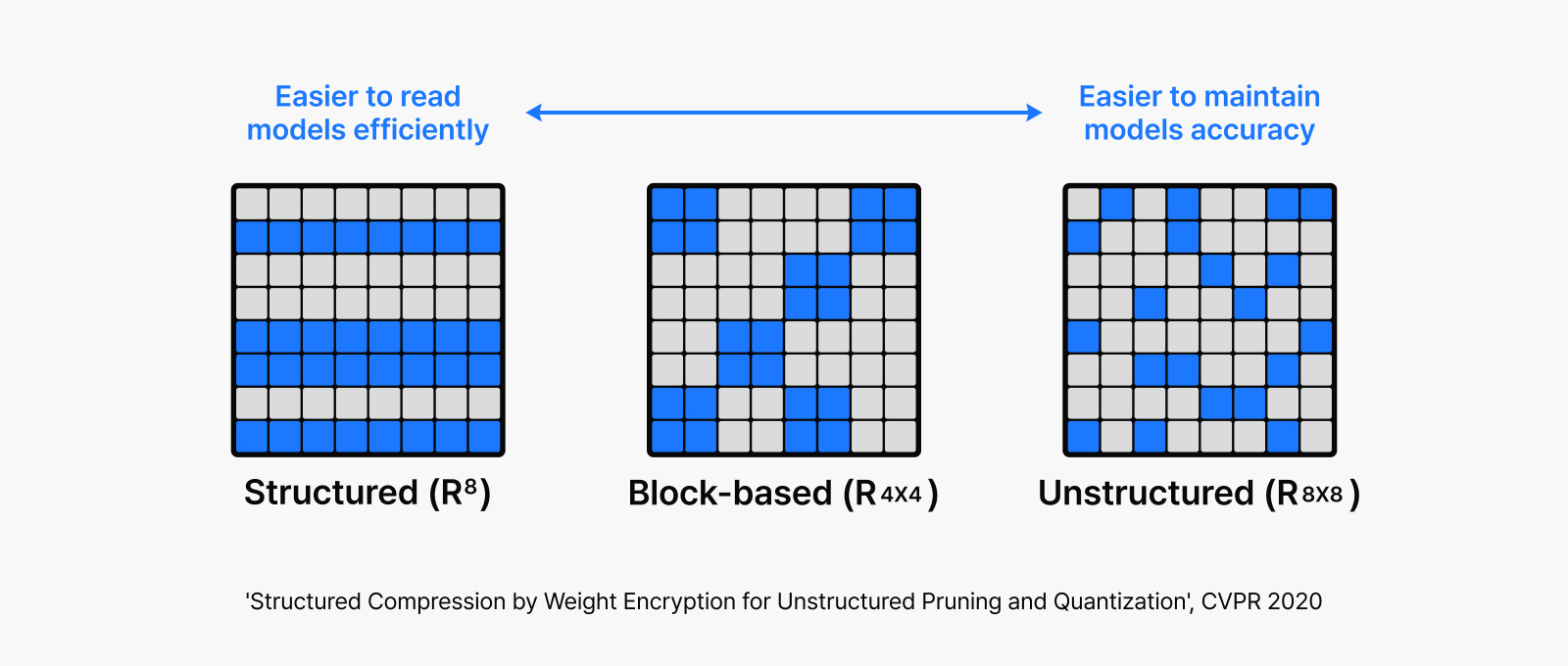
Unstructured pruning selectively removes unimportant parameters, creating the sparse, hole-filled pattern shown in the right image above. This irregular structure makes hardware acceleration difficult; unless your hardware provides specialized support, achieving meaningful speed improvements with unstructured pruning on current GPU architectures is challenging.
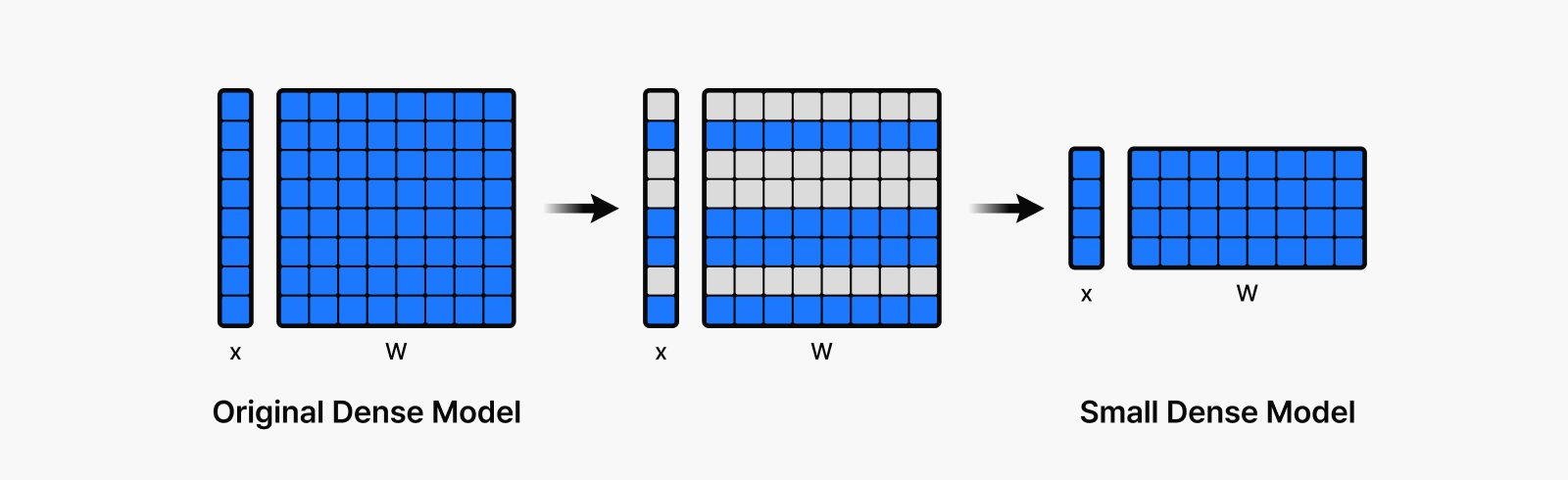
Structured pruning takes a different route, allowing you to reconfigure the model into smaller, more compact operations with fewer parameters by keeping only the remaining neurons. As illustrated in the left image above and the diagram below, this approach makes it much more hardware-friendly for acceleration.
Structured pruning comes with an important trade-off though. When removing entire structural units, you risk eliminating not just unimportant parameters but also valuable ones that happen to be in the same unit. This can lead to significant accuracy drops after pruning, which remains a key challenge for structured pruning in real-world applications.
Knowledge distillation: Transferring knowledge from larger models to smaller ones
Many methods have been proposed to restore LLM performance that may be reduced due to pruning. Research is particularly active in exploring how to compensate for performance loss resulting from model compression. Recently, knowledge distillation has emerged as a promising solution in the LLM field as well.
Knowledge distillation works by transferring the intelligence that large, sophisticated teacher models have acquired to smaller student models. The key insight is that student models learn from both the correct answers (labels) and the output patterns (logits or output probability distributions) of the larger teacher models. This approach allows even compact models to effectively mimic the larger model’s generalization capabilities and decision-making standards.
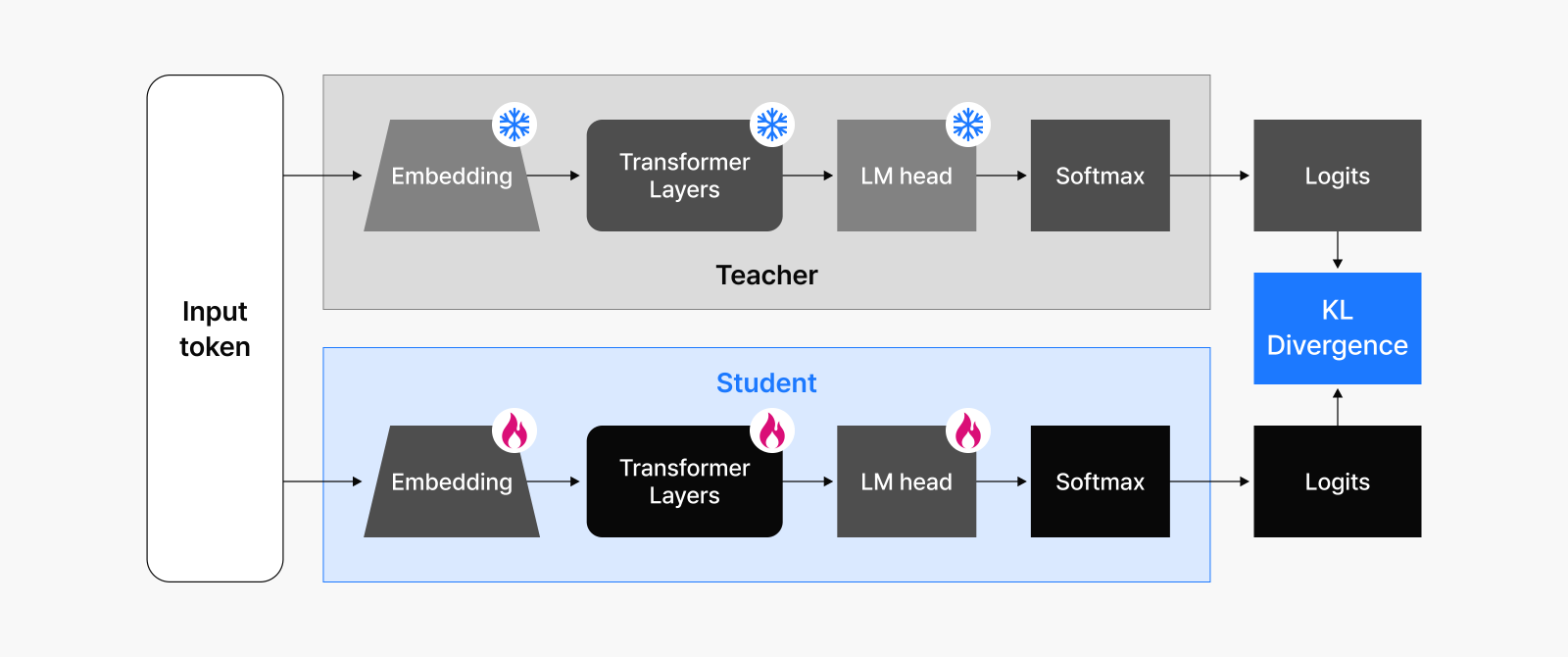
Student models trained with knowledge distillation can create even greater value when combined with pruning methods. Using a pruned model from a larger teacher model as the student model can significantly accelerate the training process. Since the pruned model already retains most of the teacher’s knowledge, the distillation training process becomes much more efficient than traditional training methods.
The synergy is clear: pruning makes the model smaller and more lightweight, while distillation adds intelligence back to this compact model. HyperCLOVA X seamlessly combines these two technologies to establish an LLM training strategy that achieves high performance at low cost. This strategy goes beyond simply combining different technologies—it provides a flexible foundation for producing optimized models tailored to diverse service requirements.
HyperCLOVA X optimization process: Efficient training for high-performance models
HyperCLOVA X focuses on solving a key challenge: producing small but high-performing models at significantly lower training costs. Beyond reducing expenses, the real value lies in designing models with the right size and structure for specific service requirements and delivering them when needed.
Traditional methods for producing various LLMs tailored to different services are resource-intensive and time-consuming. Even small models require substantial resources to maintain performance standards, typically needing trillions to tens of trillions of tokens for training. Smaller models often can’t fully utilize GPU computing power, making even small model training surprisingly costly.
By leveraging pruning and knowledge distillation, we’ve developed a cost-efficient training strategy that enables high-performance models while using significantly less time and GPU resources compared to traditional methods. We’ve refined these techniques and successfully implemented them in our newest HyperCLOVA X-SEED-Text-Instruct-0.5B model.
To learn more about our approach, read our related post “Planting the seeds for an AI ecosystem: Introducing HyperCLOVA X SEED, a commercial open-source AI.”
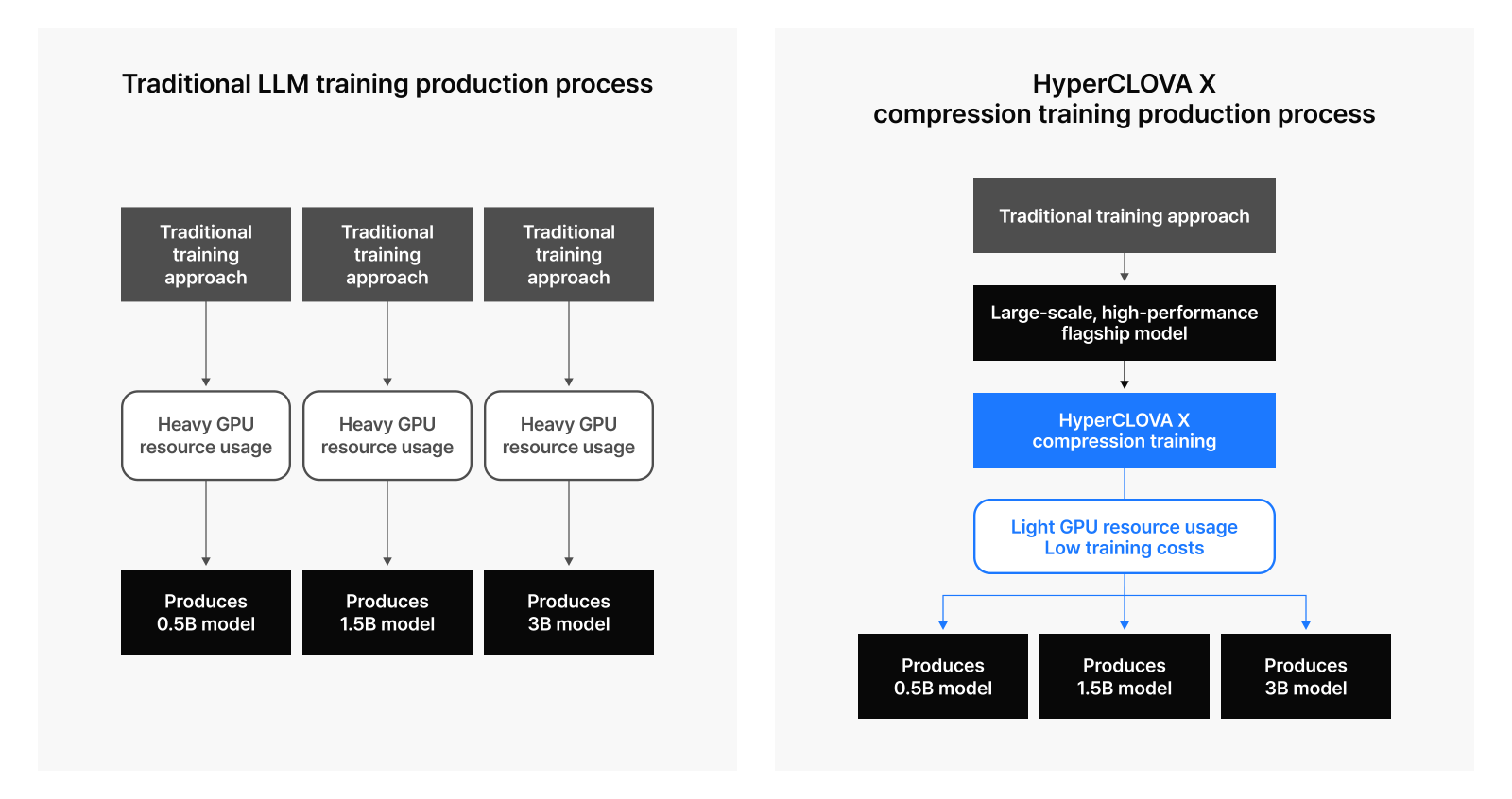
Real-world application: HyperCLOVAX-SEED-Text-Instruct-0.5B
Training efficiency breakthrough
HyperCLOVA X-SEED-Text-Instruct-0.5B demonstrates how effectively NAVER’s model compression technology performs in real-world scenarios. When compared to Qwen2.5-0.5B-Instruct, which has a similar parameter size, HyperCLOVA X achieved pre-training with significantly fewer resources.
| Pre-training resources | HyperCLOVAX-SEED-Text-Instruct-0.5B | Qwen2.5‑0.5B‑Instruct |
| A100 GPU hours | 4,358 | 169,257 |
| Cost (USD) | 6,537 | 253,886 |
The numbers tell a compelling story: HyperCLOVA X completed training with approximately 4,358 GPU hours and $6,537 USD. Compared to Qwen2.5-0.5B-Instruct, which requires 169,257 GPU hours and $253,886 USD, our model achieved nearly 39 times greater efficiency. This isn’t just about optimization—it represents a fundamental redesign of the resource and cost structure for model training.
While HyperCLOVA X-SEED-Text-Instruct-0.5B required significantly lower training costs than Qwen2.5-0.5B-Instruct, its performance demonstrates that efficiency doesn’t mean compromise.

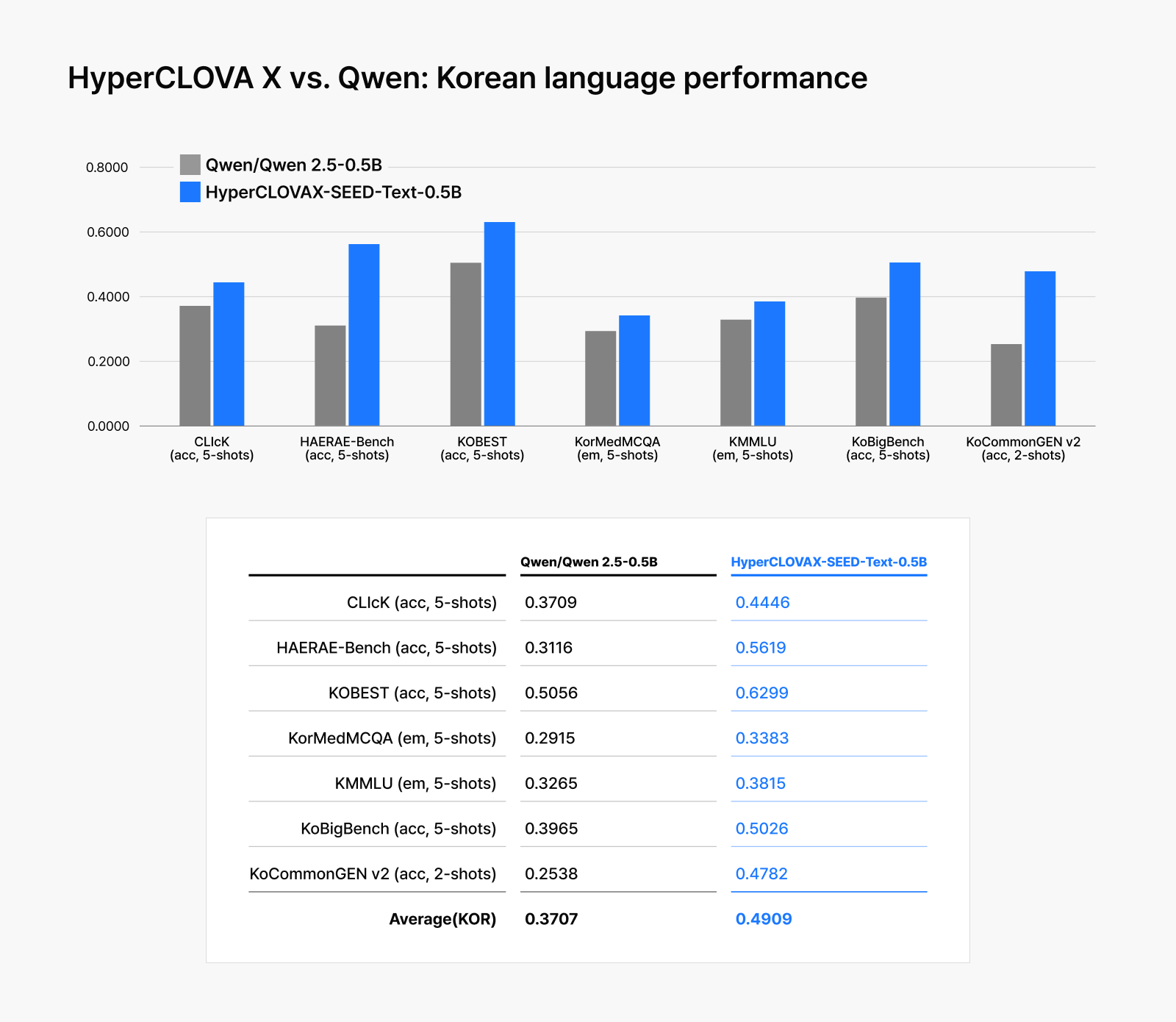
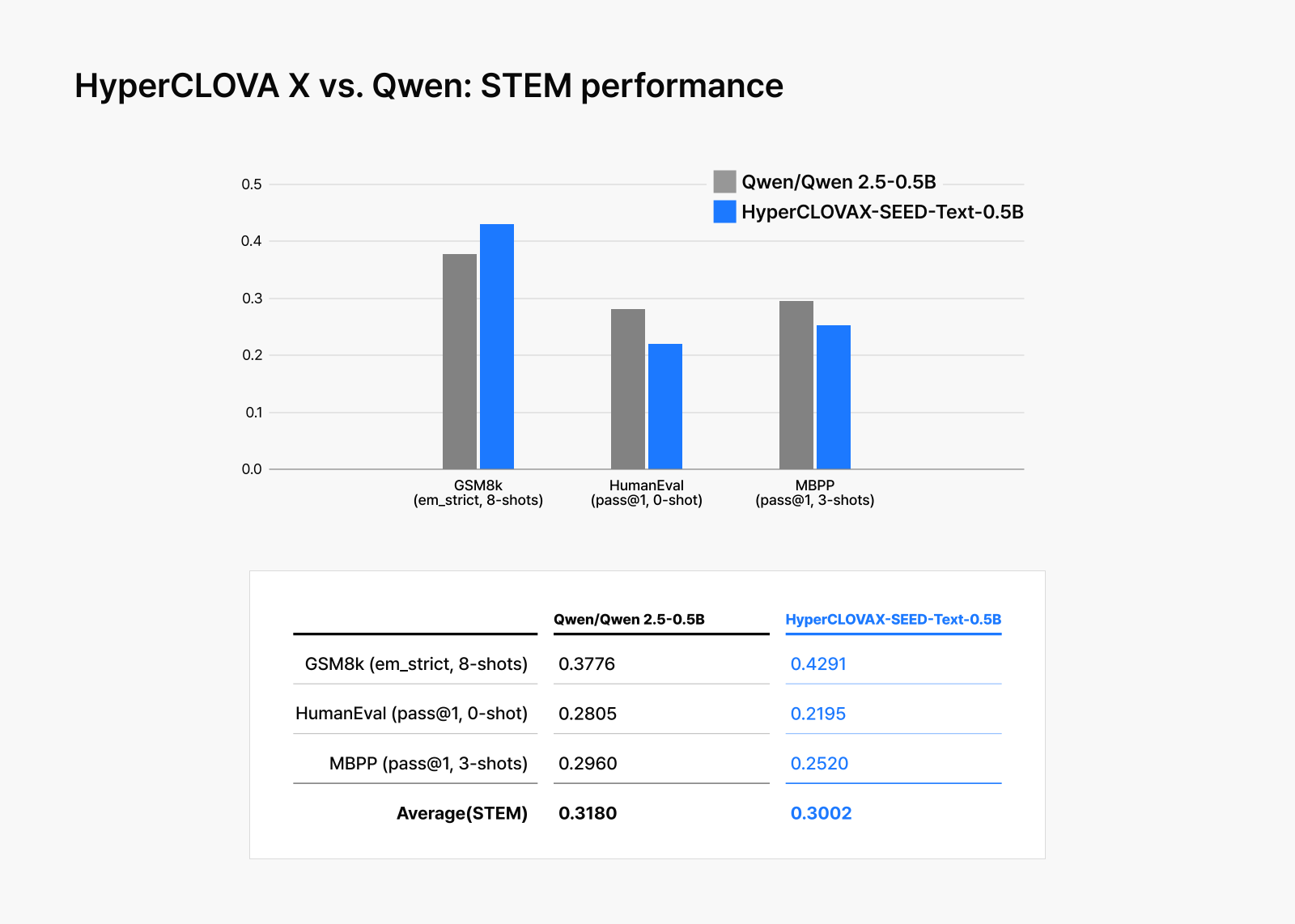
Performance evaluations across over 20 benchmarks confirm efficiency doesn’t come at the cost of quality. From MMLU, which measures fundamental LLM capabilities, to Korean-language evaluations, HyperCLOVA X consistently outperformed the similarly sized Qwen2.5-0.5B-Instruct in most comparisons, proving that optimization can deliver both cost savings and superior performance.
HyperCLOVA X brings new possibilities with model optimization
In today’s AI landscape, services are defined by speed, efficiency, and flexibility. HyperCLOVA X combines pruning and knowledge distillation to efficiently produce LLMs that are small but powerful, addressing these needs.
Our training strategy based on pruning and knowledge distillation goes beyond simple model optimization technology. It opens up significant possibilities by delivering customized models with both speed and efficiency to various AI-driven services. Building on this technology, NAVER Cloud is working to make AI a more practical tool across industry sectors. By flexibly applying model compression technology across various business domains, we’re developing a more competitive platform that achieves both the scalability and practicality that cloud-based AI technology demands.