
Our own vision encoder, HyperCLOVA X CLIP, and HyperCLOVA X SEED 4B
The modern battlefield is fast becoming an environment where different kinds of information—drone footage, satellite imagery, radio chatter, operational documents—arrive in real time and must be turned into fast decisions. That’s why omni-modal AI, able to understand text, images, video, and audio all at once, is drawing attention as a core defense technology.
TEAM NAVER has developed HyperCLOVA X SEED 4B, a lightweight omni-modal language model built for exactly this environment, along with HyperCLOVA X CLIP, the vision encoder it’s built on. Building on HyperCLOVA X 32B Think [1] and HyperCLOVA X 8B Omni [2], both released earlier this year, we’ve continued our R&D, completing the core components that serve as the model’s “eyes” and “ears” one by one, all with our own technology. What stands out in this model is that we ran the entire vision-encoder process ourselves, from weight initialization through training, and built and integrated our own audio encoder that can understand the audio inside video as well.
This kind of technical self-reliance shows its value most clearly in defense, where security and field-readiness are required at once. Defense places data sovereignty and real-time responsiveness above almost everything else. A model has to run reliably on air-gapped networks isolated from outside connections, and on platforms with limited computing resources—drones, unmanned systems, tactical vehicles. In settings like these, you can adopt a model with confidence only if it was built on your own technology rather than borrowed from an outside source.
In this post, we’ll walk through how HyperCLOVA X SEED 4B built up a self-reliant omni-modal AI technology stack, and what that technology makes possible in the demanding world of defense.
Why AI needs to understand every modality
Omni-modal large language models are moving beyond simply describing an image toward understanding documents, charts, video, and sound together in a single context. The catch is that the encoders serving as the model’s “eyes” and “ears” largely determine its overall performance and range of uses.
To build a model that genuinely understands Korean and the Korean context, it has to reliably handle Korean text, Korean objects and places, and Korean-language OCR within images. And in domains where reliability is critical—public sector, industry, defense—it matters to reduce dependence on external components and to have the “technical self-reliance” to explain exactly what data and architecture a model was built from.
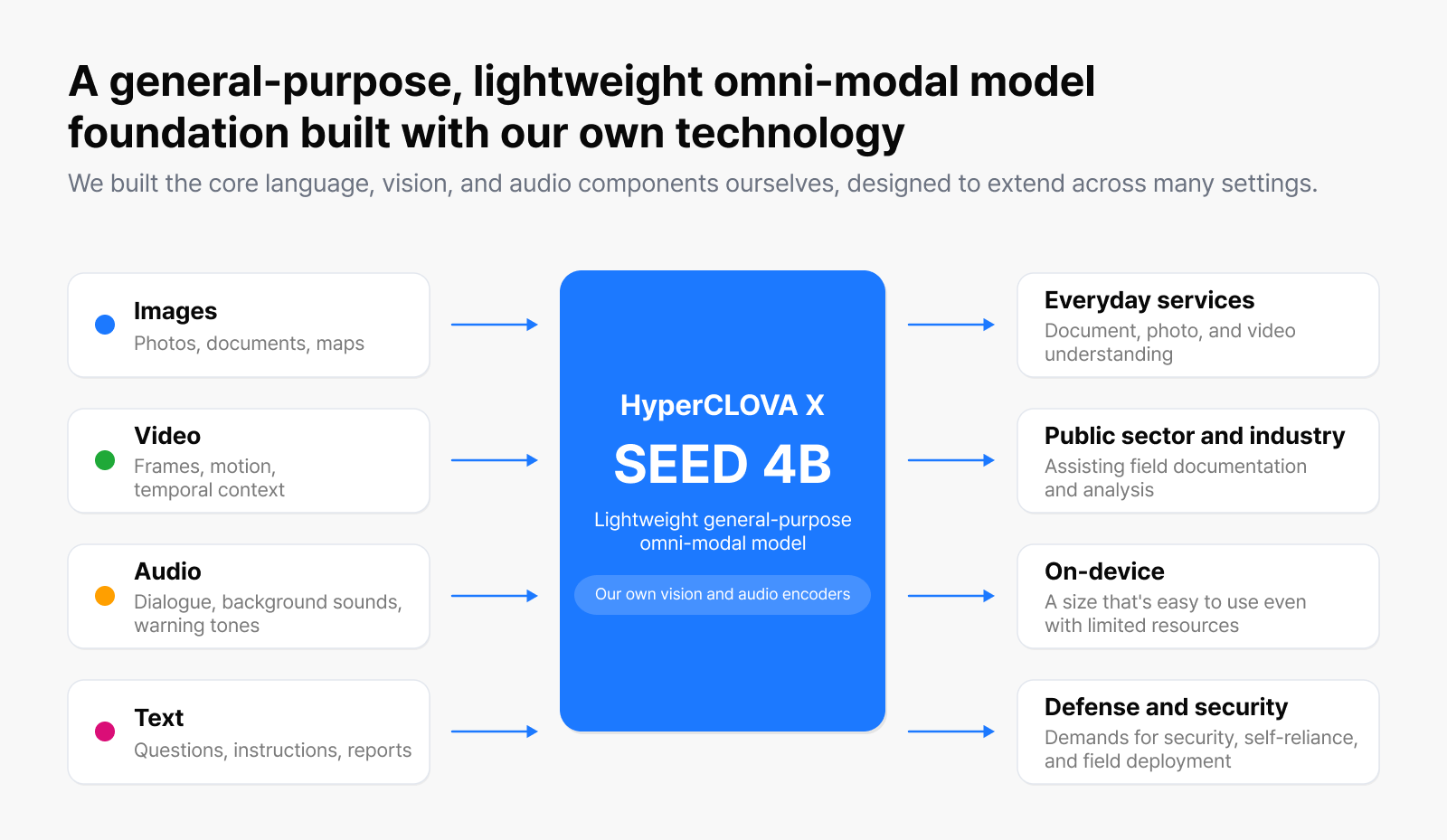
HyperCLOVA X SEED 4B is a lightweight, general-purpose omni-modal model that,
built around its own encoders, extends to a wide range of real-world settings.
Why 4B: Building it small to use it more widely
We already have larger models, so why release a 4B one? The answer lies in where models actually get used. The cloud can run big models, but not every service or site has enough compute. On smartphones and robots, factory floors, CCTV monitoring, and public-sector and defense sites, where response latency and equipment constraints are significant, a smaller model can be the more practical choice.
Small doesn’t mean settling for less, of course. HyperCLOVA X SEED 4B balances its 4B size with high-resolution image processing and audio-token compression. The goal was never a “small model” for its own sake, but an “efficient model” that actually holds up in the field.

An efficiency-focused design that combines 4B-scale compression,
local windowing, and audio-token compression
Building our own encoders: Giving the model eyes and ears
The vision encoder is the model’s “eyes.” It takes in an image, extracts its visual meaning, and turns that into a representation the language model can understand. The audio encoder is closer to the model’s “ears,” converting the sounds in a video—dialogue, background noise, sound effects—into tokens the language model can read.
We developed HyperCLOVA X SEED 4B’s encoders ourselves in three broad stages.
- CLIP pre-training: learning the relationship between images and text from scratch
- Further vision-encoder pre-training: using an LLM smaller than the target to perform efficient vision encoder–LLM alignment
- Audio-encoder development: building an encoder that understands the sounds inside video
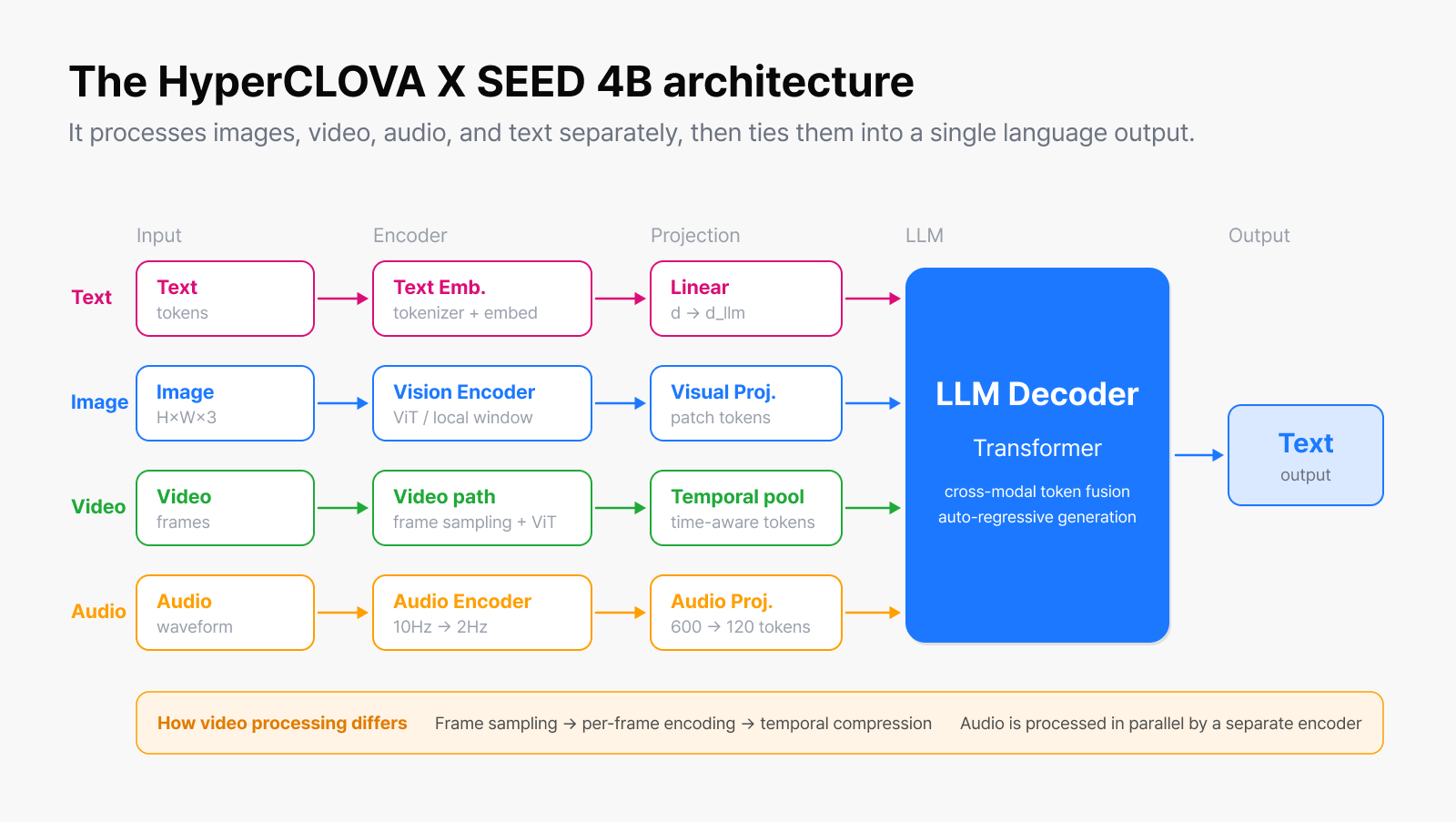
The overall architecture of HyperCLOVA X SEED 4B. It processes images, video, audio,
and text separately, then ties them together into a single language output.
Stage 1. HyperCLOVA X CLIP: Weight initialization
HyperCLOVA X CLIP is a vision encoder of about 637M parameters, trained to align images and text in a shared embedding space. The key point is that we started from fully random initialization, without importing any external weights at all.
The common approach is to take an already pre-trained model and fine-tune it, since reusing learned representations is a fast way to reach good performance. But HyperCLOVA X CLIP doesn’t lean on any such external model—we chose to build the vision encoder from its very starting point. We didn’t extend or fine-tune an existing model; we trained it completely from scratch.
Training used Korean and English image–text data on the scale of about 30B seen samples. That choice matters especially for visual understanding in a Korean setting: global vision encoders are often trained on English-centric data, so they can hit their limits on Korean OCR or images steeped in Korean context.
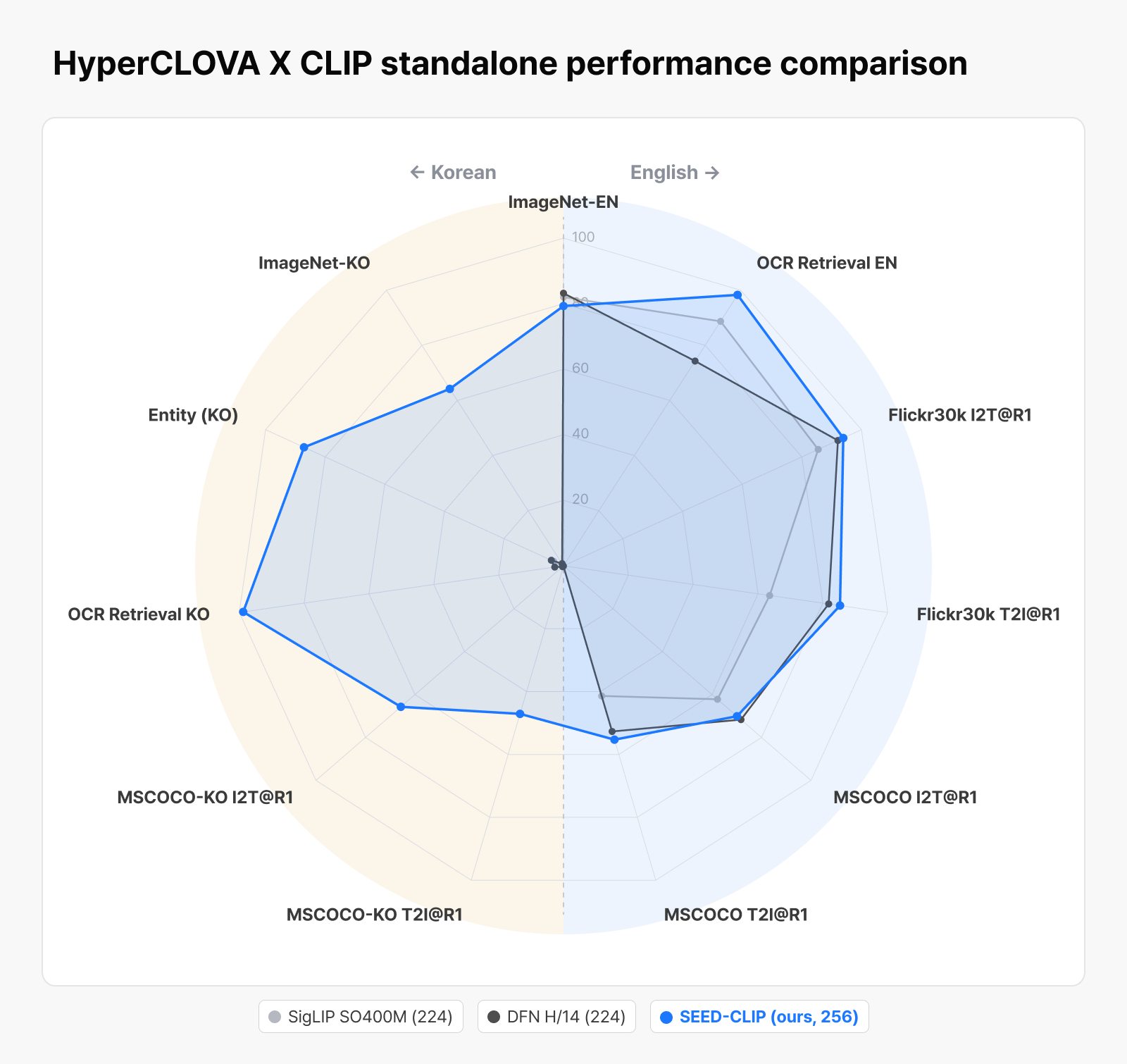
HyperCLOVA X CLIP on its own, compared against other encoders. It holds its English performance while showing large gains on Korean benchmarks.
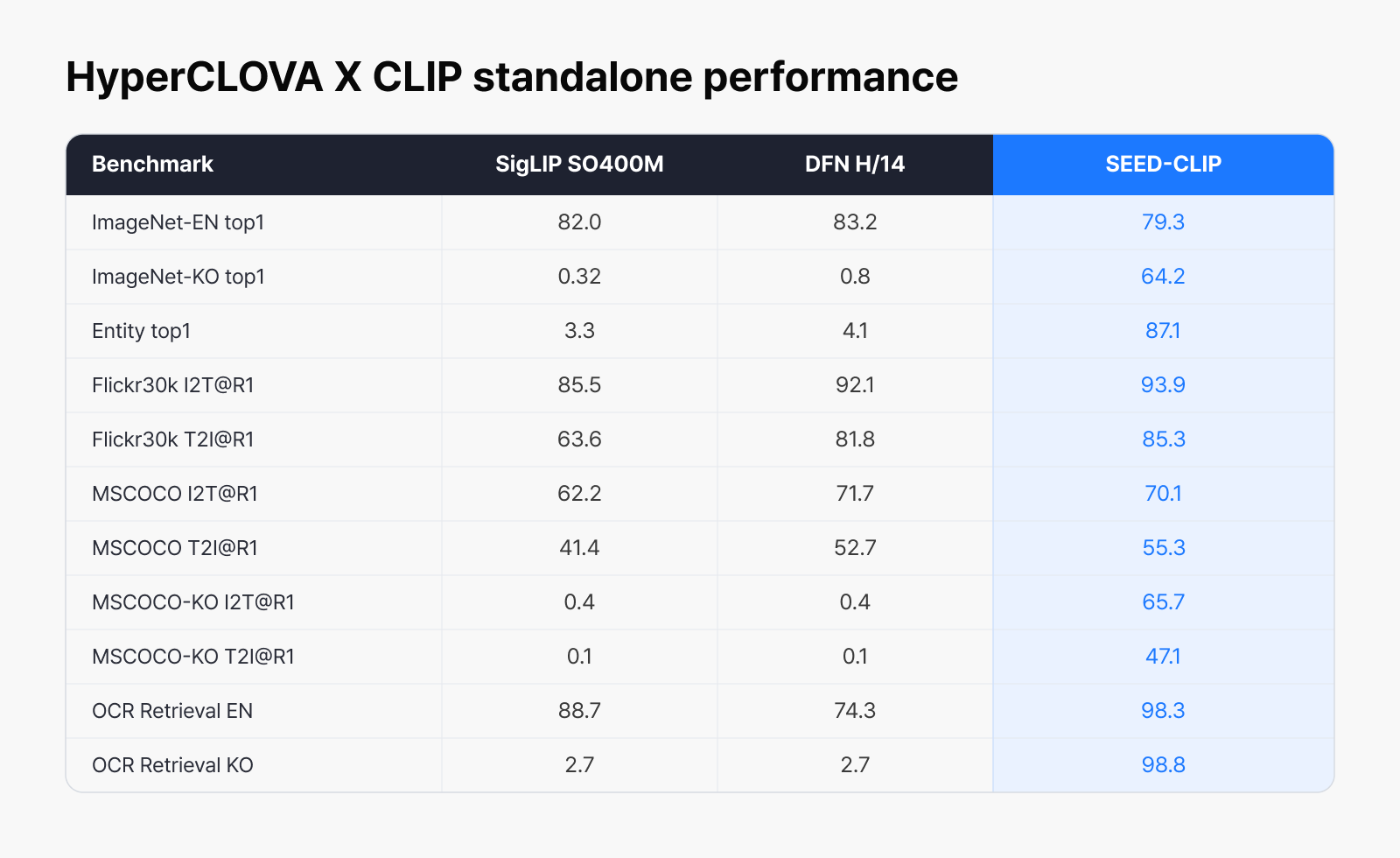
As the table shows, global encoders like SigLIP and DFN were trained on English-centric data and score close to zero on Korean benchmarks—Korean and the Korean context were simply outside their training scope from the start. It’s effectively territory those encoders couldn’t handle. HyperCLOVA X CLIP fills in exactly this unsupported territory, holding its English scores while posting large gains across the ImageNet-KO, Entity, OCR Retrieval KO, and MSCOCO-KO families of metrics. This comes from learning visual representations suited to Korean and the Korean context directly, and it forms the foundation for understanding a wide range of Korea-specific images.
- ImageNet-KO: tests how accurately the model can identify what an image shows, in Korean.
- Entity: tests how well it recognizes objects that show up often in a Korean setting, such as brands, places, and products.
- OCR Retrieval KO: tests how accurately it reads Korean text within an image.
- MSCOCO-KO: tests how naturally and accurately it can describe an image’s content in Korean.
Stage 2. Refining the encoder into the eyes a language model actually needs
CLIP pre-training alone isn’t quite enough to drop straight into an omni-modal language model. A pre-trained vision encoder is strong at matching the overall meaning of an image and a sentence, but reading small text inside an image, or describing every detail of a scene, takes further training.
So instead of training the vision encoder on its own, we connected it to a temporary lightweight language model and trained it once more as a vision-language model. Once training is done, we remove the language model used here and keep only the improved vision encoder in the final model. Put simply, we used the language model as a “temporary teacher” to coach the vision encoder. Through this, the encoder naturally learns what visual information the language model actually wants. (You can find more technical detail on this process in our research [3].)
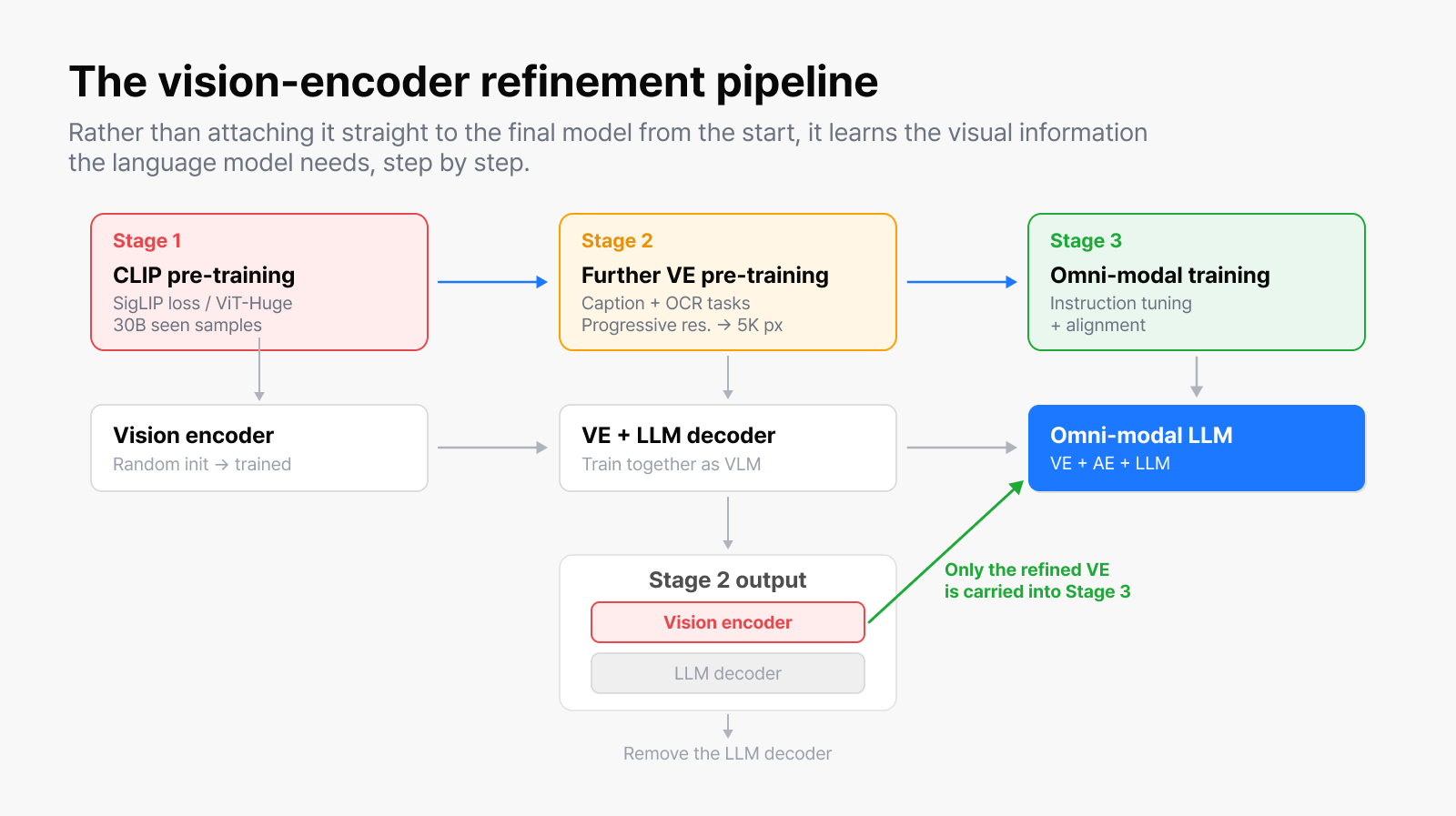
The vision-encoder training pipeline. In Stage 2, we train the vision encoder together with a language model, then keep only the refined vision encoder in the final model.
For high-resolution images, we combined progressive resolution and local windowing. Training at high resolution from the start is expensive and can be unstable, so we learned basic representations at low resolution first and raised the resolution gradually. And instead of computing relationships across all patches at once, we split the image into small windows and ran attention within each window first.
Stage 3. Understanding the sound inside video: Our own audio encoder
Many video LLMs say they understand video, but in practice they often process only the frames and leave out the audio. Yet when people watch a video, they ask about the speech, the background sounds, even the warning tones. Frames alone can’t answer what was said in the video. To handle the audio inside video as well, HyperCLOVA X SEED 4B integrates its own audio encoder.
- Training method: CTC loss (a way to learn speech-to-text matching without time-alignment information)
- Training data: roughly 1,000 hours of ASR data built from the LibriSpeech and Zeroth Korean datasets
We built the process for integrating this trained audio encoder into the language model on top of our earlier research [4]. We first extract audio features at 10 Hz, then apply average pooling to compress them down to 2 Hz—for one minute of audio, that means cutting roughly 600 tokens down to about 120. As a result, even the audio track of a long video can be fed to the language model at a manageable length.
The HyperCLOVA X SEED 4B training pipeline
Omni-modal training starts from a base model that has already finished text pre-training. The LLM decoder in HyperCLOVA X SEED 4B is based on our own language model, so it enters the omni-modal pipeline with text understanding and generation already well in hand. The full pipeline runs in this order: Omni-modal pre-training → Omni-modal SFT → Long chain-of-thought & Video SFT → Omni-modal RLVR.
Omni-modal pre-training
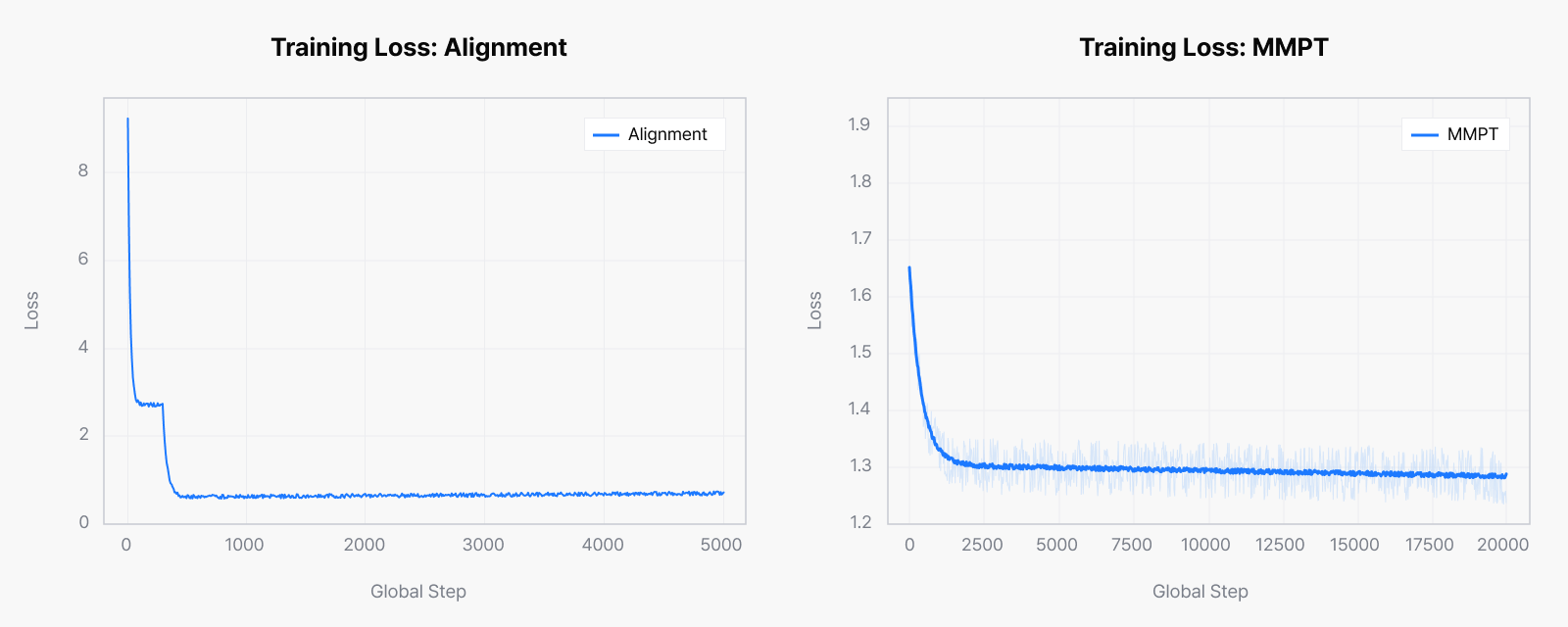
This stage connects image information into a form the language model can understand and builds the vision-language model’s basic visual understanding. We used Megatron Bridge, which excels at sustaining high throughput at scale and is well suited to training large volumes of vision-language data reliably. We first aligned image and language representations around the projector in an alignment phase, then trained all parameters in a full fine-tuning phase.
Across this stage we trained on about 200M samples, building broad foundational vision-language skills: understanding diagrams, reading OCR within images, entity recognition that identifies and links objects, and combining visual information with knowledge. As the loss curve shows, training stayed stable and gave the later refinement stages a solid base.
Omni-modal SFT
Building on the basic visual understanding from omni-modal pre-training, we now train the model’s instruction-following ability—answering a user’s question precisely. This goes beyond captioning to understanding and following specific instructions like “Which item is highest in this chart?” To get there, we gradually raised the share of omni-modal data and applied curriculum learning, splitting training into five phases by objective.
We first set text instruction tuning to about 95%, so that a model still new to instruction following could learn “how to understand and follow instructions” through text first. Next we raised the omni-modal share to about 75% and trained on large amounts of detailed captioning—the stage that catches small text, background elements, and relationships between objects. If omni-modal pre-training is the “eye that sees broadly,” this is the “eye that reads closely.” Finally, we pushed the omni-modal share to about 85% for full instruction tuning across real scenarios: question answering, document understanding, chart interpretation, and video summarization. Because over-fitting to any one task lets other abilities atrophy, we kept adjusting the task mix to stay balanced.
The training framework: Choosing flexibility
From SFT onward we switched frameworks. Omni-modal pre-training was all about high throughput, so we used Megatron Bridge; but from SFT on we were handling mixed image, video, and audio data and needed to change the data composition and ratios quickly at each step. So we took Hugging Face’s Seq2SeqTrainer as a base and built the features omni-modal training needs on top of it ourselves—among them Hybrid Sharded Data Parallel (HSDP) to speed up training, dynamic batching to train variable-length data efficiently, and a pre-load pipeline for training on large volumes of video.
The core of the design was an on-the-fly approach: rather than converting data into a fixed form in advance, we loaded and preprocessed the originals directly at training time. That meant changing the composition or ratios was just a config change—no need to re-run preprocessing—so we could train on a new mix right away, which made a big difference to development speed in the SFT stage, where ablations have to be repeated quickly. Token lengths also vary widely, since each sample has a different number of images and a different resolution. Dynamic batching kept the total tokens per step constant while adjusting the number of samples per batch on the fly, securing both GPU utilization and training stability.
Long chain-of-thought & Video SFT
By the time it has gone through omni-modal SFT, the model can handle a wide range of visual tasks. For complex problems, though, it’s far more effective to reason through an internal thought process before answering rather than producing an answer outright. We call this thinking mode.
Thinking mode and chain-of-thought
At the heart of thinking mode is chain-of-thought (CoT)—laying out a line of reasoning step by step, the way a person would, before giving an answer. Comparing chart values, for example, it moves explicitly from observation to comparison to conclusion: “A is 35 and B is 28, so A is higher by 7.” This kind of step-by-step reasoning is especially effective on tasks that need several stages of judgment, like math, chart interpretation, and diagram analysis. To teach it, we built high-quality data with the thinking process explicitly annotated, so the model could learn the full arc of reasoning from observation to conclusion.
Video training: Data design and engineering
For video, we carefully controlled the length distribution for training efficiency. We leaned on short clips for efficiency but included a fixed share of roughly 15-minute videos to build long-form understanding too, and we added audio-aware data so the model could reason using sight and sound together. The training setup is the same as omni-modal SFT, but video needs its own engineering—preprocessing such as frame decoding, audio extraction, and time alignment is complex, and the files are large. If dynamic batching can’t get the next batch of videos ready in time, the GPU sits idle, so we designed and optimized a pipeline that pre-loads videos, keeping GPU utilization stable even when lengths vary widely.
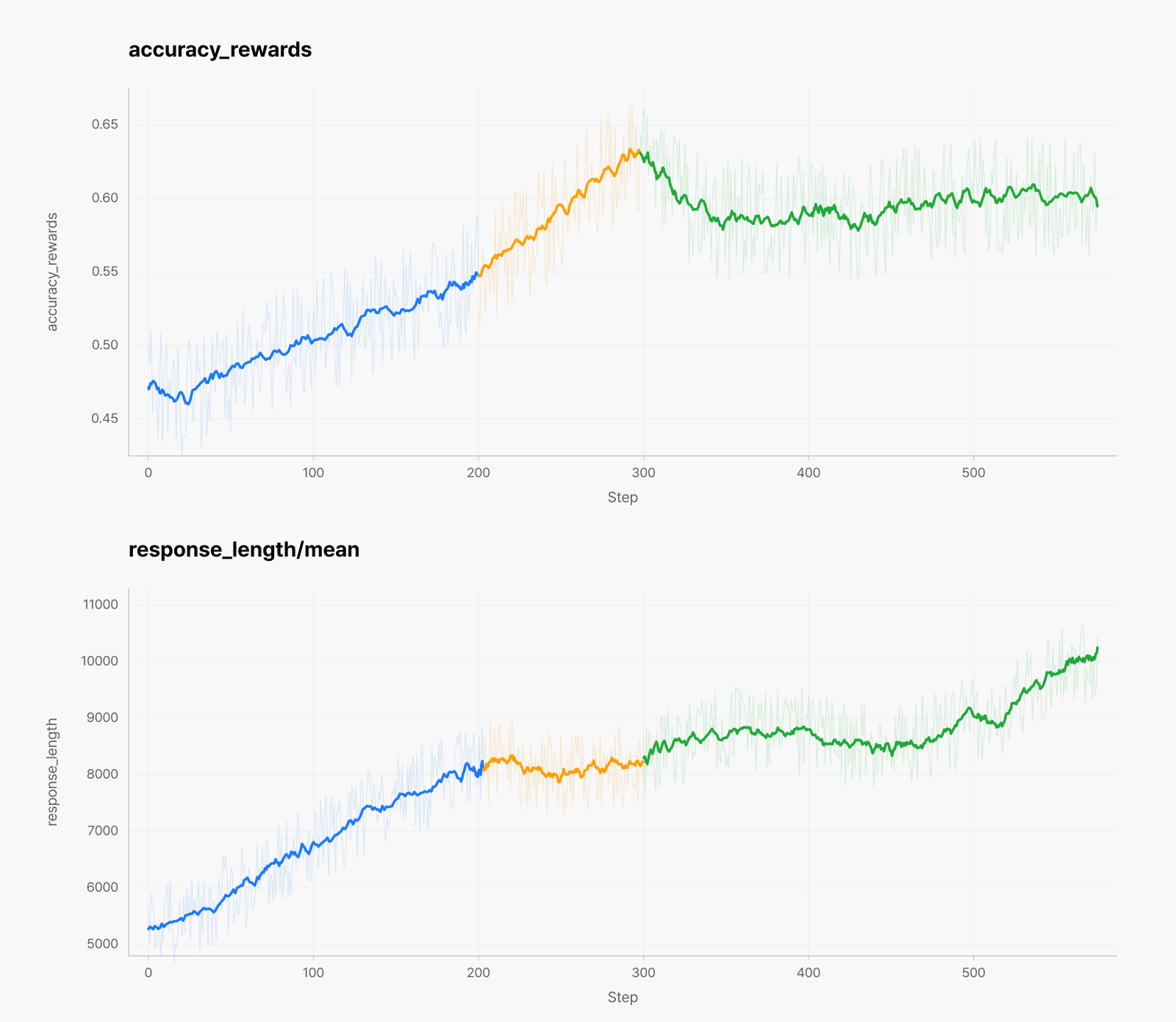
Omni-modal RLVR for reasoning
The RLVR stage focused on extending the model beyond plain visual understanding to actually applying problem-solving and reasoning. We strengthened reasoning around verifiable tasks in particular—problem solving, chart interpretation, vision-based calculation. Training ran on the verl framework, built on vLLM and FSDP, which can generate samples at scale and run distributed training at the same time, fitting the throughput and rollout–update cycle that RLVR needs.
For the algorithm we used DAPO, based on GRPO. Prompts where every sample in a group was right—or every sample was wrong—carry no useful gradient signal, so we excluded them, and we used asymmetric clipping to improve stability and data diversity. We kept omni-modal and text-only data at a 1:1 ratio to prevent over-reliance on visual information or weakening of language reasoning, growing reasoning across both modalities in balance. The reward reflected accuracy directly through a verifier that can check answers, and we added format and language rewards on top to steer responses that go beyond a correct answer to match the form and intent of the question.
We also generated more than 800,000 trajectories—about 100,000 prompts with 8 rollouts each—and trained on a filtered selection of them. This steadily improved vision-based calculation, structured problem solving, and omni-modal reasoning across the board.
Training ran in stages rather than a single run. From the midpoint on, we re-centered the data on Korean and raised the weight of the language reward to strengthen Korean reasoning and expression. The distribution of the training signal shifts from stage to stage, and the transition points show up as distinct segments in the accuracy-reward and response-length curves. Overall, accuracy and reasoning length keep rising across stage changes, confirming that reasoning ability accumulates steadily.
Half the size, sharper sight: HyperCLOVA X SEED 4B
So how does a model trained this way actually perform? What it comes down to is whether our own encoders translate into real model performance. With roughly half the parameters, HyperCLOVA X SEED 4B improved over the earlier HyperCLOVA X 8B Omni [2] across a range of image, document, and video understanding benchmarks.
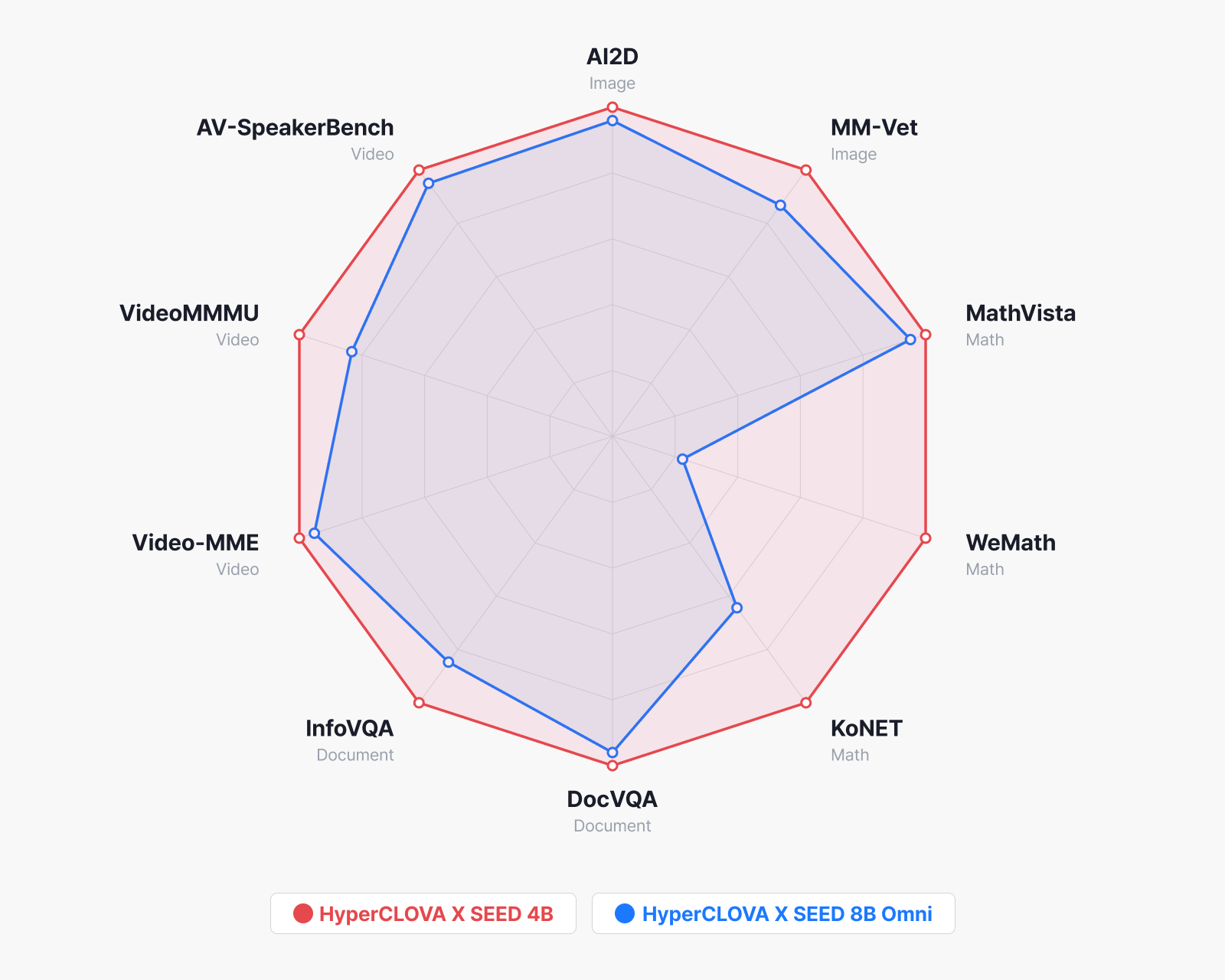
Benchmark comparison
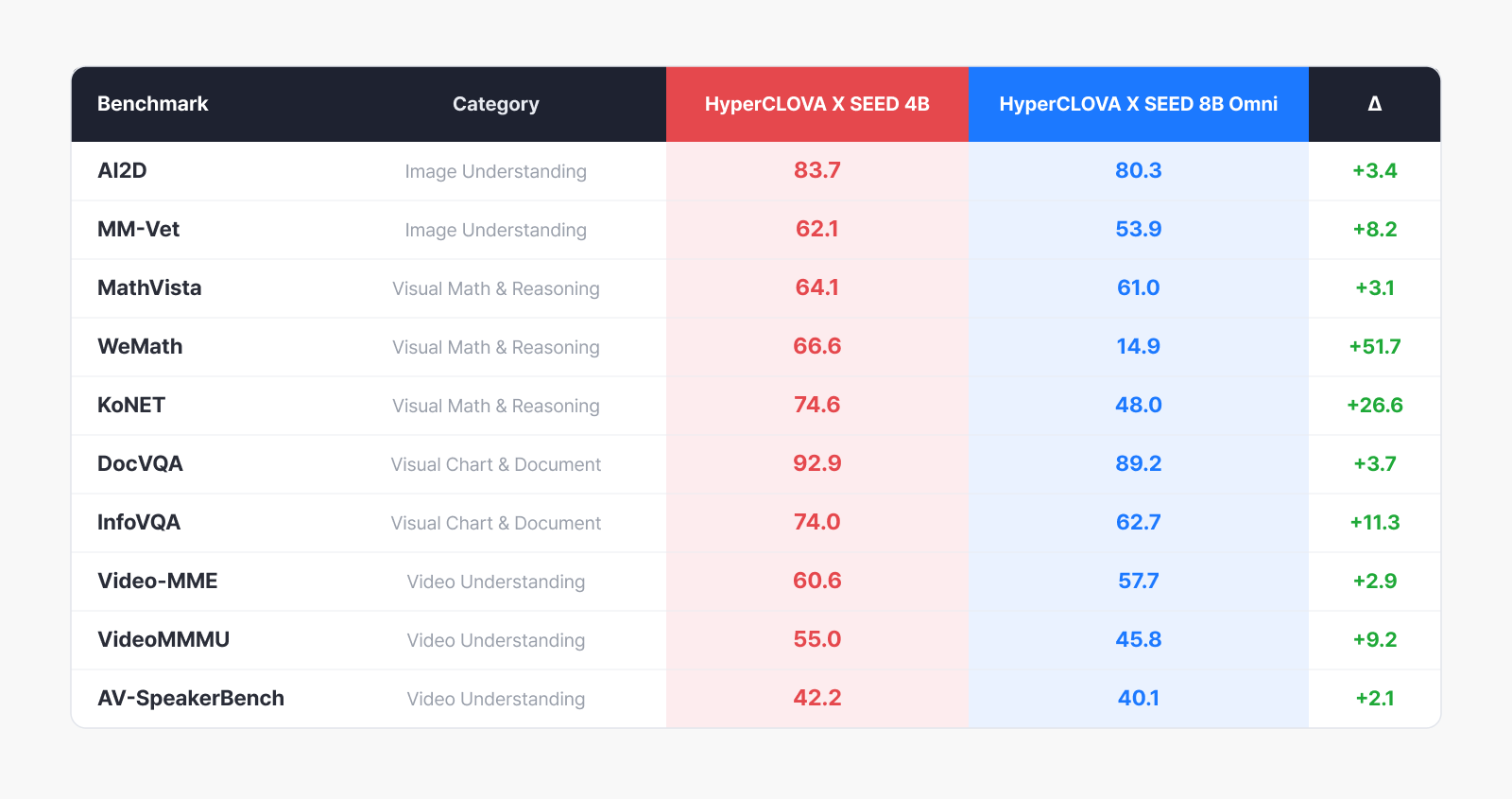
To start with the takeaway: SEED 4B came out ahead of HyperCLOVA X 8B Omni on every benchmark—a clean sweep by a model half its size.
The gap was widest in math and reasoning. On WeMath, which requires solving math problems from visual information, the difference was +51.7, and on KoNET, which tests problem-solving at the level of Korea’s college entrance exam, it was +26.6. This shows the model picked up step-by-step reasoning effectively through the long CoT training and RLVR described earlier.
On image understanding it led evenly too, on AI2D (+3.4) and MM-Vet (+8.2), and the 4B model also scored higher on the document- and chart-understanding benchmarks DocVQA (+3.7) and InfoVQA (+11.3). In the previous generation, a larger language model had the edge on dense text inside documents, but as our own vision encoder’s text-extraction ability improved, that advantage appears to have reversed.
On video understanding benchmarks, improvements showed up across the board—Video-MME (+2.9), VideoMMMU (+9.2), and AV-SpeakerBench (+2.1). AV-SpeakerBench in particular requires taking the speech in a video into account, so it’s a clear sign that our own audio encoder is making a real contribution alongside the visual information.
And the most important thing about these results is that all of this performance was achieved with our own modules alone, no external encoders.
Overall performance of HyperCLOVA X SEED 4B
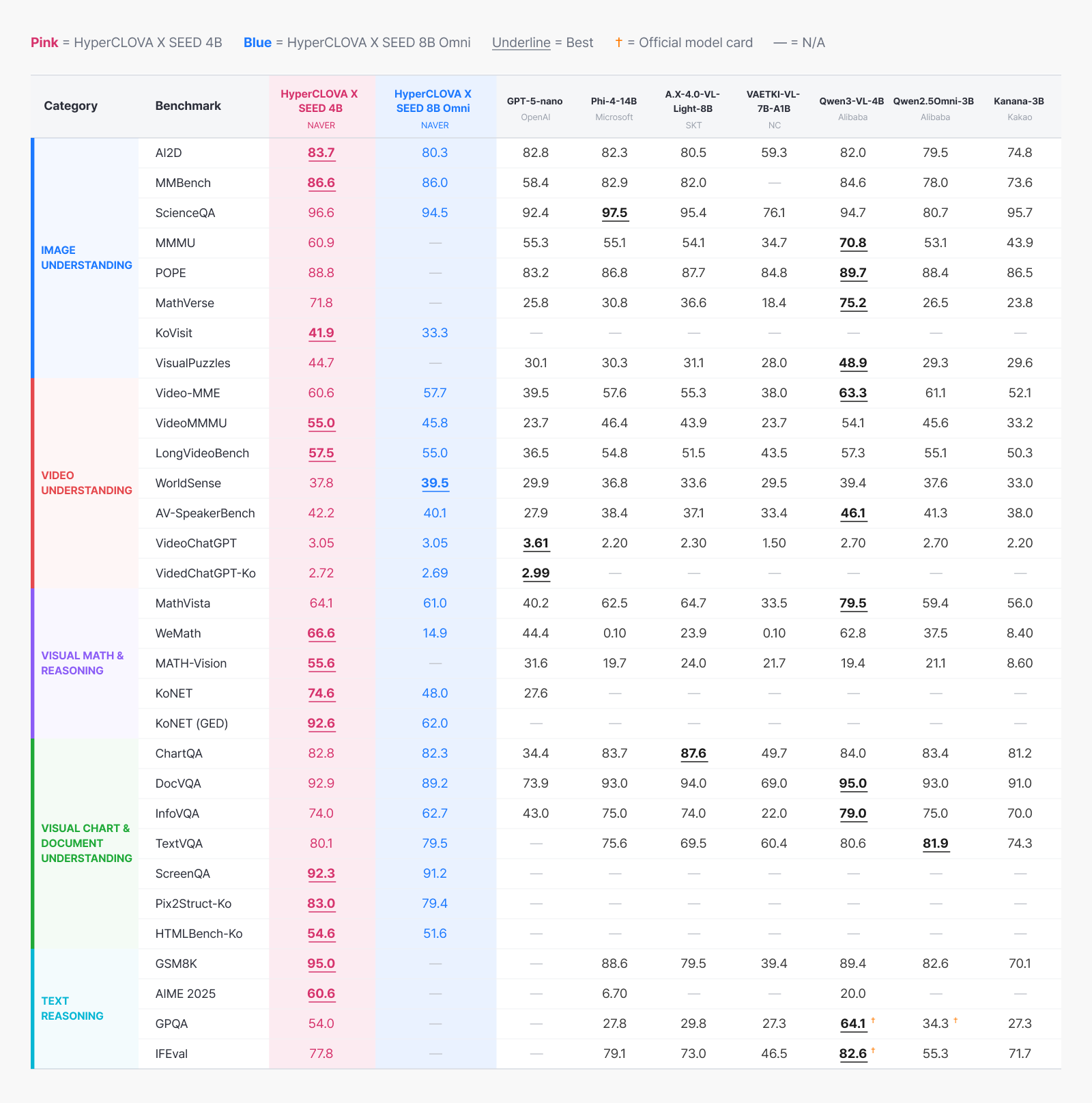
Overall benchmark comparison. Equipped with its own vision and audio encoders, HyperCLOVA X SEED 4B shows strong, well-balanced performance across the board.
Having confirmed the effect of our own encoders against our own 8B model, let’s now look at how HyperCLOVA X SEED 4B stacks up against global models. The comparison set includes OpenAI’s GPT-5-nano, Microsoft’s Phi-4-14B, SKT’s A.X-4.0-VL-Light-8B, Alibaba’s Qwen3-VL-4B, and Kakao’s Kanana-3B.
What stands out most is math and reasoning. On WeMath, a vision-based math benchmark, it scored 66.6, ahead of both the same-class Qwen3-VL-4B (62.8) and the 14B Phi-4 (0.10); on MATH-Vision it scored 55.6, the highest of the comparison set. The step-by-step reasoning built up through long CoT and RLVR shows up directly in the numbers.
In Korean the gap is even clearer. It scored 74.6 on college-entrance-level KoNET and 92.6 on GED-level KoNET (GED), while most global models can’t even handle these problems properly. The same holds for Korean document and video benchmarks like Pix2Struct-Ko (83.0), HTMLBench-Ko (54.6), and VideoChatGPT-Ko (2.72). Training our own vision encoder on Korean data from scratch is what naturally gave it this Korea-specific strength.
Document and chart understanding is clearly competitive too. At DocVQA 92.9, InfoVQA 74.0, and ScreenQA 92.3, it sits among the best at the 4B scale, and on DocVQA and ScreenQA it runs close to Qwen3-VL-4B (95.0 and —, respectively).
On image understanding—AI2D (83.7), ScienceQA (96.6), POPE (88.8)—it matched or beat models of the same and larger scale. Video was solid across the board too, with Video-MME (60.6), VideoMMMU (55.0), and LongVideoBench (57.5); on AV-SpeakerBench (42.2) it ranked just behind Qwen3-VL-4B (46.1), again confirming the contribution of our own audio encoder.
Text reasoning is worth a look as well. Even as a vision-language model, it keeps high scores on pure-text benchmarks like GSM8K (95.0), AIME 2025 (60.6), GPQA (54.0), and IFEval (77.8). Managing the data ratio so that omni-modal training wouldn’t erode text ability—and especially the 1:1 omni-modal-to-text mix in RLVR—appears to have paid off.
When the technology meets the field: The demanding requirements of defense
So far the story has been about “how” we built HyperCLOVA X SEED 4B. Now let’s ground “why” it matters in a concrete setting. Public-sector and defense work increasingly demands security, field deployability, and omni-modal situational understanding all at once—which makes defense the best place to explain why a self-reliant omni-modal model is needed.
In the field, images, video, audio, and documents don’t exist in isolation. Drone footage, satellite imagery, CCTV, equipment photos, tactical maps, and situation reports all pour in at once. Where it’s hard for a person to check everything in real time, an omni-modal model can quickly shortlist points of interest, describe what it sees in natural language, and provide a first draft for follow-up analysis.

How an omni-modal model could be used, seen through defense cases. It takes on tasks that need
omni-modal understanding—object grounding, change detection, equipment inspection,
and surveillance-video summarization.
The demos below adapt, for this public blog, the demonstration screens from a presentation at the Korea Institute of Military Science and Technology (KIMST). We’ve trimmed the long intermediate reasoning and focused on the final answers and output format visible on the slides.
Defense demos: How the model answers
Example 1. Object grounding in a drone view
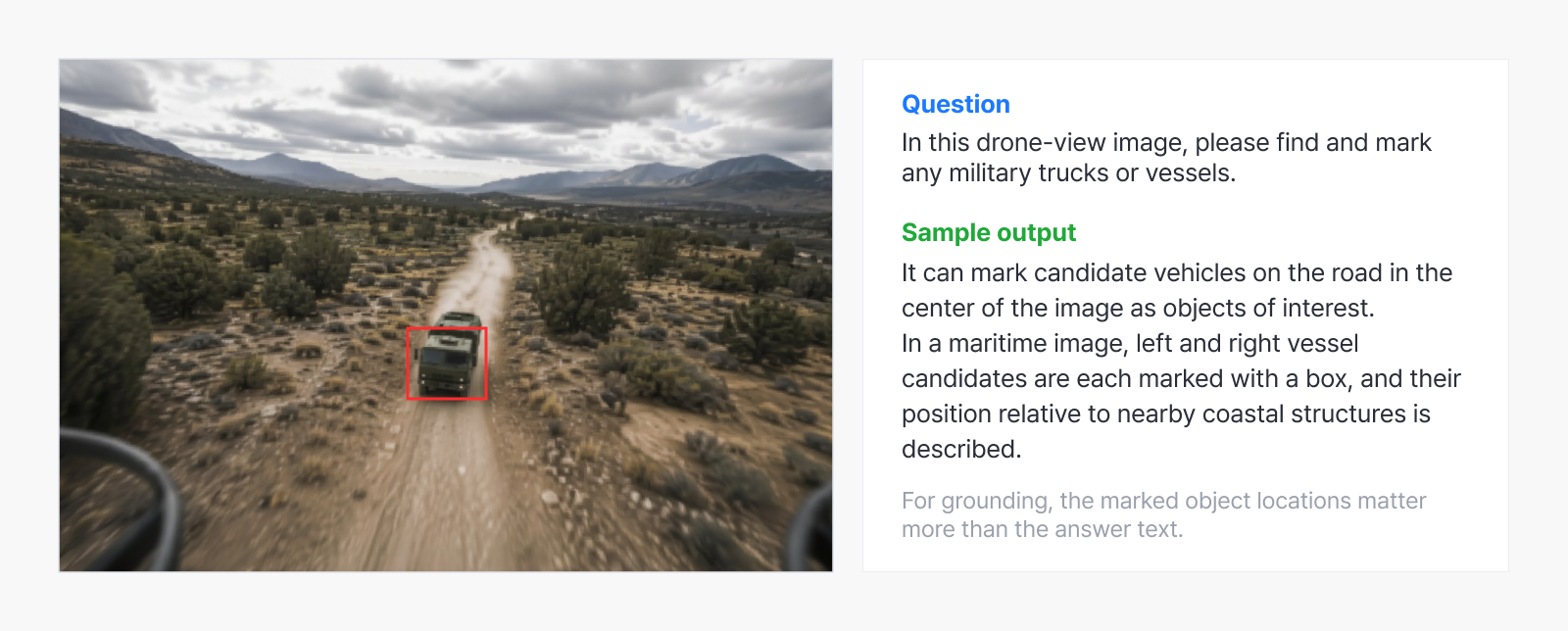
Objects of interest marked with boxes in a drone view
Example 2. Change detection in satellite imagery
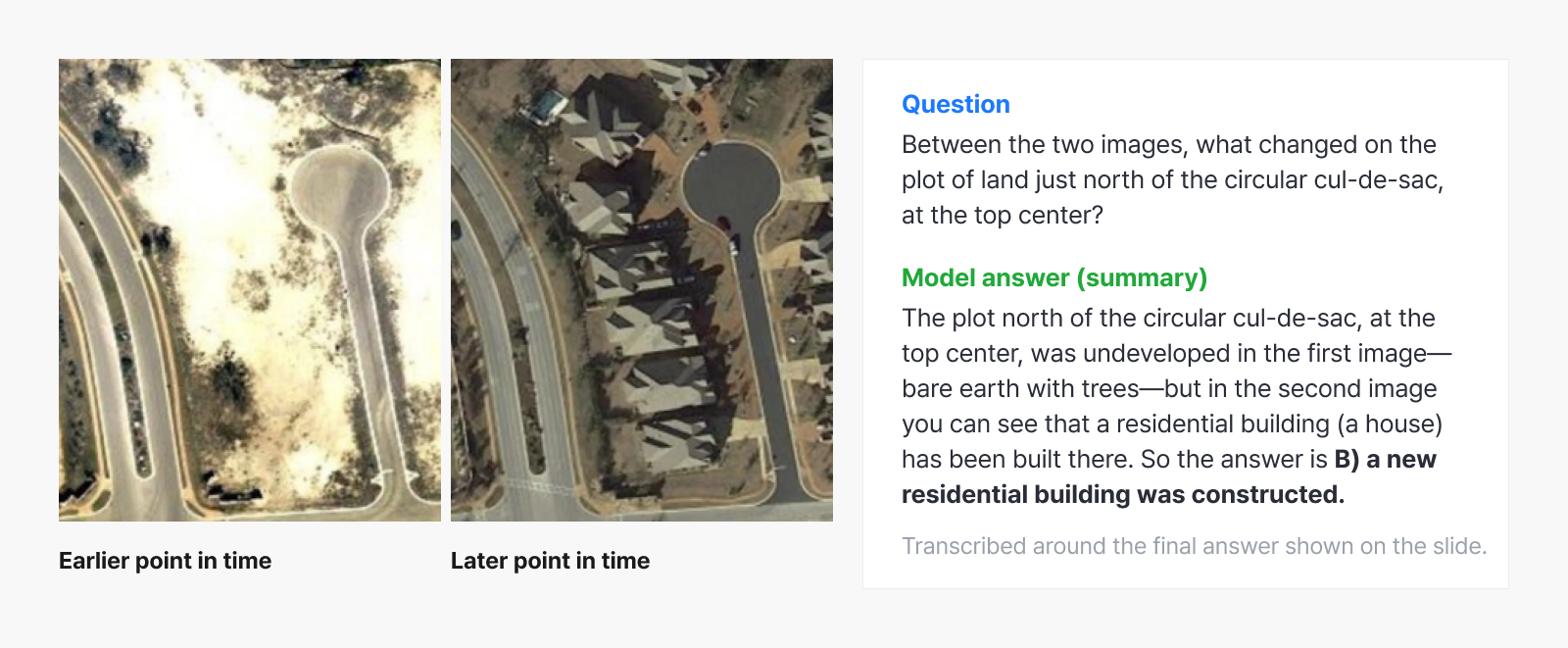
Comparing satellite images across two time points to identify and explain a change
Example 3. War-scenario analysis

Analyzing a scenario from a strategic-point map
Example 4. Spotting hazards in barracks and at a firing range
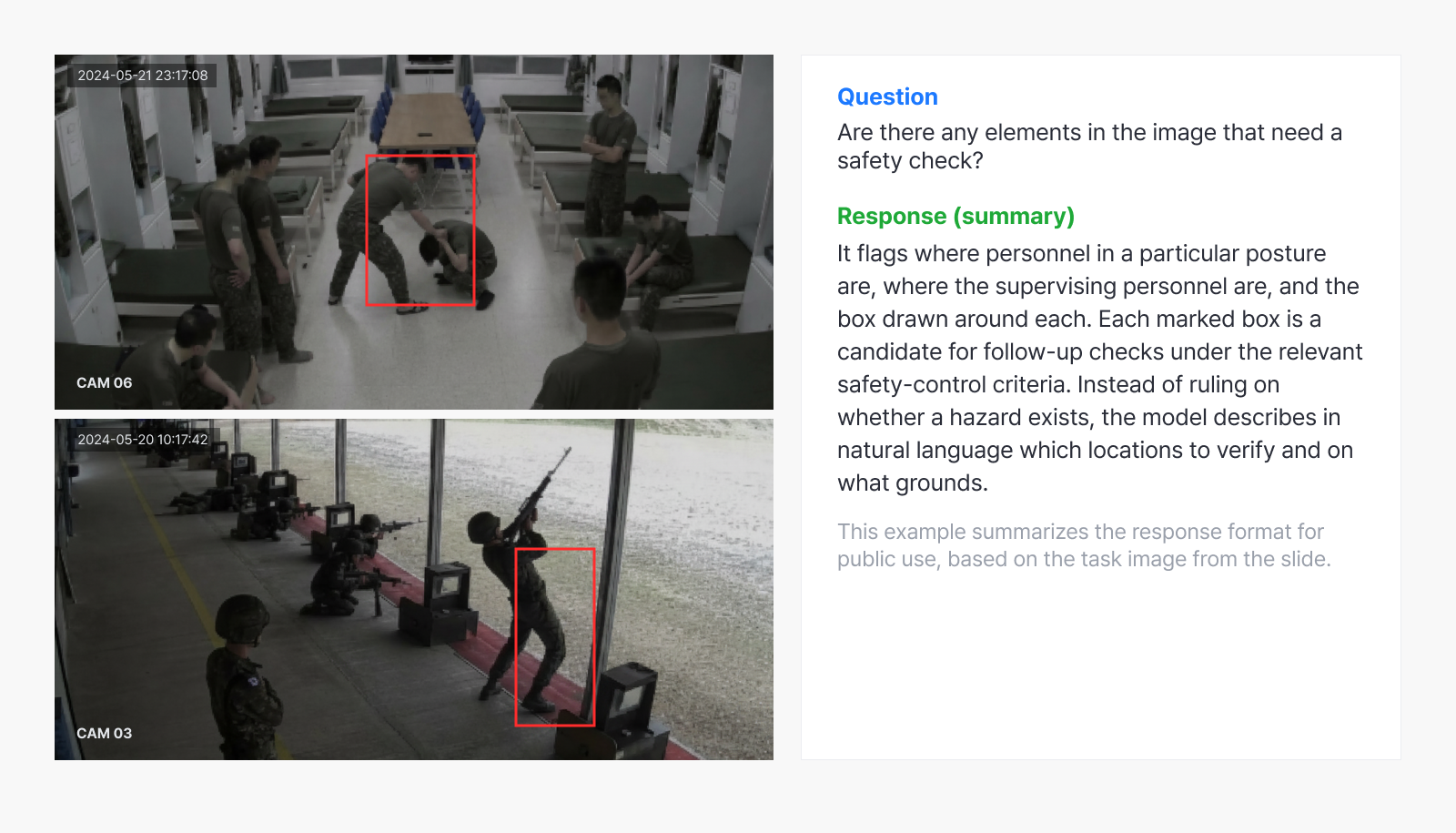
Describing hazard candidates that need follow-up checks
Example 5. Recognizing and comparing military equipment

Comparing the external features of military equipment in a table
Example 6. Summarizing anomalies in surveillance footage
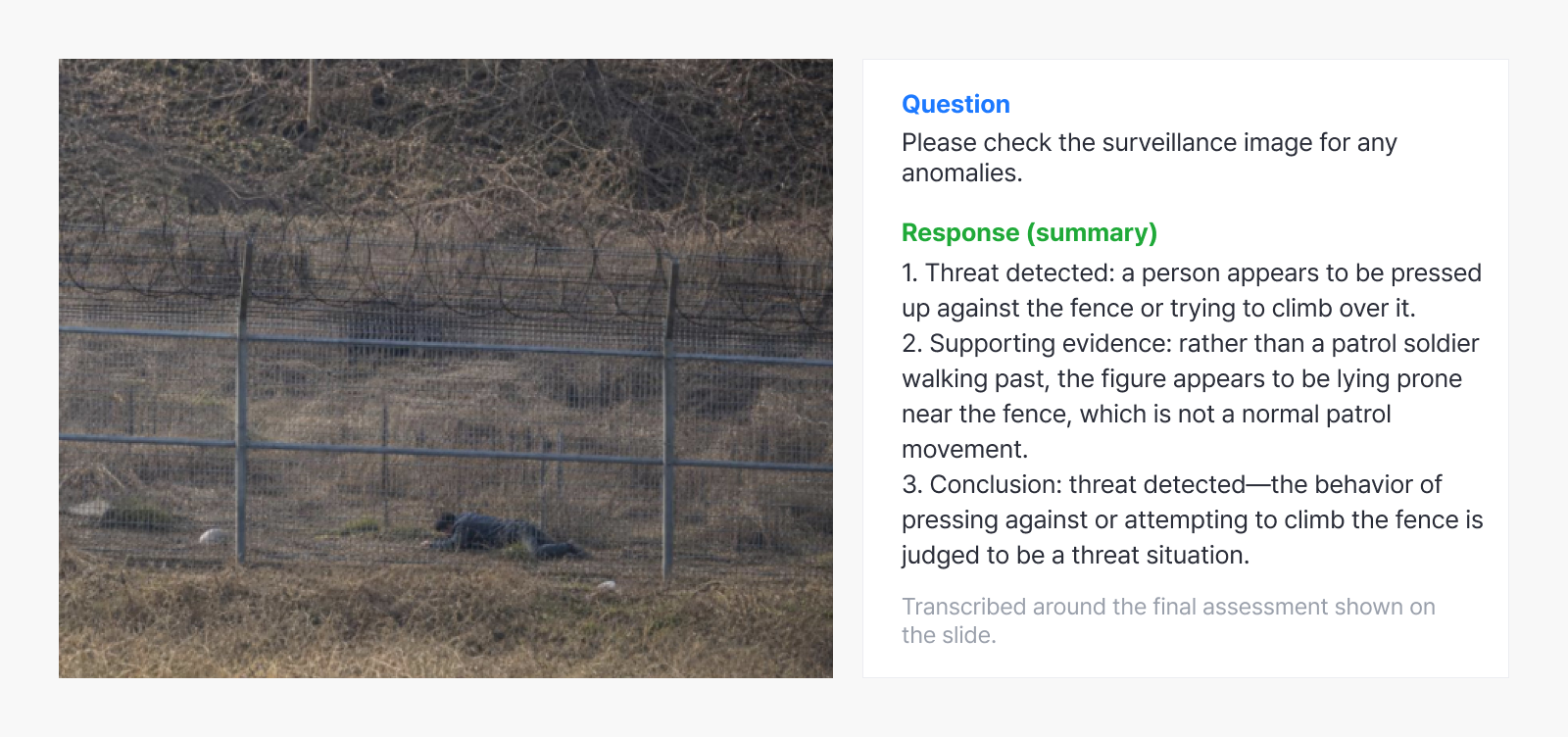
Pulling together candidate anomalies and follow-up checkpoints from surveillance footage
These scenarios don’t stay confined to defense. The ability to find points of interest in a wide scene, compare change across two points in time, describe equipment status in a structured way, and summarize long footage extends readily to public safety, manufacturing, logistics, disaster response, and more. That’s exactly why we present the defense cases alongside everything else: it’s a setting that demands all of these at once—technical self-reliance, an understanding of Korean and the Korean context, efficient reasoning under limited resources, and explanations a person can actually review.
Not just the model: Bringing data and evaluation in-house
In self-reliant model development, the architecture is only half the story. What data was collected and how it was cleaned, what criteria the model was evaluated against, and whether a new version is genuinely better than the last—the whole process has to be managed systematically. So we’ve built a system that lets us handle the entire model-development cycle ourselves, from data collection through training, version control, and evaluation.
In domains like defense, where public data is scarce, training on synthetic data is a practical alternative. So we’ve developed a pipeline that synthesizes data with LLM-based agents [5] and feeds it into training.
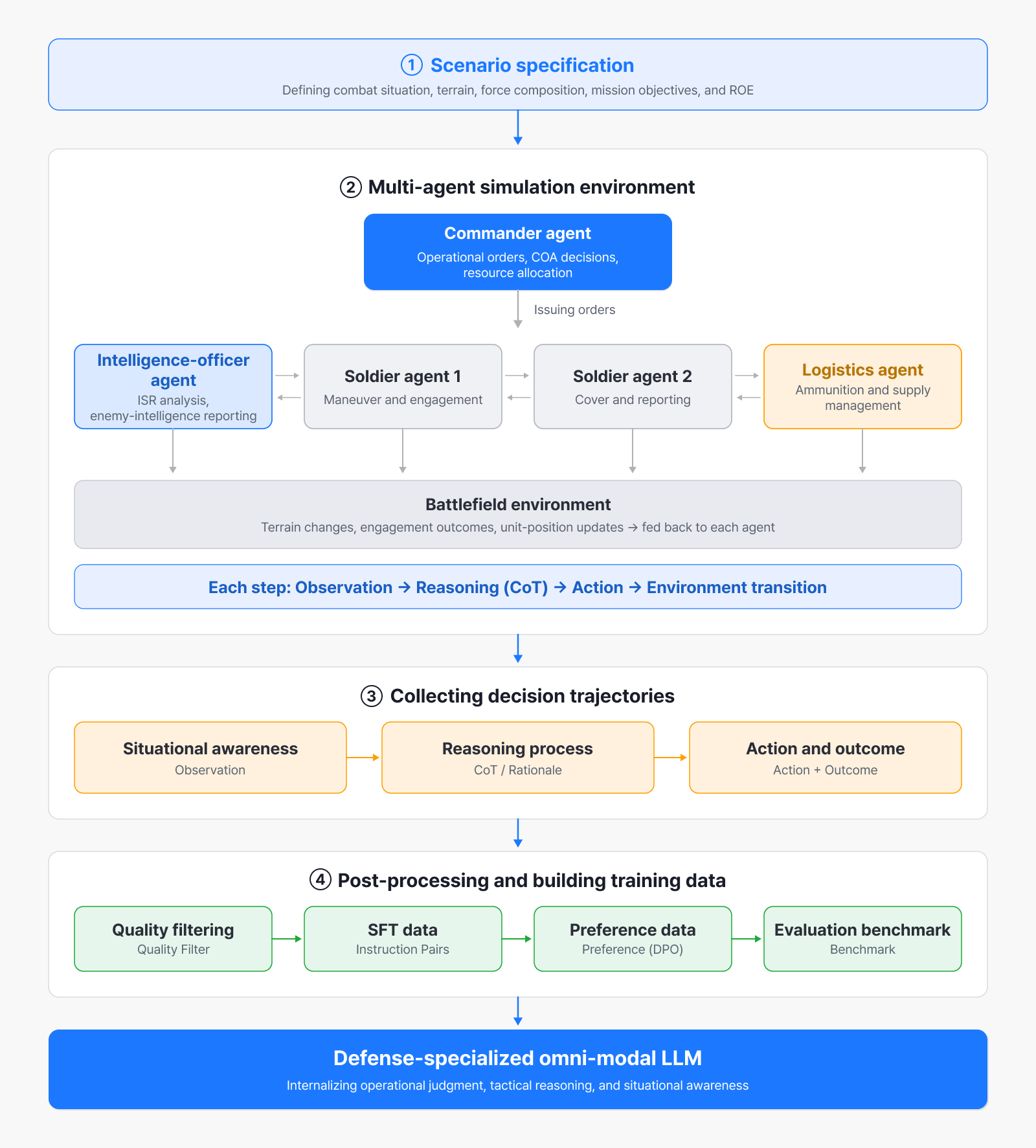
Generating synthetic defense data through agentic data simulation
Versioning and managing vast amounts of data takes its own know-how, so we’ve put a system in place for that as well. Tracking “which data a model was trained on” matters most of all—without it, you can’t tell whether a change in performance came from the model’s architecture or from the data. In defense, for instance, you sometimes have to audit whether a particular version of a model complies with the rules of engagement (ROE), and that requires being able to reproduce exactly the dataset it was trained on.
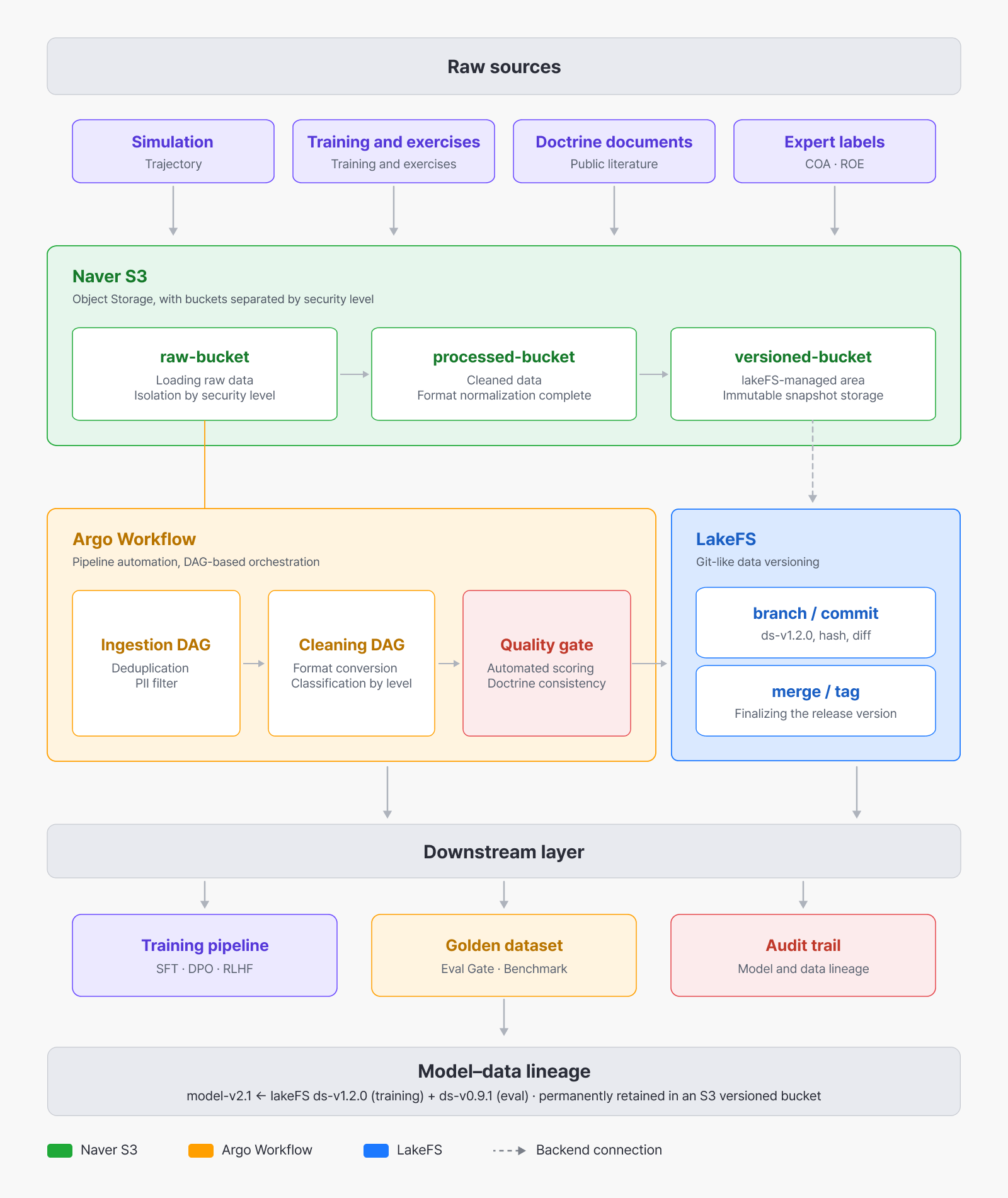
The data versioning and management system
Finally, for model release and version updates, we designed the process so that a release only goes ahead when a new version is quantitatively proven to be better than the current one. Changing the architecture or adding and removing training data can improve performance broadly, but sometimes the gains are limited to a particular goal or task. To continuously track performance changes during development and operation, we introduced an Eval Gate, building a rigorous validation system that guarantees performance for each intended use. As we refined this evaluation system further, we developed Omni Evaluator [6], which can comprehensively evaluate a wide range of omni-modal benchmarks spanning images, video, and audio.

The EvalOps Flywheel, where data collection, training, evaluation,
and operational feedback repeat in a loop
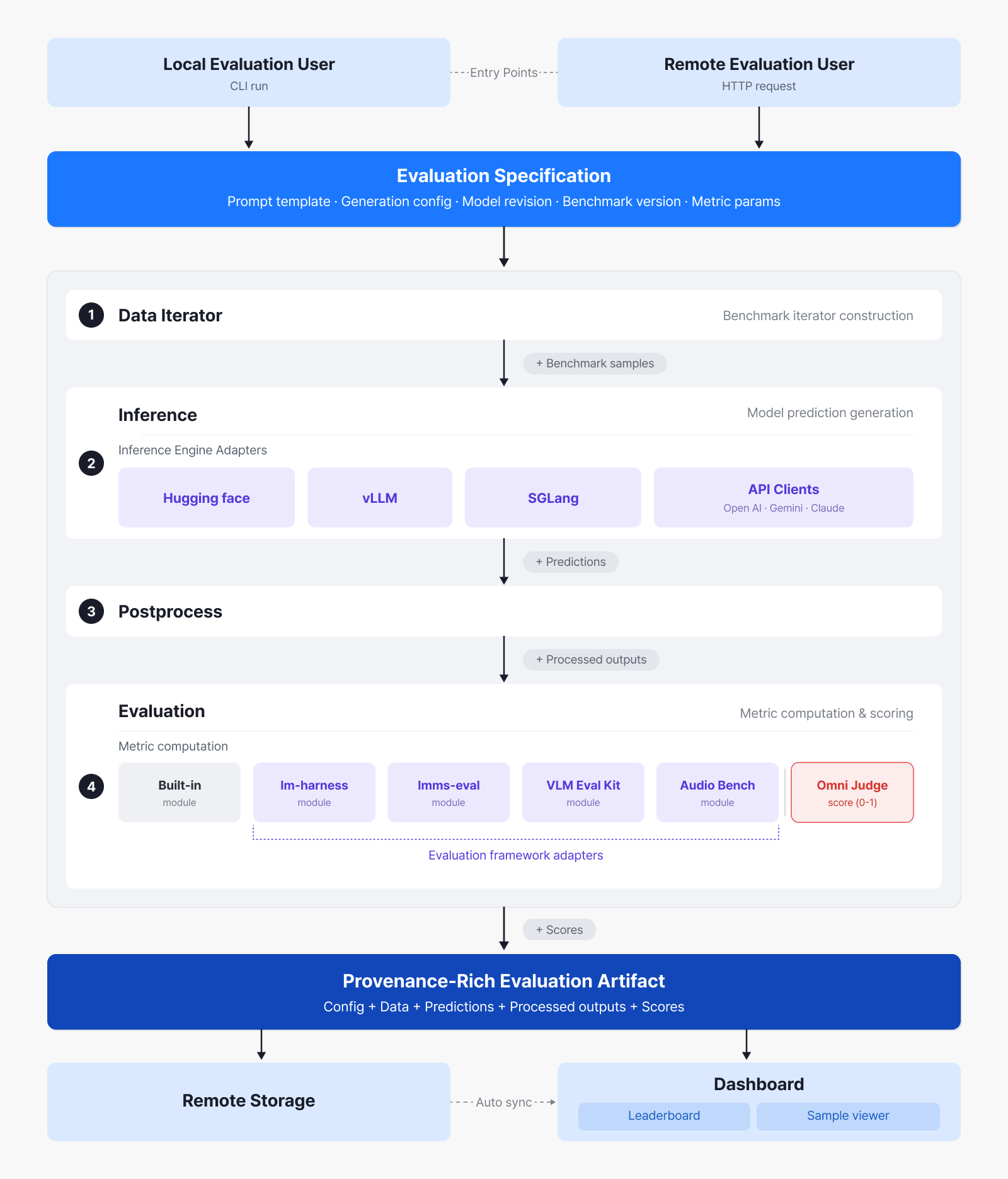
Omni Evaluator
Synthesizing data, managing versions, and validating through evaluation aren’t separate steps. Data collection, training, evaluation, and operational feedback form a single loop that flows back into data—the EvalOps Flywheel—and with every version, the data and the evaluation criteria grow more refined together. Building not just the model but this entire loop ourselves makes an even bigger difference in domains like defense, where public data is scarce and validation standards are strict.
Closing thoughts
HyperCLOVA X SEED 4B isn’t simply the result of building a small model. It’s one step in a long journey of filling in the building blocks of AI—the model’s “eyes” and “ears,” and the data and evaluation behind them—one piece at a time, with our own technology.
Along the way, we trained the vision encoder ourselves without external weights, developed our own audio encoder so the model understands the sound inside video, and applied an architecture for processing high-resolution images and long videos efficiently. The results showed up in clear numbers: higher performance at half the size, and a decisive edge on the Korean and Korea-specific tasks where global models fall short. Above all, these capabilities show their true worth in the most demanding settings—defense, where security and field-readiness are required at once.
All of this effort points in one direction: a “self-reliant AI foundation” that understands Korean and the Korean context deeply while extending to a wide range of services and settings. The security, explainability, and field deployability that public-sector, industrial, and defense work now demand make it all the clearer why bringing this technology in-house matters. HyperCLOVA X SEED 4B is a general-purpose foundation model for many different settings, and a starting point for further applications and domain specialization to come. We’ll keep taking the next steps in self-reliant AI, so that this model reaches even more fields and domains.
References
[1] “HyperCLOVA X 32B Think,” NAVER Cloud HyperCLOVA X Team, arXiv 2026. https://arxiv.org/abs/2601.03286
[2] “HyperCLOVA X 8B Omni,” NAVER Cloud HyperCLOVA X Team, arXiv 2026. https://arxiv.org/abs/2601.01792
[3] “On Efficient Language and Vision Assistants for Visually-Situated Natural Language Understanding: What Matters in Reading and Reasoning,” Geewook Kim and Minjoon Seo, EMNLP 2024.
https://aclanthology.org/2024.emnlp-main.944/
[4] “Do Modern Video-LLMs Need to Listen? A Benchmark Audit and Scalable Remedy,” Geewook Kim and Minjoon Seo, Interspeech 2026 (to appear). https://arxiv.org/abs/2509.17901
[5] “Synthesizing Post-Training Data for LLMs through Multi-Agent Simulation,” Shuo Tang, Xianghe Pang, Zexi Liu, Bohan Tang, Rui Ye, Tian Jin, Xiaowen Dong, Yanfeng Wang, and Siheng Chen, ACL 2025. https://aclanthology.org/2025.acl-long.1136/
[6] “Omni Evaluator,” GitHub repository, 2026. https://github.com/naver-ai/omni-evaluator