
From prediction to reasoning
The direction of AI is now clear: where previous models functioned more like “immediate answer machines” that instantly produced plausible responses based on learned patterns, we’re rapidly shifting toward reasoning models that apply multi-step thinking to reach conclusions.
This newer generation doesn’t answer questions immediately. Instead, they explore multiple solution paths, validate and refine their outputs, and select the most consistent and persuasive conclusion. Think of it this way: AI systems have internalized the same loop humans go through when solving exam questions—the process of thinking, reviewing, and deciding. This doesn’t just improve answer accuracy—it enhances evidence, consistency, and explainability.
A new competitive landscape
Not long ago, AI was essentially a system that instantly selected plausible answers based on trained patterns—not so different from students skilled at guessing their way through tests. That’s changed. Today’s reasoning models think before answering, evaluate intermediate steps, modify responses when they find contradictions, and arrive at the most persuasive conclusions. The focus is now on the quality of the thinking process—including evidence, consistency, and explainability.
This transformation is accelerating across research fields and industries. OpenAI introduced o1, a series of AI models designed to “spend more time thinking” to enhance their ability to solve complex problems. The company reported that performance improves with both training and reasoning steps—the more the model thinks, the better it performs. DeepSeek’s R1 demonstrated meaningful improvements in reasoning capabilities using reinforcement learning alone, challenging the conventional belief that massive costs and data are essential.
In Korea, NAVER Cloud’s HyperCLOVA X THINK is leading the field, expanding practical reasoning experiences by integrating tool-calling, self-validation, and evidence citation into Korean language services. The core capability has now become the self-evaluation loop, which allows models to generate reasoning paths and autonomously correct any inconsistencies.
How LLMs work
LLMs are driven primarily by data and models (transformers).
Data: A vast sea of language
Models train on enormous amounts of text—online articles, books, wikis, technical documents, and code. When the word “cat” appears, the model doesn’t learn the word itself but statistically learns which expressions typically precede or follow it in context. This means the model isn’t trained on correct answers for individual sentences, but on how language is actually used—on language patterns.
Model (transformer): Paying attention to what matters
The key to transformers is attention. They examine all word pairs in a sentence and score them: “What should I pay particular attention to in order to understand this word?” For example, in “She ate an apple,” “apple” is strongly related to “ate,” while “she” connects to the context as the agent. This weighted network allows models to reliably capture dependencies even in long contexts.
A simple but powerful goal
LLMs analyze the current context and calculate a probability distribution for the next token, then select one. For instance, if a user inputs “Today’s weather is so,” the system internally generates candidates like these (probabilities are illustrative):
- Basic context:
Hot 0.38, Good 0.27, Humid 0.12, Cold 0.06, Cloudy 0.05 …
- If the previous sentence was “The rainy season lasted long in July”:
Humid 0.41, Hot 0.33, Cloudy 0.10 …
- If the previous phrase was “cold weather warning”:
Cold 0.58, Harsh 0.14, Chilly 0.09 …
After sampling one token, the sentence grows by one word, and the model immediately predicts the next. For example, after “Today’s weather is so hot,” the next candidates might be connectors like “so,” “which is why,” or “today’s,” naturally completing the sentence as “so I turned on the AC.”
As this example shows, AI models repeatedly choose the most plausible option at each moment. Go through this process billions of times and they’ll produce responses with correct grammar, common sense, contextual awareness, and even creativity.
Ilya Sutskever, OpenAI’s former chief scientist, gave this analogy: Imagine a detective novel where the detective gathers everyone and says, “I’m going to reveal the identity of whoever committed the crime. And that person’s name is—” Predicting that next word is essentially what language models do, even for complex reasoning tasks.
Initially, LLM evolution was driven by scaling laws. Performance improved predictably with more data, parameters, and training time—GPT-2 and GPT-3 exemplified this trend. However, as limitations in cost and efficiency became apparent, research shifted to two new axes:
- Efficient and lightweight: Getting smarter with the same resources rather than simply bigger. Techniques that reduce computation during pretraining, fine-tuning, and inference while focusing on what’s essential have become mainstream.
- Multimodal: Models that understand and generate not just text but also images, audio, and video are becoming standard, because real-world challenges involve multiple signal types simultaneously.
What accelerated this shift were the structural limitations of traditional LLMs. Let’s examine these limitations specifically, with particular focus on hallucination and shallow reasoning.
Hallucination: Baseless confidence
Hallucination occurs when models produce plausible-sounding but inaccurate statements. For example, if you ask an absurd question like “Explain King Sejong the Great’s MacBook Pro throwing incident,” the model might answer: “King Sejong, under great stress during the creation of Hangul…” making it sound like something that could have happened, even though it never did. This happens because the goal is next-token prediction, not fact validation.
Shallow reasoning: Skipping steps
Even for simple logical problems, skipping intermediate steps can lead to errors. If you ask: “Scott is older than Emily, Emily is older than James. Who’s older—Scott or James?” the model might instantly give the wrong answer “James” if it doesn’t work through the steps and instead chooses a more familiar, higher-probability pattern. This is why errors tend to accumulate in longer problems requiring multi-step reasoning.
How reasoning models work
Reasoning models emerged to address these limitations. Previous LLMs were optimized to quickly choose the most plausible next word once asked a question. Reasoning models, however, think before answering and modify their responses when wrong—just as humans do. They internalize a self-verification loop through training: forming multiple hypotheses with different solution paths, evaluating intermediate results, and revising when they find contradictions.
- Plan: Breaks down possible solution paths
- Verify: Checks whether intermediate and final computations are sound
- Refine: Returns to previous steps to change course when errors are found
By repeating these three steps, both the probability and reliability of reaching correct answers increase.
Chain of thought: A window into AI thinking
Chain of thought (CoT) is a prompting technique that reveals how the model reaches an answer sentence by sentence, rather than simply providing the final result. The easiest way to apply this technique is adding something like “Let’s think step by step” to your prompt. This single phrase transforms the model’s approach, shifting from instant-answer mode to thinking mode, where it lists intermediate steps and validates them independently.
Why chain of thought works: Activating hidden potential
The key elements are time and structure. LLMs already possess latent capabilities for sequential reasoning, arithmetic, and rule application through large-scale pretraining. It’s just that the default decoding mode prioritizes instant answering—quickly choosing the most likely next token—making it probable that models jump to conclusions without sufficient exploration and verification.
Chain-of-thought prompts change this default mode. They give the model more token budget (more time to think) and break questions into steps that expose intermediate results. This produces the following effects:
- Exploration: Examines multiple hypotheses and solution paths before choosing the most consistent one
- Structurization: Divides large questions into sub-problems to perform computation and rule application sequentially
- Verification: Externalizes intermediate evidence, enabling self-verification and the use of tools like calculators and search to correct errors
Chain of thought in action
<Mathematical reasoning example>

<Korean decoding example>
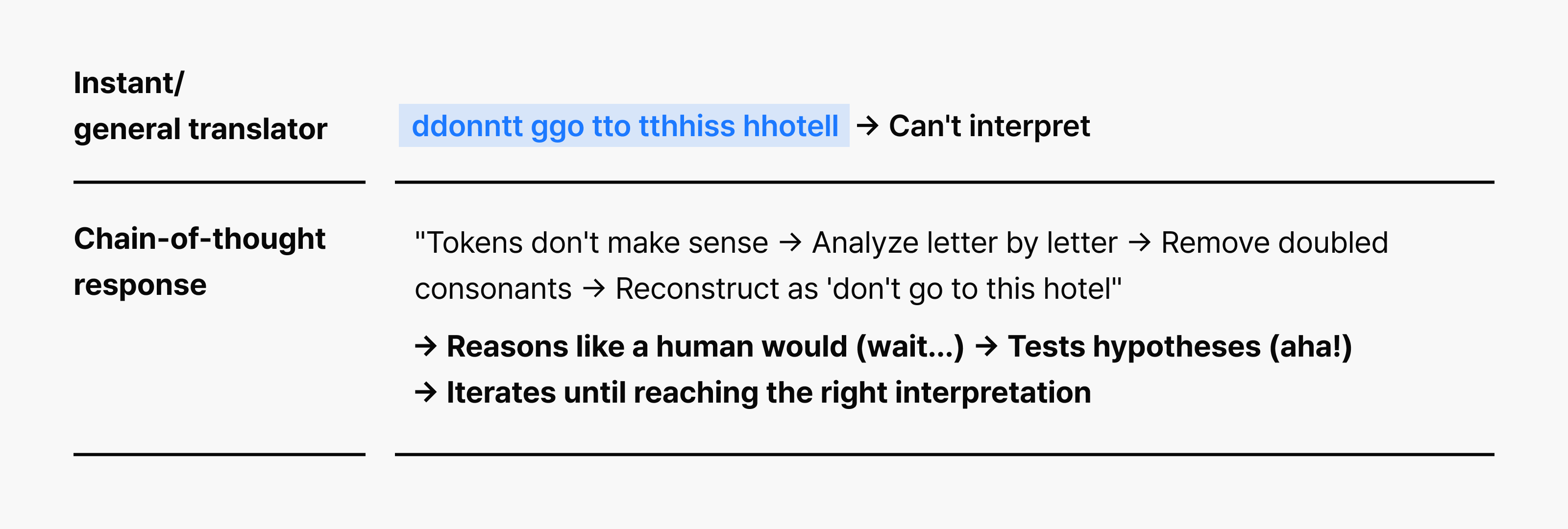
To summarize, reasoning models don’t stop at getting the right answer. Through extended, deliberate internal dialogue, they provide reasoning that explains why the answer is correct and persuades you of its validity. Chain of thought is the simplest yet most powerful lever for transforming a model’s hidden reasoning capabilities from instantaneous responses to thoughtful processing, and externalizing them into actual performance.
Looking ahead: Prospects and challenges
1) Compute and cost constraints
Reasoning models generate thousands to tens of thousands of tokens during their thinking process before producing an answer. As token count increases, computational power, latency, and costs rise more than linearly, which also leads to increased carbon emissions from large-scale data centers. This makes the following optimization approaches critical challenges:
- Think short: Answer simple questions immediately and apply chain of thought only for difficult questions to conserve computation
- Think quick: Use draft-then-finalize decoding, KV cache for context reuse, and selective module activation to distribute computation and improve response speed
- Think outside: Delegate calculation, search, and code execution to external tools to minimize tokens generated by the model
- Compress through training: Preserve knowledge gained through deep thinking via distillation, enabling shorter, faster answers next time
2) Multimodal reasoning
Real-world problems can’t be solved with text alone. In healthcare, for example, doctors diagnose patients by considering CT images, medical history records, and even subtle tremors in the patient’s voice. Models need similar capabilities:
- Vision and text integration: Understand text, tables, images, and video simultaneously and explain, summarize, or generate appropriately
- Cross-verification: Show “Why did you reach that conclusion?” with precise source locations
- Real-time responsiveness: Respond instantly to streaming audio input and update judgments immediately as screen content changes
- Domain adaptation: Align using localized, domain-specific data (healthcare, manufacturing, finance, etc.) while internalizing bias mitigation and privacy standards
3) The rise of AI agents
In the future, AI won’t stop at providing information—it will evolve into agents that set goals (plan), call tools for execution (act), and adapt based on results (observe). For example, if a user says “weekend overnight trip to Busan,” the agent considers weather, budget, and travel companions to search for transportation, lodging, and restaurants, compare options, build an itinerary, and complete bookings. It even automatically replans when circumstances change, like flight delays or waitlist openings.
Conclusion
The center of gravity in AI is shifting from systems that recall answers to ones that provide evidence for claims and verify truthfulness autonomously. By layering chain-of-thought reasoning, tool-calling, and self-verification onto large-scale pretraining, reasoning models have advanced beyond simple accuracy improvements to fundamentally transforming how we implement, explain, and evaluate intelligence.
This paradigm shift is also changing research standards. Rather than “what it knows and how much,” the core of competitiveness becomes “how deeply and consistently can it think” and “how transparent are its steps.” The evolution toward agents—from multimodal understanding and efficient reasoning (spending more time thinking only when necessary) to reliability assurance (providing evidence, verification, and safeguards) and execution—will become the default for next-generation AI stacks.
To summarize in a single sentence: what will distinguish models will be the quality of thinking, not the quantity of knowledge. The winners who write AI’s next chapter will need to move beyond building “AI that knows well” to creating systems “that think well, provide evidence, and execute to completion” with speed, safety, and efficiency.
Learn more in KBS N Series, AI Topia, episode 1
You can see all of this in action in the first episode of KBS N Series’ AI Topia, where NAVER Cloud’s AI Lab leader Yun Sangdoo breaks down these ideas with clear examples and helpful context. It’s a great way to get a fuller picture of what we’ve covered here!