
Introduction
What happens when AI sits for an exam? As generative AI grows more sophisticated, people increasingly ask whether these models can solve problems the way humans do. Many want to see how AI performs under rigorous testing conditions—like Korea’s college entrance exam.
At NAVER Cloud, we set out to answer this question. In our paper “Evaluating Multimodal Generative AI with Korean Educational Standards,” presented at 2025 NAACL, we introduced the Korean National Educational Test Benchmark (KoNET)—an evaluation benchmark that puts AI to test using Korea’s national educational systems.
In our earlier post on HyperCLOVA X THINK, we demonstrated how college entrance exam questions from KoNET revealed our model’s reasoning capabilities firsthand. This real-world application shows that KoNET is more than just another benchmark—it’s a practical tool for objectively comparing how different AI models perform. You can learn more about HyperCLOVA X THINK in our previous blog post.
KoNET uses actual exam questions based on Korea’s educational standards to evaluate generative AI’s learning and reasoning capabilities under genuine testing conditions. This approach allows us to identify precise strengths and weaknesses in AI models, offering a valuable reference point for developing systems tailored to Korean educational contexts.
AI takes the college entrance exam
Our research team converted all questions from elementary through high school General Educational Development tests (KoEGED, KoMGED, KoHGED) and the College Scholastic Ability Test (KoCSAT) into images and used them to evaluate both text-only LLMs and multimodal LLMs that process both text and visual information.
The results were surprising. While AI performance declined as educational level increased from elementary through college—as we had expected—the performance drop at the college entrance exam level was much steeper than anticipated. This shows that even the latest models struggle with the complexity of real-world testing environments.
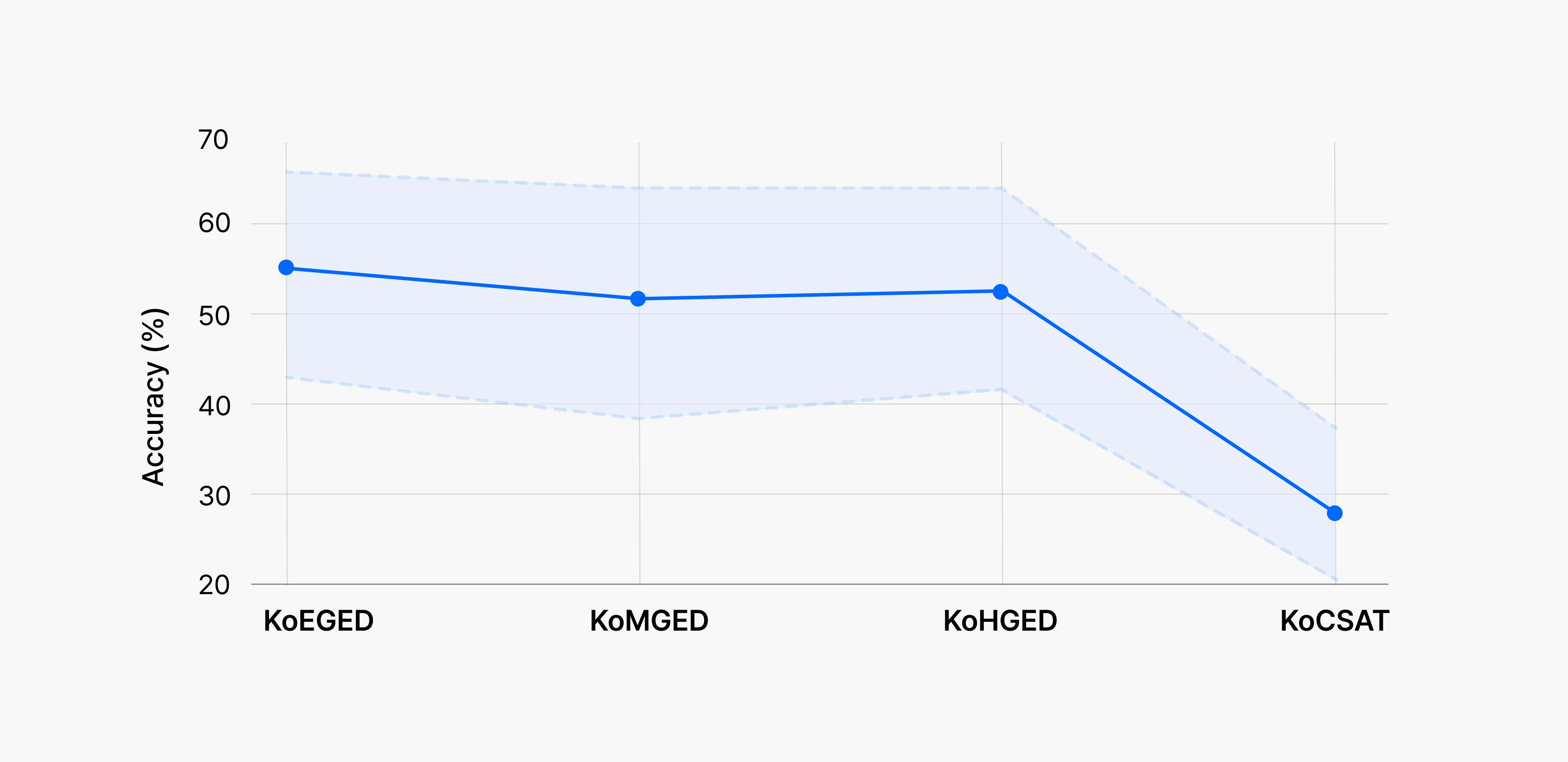
Korean Elementary General Educational Development Test (KoEGED), Middle (KoMGED),
High (KoHGED), and College Scholastic Ability Test (KoCSAT)
We discovered another compelling finding: bigger models didn’t necessarily perform better. Korean-focused models like NAVER Cloud’s HyperCLOVA X and LG’s EXAONE often outperformed global models with comparable parameter counts across several tests. The performance gaps, invisible in English-centric benchmarks, became clear with KoNET. This underscores how important it is for each country to develop datasets rooted in their own language, educational systems, and cultural contexts—along with evaluation standards that reflect those unique characteristics.
Introducing the KoNET benchmark
KoNET encompasses four official Korean educational tests: elementary through high school General Educational Development tests (KoEGED, KoMGED, KoHGED) and the College Scholastic Ability Test (KoCSAT).
- General Educational Development tests: Complete exam questions from both the first and second sessions of 2023
- College Scholastic Ability Test: Comprehensive coverage of all 2024 CSAT subjects, including Korean, Mathematics, English, Korean History, Social Studies, Science, Vocational Studies, and Second Foreign Languages
We recreated realistic exam conditions by converting all questions, multiple-choice options, and visual elements into unified image formats that mirror actual test papers. This approach aligns with current trends in multimodal AI evaluation, where models must process integrated text-visual information.
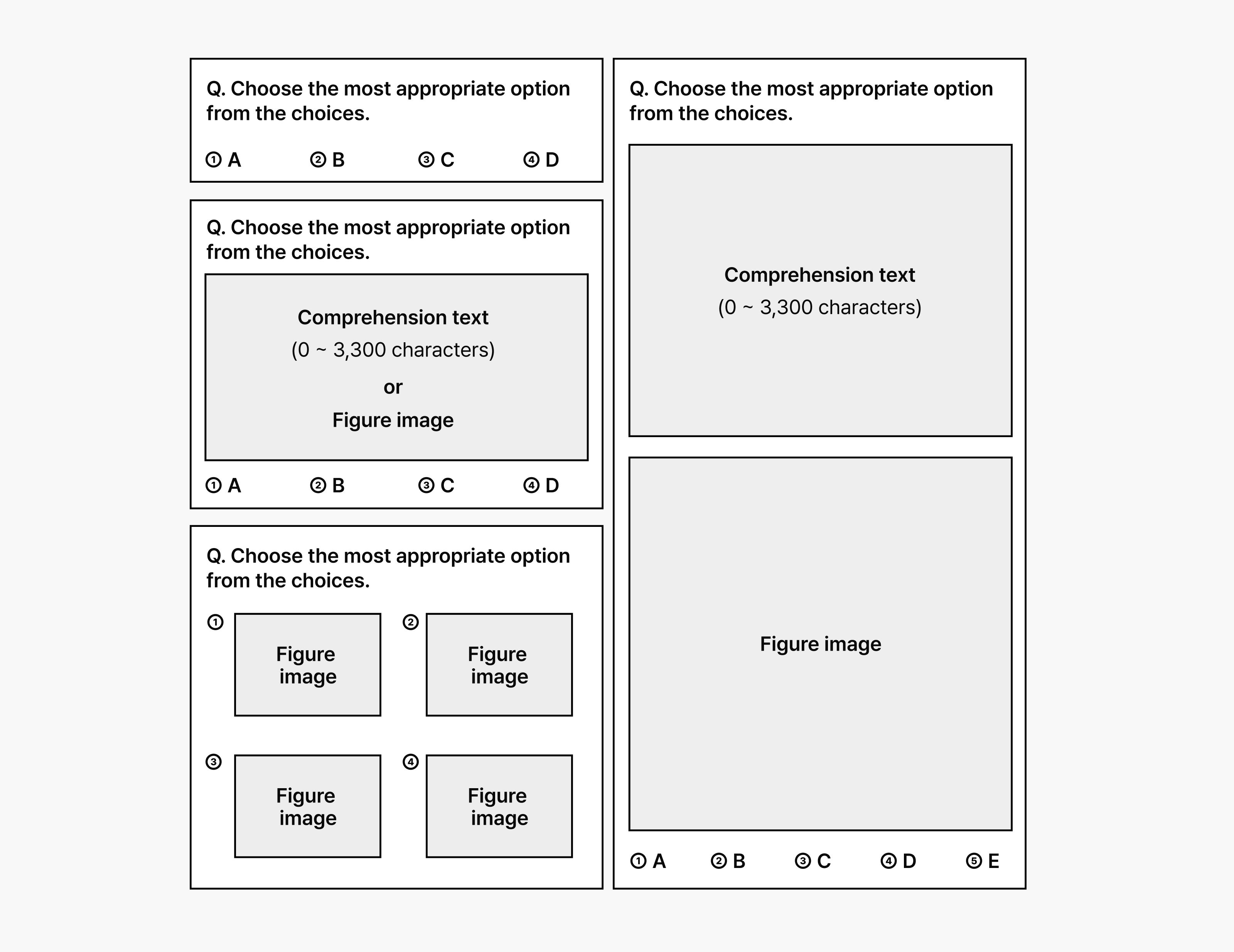
Figure: KoNET test paper

Figure: College Scholastic Ability Test question
The CSAT data proved particularly valuable because it included error rates from 500,000 actual test-takers, which enables direct difficulty comparisons between AI systems and human students. The evaluation also covered Second Foreign Language subjects like German, French, and Chinese, letting us examine how models perform beyond Korean.
We’ve released our dataset generation code on GitHub, ensuring researchers and practitioners worldwide can access and use the data.
What the leaderboard reveals
The performance numbers tell an interesting story.
- Commercial API-based multimodal LLMs like GPT-4o and Claude 3.5 Sonnet consistently delivered strong performance, achieving scores above 80% on average. Meanwhile, recent open-source LLMs and multimodal LLMs showed significant variation depending on model size and primary language focus.
- Notably, EXAONE-3.0-7.8B outperformed global models with similar parameter counts and even matched larger models like Qwen2-72B, though it still lagged behind commercial API-based models on Korean language benchmarks.
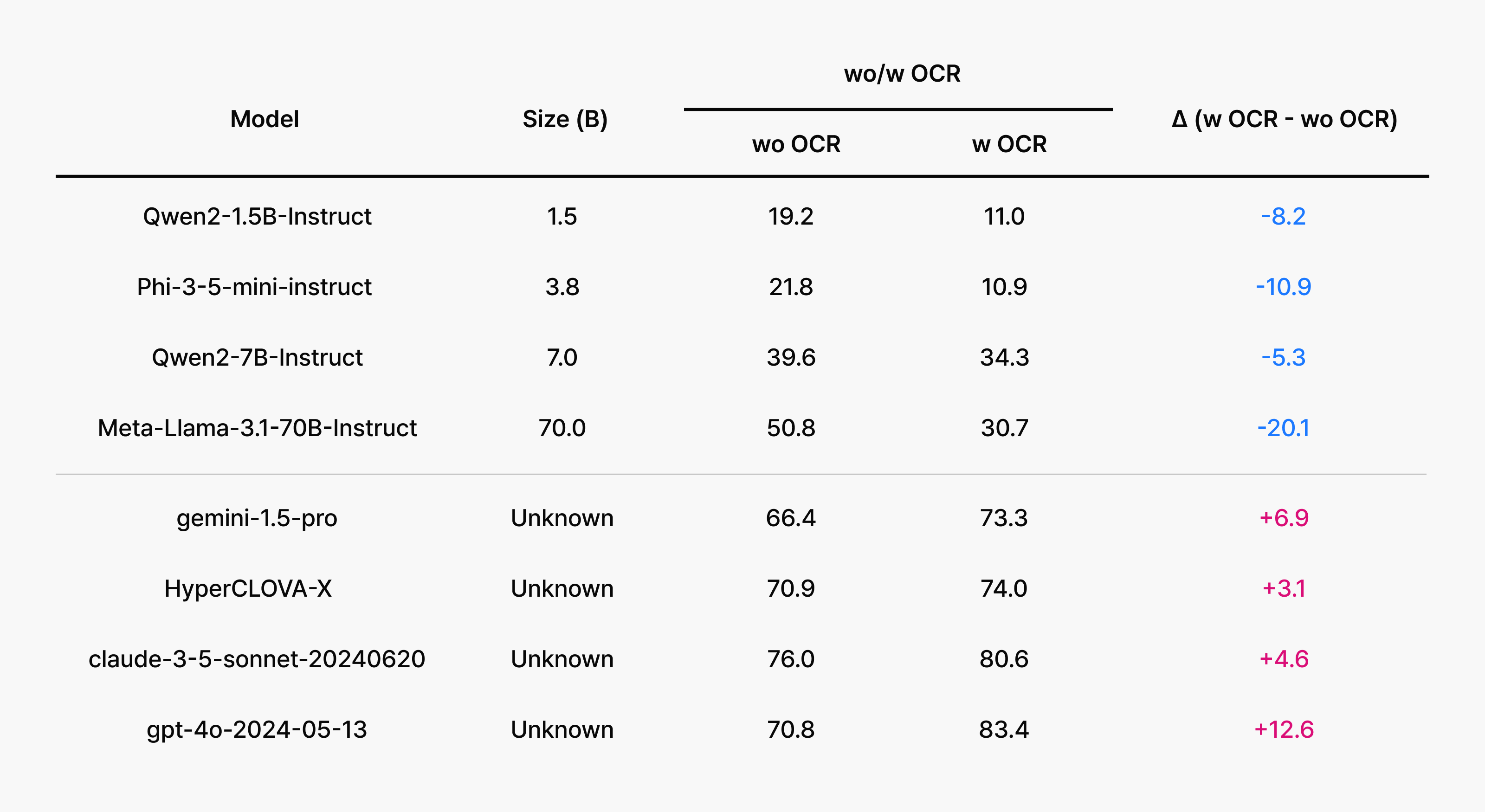
- Open-source multimodal models showed a particular weakness in Korean OCR and text recognition, while traditional LLM+OCR pipelines maintained more reliable and consistent performance.
The key insight here is revealing: in college entrance exam scenarios where questions and options are presented as single images, OCR technology and Korean language preprocessing made all the difference. When OCR systems struggle, they miss or misread passages, creating a bottleneck that prevents even capable reasoning models from reaching correct answers.
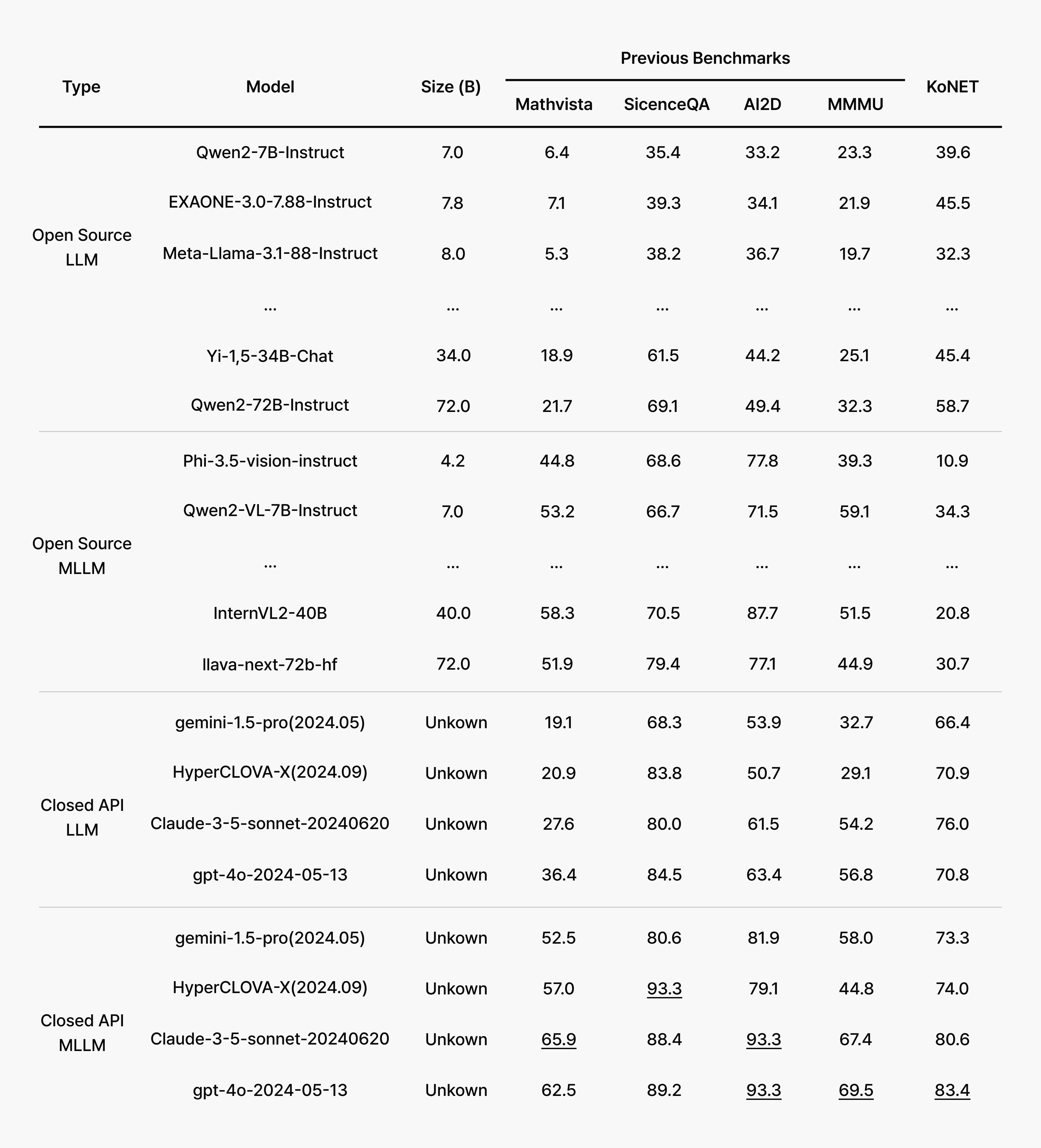
Analysis 1: Can multimodal AI really solve CSAT questions?
Success on KoNET demands more than text comprehension. Models must simultaneously process charts, tables, graphs, figures, and captions integrated with Korean text. However, open-source multimodal LLMs often lack robust OCR foundations, causing them to misread passages and derail their reasoning chains. We consistently observed that pipelines combining LLMs with separate OCR engines achieved more stable results.
Commercial models like GPT-4o and Claude, by contrast, possess built-in OCR capabilities and strong layout understanding, enabling them to accurately reconstruct context. Crucially, they can maintain consistent performance even when questions and answer choices are presented as single images.
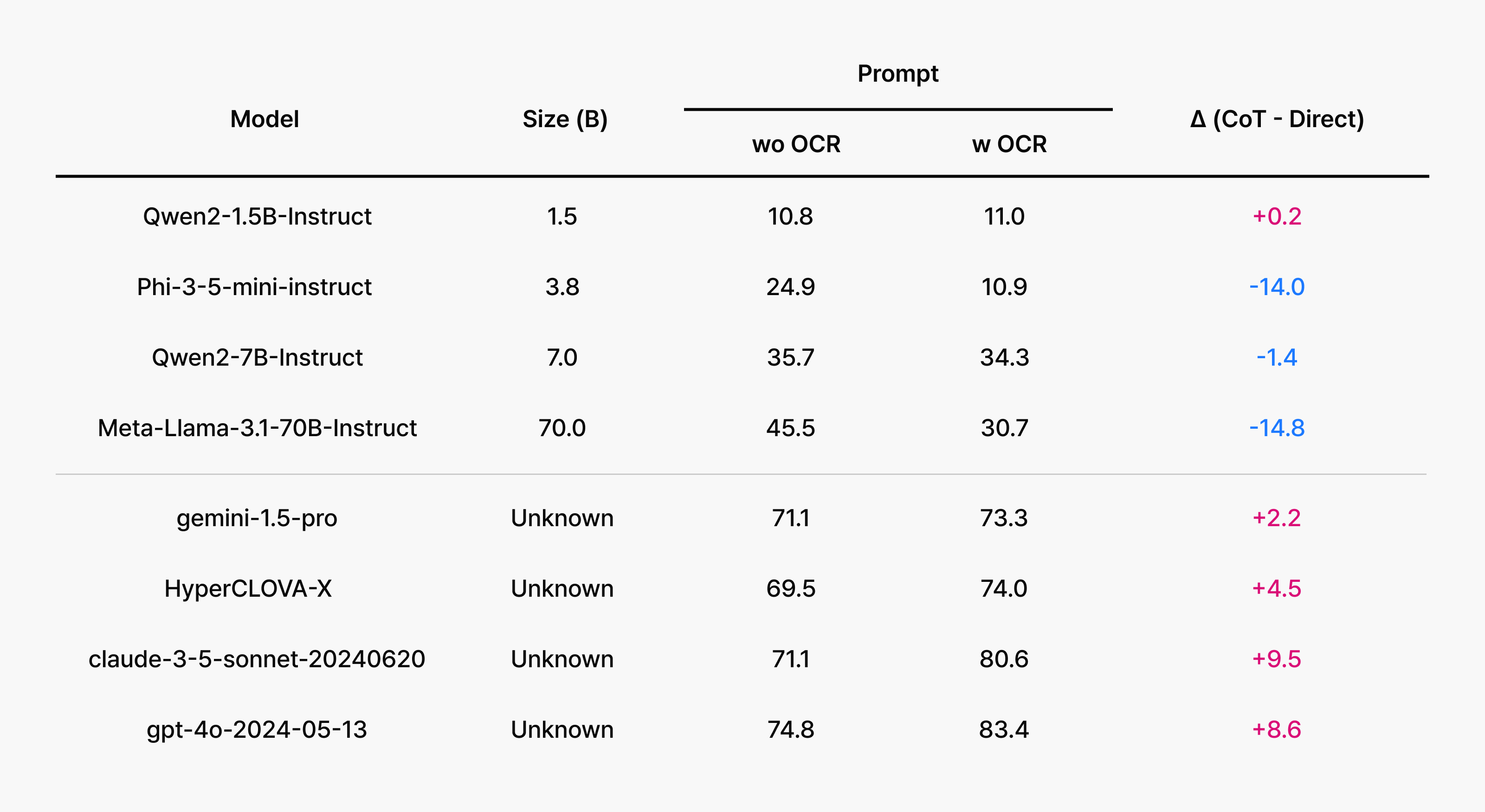
Analysis 2: Is chain-of-thought prompting effective?
Chain-of-thought (CoT) prompting encourages step-by-step reasoning when solving a problem. Their effectiveness becomes more apparent as questions progress from simple visual question answering to more complex problems. We confirmed this trend in our experiments: GPT-4o demonstrated approximately 10 percentage points improvement with CoT prompting alone. Open-source models varied in their improvement levels, but across all models, we observed that higher difficulty levels made the benefits of CoT prompts clearer. The pattern is clear: encouraging step-by-step reasoning consistently improves performance.
Analysis 3: AI vs. human error patterns
The most fascinating aspect of our research was direct comparison between AI and human mistake patterns.
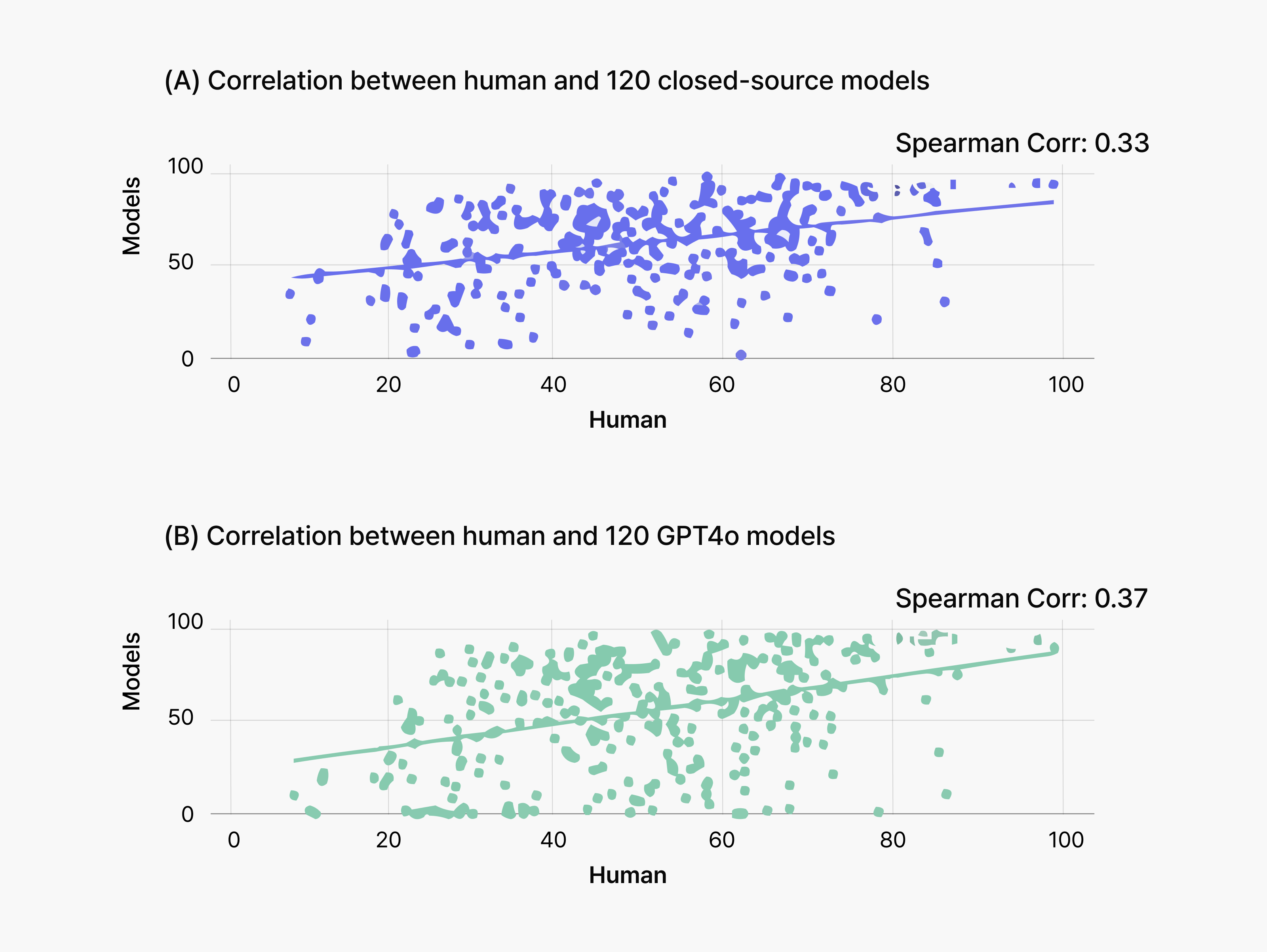
AI achieved relatively reliable performance on reading comprehension questions that was repetitive or required sustained attention, while humans excelled on questions requiring background knowledge or understanding of Korea’s cultural and historical context. The correlation coefficient between error rates was 0.33-0.37— confirming that AI and humans struggle with fundamentally different question types.
Our scatter plot analysis visualizes this divergence. Each dot represents a question, plotted by human error rate (x-axis) versus AI error rate (y-axis). If both groups found questions similarly challenging, dots would cluster along the diagonal. Instead, the widespread scattering demonstrates that humans and AI assess question difficulty differently.
Key patterns:
- AI showed consistent performance on repetitive reading comprehension tasks requiring sustained focus.
- Humans showed superior results on questions requiring cultural knowledge and historical context.
- The low correlation coefficient (0.33-0.37) confirms that mistake patterns rarely overlap between the two groups.
- Dots near the diagonal indicate similar difficulty perception; the widespread scattering shows humans and AI assess question difficulty quite differently.
Another notable aspect of our methodology is that we didn’t simply examine basic model outputs. To deepen this analysis, we tested models with different personas—”teacher,” “professor,” “academic,” and “student”—while adjusting reasoning parameters to generate diverse response patterns for error rate calculation. This approach mirrors how students with different learning styles and ways of thinking tackle the same problems, enabling us to conduct more realistic performance assessments.
KoNET’s inclusion of actual test-taker error rates for each question enabled analytical depth. Rather than relying on simple pass/fail metrics, we identified specific factors driving performance gaps: reasoning processes, background knowledge, and layout understanding. This in-depth analysis revealed not just where AI and humans differed, but why these differences emerged, significantly enhancing the value of our research.
Conclusion
This research highlighted the critical need for benchmarks grounded in Korean language and educational contexts. We confirmed that existing English-centered metrics make it difficult to identify where AI models show specific strengths and limitations in real-world Korean environments.
We learned similar lessons during AI development and deployment. Through hands-on experience, we saw how fine-tuning models using Korean-specific OCR technology, reading comprehension capabilities, and Korean educational data played a decisive role in performance improvements.
Our work developing KoNET bridges the gap between research and industry applications. We believe it will serve as an important benchmark for advancing AI competitiveness in Korean contexts and beyond.
Explore our complete findings in the full research paper.