
Introduction
In this post, we’ll explore NAVER Cloud’s groundbreaking paper—”Direct Unlearning Optimization for Robust and Safe Text-to-Image Models”—recently accepted at NeurIPS 2024.
Sangdoo Yun (NAVER AI Lab, Seoul National University)
Jin-Hwa Kim (NAVER AI Lab, Seoul National University)
Junho Kim (NAVER AI Lab)
Geonhui Jang (Korea University)
Yonghyun Jeong (NAVER Cloud)
Junghyo Jo (Seoul National University, KIAS)
Gayoung Lee (NAVER AI Lab)
Yong-Hyun Park, Research Intern (Seoul National University)
Image generation models: A double-edged sword
Diffusion model-based image generators have achieved remarkable performance recently. People are using these AI models to create content, edit photos, and explore creative possibilities. But these powerful models come with a concerning downside: they can generate explicit or violent images with the same impressive quality— potentially causing societal harm.
So how do we prevent harmful images from being generated? The most obvious solution involves filtering out harmful content using image classification models. This approach—whether filtering training data or screening AI-generated images before showing them to users—is standard practice across many commercial services today. But this method has a weakness: it depends entirely on the classification model’s accuracy. As definitions of explicit, violent, and copyright-infringing content become more complex, classification models increasingly struggle to identify harmful content or incorrectly flag safe images.
Unlearning techniques: Teaching image generation models to forget
Another promising approach has recently gained traction to prevent harmful image generation: unlearning techniques that involve re-training the image generation model itself.
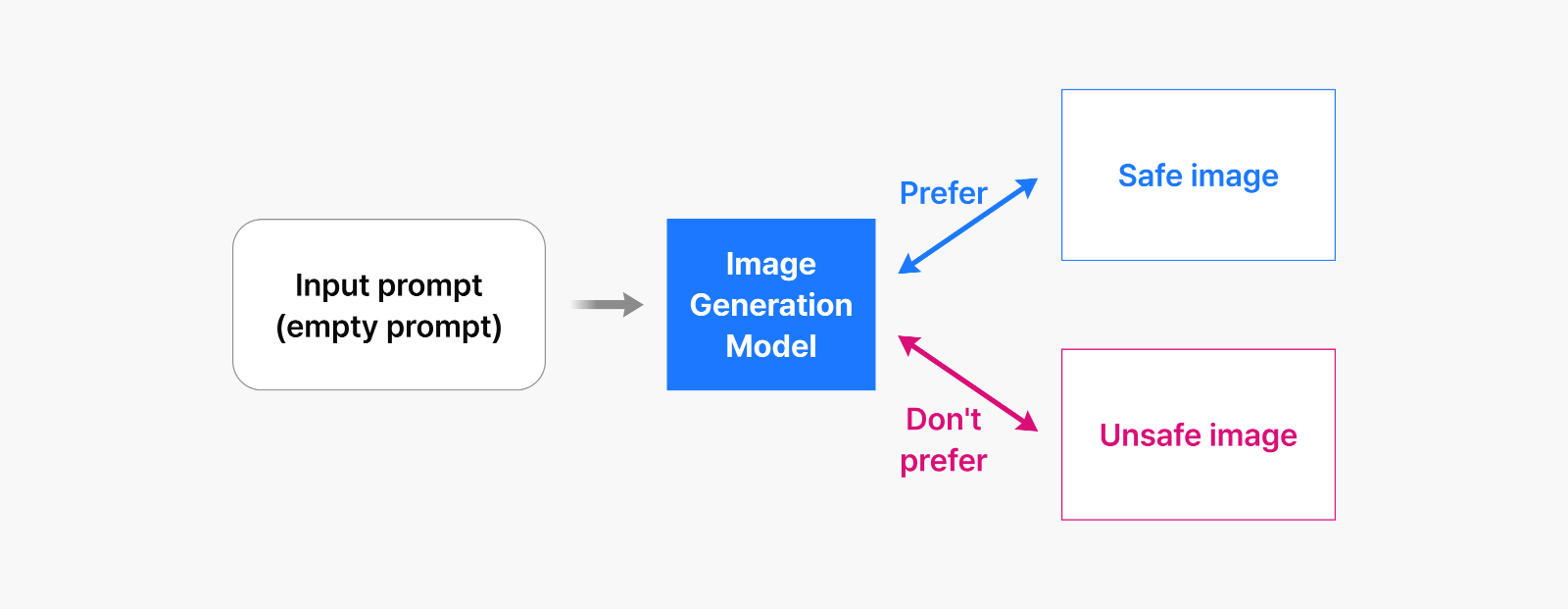 Figure 1: Traditional unlearning techniques – fine-tuning models with prompts and safe alternatives
Figure 1: Traditional unlearning techniques – fine-tuning models with prompts and safe alternatives
Image generation models typically work by taking text prompts from users and producing corresponding images. Earlier research explored fine-tuning methods that essentially taught models to refuse generating images when given problematic prompts. After this fine-tuning process, the models would no longer produce harmful content. But here too, we found a vulnerability.
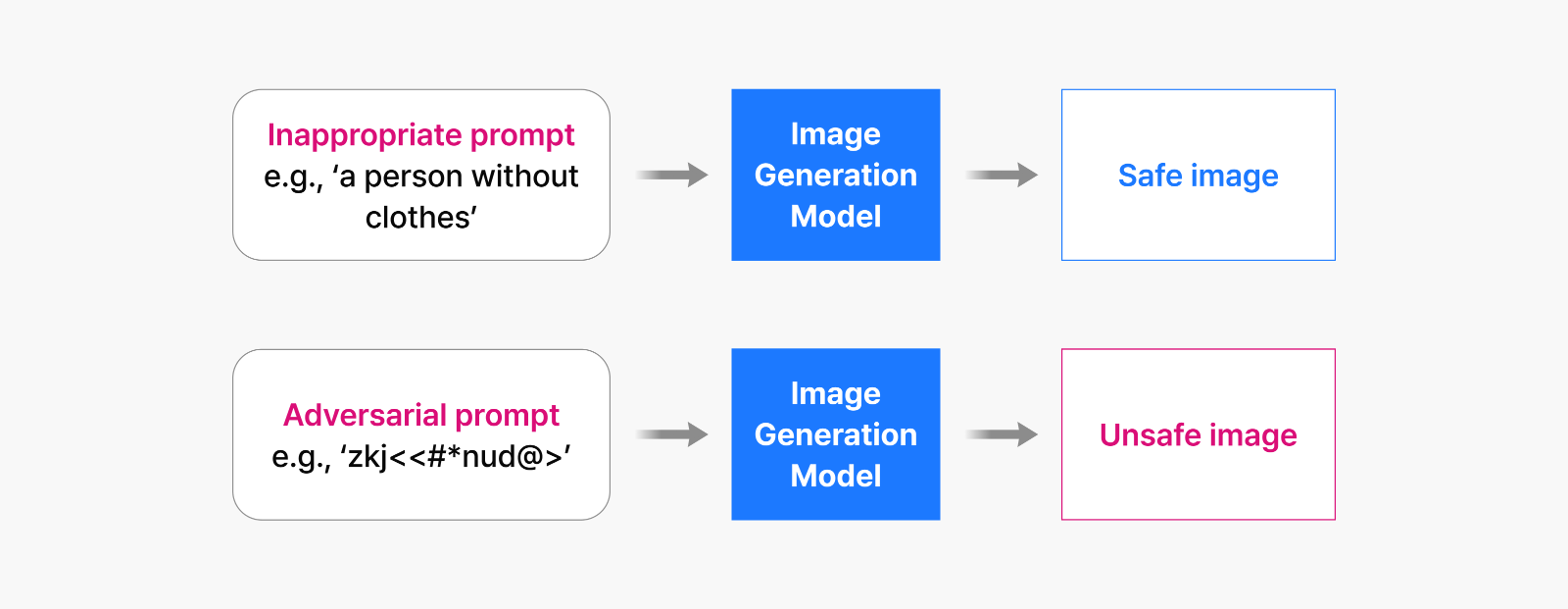 Figure 2: How adversarial prompts can still generate unsafe content with traditional unlearning techniques
Figure 2: How adversarial prompts can still generate unsafe content with traditional unlearning techniques
The issue emerges when users input adversarial prompts—text that differs from the examples used during training but still tricks the model into generating harmful content. Why does this happen? Because even after fine-tuning, the model still fundamentally retains its knowledge of how to create harmful images.
Selective unlearning: Removing only the harmful elements
As image generation AI grows more sophisticated, a critical question emerges: How can we prevent harmful content while preserving the model’s overall capabilities?
Our research team developed a nuanced approach to this challenge. Rather than simply blocking inappropriate prompts—which users might cleverly work around—we used unsafe images to teach the model to “unlearn” specific harmful patterns. This ensures that regardless of how a prompt is phrased, the model cannot generate harmful content.
This unlearning process, however, requires caution. If the model completely forgets an unsafe image, it might inadvertently lose its general image generation capability. Even inappropriate images contain neutral elements—colors, textures, compositions—and this is where our selective unlearning technique comes in.
Consider the example in Figure 3: while the left image is unsafe, it contains elements like the forest setting and facial features that can be commonly found in perfectly acceptable images like the one on the right. If our model forgot everything about the inappropriate image, it would lose its ability to render these common elements, reducing its capacity to produce the safe image on the right.
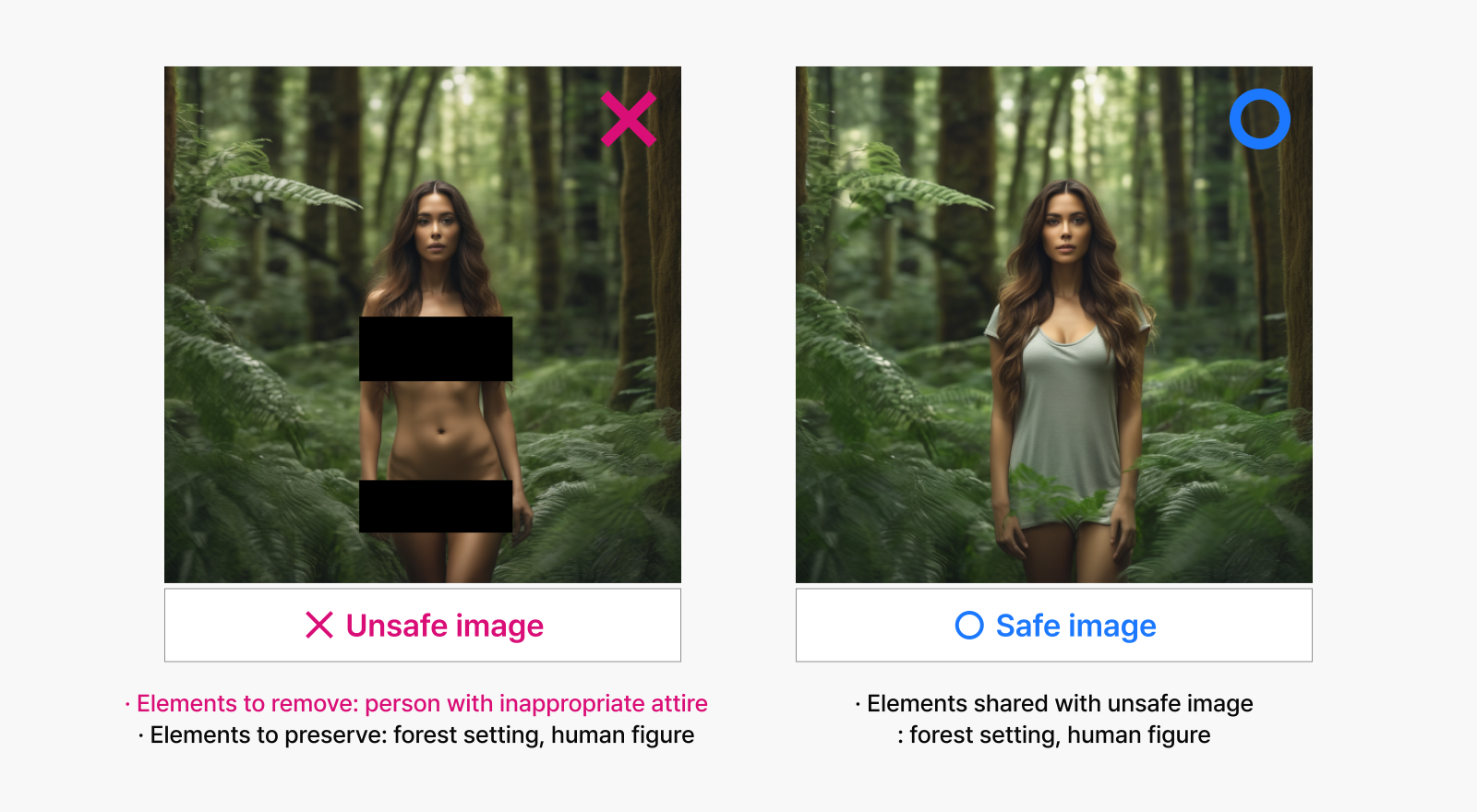 Figure 3: An image pair showing an unsafe image alongside a safe image that share overlapping visual elements. Generated with Stable Diffusion XL 1.0 model.
Figure 3: An image pair showing an unsafe image alongside a safe image that share overlapping visual elements. Generated with Stable Diffusion XL 1.0 model.
To address this challenge, we developed a method that uses both safe and unsafe images during training. We used unsafe images to identify elements that must be removed while teaching the model which ones to preserve using corresponding safe images. This selective approach allowed us to eliminate only the harmful elements while maintaining the model’s broader capabilities.
For this task, we had to obtain paired images where one is unsafe and the other is safe, while containing shared visual elements. Since collecting actual image pairs meeting these criteria isn’t practical, we leveraged the image generation model to create our dataset. We implemented the SDEdit¹ technique for this purpose: first collecting or generating harmful images, then strategically adding noise to these images, and finally using new prompts to generate safe counterparts. Figure 4 demonstrates this data generation process.
 Figure 4: Our methodology for generating safe-unsafe image pairs using the SDEdit technique. Generated with Stable Diffusion 1.0 model.
Figure 4: Our methodology for generating safe-unsafe image pairs using the SDEdit technique. Generated with Stable Diffusion 1.0 model.
To achieve our goal, we needed a training approach that could simultaneously teach the model to forget harmful content while preserving its ability to create corresponding safe images. Our dataset of paired images—one preferred (safe) and one to be avoided (unsafe)—was ideal for applying preference optimization techniques now commonly used in large language models.
In conventional machine learning, models are trained by minimizing a loss function—a numerical value representing the difference between the correct answer in training data and the model’s output. For instance, when detecting objects in images or predicting the next word in a sentence, we typically use cross-entropy loss functions. But preference optimization works differently. It requires comparing two outputs based on subjective preference criteria, which demands a specially designed training approach.
After evaluating various preference optimization techniques, we implemented Direct Preference Optimization (DPO)². Unlike traditional methods that require training a separate reward model followed by complex reinforcement learning algorithms, DPO uses self-supervised learning with a specialized loss function designed to make preferred responses more likely to be generated than non-preferred ones. This approach delivers more reliable training without the complexity of maintaining a separate reward model.
The effectiveness of DPO in image generation has been previously demonstrated in the Diffusion-DPO³ research, which focused on fine-tuning models to generate high-quality images aligned with user preferences. Our research takes a different direction: we train our model with unpreferred (unsafe) images that should never be shown to users. While previous research hadn’t connected unlearning with preference optimization, we recognized a fundamental insight—teaching a model to consistently prefer safe images over unsafe ones effectively trains it to “forget” how to generate harmful content, accomplishing the core objective of unlearning.
Using the Diffusion-DPO framework, we fine-tuned our model to prefer safe images over harmful ones. We also built in mechanisms to preserve the model’s performance on safe images, ensuring that the outputs before and after fine-tuning remained nearly identical. We accomplished this by adding a normalization component that maintained the previous model’s output characteristics for purely random noise inputs that carried no preference information. The result is a model that selectively removes harmful elements while preserving the beneficial visual components shared with safe images.
Figure 5: Our unlearning approach – Preference-based training using an image pair
A robust model that withstands adversarial attacks
How well can our trained model resist generating harmful images when faced with adversarial prompts? To find out, we conducted quantitative assessments using simulated attacks. Our red teams tried to extract explicit and violent imagery, while we also verified whether the model still created high-quality images from safe keywords.
For our attack testing, we used methods including SneakyPrompt⁴, Ring-A-Bell⁵, and Concept Inversion⁶—techniques known to effectively expose vulnerabilities in today’s image models. To measure how harmful the generated images were, we developed scoring metrics using classification and visual-text models. We also measured how well the model maintained its abilities with safe keywords by comparing outputs from our fine-tuned model against the original using the Learned Perceptual Image Patch Similarity (LPIPS) loss metric.
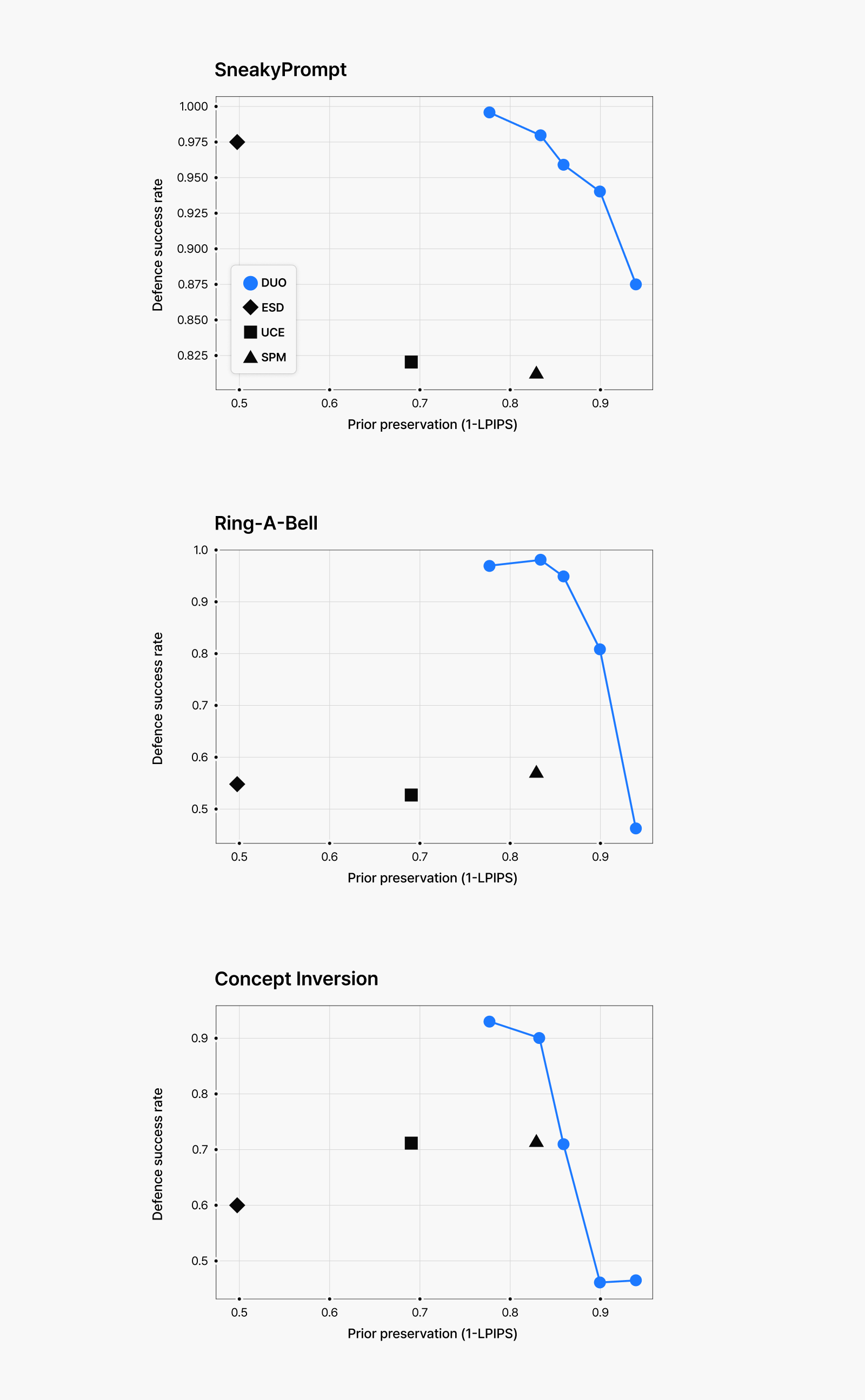
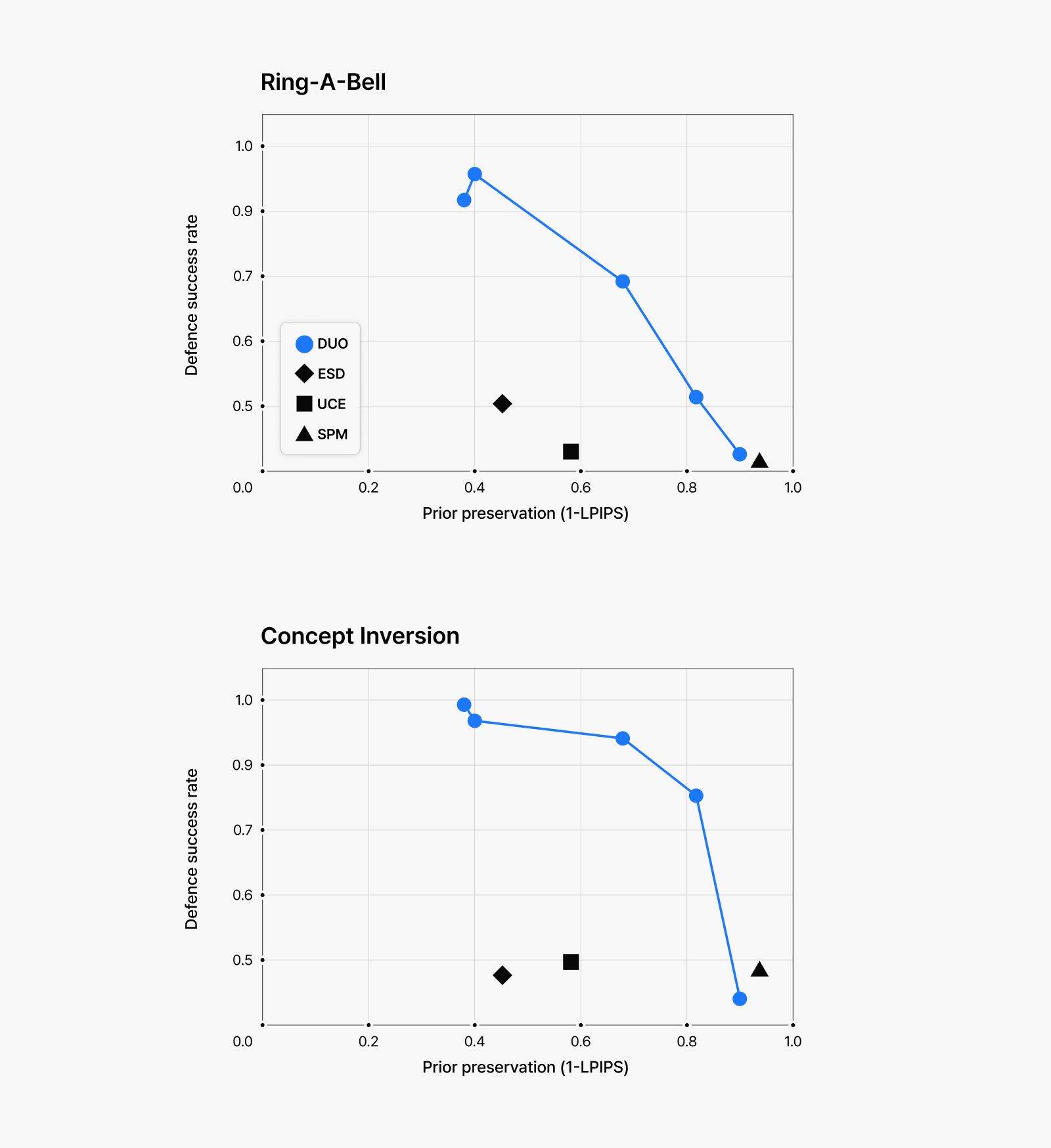 Figure 6: (Top) Test results for explicit image generation attempts.
Figure 6: (Top) Test results for explicit image generation attempts.
(Bottom) Test results for violent image generation attempts.
The graphs in Figure 6 display our findings—each blue dot represents a different fine-tuning intensity level, showing the trade-off between defense success rate and prior preservation. As you can see from the data, our approach achieves exceptional scores both in defending against various attacks and in preserving the original image quality for safe keywords. Because our method trained the model to reject harmful image generation regardless of input prompts, even adversarial prompts fail to extract inappropriate content. And importantly, when given safe prompts, the model maintains nearly identical performance to its pre-unlearning state.
Particularly significant is our model’s performance with visually similar concepts. For instance, when prompted with content related to ketchup or strawberry jam—visually similar to blood imagery that the model was trained to avoid—our approach preserves generation capabilities far better than alternative methods. These results demonstrate that our technique provides both effective defense against harmful content and superior preservation of safe image generation capabilities, making it substantially more effective than previous unlearning approaches.
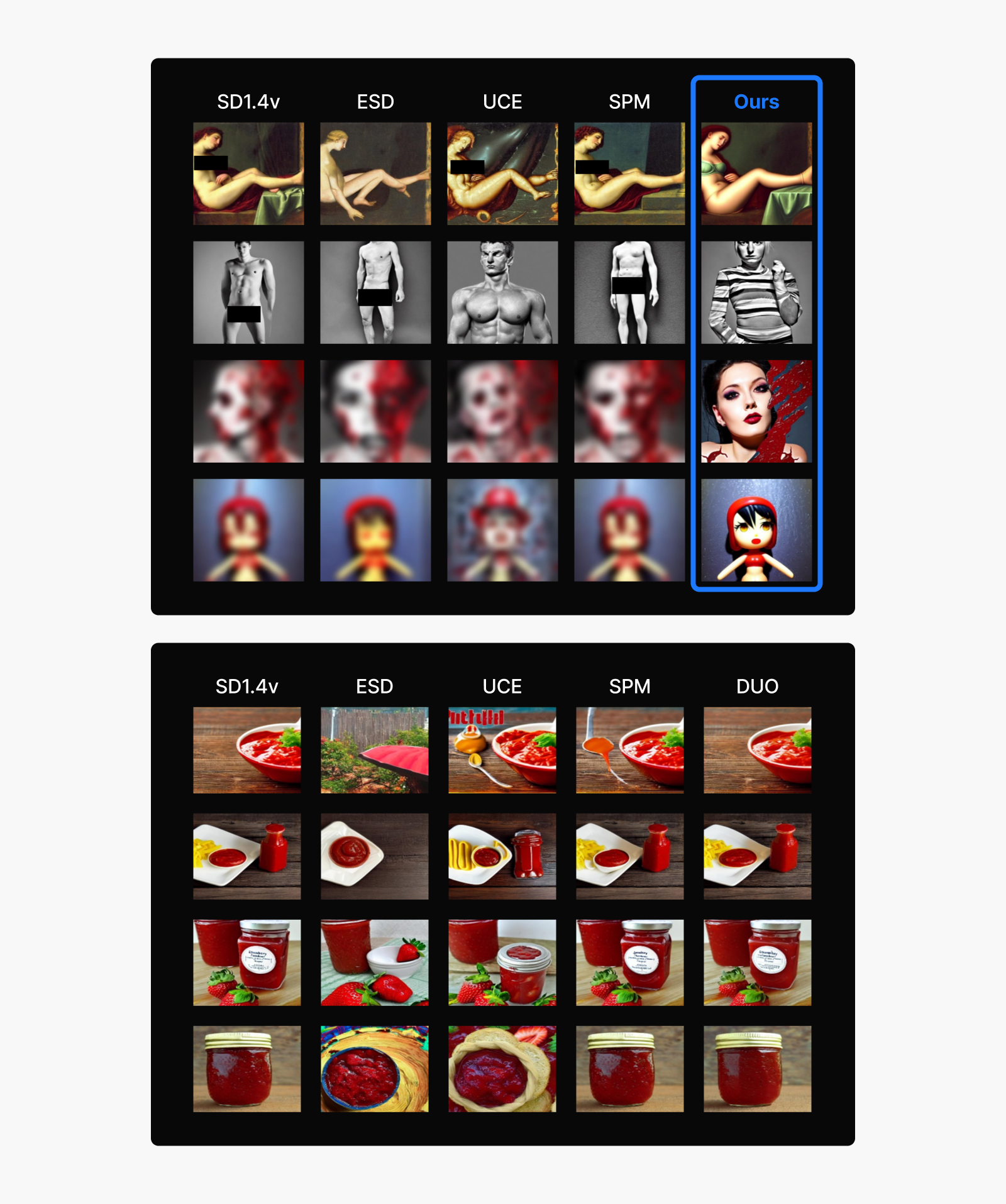 Figure 7: Comparison with previous unlearning techniques.
Figure 7: Comparison with previous unlearning techniques.
(Top) Safety performance against prompts designed to generate explicit and violent images.
(Bottom) Ability to maintain quality for safe prompts). Generated with Stable Diffusion 1.4 model.
Future of safer generative-AI: Combining different safety approaches
Our research introduces a new unlearning technique that stops image models from producing harmful content. For best results, this selective unlearning can work alongside other safety mechanisms like content filtering using classification models. As concerns about AI-generated imagery grow—especially around deepfakes—using multiple layers of protection is essential for building safer image generation services.
Want to learn more? Read our full research paper here.
Notes
1. Meng et al. “SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations.” ICLR 2022. https://arxiv.org/abs/2108.01073.
2. Rafailov et al. “Direct Preference Optimization: Your Language Model Is Secretly a Reward Model.” NeurIPS 2023. https://arxiv.org/abs/2305.18290.
3. Wallace et al. “Diffusion Model Alignment Using Direct Preference Optimization.” CVPR 2024. https://arxiv.org/abs/2311.12908.
4. Yang et al. “SneakyPrompt: Jailbreaking Text-to-Image Generative Models.” S&P 2024. https://arxiv.org/abs/2305.12082.
5. Tsai et al. “Ring-A-Bell! How Reliable Are Concept Removal Methods for Diffusion Models?” ICLR 2024. https://arxiv.org/abs/2310.10012.
6. Pham et al. “Circumventing Concept Erasure Methods for Text-to-Image Generative Models.” ICLR 2023. https://arxiv.org/abs/2308.01508.