
The AI semiconductor boom
AI semiconductors have become the stock market’s hottest trend, highlighting their importance as a transformative technology with world-changing potential. Semiconductors have already fundamentally reshaped human life, with one of their most significant contributions being their ability to deliver powerful computing at affordable prices, making IT services accessible to everyone. When we talk about AI’s potential to transform our world, we’re inherently assuming semiconductors as the essential foundation.
Ideally, semiconductors would allow everyone to access AI services affordably and integrate them into daily life as seamlessly as smartphones. However, a substantial gap exists between this ideal and our current reality. Artificial General Intelligence (AGI) refers to AI systems capable of learning, reasoning, and solving problems across diverse domains like humans. While today’s AI largely consists of “narrow AI” specialized for specific tasks like image recognition and language processing, AGI aims for human-level versatility and flexibility.
Even if AGI were successfully developed today, hardware costs and other practical limitations would significantly delay its widespread adoption. In this post, we’ll explore how LLM inference costs are rising in direct proportion AI performance improvements, and why semiconductor advancement is crucial to overcoming these challenges.
AI semiconductors challenges: The structural limitations of LLMs
To understand the costs of running LLM services, you need to grasp the model’s structure and computational characteristics. An LLM generates responses by taking an input and predicting the next word one by one through two major steps:
- Prefill: Understanding the input and organizing core content
- Decode: Generating one word at a time to complete the response
LLMs don’t process words directly but instead divide text into small units called “tokens.” For example, “artificial intelligence” might be processed as a single token or as two separate tokens: “artificial” and “intelligence.”
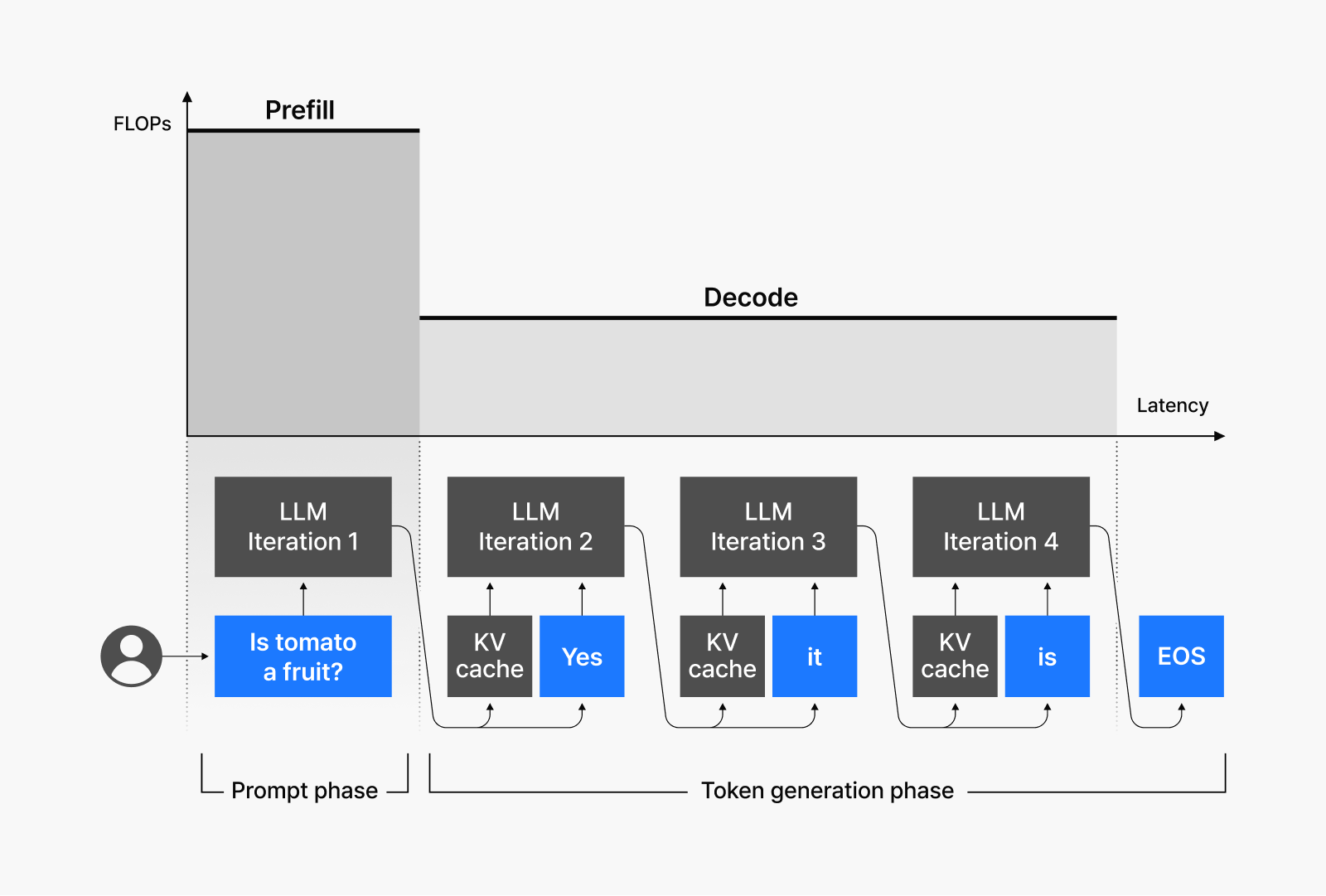
Most LLMs today use Google’s Transformer architecture, introduced in 2017, as their foundation. The scaling laws that OpenAI discovered in Transformer-based models—the model size, the dataset size, and the relationship between the amount of computing resources versus performance—have served as the theoretical foundation for developing LLMs like GPT-3. Subsequent LLM development has primarily centered on optimizing the Transformer’s decoder structure, which works by referencing all previously generated tokens to produce the next token sequentially. When generating responses using this chain approach, two significant bottlenecks emerge:
- Compute-bound bottleneck: Occurs primarily during prefill, where data has already been sent but is waiting for computations to complete due to processing volume. Because the system needs to process large amounts of data simultaneously, limited computing power leads to processing latency.
- Memory-bound bottleneck: Happens mostly during decoding, where the system must wait for data transfer after computations are complete. When generating responses one token at a time, the AI must continuously retrieve previous data. Delays in this data transfer slow down the entire process.
These constraints are inherent to LLM inference, which is why optimization requires understanding how these processes are intricately intertwined. Rising LLM service costs stem primarily from the memory-bound decoding process with its sequential token generation, which is why NAVER Cloud is focusing on optimizing this aspect. These compute- and memory-bound limitations directly impact both the scalability and costs of LLM services, with the memory-bound bottleneck during decoding being a major factor in token generation costs.
Since launching the world’s third LLM, NAVER Cloud has dedicated itself to training and developing AI services while working to resolve these LLM inference cost issues through various R&D initiatives. From an early stage, we’ve analyzed the cost structure of LLM operations and sought solutions to reduce expenses through efficient memory management and compute optimization.
NAVER Cloud’s AI semiconductor research
AI software: Driving semiconductor performance
While a semiconductor’s processing unit and memory represent its maximum theoretical performance, actual real-world performance depends heavily on the serving infrastructure and optimized AI software. At NAVER Cloud, we don’t just passively use existing software solutions—we actively pursue optimization strategies to maximize hardware performance. We’re collaborating with NVIDIA to enhance LLM training and inference, while regularly contributing our innovations to open-source communities.
Recently, the industry has shifted from supporting general-purpose computing to efficiently processing the specific computations needed for LLMs. NAVER Cloud is responding nimbly to this evolving market trend by accelerating our research in AI optimization technology specifically tailored for LLM training and inference, alongside advancing our software capabilities.
NAVER Cloud and Intel joint research center
AI software has evolved from being merely an execution tool to becoming the core enabling practical application of AI semiconductors in real-world services. However, newcomers to the AI semiconductor industry have yet to develop high-level software solutions capable of replacing existing offerings, resulting in an underdeveloped software ecosystem.
To address this challenge, NAVER Cloud has partnered with Intel to establish the NAVER Cloud-Intel Co-Lab. This collaboration aims to accelerate partnerships across industries, academia, and startups while expanding the AI software ecosystem based on the Intel Gaudi accelerator. Leveraging NAVER’s technological expertise, we are pursuing various initiatives to help universities and startups effectively utilize Intel’s hardware to implement cutting-edge AI technologies in real-world scenarios. Through this partnership, we aim to create a structural foundation supporting the mutual growth of both Intel’s AI software ecosystem and Korea’s AI R&D community.
Pioneering advanced model compression technologies
NAVER Cloud has moved beyond basic AI software optimization and is now enhancing overall performance by leveraging our deep understanding of both service environments and model structures.
We’re particularly focused on LLM compression techniques that account for hardware computational characteristics. Model compression reduces size and computation needs while preserving performance, through methods like quantization and pruning. Traditional GPU-based inference systems provide powerful computing capabilities and fast memory access, but they come with major drawbacks: high costs and excessive energy consumption. These systems rely on expensive technologies like high bandwidth memory (HBM) to solve memory bottlenecks, which drives up overall system costs significantly.
This is why NAVER Cloud is focusing on model compression techniques to increase cost efficiency. We’re also exploring the optimal balance between performance and speed to develop compression methods tailored specifically for LLMs. Our published research papers showcase these efforts and contribute valuable insights to the global AI community.
Developing AI semiconductor intellectual property solutions
At NAVER Cloud, we’re conducting extensive semiconductor intellectual property research focused on efficiently running lightweight LLMs. Our primary objective is to develop optimal IP solutions tailored for model compression that overcome the inherent limitations of GPU acceleration.
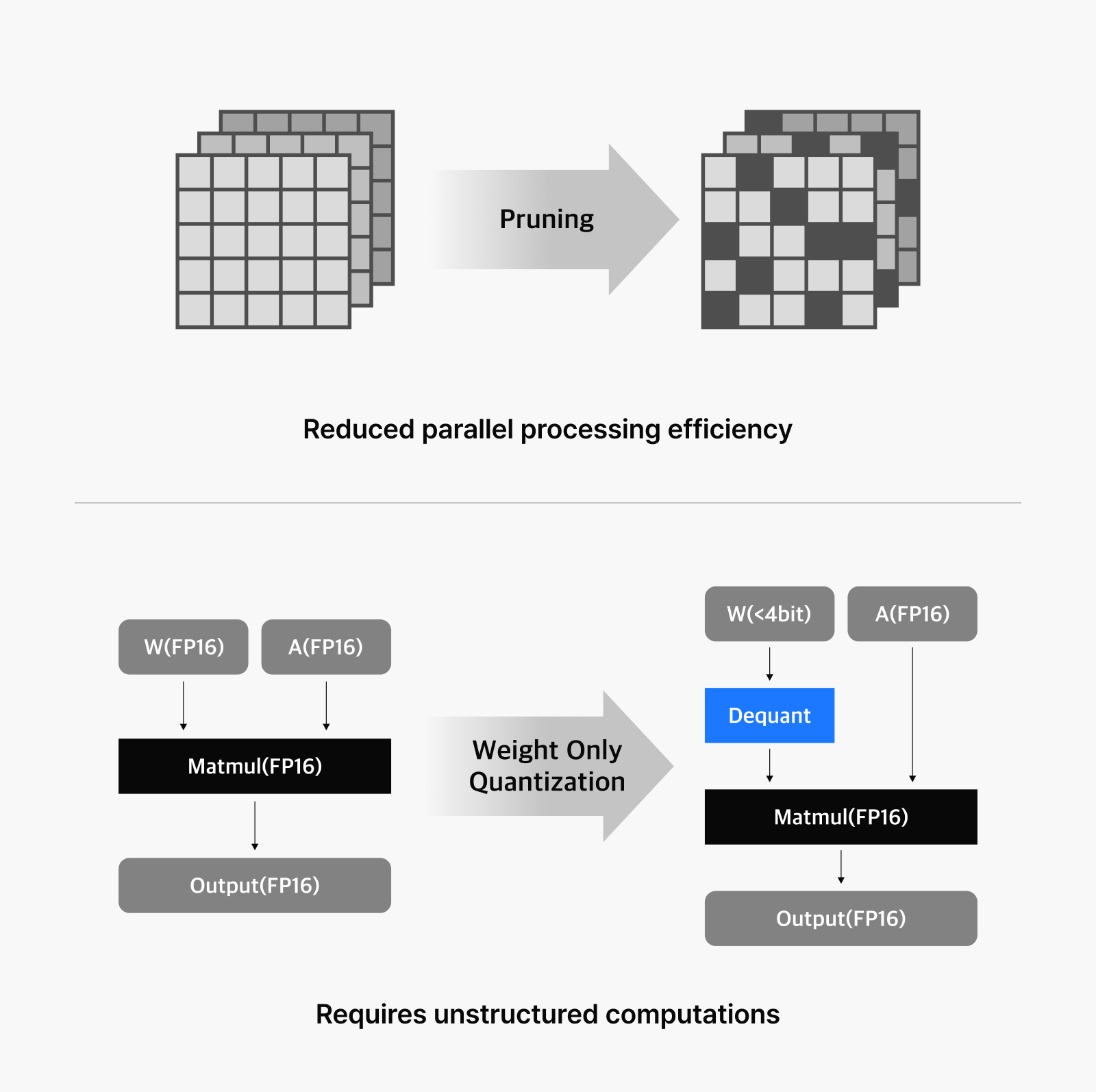
Requires unstructured computations
Quantization is a widely adopted technique for LLM compression, with weight-only quantization being the most common approach due to significant variations in input distributions across different model layers. However, this method requires dequantization for matrix multiplication (MatMul) operations, which introduces processing delays. Another compression technique—model pruning—removes components that minimally influence the model’s output, resulting in sparse matrices. This, in turn, can reduce the model’s computational efficiency on GPUs, which are optimized for parallel processing.
NAVER Cloud is pioneering new technologies that accelerate the computation of lightweight AI models without compromising LLM performance. Our research has yielded significant results, including the development of optimized kernels and semiconductor architectures that we’ve published in academic papers. These accomplishments demonstrate NAVER Cloud’s technological leadership in the AI semiconductor field.
NAVER Cloud’s vision for AI semiconductor innovation
Realizing affordable AI computing
NAVER Cloud is responding to the exponential growth in demand for AI services by carefully analyzing how to efficiently generate LLM tokens at scale, determining optimal GPU requirements, and calculating the necessary energy consumption and data center space to support these operations.
With nearly three decades of experience processing the highest service traffic volumes and operating diverse services throughout Korea, NAVER understands that establishing an affordable cost structure is fundamental to expanding the reach of high-quality AI services.
Strengthening collaboration with hardware providers
NAVER Cloud continuously researches and identifies the optimal AI semiconductor technologies needed to achieve our mission of reducing LLM inference costs. We firmly believe that model compression techniques coupled with corresponding hardware optimization represent essential technologies that can significantly lower LLM inference costs. To realize this vision, we’re actively collaborating with various hardware companies.
NAVER Cloud takes center stage in the AI era
Significantly reducing AI computing costs will catalyze the development of higher-quality services and models, accelerating our journey toward a world enhanced by artificial intelligence. NAVER Cloud is making sustained investments in technologies that make AI computing more affordable—a strategy we believe will make AI services accessible to more people across more regions globally. Through our pioneering research in AI semiconductor technology, NAVER Cloud is positioning itself at the center of the future AI landscape.