
Large language models (LLMs) are the recent buzz in the tech industry. From natural conversations and long text summaries to code and image generation, the capabilities we observe are truly remarkable. But have you ever wondered about the mechanisms behind the scenes—how these systems power real services in real time?
Between the moment you hit “send” on a prompt and when the first word appears on your screen, an intricate system known as LLM serving is hard at work. In this post, we’ll unpack how serving architectures work: how data flows through them and how they’re configured. We’ll also explore the key trade-offs between latency, cost, and reliability that shape these systems.
Whether you’re new to LLM serving or already working with these models and want to understand what really matters when deploying them in production, this post offers practical insights into how these systems work.
LLMs: Models that understand language
Before we dive into serving architecture, let’s briefly cover what LLMs are. Large language models are neural networks trained on vast amounts of text to statistically understand context, dependencies, and the logical flow of language. Think of them as assistants who’ve read millions of documents and internalized the patterns of how language works.
When you ask a question, the model predicts the most likely next word based on everything that came before—stringing these predictions together to form coherent sentences. Crucially, it’s learning patterns, not memorizing text. This is what allows LLMs to summarize, translate, answer questions, and even reason in ways that feel almost human.
Tokens: The building blocks of language
LLMs don’t process language the way we do. Instead of understanding a sentence as a whole, they break it down into small units called tokens. For example, the Korean sentence “나는 오늘 학교에 간다” (“I go to school today”) gets segmented into tokens like this:

Each token then maps to an integer ID from the model’s predefined vocabulary, creating a numerical representation:

Here’s the key thing: words and tokens don’t always match one-to-one. A phrase like “artificial intelligence” splits into two tokens (“artificial”, “intelligence”), while a single word like “serving” might break into subwords (“serv”, “ing”). Frequently used expressions, on the other hand, can be stored as a single token.
Tokenization isn’t limited to text either. Audio and images can also be tokenized—converted into numerical sequences that the model processes using similar principles.
When you submit a question, the model first tokenizes your input, converting sentences into sequences of number tokens. It then calculates the probability of each possible next token to generate a response. In essence, LLMs perceive the world through tokens, using these sequences to capture relationships across long spans of text with striking accuracy.
How do we talk to LLMs?
How do we actually interact with these models? The process boils down to four steps:
- Prompt input
You provide a question, instruction, or context in text form. This input defines the model’s task. - Tokenization
The model converts your input into a sequence of tokens. Each token maps to an integer ID in the model’s vocabulary, creating the numerical foundation for computation. - Inference
The model processes these tokens and calculates the probability of each possible next token. It selects the most likely one, adds it to the context, and repeats—building a coherent response token by token. - Detokenization
The generated token sequence converts back into readable text that appears on your screen.
This all happens in a fraction of a second, creating the illusion of real-time conversation. But actually, the mathematical operations involved in processing your input are fundamentally different from those used to generate the response.
In the next section, we’ll dive into these two phases of inference and explore how they affect performance and latency.
Prefill and decode: The two phases of LLM inference
LLM inference happens in two distinct phases: prefill and decode. Understanding this distinction is key to optimizing performance.
1) Prefill: Processing the input all at once
Take a prompt like “What’s the capital city of Korea?”—six tokens. During prefill, the model processes all six tokens simultaneously. This phase leverages massive parallelism, letting GPU cores work efficiently across large batches of data. As a result, prefill typically completes quickly, even for long prompts.
This is where the model interprets the overall structure and intent of your input in one pass.
2) Decode: Generating the response token by token
After prefill comes decode, where the model generates the response one token at a time. For our example, when outputting “It’s Seoul,” the model first produces “It’s,” then predicts “Seoul” by feeding the existing output back into itself as new input. This process is inherently sequential—the model must finish computing token (n–1) before it can generate token n.
This is where bottlenecks emerge. Each time a new token is generated, the GPU’s high-bandwidth memory (HBM) must access the model’s large parameters and key-value (KV) cache, which stores intermediate attention results: the keys (K) and values (V) representing the conversation context. Because this memory access cost accumulates with every token generated, decode becomes the primary bottleneck determining overall inference speed.
Why are GPUs the heart of LLMs?
LLM inference—essentially next-word prediction—relies on performing massive numbers of arithmetic operations. To understand why GPUs are critical to this process, let’s start with neurons, the basic building blocks of a neural network.
A neuron takes multiple inputs (x), multiplies each by its weight (w), sums the results, adds a bias term (b), and applies an activation function (f) to produce an output.
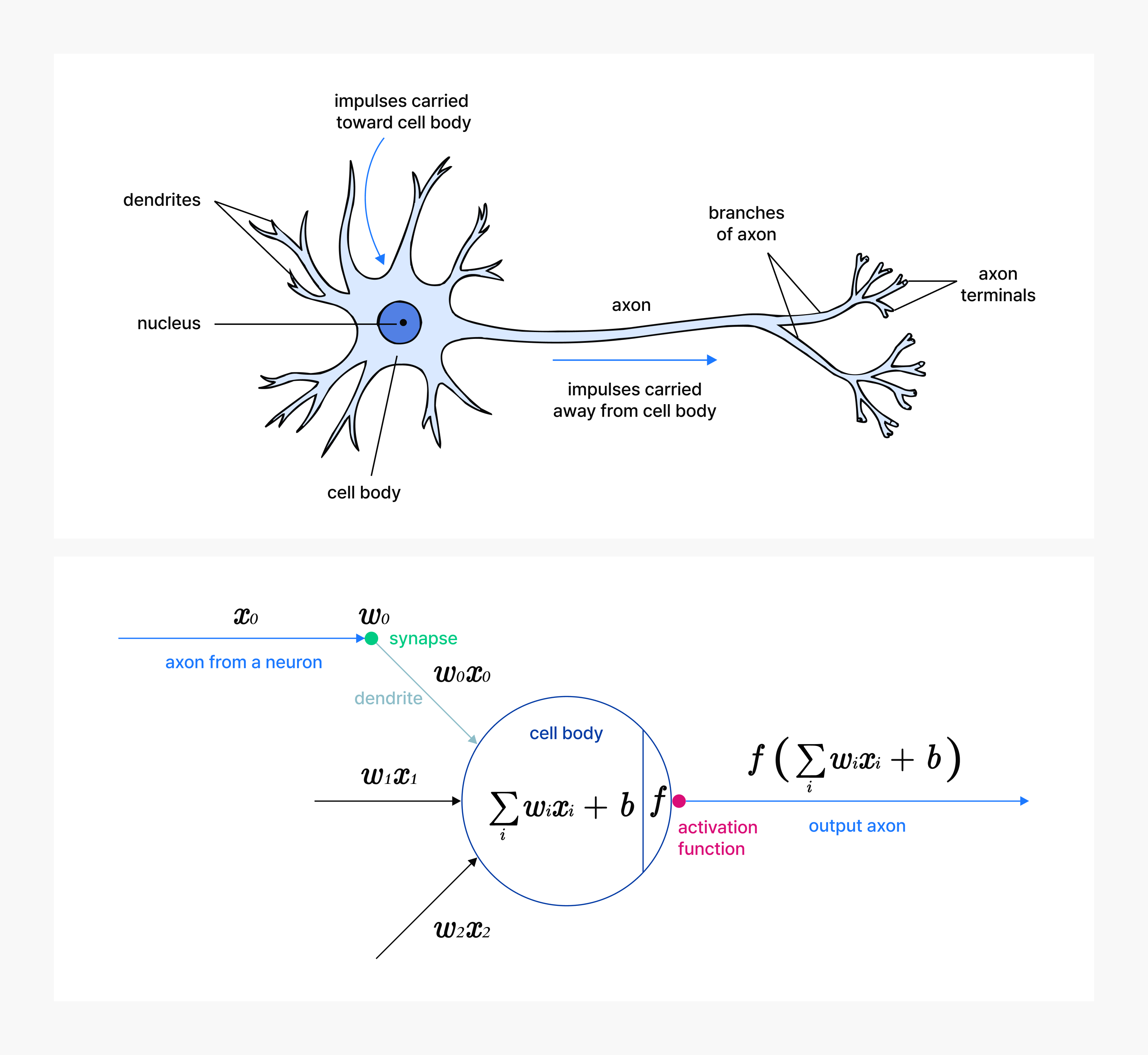
[Figure 1: A cartoon drawing of a biological neuron (up) and its mathematical model (down)]
Source: CS231n: Deep Learning for Computer Vision
An LLM is built by stacking thousands of these neuron layers. The output of one layer becomes the input to the next, repeating in depth. The key point is that the entire computation can be expressed as large matrix multiplications. A matrix is simply a grid of numbers arranged in rows and columns, and the many multiplications and additions happening in a single layer can be condensed into one operation—multiplying two large matrices.
When we talk about an LLM’s parameter count, we’re referring to the total number of elements in these weight matrices. A 7 billion (7B) parameter model contains 7 billion numbers in its weight matrices, and inference is the process of repeatedly multiplying these massive matrices layer by layer. In other words, the speed and computational complexity of an LLM depend on how large the matrices are, how often they’re multiplied, and how quickly those multiplications can be performed.
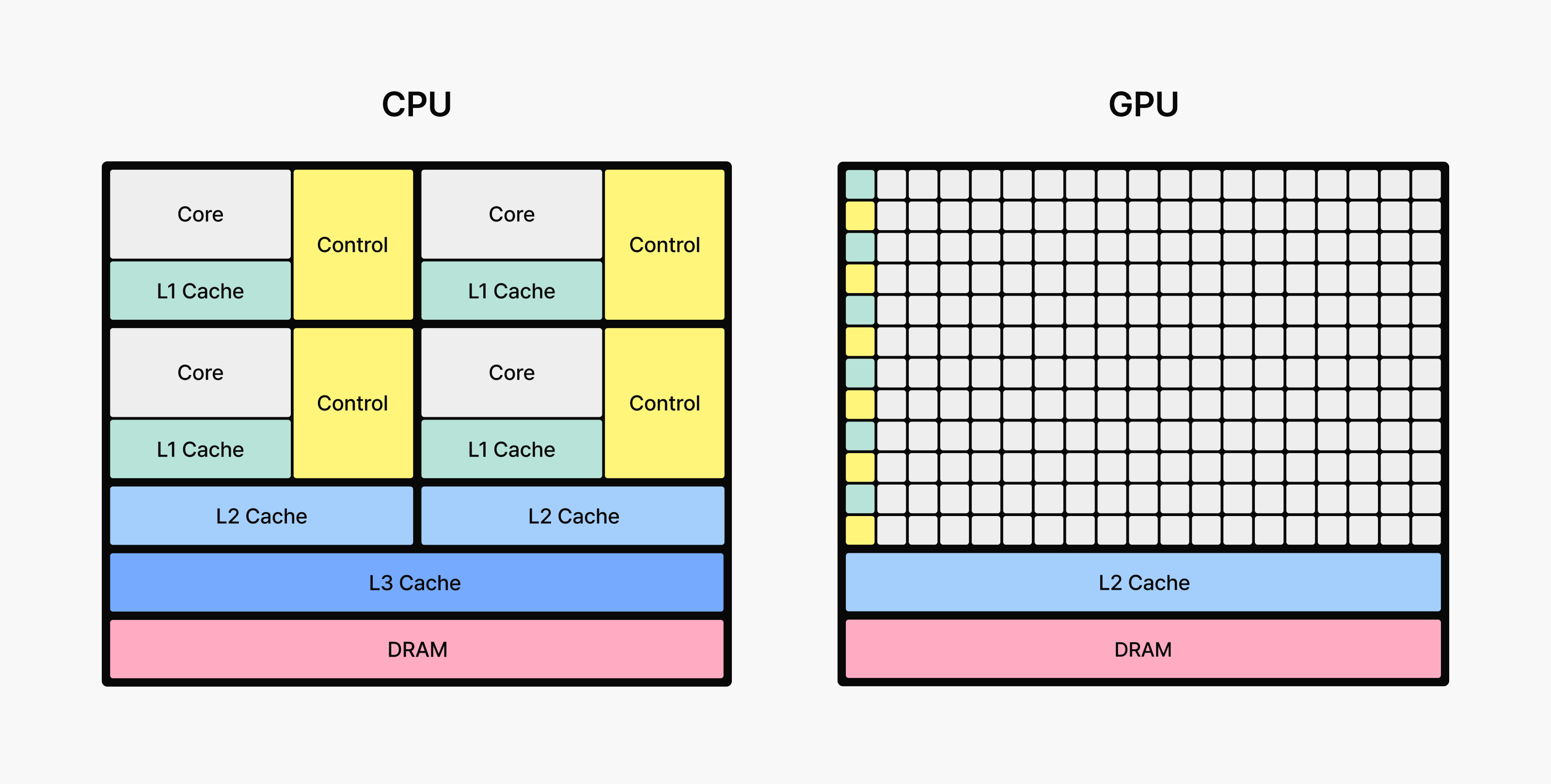 [Figure 2: The GPU Devotes More Transistors to Data Processing]
[Figure 2: The GPU Devotes More Transistors to Data Processing]
Source: NVIDIA CUDA C++ Programming Guide
A Graphics Processing Unit (GPU) is hardware specialized for performing these simple but repetitive calculations on a massive scale simultaneously. Originally designed for 3D graphics rendering, GPUs excel at large matrix operations thanks to their thousands of computing cores that can execute identical calculations in parallel. For models that continuously multiply and add massive weight matrices, GPUs are indispensable.
Think of it this way: if a CPU is a small team of experts handling various tasks sequentially, a GPU is a massive workforce performing simple calculations simultaneously. Because the bottleneck in LLM inference is matrix multiplication, GPUs—with their ability to parallelize across thousands of cores—determine speed and throughput.
Recent advances take this even further. Modern AI accelerators now include dedicated circuits specifically for matrix operations. The systolic array architecture, in particular, has gained traction—it’s a specialized pipeline that systematically streams data through while continuously performing multiplications and additions. Google’s TPU Matrix Units and NVIDIA Tensor Cores use these dedicated architectures to deliver significantly higher matrix processing efficiency than general-purpose GPU cores. This means more operations within the same power budget and physical space, dramatically reducing LLM inference latency and cost.
Conclusion
In this first part of Inside LLM serving, we’ve explored how LLMs work, what tokens are, and why GPUs are essential to making it all possible. In the second part of this series, we’ll introduce two critical metrics for serving performance—latency and throughput—and dive into how LLMs actually process user requests under the hood. Stay tuned!