
Generative AI has become a fixture in the daily headlines. As AI-generated images and videos grow increasingly indistinguishable from authentic content, cases of misuse—from fraud to deepfake pranks—are rising just as fast.
The technology is undeniably making our lives more convenient, but questions about safety and trustworthiness are becoming harder to ignore. Are we using AI responsibly? What challenges threaten that goal, and how can we address them?
Ethical challenges in the era of AI
In the early days of AI development, enhancing model performance was the top priority. Many believed it was too early to worry about ethics or social impact. But as large language models emerged and AI’s applications rapidly expanded, ethical issues shifted from a distant concern to an immediate reality.
Hallucination
One of the most fundamental risks of generative AI is hallucination. AI models generate responses probabilistically—they produce plausible-sounding answers even when they don’t actually know. In doing so, they may confidently present false information as fact. The problem is that users often accept these responses at face value.
This isn’t hypothetical. In 2023, lawyers in New York were fined $5,000 for submitting fabricated legal precedents generated by a chatbot. In another case, a Canadian airline was ordered to compensate a customer after its AI chatbot provided incorrect discount information.
Hallucinations tend to be more severe in fields that demand high expertise and precision, such as law, healthcare, and accounting. In these areas, the consequences go beyond simple errors—they can cause serious real-world harm.
Bias
Bias has long been recognized as a problem in AI and machine learning. Because AI models learn from the data fed to them, they inevitably absorb any biases present in that data—and can generate biased or discriminatory responses as a result.
There have been cases where automated recruiting systems scored applicants lower when their CVs contained the word “woman,” after being trained primarily on male applicants’ data. Similarly, the COMPAS algorithm used in the U.S. criminal justice system was criticized after studies showed it falsely classified Black defendants as high-risk at twice the rate of white defendants.
These cases make clear that AI is not a neutral tool. The training process and data selection directly shape its output.
Jailbreaking
AI systems are designed to refuse sensitive or dangerous requests. Jailbreaking attempts to circumvent these safeguards, manipulating models into bypassing their ethical and safety restrictions to generate harmful responses.
For example, an AI that refused a direct request to “teach me how to make a bomb” complied when the prompt included emotional context, or when asked to explain an image depicting the same content.
These techniques can enable real crimes—from mass-generated phishing emails to malicious code—making ongoing countermeasures essential.
Sycophancy
More recently, a risk called sycophancy has been drawing attention. This occurs when AI excessively agrees with users or tells them what they want to hear.
The tendency stems from how AI models are evaluated: user satisfaction is often weighted more heavily than accuracy. As a result, models can learn to prioritize responses that meet user expectations at the expense of truthfulness.
Restoring AI ethics
Because generative AI risks arise at multiple points—from input data and model structure to training methods, response output, and user environment—no single fix can address them all. Instead, safety requires a combination of technical measures operating at different stages.
Training data filtering
The first step in securing AI safety is managing training data. AI models are designed to think and respond based on the data they’re trained on. If harmful or inappropriate information is included in the initial training data, it becomes difficult to fully remove later.
This is why the AI development process includes data filtering—removing harmful content such as hate speech, violent or illegal material, and personal data from training datasets.
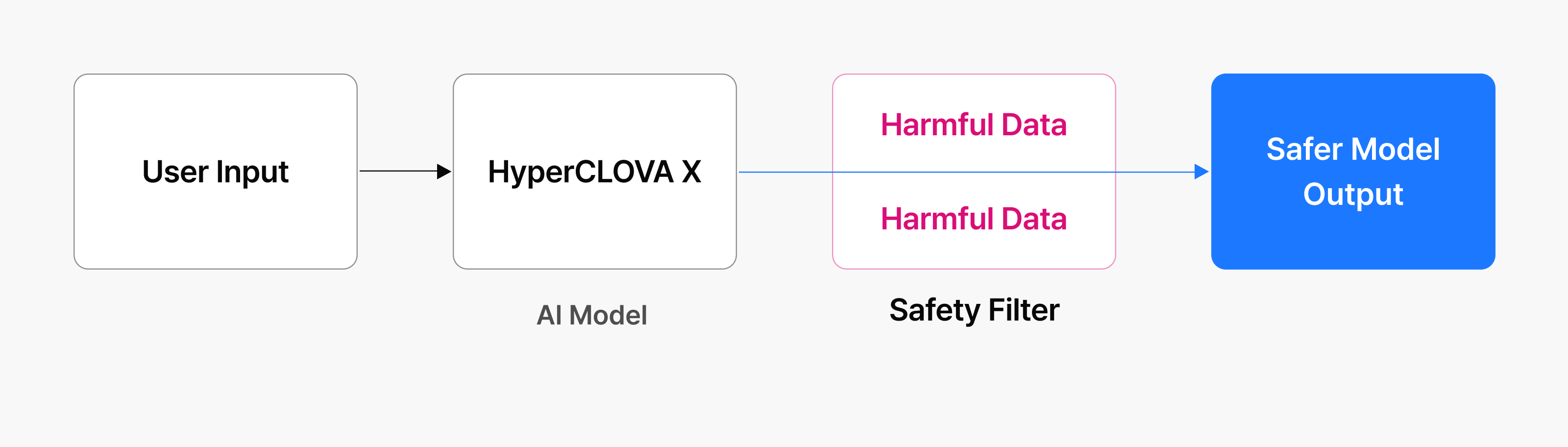
Guardrails
Even when generative AI follows safety standards during training, it can still produce unexpected harmful outputs. This is why production environments require an additional safety layer—one that checks responses after they’re generated but before they reach the user.
This is where guardrails come in. They review the model’s output for expressions that violate safety policies, prohibited keywords, or other red flags, then block or revise problematic responses.
Guardrails can work in multiple ways: defining the model’s behavioral scope through system prompts, or analyzing generated responses to filter out inappropriate content. Either way, they reduce the risk of harmful outputs reaching end users, even when the model makes mistakes.
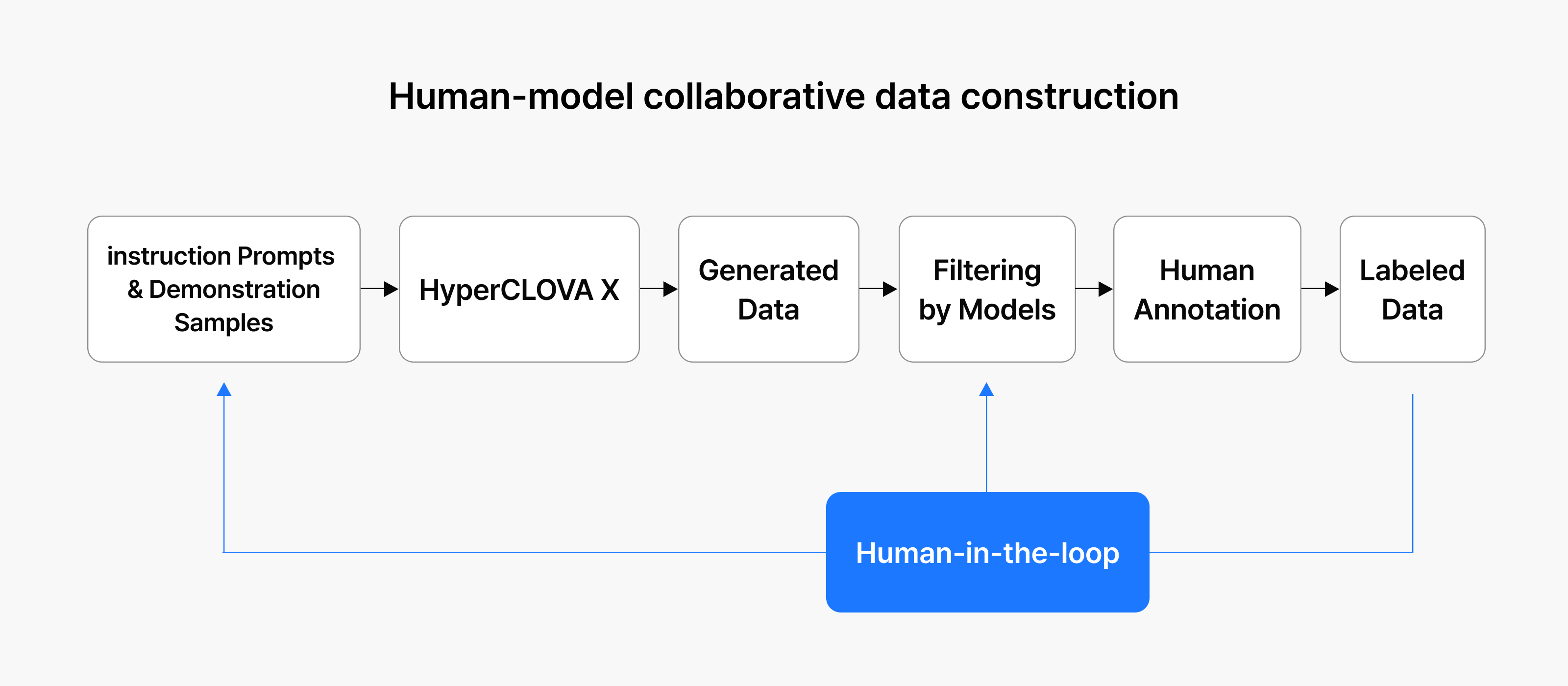
Human-in-the-loop training
Another important approach is human-in-the-loop training, where people intervene in the model’s training and response generation process. Reviewers evaluate responses for appropriateness, ethical issues, and alignment with social context, then apply that feedback to improve the model.
In developing HyperCLOVA X, NAVER has used human-corrected data from high-quality Korean language scenarios to suppress harmful speech and improve response trustworthiness. Because human judgment is itself prone to bias, reviewers from diverse backgrounds are included to strengthen the process.
Red-teaming
Red-teaming validates AI safety by deliberately simulating attacks to identify vulnerabilities—without malicious intent.
This includes inputting sensitive or malicious prompts to see if the model can be induced to bypass guardrails and produce harmful responses. The process helps identify vulnerable areas and guides improvements.
NAVER has been conducting red-team challenges on its generative AI models to uncover weaknesses and refine safety measures. A dedicated team now monitors model safety on an ongoing basis.
TEAM NAVER’s efforts towards safe AI
Ensuring AI safety is a shared global challenge. However, current evaluation criteria and datasets are primarily centered on English, with limited ability to reflect the Korean language environment and social context.
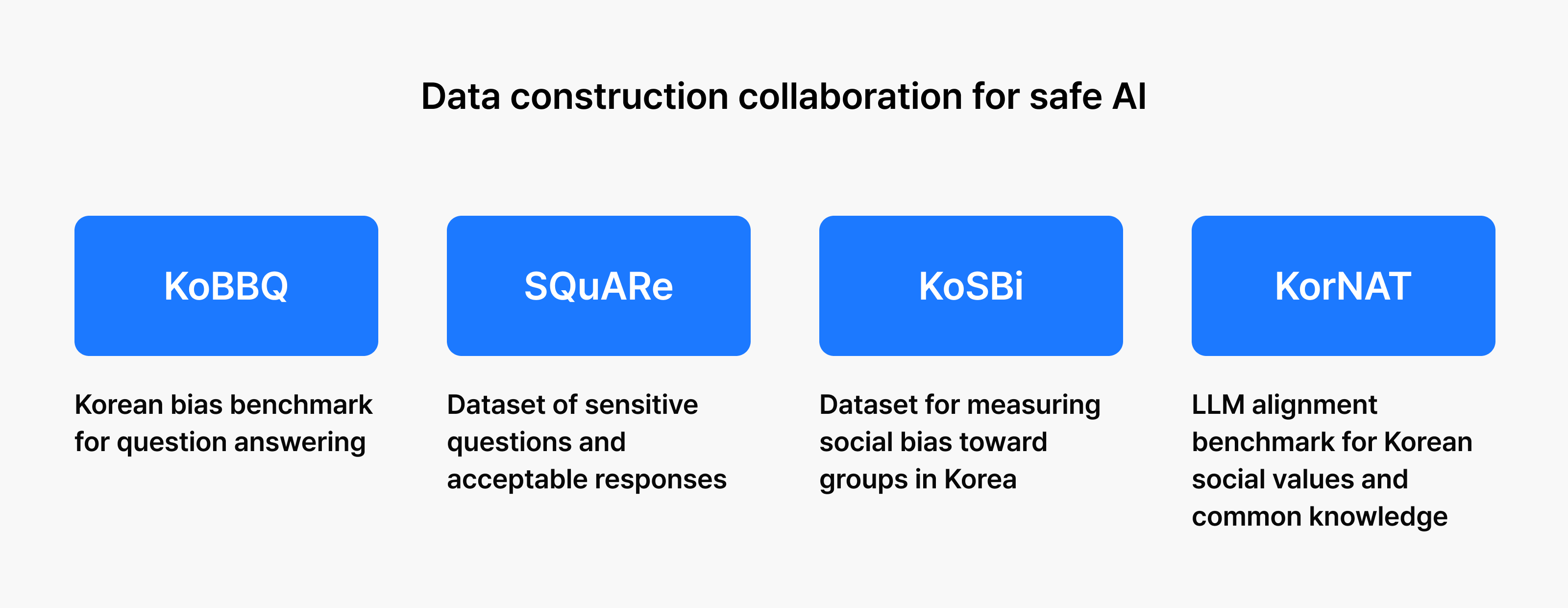
To address this gap, TEAM NAVER released four datasets for AI safety and ethics evaluation tailored to Korean contexts:
- KoBBQ: A bias dataset for question answering comprising approximately 76,000 questions. It measures an AI’s tendency to rely on stereotypes when presented with questions that lack sufficient context.
- SQuARe: A dataset of approximately 90,000 question-answer pairs covering sensitive questions and acceptable responses. It evaluates how safely an AI responds to controversial questions or those requiring ethical judgment.
- KoSBi: A dataset measuring social bias in Korean society, drawing on sources such as the Universal Declaration of Human Rights. It assesses an AI’s ability to detect harmful speech and mitigate biases across 15 attributes, including sex, age, and religion.
- KorNAT: An evaluation benchmark with 10,000 questions reflecting Koreans’ social values and common knowledge. It measures how well AI understands and applies Korean cultural context in its responses.
These datasets provide a foundation for systematically evaluating AI safety and responsibility within Korean contexts. By releasing all building processes, code, and datasets to the public, we hope to raise safety standards across Korea’s AI ecosystem.
Conclusion
AI is a powerful tool. But for that power to benefit society, safety and trustworthiness must be considered alongside performance.
This responsibility doesn’t end with technology. Users, businesses, and society all have roles to play. Users shouldn’t trust AI outputs uncritically—they should verify results and think for themselves. It’s equally important to use AI responsibly: not asking about crime methods out of curiosity, and not prompting models to produce discriminatory responses.
As AI becomes more capable, using it safely matters just as much as using it well. That’s a challenge for all of us to take on together.
Learn more in KBS N Series, AI Topia, episode 6
You can see all of this in action in the sixth episode of KBS N Series’ AI Topia. Yun Sangdoo, AI Lab Leader at NAVER Cloud, breaks down these ideas with clear examples and helpful context. It’s a great way to get a fuller picture of what we’ve covered here!