
Upending everything we thought we knew about AI
When we think about AI, most of us picture a text-based model like ChatGPT—one that answers our questions through written language. But humans don’t learn about the world through text alone. From the moment we’re born, we see, hear, touch, and feel our surroundings. Babies hear their mothers’ voices, touch their toys, and take in colors and sounds all at once to make sense of the world.
AI is now taking the same journey. Omnimodal AI processes images, sounds, videos, and even physical environments simultaneously, not just text. Just as we rely on multiple senses to understand the world, omnimodal AI learns through multiple modes from the very beginning, evolving into an intelligence that can truly interact with its environment.
From multimodal to omnimodal
Let’s trace AI’s evolution step by step.
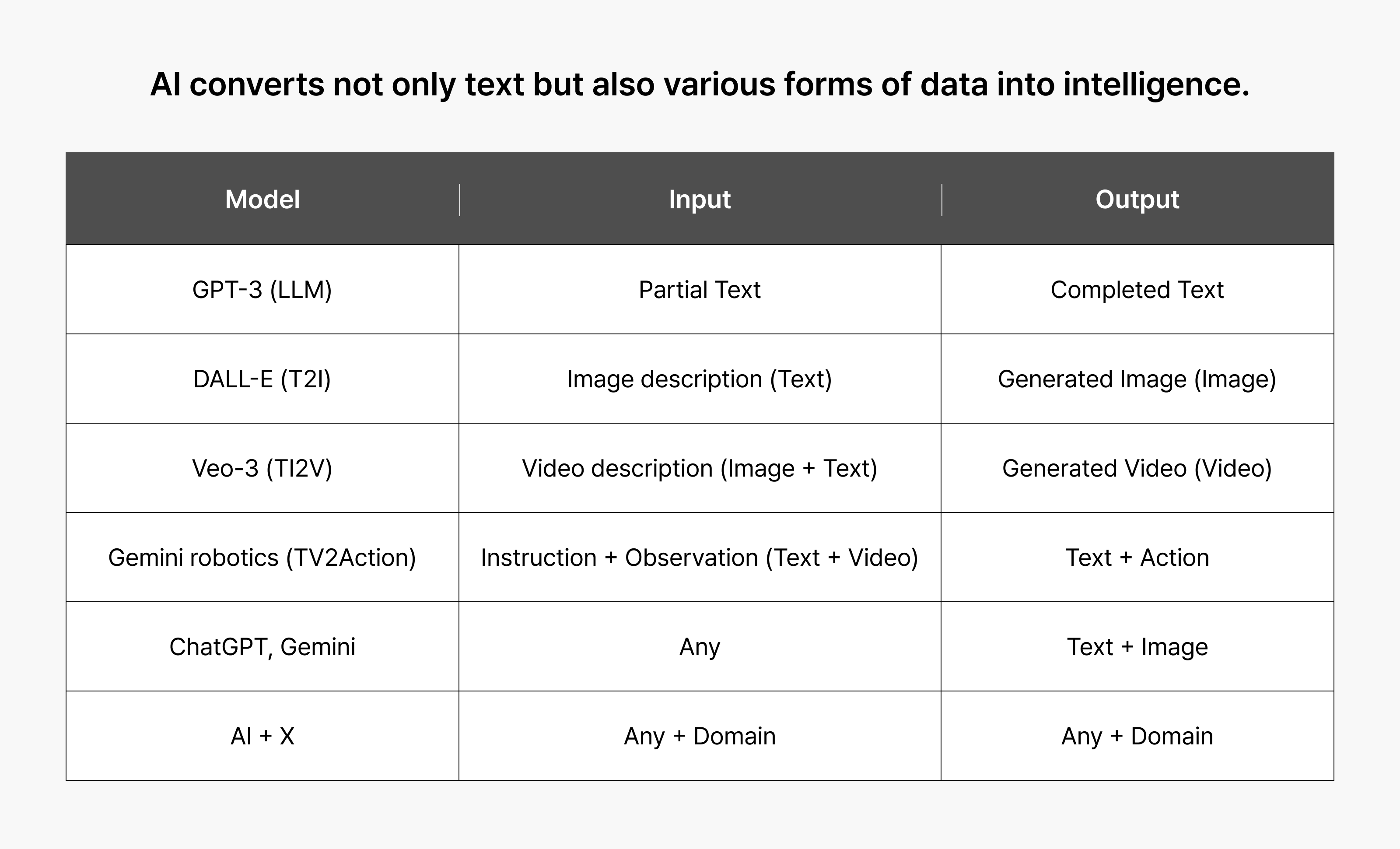
Step 1: Training on text (LLMs)
- Large language models (LLMs) are trained on vast amounts of text to compress the structural rules of language. They excel at summarization, translation, question answering, and other text-based tasks.
- Instead of words, these models use tokens as fundamental units. By predicting the next token in a sequence, they acquire deep linguistic knowledge and contextual awareness.
- This naturally leads to a new question: What if we could represent vision and audio information in the same way for training?
Step 2: Integrating multiple senses (multi-modality)
- Multimodal models add image and audio channels to a text model, expanding its capabilities. For example, they can generate images from text, or captions from images.
- However, because this is often a post-hoc fusion, the representational axes between different modules may not fully align. Misalignments can cause instability or hallucinations in understanding location, quantity, or relationships.
- Put simply, multimodal AI is like learning the world through words first, then adding pictures and sounds later.
Step 3: Learning all modes simultaneously (omni-modality)
- Omnimodal models learn from text, images, audio, and video simultaneously, aligning all sensory inputs within a shared coordinate system.
- In practice, this means that the word “apple,” its visual form, the sound of a bite, and the intention behind the scene are all interconnected. This deepens understanding of relationships and context.
- The key distinction lies between post-hoc fusion and simultaneous learning. The former struggles to manage misalignment between channels, while the latter trains from the same foundation—improving consistency, generalization, and robustness.
- From a user perspective, this means you can communicate with the AI however feels most natural—through text, images, or audio—and it will accurately understand your intent and respond reliably.
Omnimodal AI vs. multimodal AI
The key difference lies in learning later versus learning from the start.
Multimodal AI adds vision and audio modules on top of a trained language model. While this quickly expands capabilities, the representational axes between modalities may not align properly or the connections loosened. As a result, these models can misjudge space, location, or relationships within a scene. They might perceive objects incorrectly that are clear to human eyes or distort context.
Omnimodal AI trains text, image, and audio signals simultaneously within a single model, creating strong connections between words, scenes, and sounds, and allowing the model to capture nuanced relationships between data. The results speak for themselves: omnimodal AI maintains a more consistent understanding of the world. This reduces hallucinations and improves accuracy, even when instructions are partial (e.g., “… only the object on the right side of this image”). It brings us closer to an integrated intelligence we can rely on in real-world environments.
Why AI needs to learn all senses at once
When humans experience a scene, we process all senses simultaneously. We see the image, hear the sounds, and feel the atmosphere—all at once, creating a single, unified impression. This is why a scene from a fantasy novel you read as a child might feel strange when you see it adapted in a movie. You think that “the scenery’s different from what I’d imagined.”
When you build a world from text alone and later encounter visual and audio information, the two representations can conflict. The same principle applies to AI. When a model trains on visual, audio, and textual information simultaneously from the beginning, it avoids anchoring too heavily on any single modality and captures the nuanced relationships between different types of data more accurately.
- Training structure that reduces misunderstanding
As explained earlier, traditional multimodal models tend to add sensory capabilities to a trained language model, which can lead to hallucinations in tasks involving spatial reasoning and relationships. Omnimodal AI, by contrast, trains on various signals within a shared semantic space from the start, forming a more consistent understanding of the world.
- Intelligence suited for complex real-world scenarios
Consider manufacturing as an example. Effective predictive maintenance requires a model that can simultaneously hear subtle changes in equipment sound (audio) and identify problems with components (vision). In robotics, true intelligence requires understanding commands, planning actions, executing tasks, and validating results. A system that simply moves according to preset instructions is sophisticated automation; a system that understands language and adapts its plans based on changing situations functions as a genuine AI agent. Omnimodal models are structurally designed to meet this requirement.
- An interface for everyone
Not everyone works with complex documents. When AI can understand how we naturally communicate—through speech, images, gestures, or pointing at screens—it becomes far more accessible. The key is any-to-any capability: the ability to accept input in any format and produce output in whatever format you need, whether that’s text, image, audio, or something else. Omnimodal AI possesses this flexibility, enabling real-time collaboration where you can see results immediately and adjust on the fly.
To sum up, simultaneous training enhances accuracy by preventing misaligned conceptualization, improves robustness by processing complex signals as an integrated whole, and expands accessibility by letting more people interact with AI in natural ways. Omni-modality implements these three values directly into its architecture, with natural instruction and interaction at its core.
Instruction and interaction: When AI becomes our partner
In the past, AI was simply a tool that reacted to user inputs. Today’s AI, however, understands instructions, engages in genuine interaction, and acts flexibly to achieve goals.
- Understanding instructions with precision
Omnimodal AI accurately interprets partial instructions, enabling continuous updates and collaboration. It responds reliably even to referential commands like “Re-calculate only the third table from the last result.”
- Maintaining context for continuous tasks
The AI shows intermediate results, incorporates feedback, and adjusts its approach in real time.
- Varying response to different situations
Modern AI doesn’t just maintain a conversation—it analyzes what users say, formulates plans independently, and changes its behavior based on the situation. For example, a care-call AI checking in on seniors doesn’t stop at “Are you doing fine?” If a response seems unusual, it immediately adjusts its next question. If it detects danger signals, it alerts the relevant institution.
In other words, AI has evolved from “a simple automated system” to a capable partner that can converse, collaborate, and solve problems.
The rise of agents
Just as humans use all five senses to understand a scene, omnimodal models align different signals—text tokens, image pixels, audio waveforms—within a single shared representational space. Taking our earlier example, the word “apple,” its visual form and the sound of a bite are all interconnected, forming a consistent understanding of the world. The stronger this alignment, the more reliably the model can interpret relationships and contexts in entirely new situations.
Why have “agents” become important now?
As AI capabilities advanced through scaling laws, models moved beyond simple “observation” and “description” to genuine understanding, simulation, and planning. Agent capabilities—the ability to formulate plans independently and execute multi-step processes—are developing rapidly. Today’s models don’t just predict the next word; they understand users’ complex intentions and engage in goal-driven interactions that plan and carry out actual tasks.
Why is interaction capability key?
In real life, things rarely go exactly as planned. Plans get disrupted by changes in user moods, shifts in target conditions, or unexpected external variables. True intelligence doesn’t mean robots that execute pre-defined processes; it means systems that interact in real time, correct errors immediately, and replan their approach as needed. Omnimodal AI continuously updates context throughout a conversation, adjusts its next actions by observing changes in its environment, and collaborates with other agents when necessary to achieve better outcomes.
In other words, omnimodal AI combines multiple sensory inputs into a unified understanding of the world, then plans and executes goals based on that understanding. Continuous interaction with users determines its ability to solve real problems. This is where AI transitions from being merely a tool to becoming a partner that works alongside you.
What’s next for NAVER
Our goal at NAVER is building an any-to-any omnimodal model that accepts any input—text, image, audio, or video—and outputs any format—documents, tables, images, audio, or UI interactions—by unifying vision understanding, audio understanding and generation, and vision generation into a single axis. We chose this approach for three reasons:
- Lowering the barrier to giving instructions: When models can understand the way people naturally communicate—through speech, gestures, or pointing—the usability barrier drops significantly.
- Reducing misunderstanding: Learning vision and sound from the beginning reduces the bias and hallucinations frequently found in text-only models.
- Creating a shared experience: Real collaboration means “seeing intermediate results and updating continuously.” The model must be able to generate and update output formats—documents, images, audio, and UI elements—on its own.
Beyond the model itself, our data strategy is equally crucial. To make any-to-any a reality, high-quality data must come first. To learn to perceive the world as humans do, AI must go beyond documents and images to include real-life data that hasn’t been sufficiently digitized yet—like first-person point-of-view (POV) recordings that capture how people actually experience the world.
Local data is also essential, since each country and region has distinct cultures, languages, and environments. We’re working to establish an ethics, safety, and governance system that responsibly handles personal data, biometrics, and location signals. We’re also building sovereign AI capabilities—designing, training, and deploying proprietary models tailored to local environments to reduce global dependency. Creating data grounded in the lives and spaces we inhabit is the most direct path to AI that truly understands our world.
We’re also developing real-time processing as a core capability. By designing a pipeline that reasons while listening and streams partial results, we’ve implemented streaming audio conversations that feel as natural as talking to another person. Our PodcastLM is one example of this approach. It creates panel discussion scripts through deep understanding of documents or news articles, then integrates neural network-based text-to-speech to auto-generate podcasts.
Conclusion
NAVER’s goals are clear: creating intelligence that can understand in real time, provide evidence-backed answers, and carry out tasks responsibly—grounded in Korean data and standards to establish trustworthy AI infrastructure. We’re building our strategy around any-to-any omnimodal capabilities, local data and governance, and sovereign AI to design next-generation user experiences and developer ecosystems that extend beyond Korea to the global stage.
Learn more in KBS N Series, AI Topia, episode 2
You can see all of this in action in the second episode of KBS N Series’ AI Topia, where Sung Nako, Executive VP of Hyperscale AI Technology at NAVER Cloud, breaks down these ideas with clear examples and helpful context. It’s a great way to get a fuller picture of what we’ve covered here!