The delicate art of AI responses
Every AI service faces unique requirements, even when handling seemingly identical tasks. Context and service policies often demand completely different approaches to the same query, and these nuanced distinctions can’t be managed through simple rules. The challenge only intensifies when trying to automate these complex interactions.
Consider a brand-specific AI assistant that must engage naturally in product inquiries. At the same time, it needs to elegantly sidestep competitor recommendations or tactfully deflect sensitive topics like pricing policies and matters without authorized public statements.
How can AI solve this problem?
When AI fails to navigate these subtle contexts, poor judgments inevitably follow, damaging both service quality and user experience. Effective automation requires a system that accurately reflects and applies service-specific policies and contexts to find the optimal path. This is where LLM-based routing technology offers a breakthrough.
Router: The essential solution for introducing AI
As AI transformation (AX) accelerates, organizations are facing a common challenge: how to effectively implement and manage these systems. Success hinges on designing precise data flows that address various requirements while keeping services reliable.
Router cuts through these complexities, making AI adoption easier and immediately applicable. It delivers high accuracy without the headache of model fine-tuning, streamlining automation and boosting efficiency.
1. Bring precision to AI Contact Center channeling
One of the main priorities for all AI Contact Centers is accurately classifying customer inquiries without sacrificing speed. Traditional Natural Language Understanding (NLU) systems have struggled with this balance, particularly when customers phrase their needs in unexpected ways.
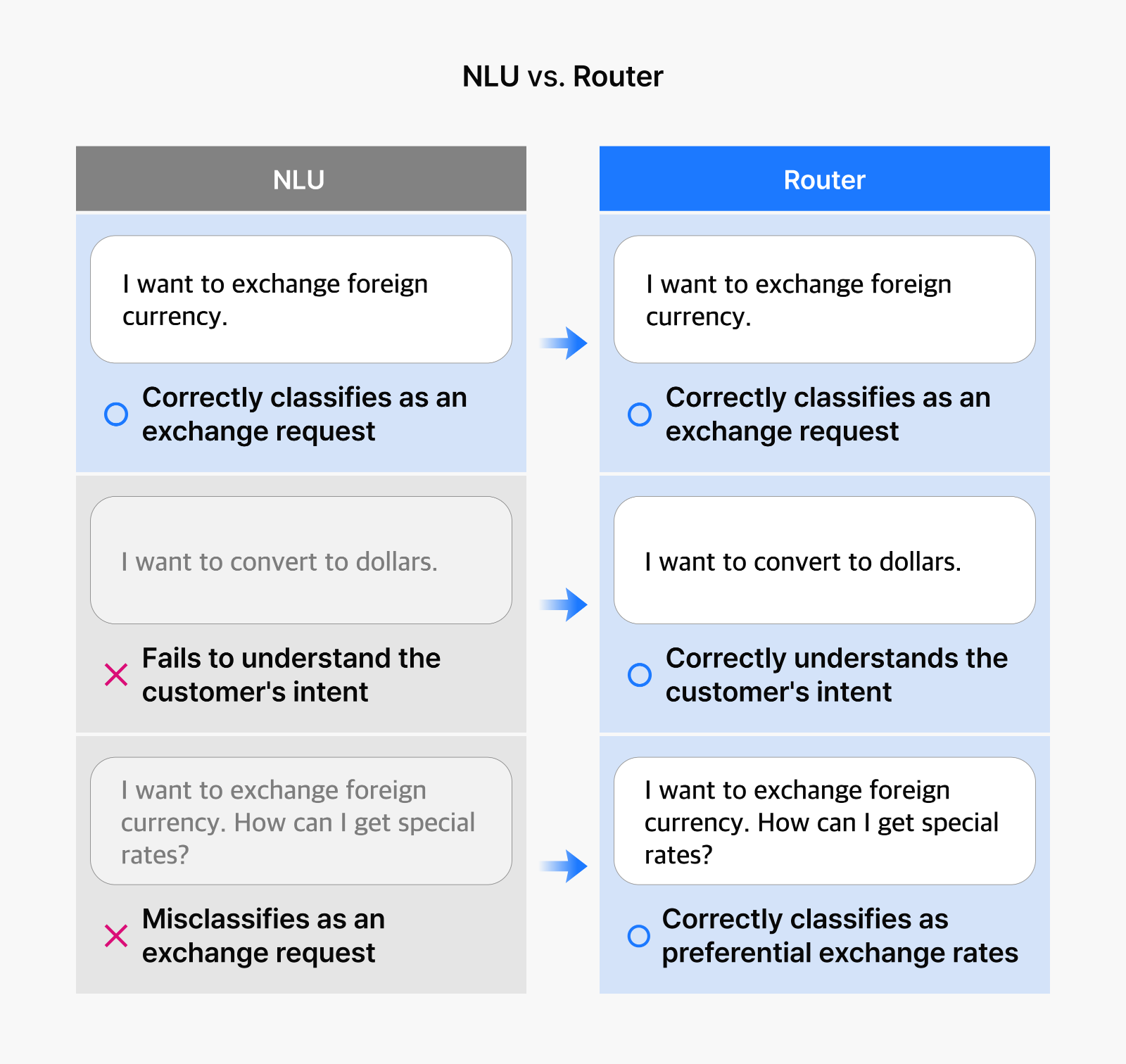
When someone says “I want to exchange foreign currency,” NLU handles this straightforward request just fine. But change it slightly to “I want to convert to dollars,” and these systems frequently miss the connection.
Or consider a more nuanced request like “I want to exchange foreign currency. How can I get special rates?” Though clearly about preferential exchange rates, older NLU systems tend to misclassify this as a simple exchange request.
Router doesn’t trip over these everyday language variations. It captures customer intent accurately, streamlining the consultation process and leaving customers satisfied.
2. Skip fine-tuning when classifying documents
Classifying lengthy documents with AI has previously required massive training datasets and continuous fine-tuning, which drive up maintenance costs. Traditional models also demand retraining whenever a new category is added. Router, however, takes a zero-shot approach to deliver precise classification without the burden of additional training.
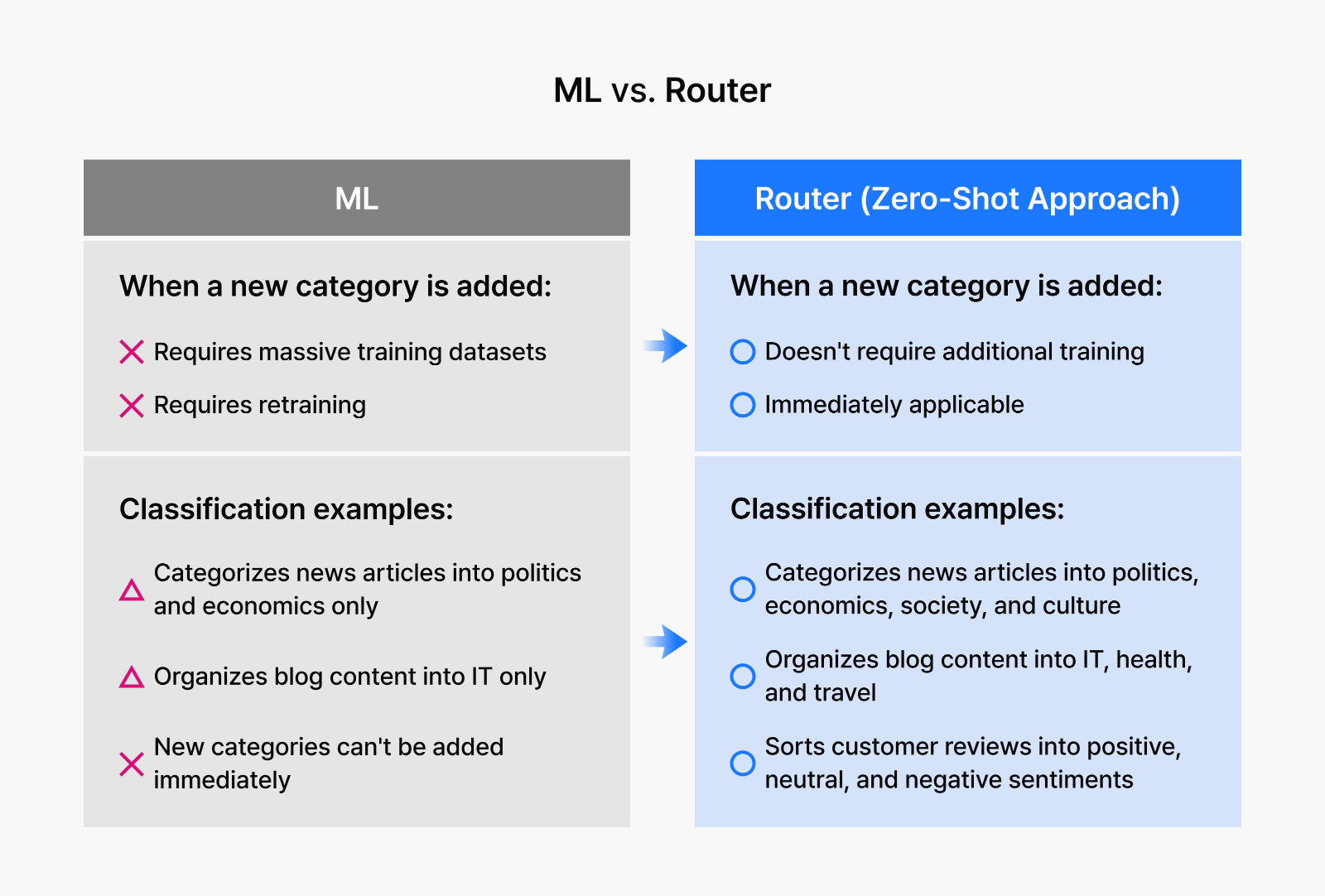
Router seamlessly categorizes news articles into domains such as politics, economics, society, and culture. It organizes blog content by topics including IT, health, and travel, while efficiently sorting customer reviews into positive, neutral, and negative sentiments. By automating these classification tasks, Router significantly reduces training costs while enabling more efficient and accurate content management.
3. Flexibly implement service-specific filtering
Traditional keyword-filtering systems simply matched words without understanding their context. Router takes a smarter approach by analyzing the entire conversation to enable more precise filtering. For instance, when your AI needs to avoid mentioning a specific brand, Router can distinguish between casual references and promotional content. You can also choose what topics should be filtered based on company policies or compliance standards. By adopting this sophisticated filtering, Router improves service reliability, automates policy compliance, and reduces manual oversight—all while maximizing effective content management.

4. Create a safety layer for generative AI services
Generative AI offers incredible capabilities, but it comes with inherent risks—sometimes producing inappropriate content. From hate speech and violent language to accidental personal data exposure, these issues not only violate service policies but can harm users directly.
Router acts as a “safety layer,” continuously reviewing and adjusting AI responses in real time. It goes beyond simple word filtering to evaluate content against your service’s specific policies and ethical standards. It also detects and blocks problematic responses before they reach users.
As AI adoption accelerates, ethical and safety concerns naturally grow. Router ensures your generative AI implementations remain reliable by preemptively blocking harmful content, moderating sensitive topics, and applying customized safety rules for each service.
LLM Router: Your intelligent service navigator
What does every efficient service need? The ability to accurately categorize information and make smart decisions quickly. Router is the core technology that delivers these essential capabilities.
For commerce services, product categorization is just the beginning. You need AI that can identify policy violations in product descriptions and automatically flag items that require additional review. Router handles these tasks seamlessly, giving operators the flexibility to adapt to changing business strategies and policies. The system conducts thorough analysis by systematically classifying data using concepts like domains and filters.
- Domain: primary categories for classifying data (e.g., skincare products, kitchen appliances)
- Filter: specific rules applied within each domain (e.g., missing potential allergens from product labels)
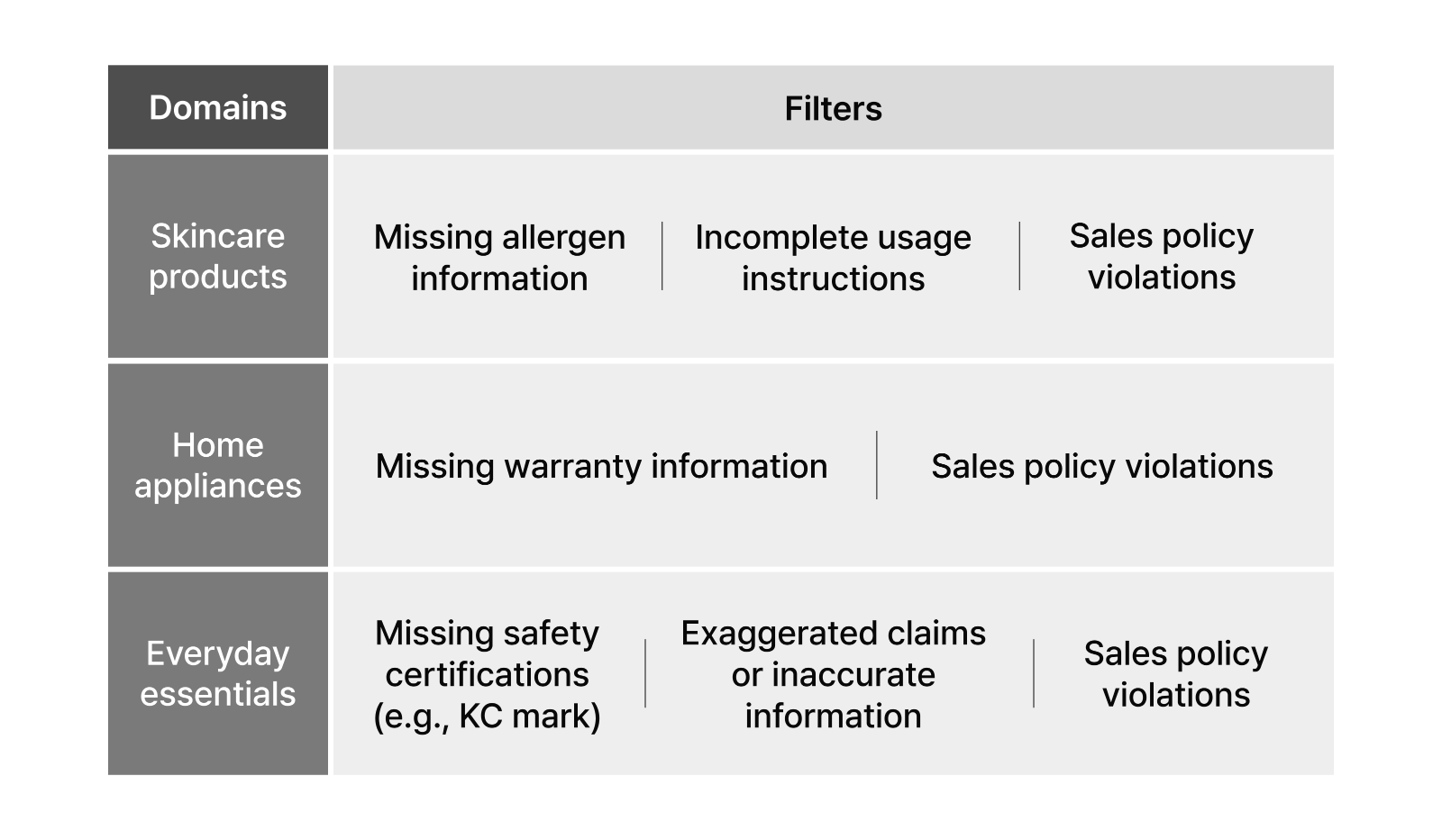
Users can define domains and filters using natural language descriptions. For example, writing “missing potential allergens from product labels” as a filter definition gives Router everything it needs to identify this issue in product listings. This approach moves beyond basic keyword matching—Router truly understands your service’s context and applies appropriate standards for each domain to deliver comprehensive analysis.
Real-world applications
| Application | Data | Router’s judgment | Result |
| Product listing system | [Product description] Our moisturizer contains ceramide and hyaluronic acid to keep your skin hydrated throughout the day. | ① Domain: skincare product ② Filter: all clear |
Listing approved |
| [Product description] This mixer cannot be returned after use. As an appliance, no refunds for defects discovered after the initial period. | ① Domain: home appliances ② Filter: sales policy violation detected |
Listing paused | |
| Customer support AI | [Customer message] My product arrived broken. How can I get a refund? | ① Domain: return request② Filter: all clear | Full response provided |
| [Customer message] Why does this product have so many one-star reviews? Is it really that bad? | ① Domain: product inquiry② Filter: negative tone detected | Limited response |
As the examples demonstrate, Router does far more than match keywords. It intelligently applies your specific rules for thorough content evaluation. Whether detecting inappropriate language, blocking malicious requests, or automating policy compliance, Router handles a wide spectrum of responsibilities. This versatility allows you to adapt quickly, even in rapidly changing environments.
What makes Router work so well: Smart data design
Router performs well across many scenarios with minimal setup—just provide service descriptions (or prompts) and you’re ready to go, no additional fine-tuning needed. This efficiency comes from its solid foundation: extensive training on diverse situations using the HyperCLOVA X model.
- Data augmentation: We mixed up prompt orders and rewrote them in different ways to build rich training datasets.
- Multi-turn dialogue integration: By training on complete conversations, Router develops a better understanding of context, allowing for more accurate predictions.
- Hard negative examples: We improved classification by including challenging cases that typically confuse models. These “hard negatives” appear to belong in one category (positive) but actually don’t (negative).
For instance, text containing product details but requesting translation might be misclassified as “product description.” Including these nuanced examples significantly improves Router’s ability to make proper distinctions.
Type Data Router’s judgment Hard negative [Product description] Our moisturizer contains ceramide and hyaluronic acid to keep your skin hydrated throughout the day.Could you translate this into Korean? Domain: not applicable Negative Tell me what the weather’s going to be like in Jeongja-dong tomorrow Domain: not applicable Positive [Product description] Our moisturizer contains ceramide and hyaluronic acid to keep your skin hydrated throughout the day. Domain: skincare product
- Chain-of-thought (CoT) reasoning: Router approaches classification in three clear steps: understanding the user’s actual intent, weighing possible interpretations, and making the best choice based on context and service requirements. Despite this sophisticated reasoning process, Router maintains its speed when delivering predictions thanks to its lightweight design.
Evaluating Router’s performance
To validate Router’s capabilities, we conducted rigorous testing using out-of-domain (OOD) data representing real-world service scenarios. Our evaluation framework included six distinct domains based on CLOVA X’s skills (NAVER Shopping, NAVER Travel, Socar, Wanted, Kurly, and Triple), using both single- and multi-turn conversations for comprehensive assessment. Importantly, these domains were absent from Router’s training, ensuring a genuine test of adaptability.
Testing results showed Router achieving performance comparable to the leading competitor’s model across domain classification and filtering tasks. Router also excelled in multi-turn conversations where contextual understanding is critical. Considering that the competitor’s model typically sets industry standards, HyperCLOVA X’s lightweight Router demonstrated remarkable cost efficiency by matching these results with lower resource consumption.
| Testing scenario | Model | Domain | Filter | End-to-end |
| Single-turn | Competitor O’s model | 0.99 / 0.01 | 0.96 / 0.04 | 0.89 / 0.04 |
| Router | 0.98 / 0.01 | 0.93 / 0.04 | 0.9 / 0.06 | |
| Multi-turn | Competitor O’s model | 0.99 / 0.04 | 0.84 / 0.03 | 0.95 / 0.1 |
| Router | 0.97 / 0.01 | 0.86 / 0.04 | 0.92 / 0.08 |
- Performance metrics (displayed as F1 score / FPR)
- F1 score: overall classification accuracy (closer to 1 indicates better performance)
- False positive rate (FPR): proportion of incorrect classifications (closer to 0 means fewer errors)
- Evaluation categories
- Domain: accuracy in identifying the primary category
- Filter: precision in applying specific rules within domains
- End-to-end: overall performance across the complete dataset
- Testing scenarios
- Single-turn: performance with standalone inputs
- Multi-turn: performance with awareness of previous conversation context
Router excels not only with conversations but also when classifying longer documents, demonstrating its adaptability across diverse service environments and high scalability.
Maximizing Router’s performance
Router’s greatest strength is adapting through natural language instructions without fine-tuning the model. For optimal results, focus on writing clear, specific descriptions when defining domains and filters. Precise, consistent descriptions maintain both accuracy and flexibility, while vague expressions can lead to unpredictable outcomes.
Setting clear domain boundaries
Each service requires distinct domains, and Router may struggle with subtle boundaries unless they’re properly defined. Unlike traditional ML-based classification models that struggle to maintain consistency when building datasets and training, Router works with a zero-shot approach—simply provide clear natural language descriptions without any additional training.
For example, these domains all relate to “health,” but serve distinct purposes. With clear definitions, Router classifies them accurately:
- Medical: addresses specialized clinical practices, including diagnoses, treatments, medications, and surgical procedures (e.g., “What treatments are available for a herniated disc?”)
- Fitness: covers physical strength improvements through exercise routines, stretching, strength training, and cardiovascular activities (e.g., “Can you recommend stretches that might help with my herniated disc?”)
- Nutrition: focuses on dietary intake and habits, including food choices and supplements (e.g., “Are there any supplements that might help with herniated disc recovery?”)
- Daily health: addresses lifestyle factors for wellbeing, focusing on preventive habits (e.g., “How should I sit and stand to avoid making my herniated disc problems worse?”
By clearly defining each domain’s purpose and scope, boundaries become distinct and adjustable. To add a new domain like “medical devices,” simply provide a description:
- Medical devices: covers supportive tools for injury management and rehabilitation, including braces and physical support equipment (e.g., “What kind of back brace would help while I’m recovering from a herniated disc?”)
Adding and managing domains are easy with just a well-crafted description. If classification errors occur, you can address them by adding examples without modifying the model itself.
Making clear distinctions between filters
As with domains, filters require clear boundaries to prevent classification errors. Filters for “unethical content” and “contentious topics,” for instance, often share conceptual overlap. When presented with a statement like “This politician is corrupt,” Router may struggle to determine the appropriate filter without precise definitions.
- Unethical: detects ethically problematic content
- Contentious: detects socially controversial content
These definitions lack specificity. For improved classification, define each filter’s scope precisely:
- Unethical: identifies defamation, promotion of illegal activities, violent content, discrimination, and other explicitly unacceptable expressions
- Contentious: identifies biased or aggressive content related to politics, religion, and policies
Even with well-defined initial standards, implementation will inevitably reveal edge cases. Router’s flexibility is particularly valuable in these situations—you can simply update natural language descriptions without complex retraining processes.
Because Router responds directly to your descriptions without requiring model fine-tuning, its performance directly reflects the clarity and systematic nature of these descriptions. With thoughtfully defined standards for both domains and filters, you can develop a robust classification system that adapts efficiently through continuous updates.
Conclusion
We’re excited to introduce Router through CLOVA Studio. Soon, organizations will be able to customize Router for their specific needs across diverse service environments.
We’re living in an era where AI delivers tangible business value. In today’s rapidly evolving landscape, Router will play an essential role helping organizations intelligently classify and process information.