
We live in a world of constant motion, where our human vision intuitively captures and processes each dynamic moment in real time. Video isn’t merely a sequence of static images—it’s the flowing narrative of reality unfolding through time. HyperCLOVA X has set its sights on understanding this dynamic world.
HyperCLOVA X Video ventures beyond still images to capture the complex interactions and transformations occurring across the dimensions of time and space. What once seemed like science fiction is becoming reality: machines capable of analyzing and comprehending events as they unfold over time. To realize this vision, NAVER has integrated diverse video datasets with cutting-edge AI technologies, opening new horizons of possibility.
Many readers expressed enthusiasm for our previous article, “Introducing HyperCLOVA X Vision.” We’re excited to build on that foundation as we explore how HyperCLOVA X Video interprets continuous, evolving scenes.
To learn more about our vision technologies, read our previous post Introducing HyperCLOVA X Vision.
Introducing HyperCLOVA X Video
HyperCLOVA X Video elevates traditional vision-language models (VLMs) with its specialized ability to comprehend video’s dynamic nature. Trained on diverse video scenarios, it has developed advanced capabilities for analyzing complex narratives and tracking subject-object interactions across multiple frames. This technology transcends basic scene recognition, enabling the construction of architectures that effectively capture scene transitions, movement patterns, and contextual shifts while maintaining computational efficiency.
Building on years of image processing expertise, NAVER has enhanced HyperCLOVA X Video with the capability to integrate multimodal information streams from videos into cohesive, unified data representations. By synthesizing visual elements throughout video content, the system achieves impressive accuracy in video comprehension. The model demonstrates particular strength in processing Korean-language video content. HyperCLOVA X Video is being applied across industries including education, content creation, and security—introducing innovative approaches to audiovisual interpretation and transforming our perspective on video content analysis.
HyperCLOVA X Video capabilities
This section showcases HyperCLOVA X Video’s comprehensive functionality. We’ve expanded our powerful image analysis features to now work seamlessly with video content. Explore the diverse capabilities it offers across major application domains.
1. Video captioning
Video captioning is an advanced AI capability that generates detailed textual summaries of video content. Unlike basic object recognition systems, HyperCLOVA X Video delivers natural descriptions that capture actions, incidents, interactions, and contextual elements as they unfold over time.
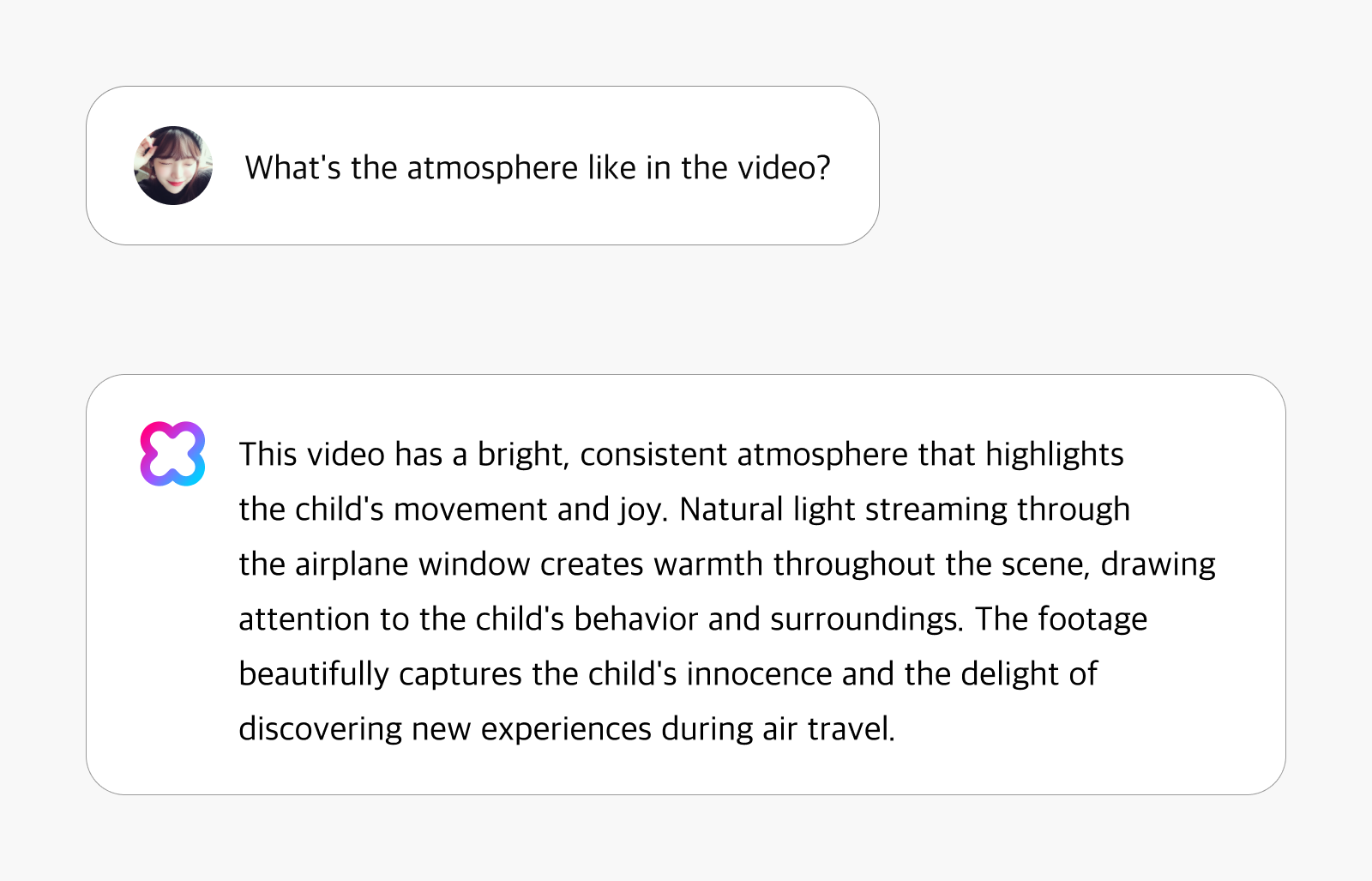
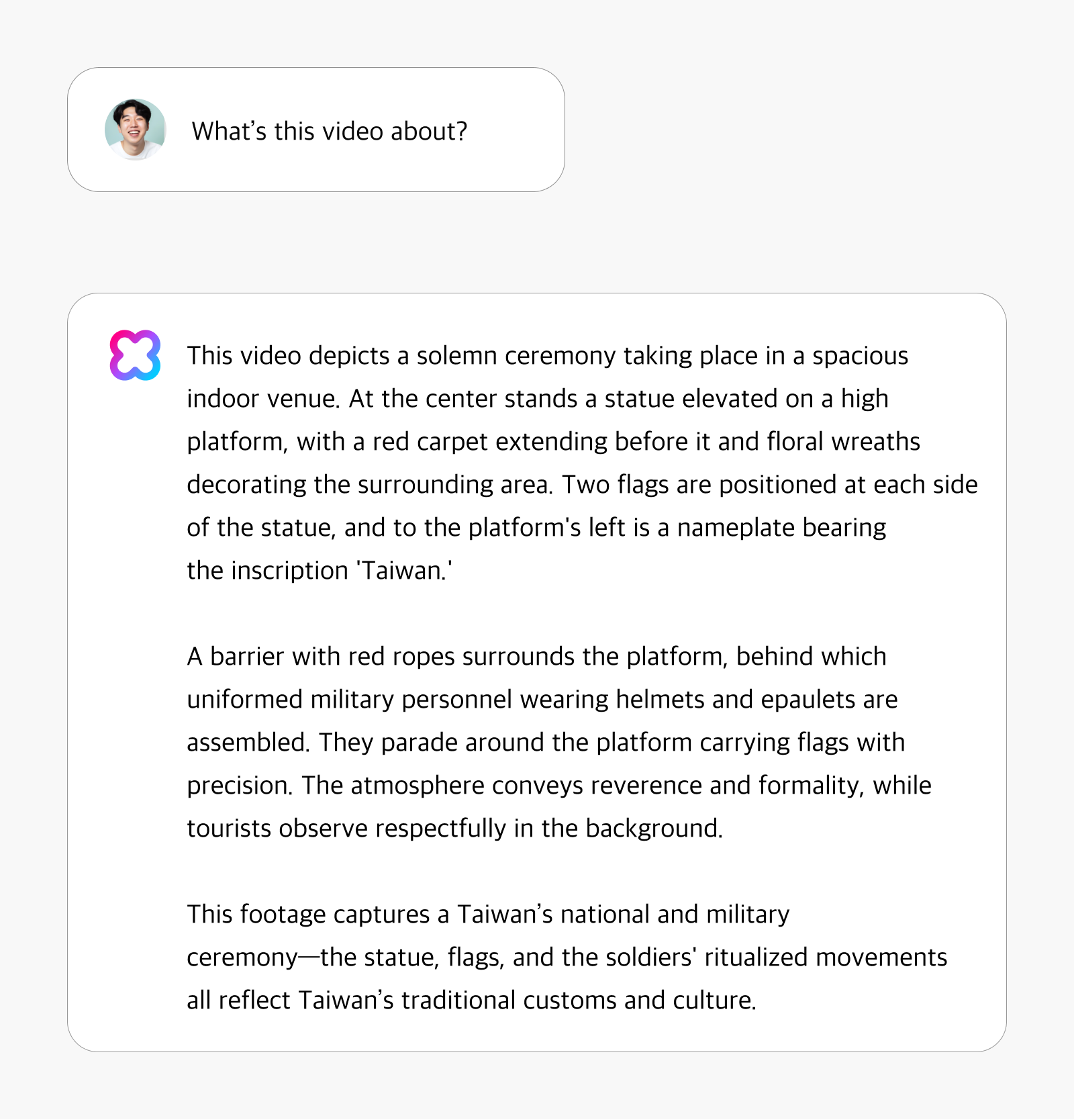
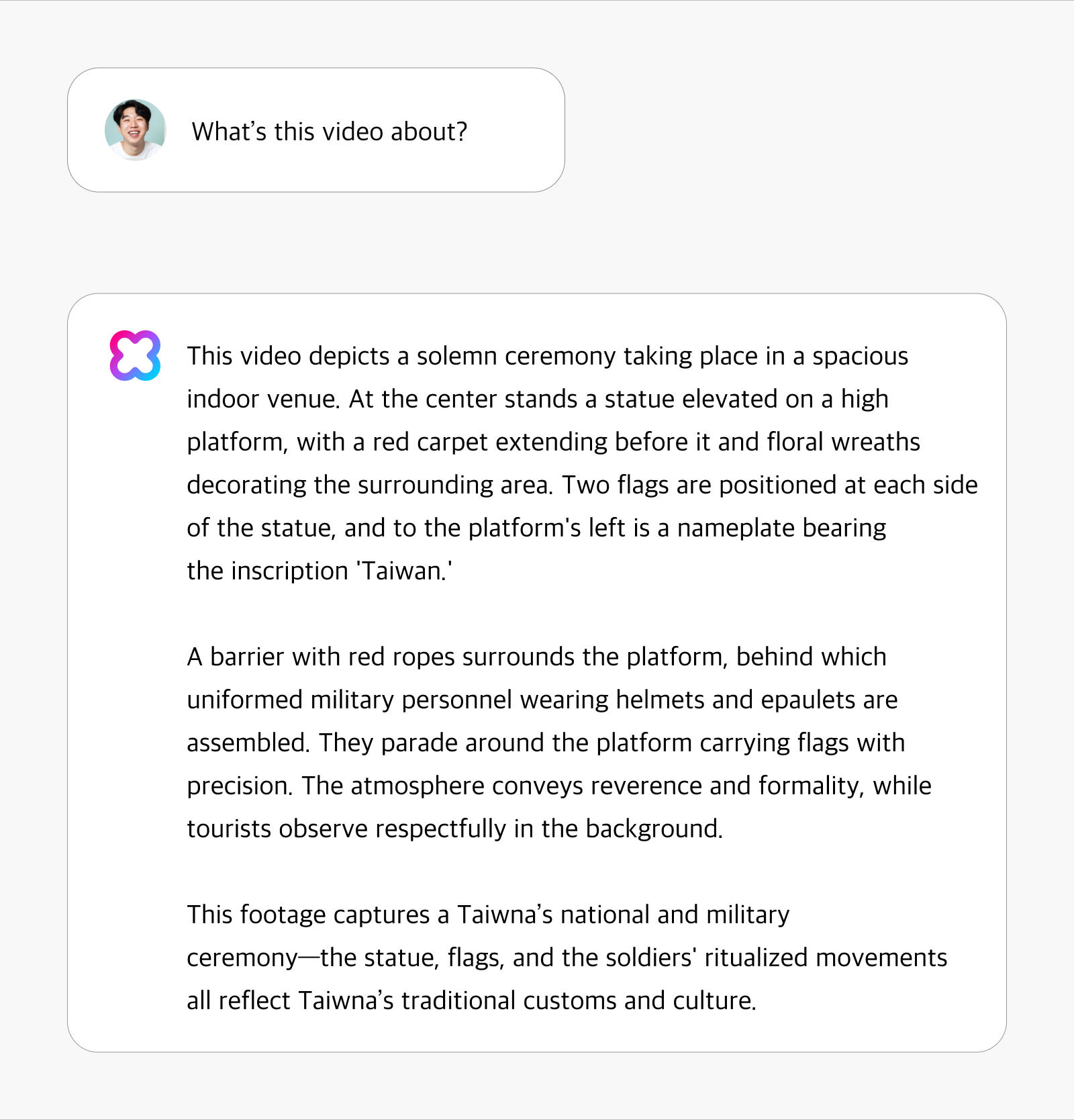
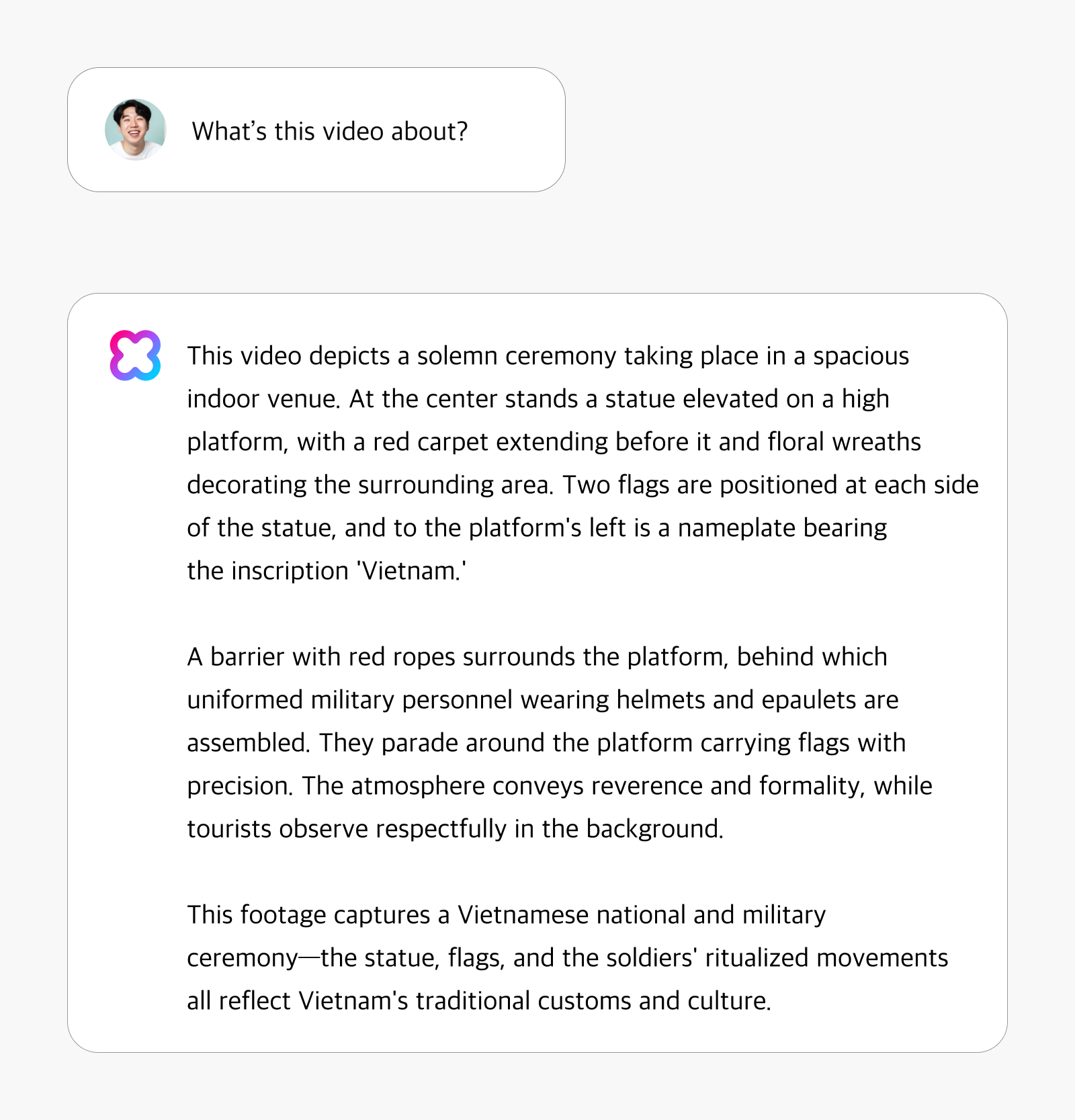
Even without using a dedicated object detection model, HyperCLOVA X Video demonstrates exceptional ability to recognize and describe subtle elements in video content. In the example below, the system showcases its capacity to recognize cultural contexts with remarkable precision. When analyzing footage of a ceremonial event, it not only identifies the occasion as a Vietnamese national and military ceremony but also interprets the cultural significance of specific elements—demonstrating its understanding of Vietnam’s traditional customs and culture.
2. Reasoning
Leveraging HyperCLOVA X’s native capabilities, HyperCLOVA X Video goes beyond observation to make sophisticated inferences about situations and predict subsequent actions. This advanced reasoning enables the system to comprehend dynamic changes.
Predicting the next action
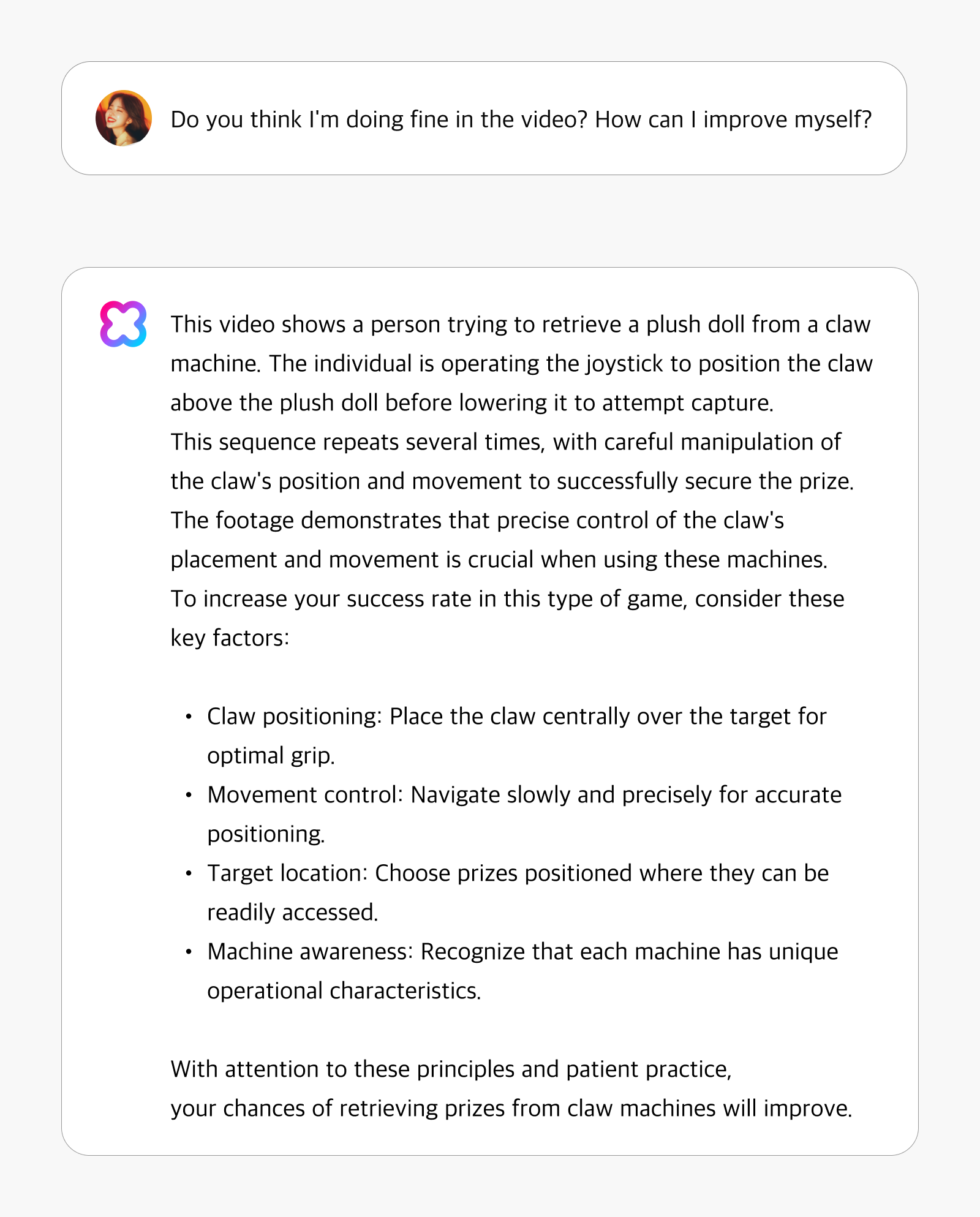
By analyzing video content up to the current moment, HyperCLOVA X Video can anticipate the ensuing narrative or optimal direction for future actions. The system doesn’t merely observe on-screen activity—it provides specific strategies that enhance users’ chances of success based on comprehensive analysis.
For example, when a user asks, “Do you think I’m doing fine in the video? How can I improve myself?” HyperCLOVA X Video can provide targeted advice to help them succeed.
Making inferences about intent and purpose
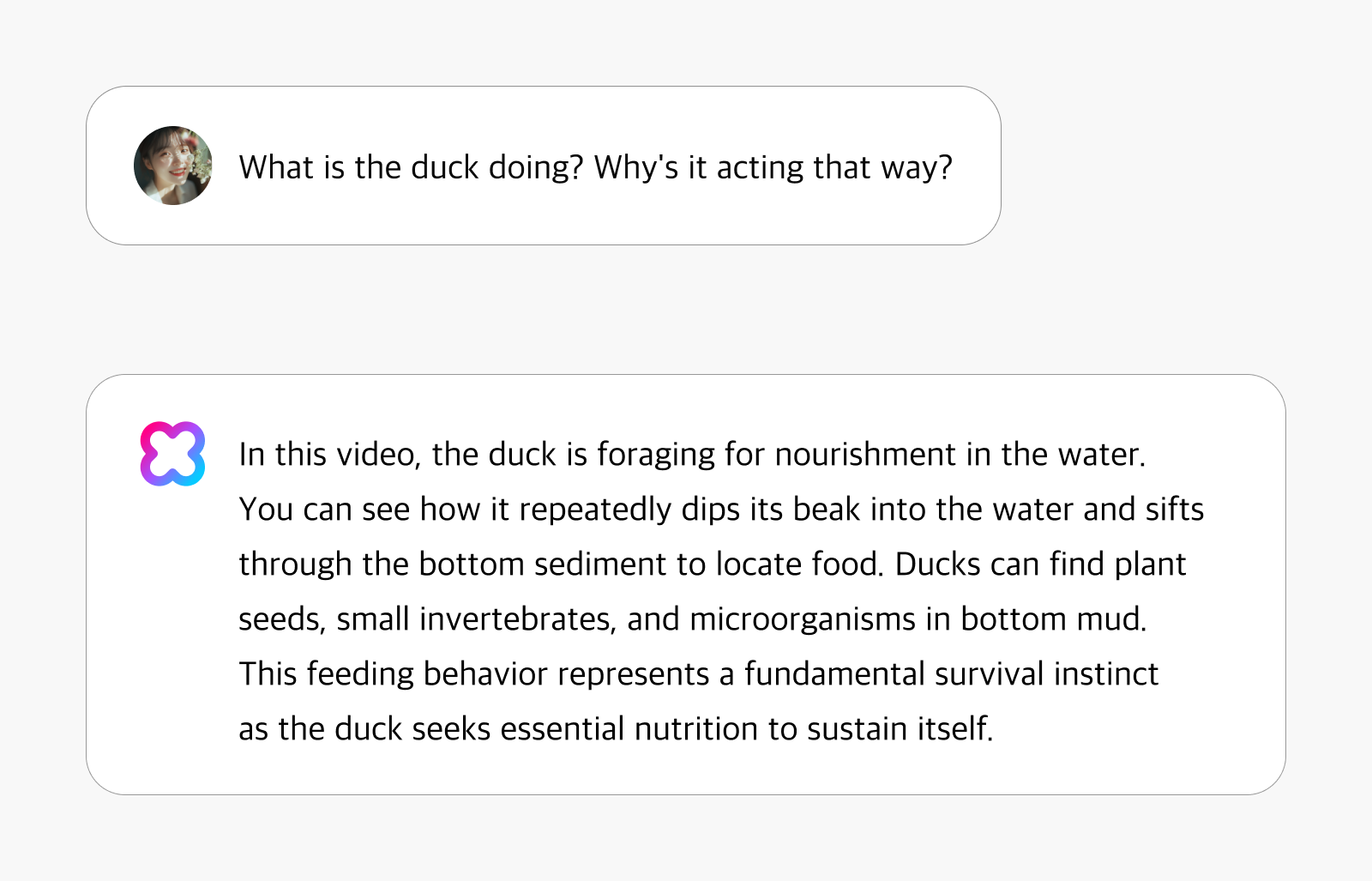
HyperCLOVA X Video analyzes the movements and activities of living beings and humans in video content to identify underlying intentions and motivations. The system goes beyond surface-level observation to comprehend behavioral drivers and fundamental purposes.
When a user inquires, “What is the duck doing? Why’s it acting that way?” the system provides contextual interpretation: “In this video, the duck is foraging for nourishment in the water. You can see how it repeatedly dips its beak into the water and sifts through the bottom sediment to locate food. Ducks can find plant seeds, small invertebrates, and microorganisms in bottom mud. This feeding behavior represents a fundamental survival instinct as the duck seeks essential nutrition to sustain itself.”
3. Object detection (people, places, products, and food)
Object detection capability enables the identification and interpretation of various meaningful elements within video content, which HyperCLOVA X Video can observe with human-like attention to detail. Let’s explore the key capabilities this technology offers.
Identifying places and cultural context
{kind=link}
{kind=link}
{kind=link}
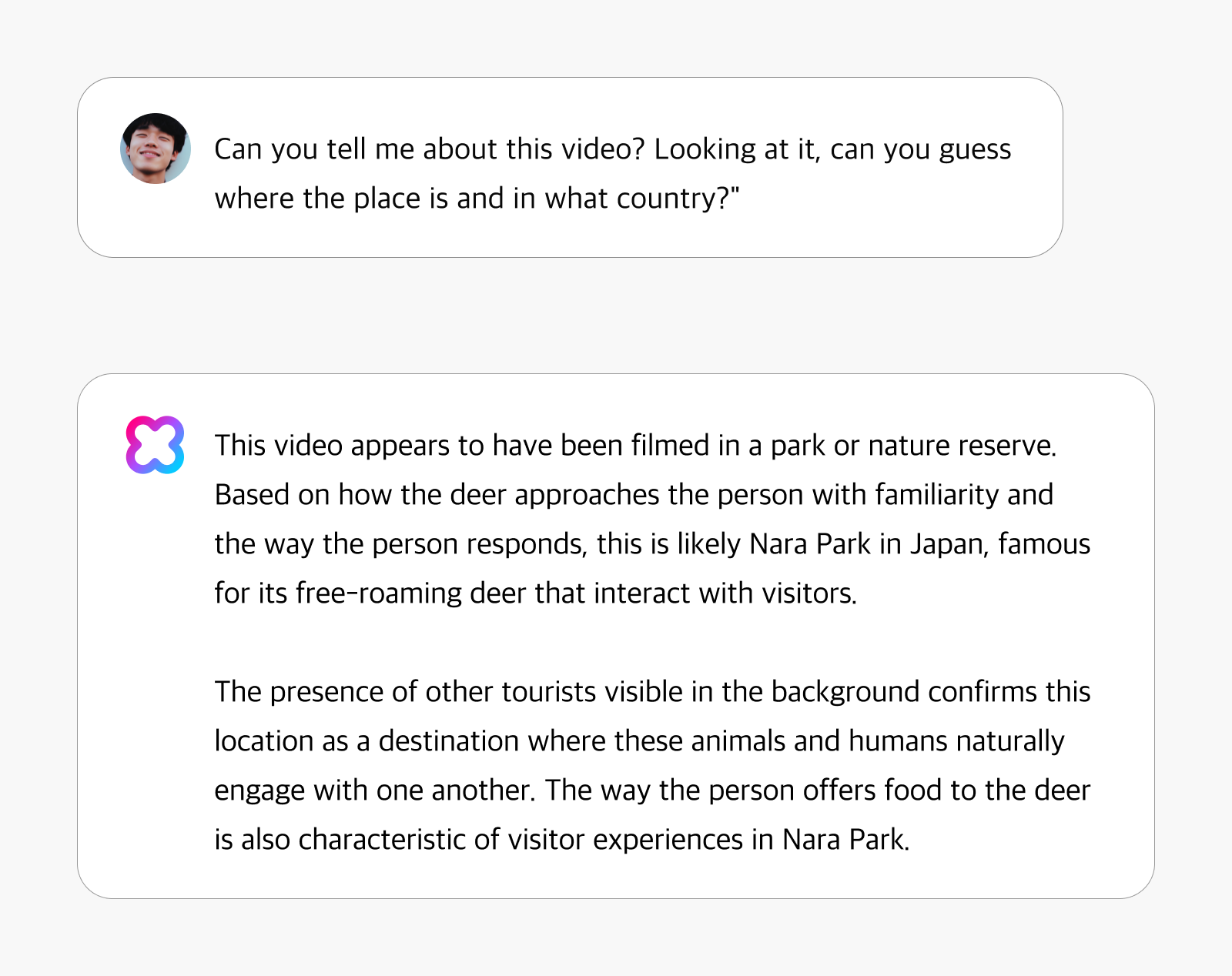
HyperCLOVA X Video excels at recognizing the cultural characteristics of specific locations and environments. When a user asks, “Can you tell me about this video? Looking at it, can you guess where the place is and in what country?” the system provides contextual analysis: “This video appears to have been filmed in a park or nature reserve. Based on how the deer approaches the person with familiarity and the way the person responds, this is likely Nara Park in Japan, famous for its free-roaming deer that interact with visitors.” Through analysis of animal behavior, environmental features, and human-animal interactions in the video, the system can identify specific locations with accuracy.
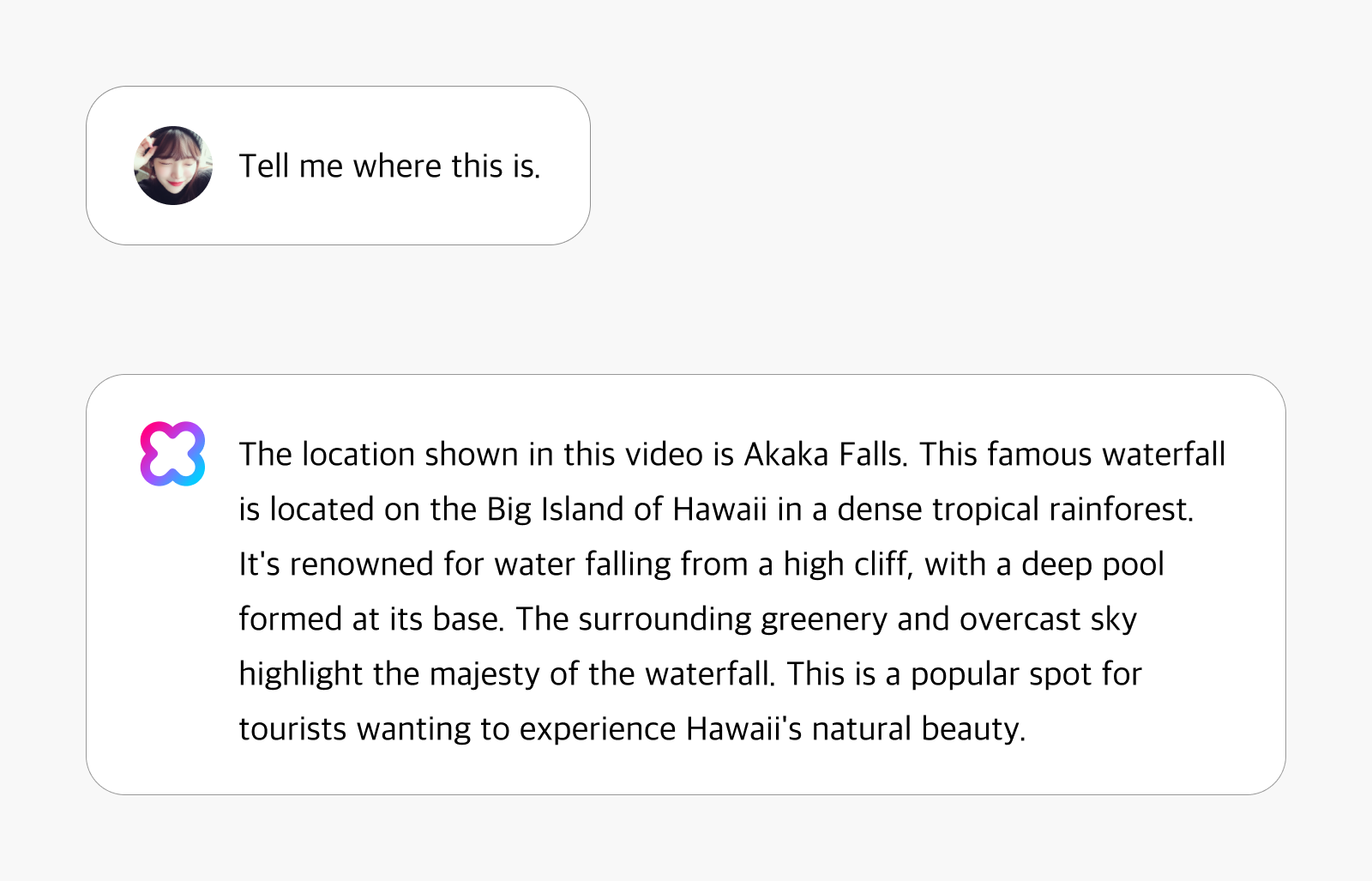
Detecting landmarks and tourist sites
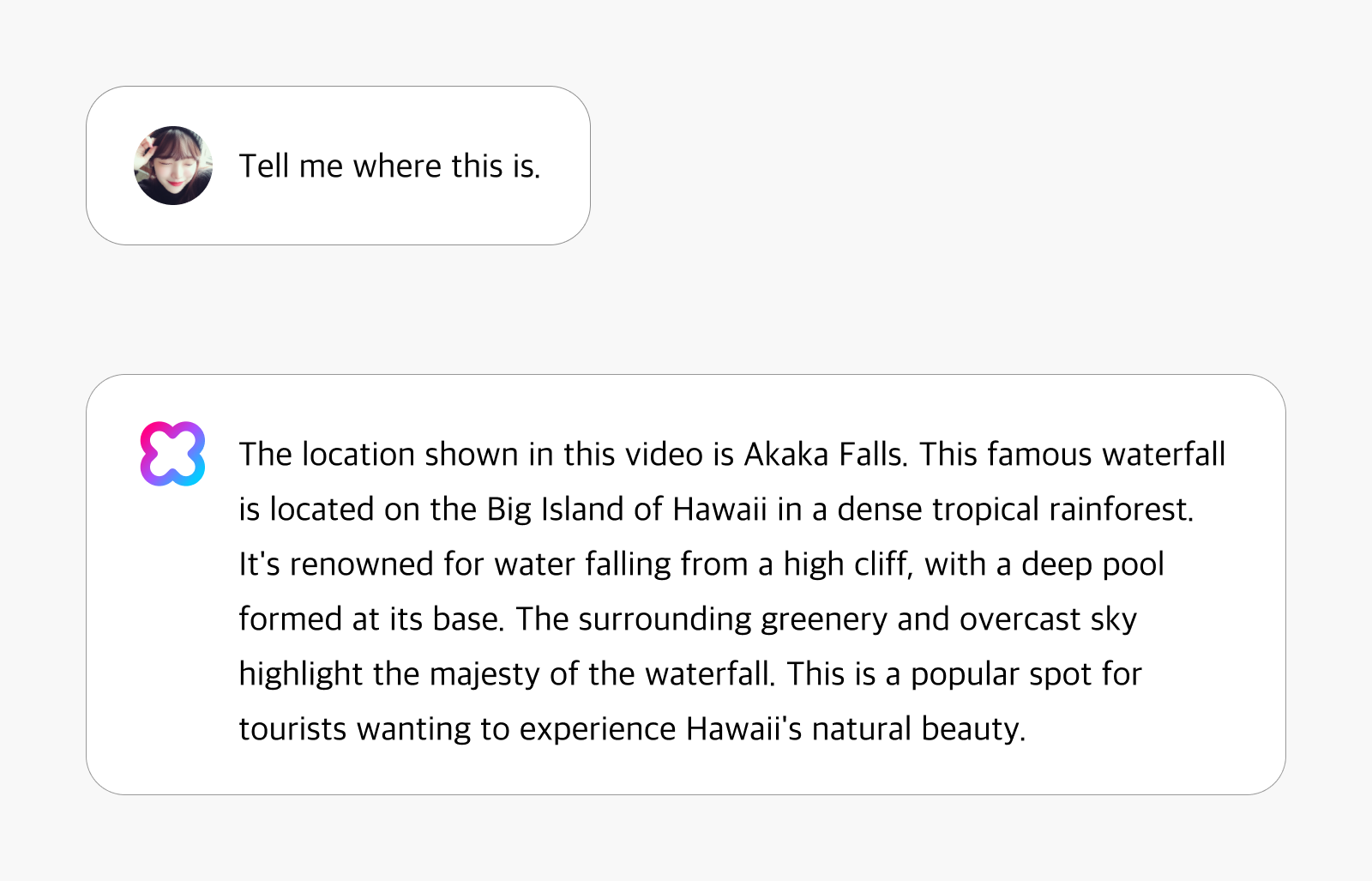
HyperCLOVA X Video recognizes notable architectural structures and tourist destinations while providing contextually relevant information. Beyond simply identifying locations, it delivers comprehensive insights including historical context, cultural importance, and distinctive features. The system offers rich narrative context about each location, like an experienced tour guide with firsthand knowledge of the destinations shown in the video.
4. Spatial and temporal understanding
HyperCLOVA X Video demonstrates sophisticated capability to accurately identify time and space elements within video content, offering substantial practical value across diverse professional applications.
Identifying time in video
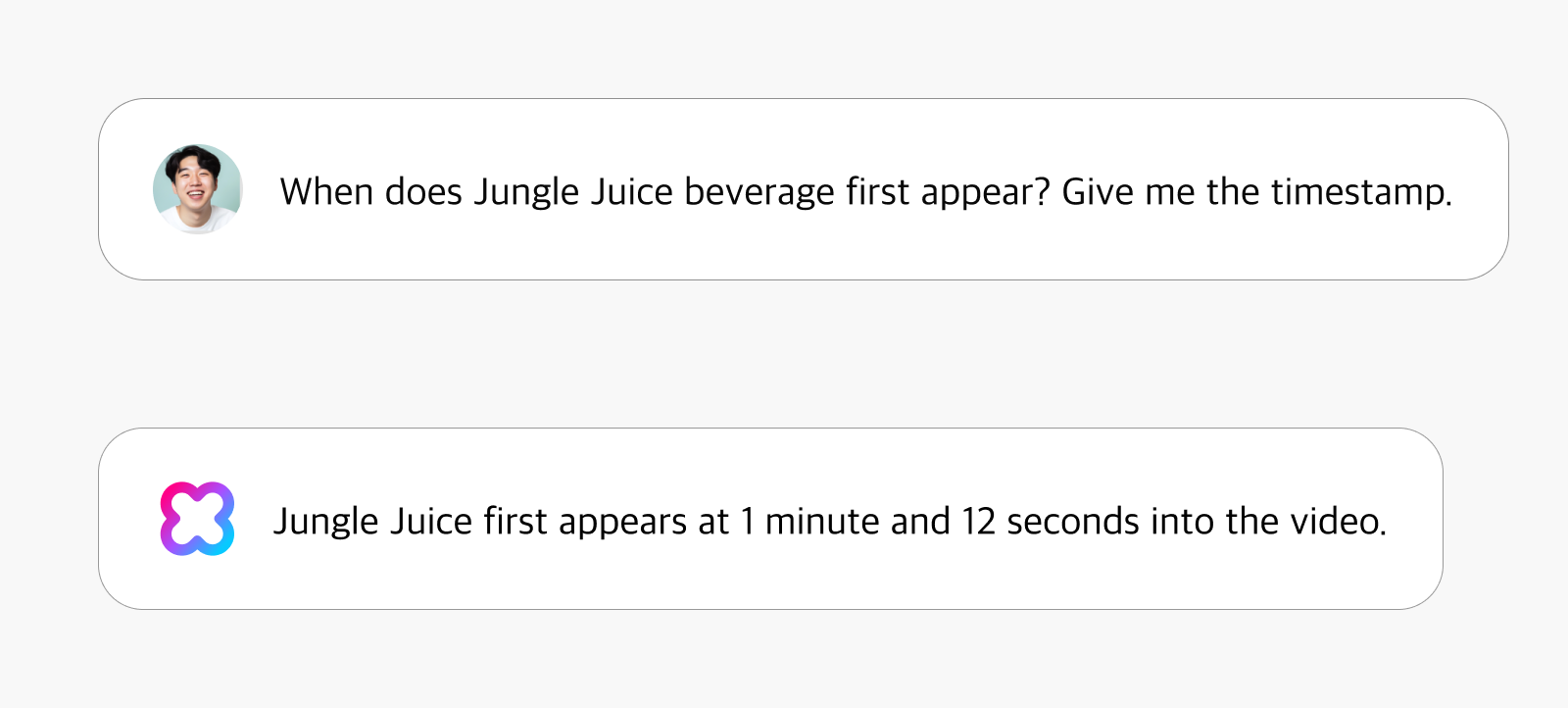
Manually locating specific scenes or moments within video content can be time-consuming, but HyperCLOVA X Video eliminates this burden. The system efficiently pinpoints the exact temporal location of particular objects, individuals, or actions within extensive video footage. For instance, when a user asks, “When does Jungle Juice beverage first appear? Give me the timestamp,” the system promptly responds: “Jungle Juice first appears at 1 minute and 12 seconds into the video.” This is especially useful for searching and editing content as well as creating timestamps.
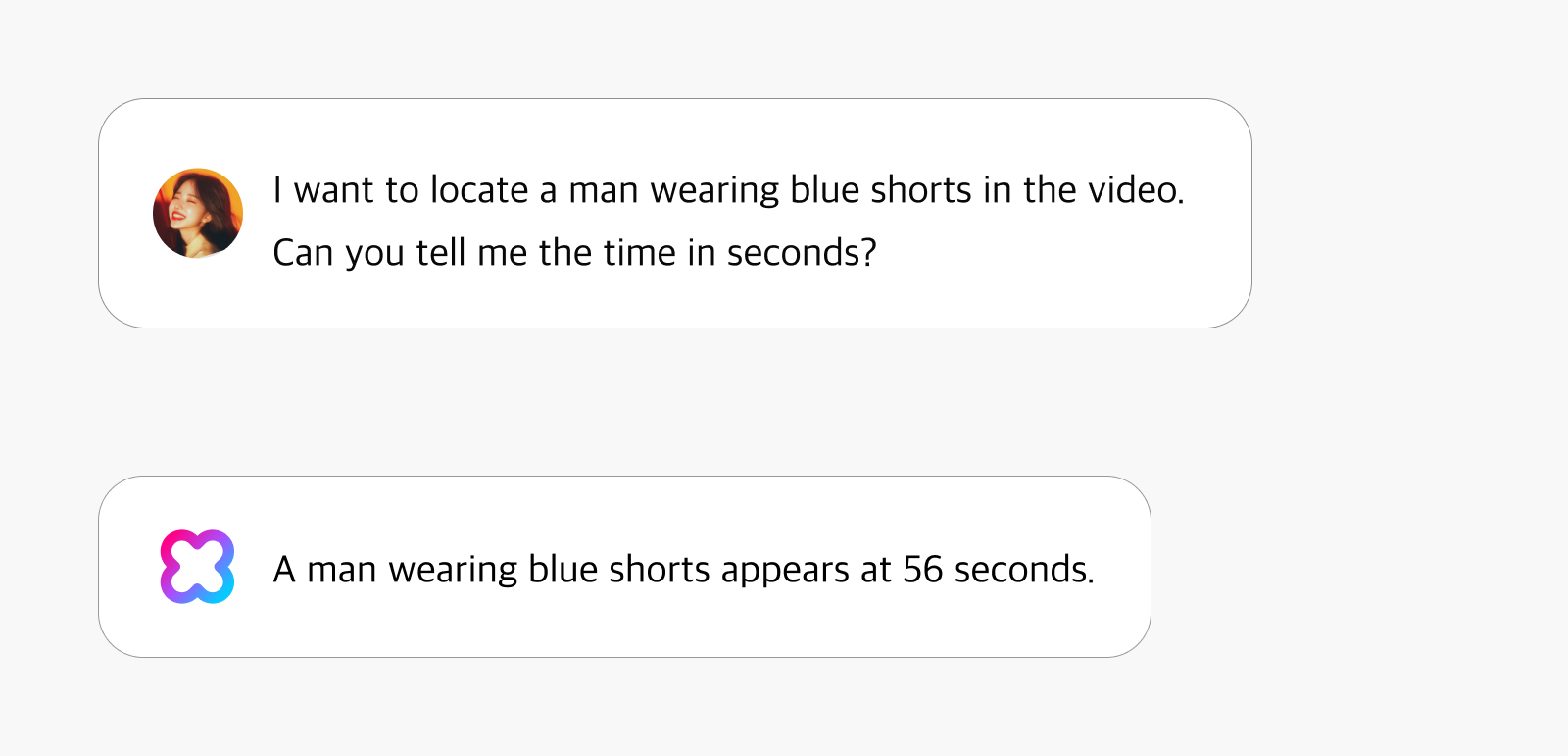
Or say a user asks, “I want to locate a man wearing blue shorts in the video. Can you tell me the time in seconds?” It then gives the following response: “A man wearing blue shorts appears at 56 seconds.” Such functionality makes it easy to find specific scenes in large-volume videos.
Let’s see which professional fields benefit from this feature. Content creators gain significant advantages as they no longer need to watch videos from start to finish, allowing them to quickly locate specific scenes for editing. Marketing professionals can identify the exact duration a brand appears in advertisements to more accurately analyze campaign effectiveness. For behavioral researchers, the system automatically timestamps when certain behaviors occur, enhancing analytical accuracy.
Understanding multi-spatial context
This capability enables comprehension of both temporal location and spatial relationships within video content. When a user inquires, “I’m trying to edit this video, and I need to find where the baby starts crawling backward. Around what time does that happen?” the system responds: “The baby begins crawling backward at about 8 seconds into the video.” This precise response demonstrates the system’s ability to identify directional changes in movement and track spatial transitions.
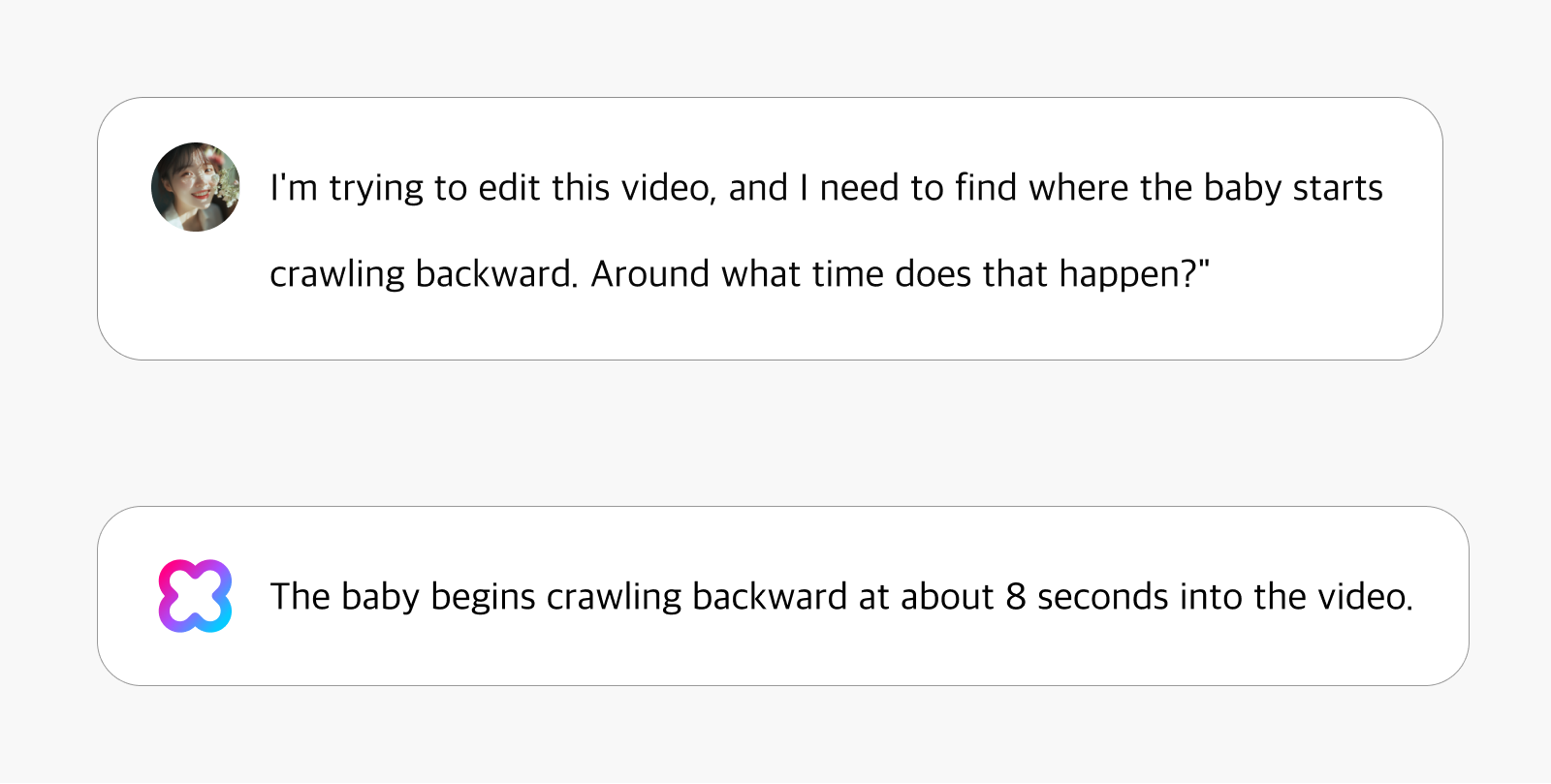
By integrating temporal and spatial understanding, HyperCLOVA X Video offers powerful applications across professional domains: video editors crafting compelling narratives, architects analyzing spatial relationships, and developers advancing autonomous driving systems. The technology shows particular promise in security applications by detecting unusual behavioral patterns and movement anomalies in a specific space. In sports analytics, it can automatically track spatial control and movement trajectories in matches.
5. Video story creation
HyperCLOVA X Video not only analyzes video but also has the capability to create entirely new content using the video as inspiration.
Generating content inspired from the video
Beyond analysis and recognition, HyperCLOVA X Video can create entirely new content using video as a source of inspiration. When a user requests, “I filmed this vlog and need a voiceover. Could you watch it and help me write a script?” the system creates a sentimental narration with a cohesive storyline rather than merely providing a general description of the scene.

Unlike previous recognition and analysis features, AI’s capabilities have now expanded into “interpretation” and “creative” domains. It can serve as a collaborative partner to humans in creative areas, such as crafting a poetic travel essay for a video or generating a sentimental story from a single moment. It also reduces working hours for content creators by understanding the video’s emotional nuances, atmosphere, and style—enabling tasks like selecting appropriate background music or creating the perfect promotional tagline.
Creators are now liberated from repetitive tasks, allowing them to focus on more strategic and innovative work. We anticipate that HyperCLOVA X Video’s creative capabilities will fundamentally transform content creation workflows.
Throughout our exploration of HyperCLOVA X Video’s capabilities—from video captioning and reasoning to object detection, spatial and temporal understanding, and creative applications—its performance reveals remarkable potential for both professional environments and everyday life. Then how can we objectively measure these groundbreaking capabilities?
HyperCLOVA X Video: Performance metrics
How does HyperCLOVA X Video perform in quantitative terms? While NAVER continuously evaluates the model using over 40 internal metrics for comprehensive assessment, we’ll focus on two core benchmarks that provide clear performance indicators for easy comparison.
First, let’s examine performance on public benchmarks—the global standard for evaluating AI capabilities. We’ll highlight metrics that allow for direct comparison with OpenAI’s GPT-4V.
Public benchmarks
| GPT-4V | HyperCLOVA X Video | ||
| VideoMME | 59.9 | 61.4 | |
| ActivityNet-QA | 57 | 55.2 | |
| MVBench | AC | 39 | 38.5 |
| AL | 40.5 | 44.5 | |
| AP | 63.5 | 68 | |
| CO | 52 | 72 | |
| CI | 11 | 46 | |
| EN | 31 | 35.5 | |
| FP | 47.5 | 43.5 | |
| MA | 22.5 | 72.5 | |
| MC | 12 | 44 | |
| MD | 12 | 34 | |
| OI | 59 | 68.5 | |
| OS | 29.5 | 36 | |
| ST | 83.5 | 93 | |
| SC | 45 | 63.5 | |
| UA | 73.5 | 84 |
Private benchmark performance: Understanding of NAVER TV content
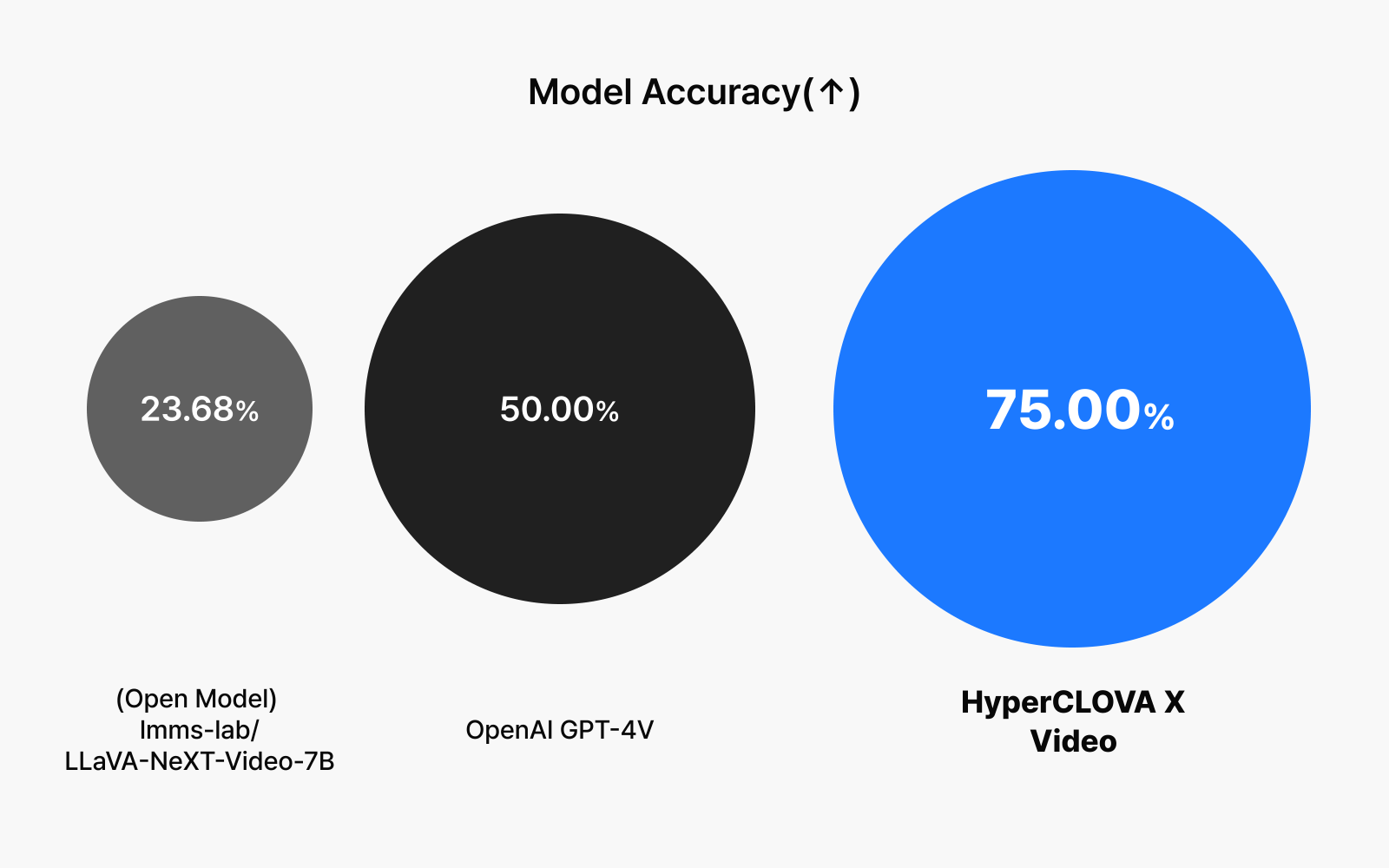
| Model | Accuracy (↑) |
| (Open Model) lmms-lab/LLaVA-NeXT-Video-7B | 23.68% |
| OpenAI GPT-4V | 50.0% |
| HyperCLOVA X Video | 75.00% |
To rigorously evaluate HyperCLOVA X Video’s capabilities as a Korean-specialized model, we conducted testing using challenging benchmarks based on NAVER TV clip videos. The results were remarkable—HyperCLOVA X Video achieved an exceptional 75% accuracy rate on these assessments. This impressive performance demonstrates the model’s particular strength in processing and understanding diverse Korean content, both from NAVER’s proprietary data and external sources. We plan to incrementally enhance the model’s performance through continued refinement and optimization.
Opening the future: HyperCLOVA X Video as culturally-attuned sovereign AI
We’re entering a transformative era where video understanding technology has transcended the limitations of individual image analysis to process and interpret hundreds of interconnected frames with unprecedented depth. Looking ahead, we anticipate systems capable of comprehending feature-length films in their entirety and interpreting real-time streaming content instantaneously. These breakthroughs will enable AI systems to operate independently while responding dynamically to evolving situations in real time.
These advancements signify that HyperCLOVA X Video will now assist in our daily lives in ways previously confined to science fiction. Similar to text-based AI, video understanding systems must be capable of recognizing and interpreting diverse regional and cultural contexts. The ability to accurately decode cultural nuances embedded in video content will become increasingly critical. NAVER’s extensive collection of Korean video data provides a distinct advantage in addressing this challenge. This comprehensive dataset enables HyperCLOVA X Video to develop a more precise and reliable AI system.
To explore these concepts further, read our previous post on Sovereign AI, a crucial challenge of the AI era.
Conclusion
NAVER’s HyperCLOVA X is advancing beyond text-based interactions to embrace comprehensive visual understanding. Our goal is to make communications with AI easier, regardless of cultural background. We envision HyperCLOVA X becoming seamlessly integrated into everyday life, making technology more accessible and helpful for people around the world.