
Learn more about HyperCLOVA X SEED 32B Think on Hugging Face
Learn more about HyperCLOVA X SEED 8B Omni on Hugging Face
Sovereign AI means independently developing and operating AI that truly understands a nation’s or region’s culture, history, and values. As AI transforms industries and daily life at an unprecedented pace, nations around the world are racing to take the lead. Korea is no exception—through the Sovereign AI Foundation Model Project , the country is working to develop indigenous AI capabilities.
TEAM NAVER is participating in this initiative as one of the elite teams leading the K-AI journey. In this post, we introduce two new models that reflect our AI development direction and philosophy, along with a glimpse of our years-long commitment to sovereign AI and our efforts to build a national AI ecosystem.
K-AI, AI for everyone
TEAM NAVER’s vision for K-AI is clear: creating an AI ecosystem for every citizen. Our goal is to make AI accessible to everyone, extending its benefits to communities it has previously failed to reach while strengthening national industry competitiveness.
“K-AI for everyone” means AI should solve the diverse problems people encounter in their daily lives. This requires truly understanding our culture and world—not just generating plausible answers. To this end, TEAM NAVER is training models with Korean-specific data so they can understand our unique language, culture, and social context in depth.
But AI should go further still, integrating with the physical world to perform real-world tasks. As AI’s applicability expands across industries, so does the demand for understanding and generating various modalities—images, audio, and more, beyond text alone. Just as our daily communication involves not just written words but voices and visual context, AI must handle different modalities within a single context to serve a wider range of industries and real-life applications.
This expansion of modalities marks a departure from heavy reliance on text-based information—and a step closer to artificial general intelligence. Traditional large language models built their understanding of humanity’s accumulated knowledge through text, modeling our world with remarkable success. However, high-quality text data is reaching its limits, and text alone lacks the visual and auditory information essential for understanding the real world. Only by training on data across various modalities can models develop a deeper understanding of reality.
What is omnimodality?
This is why we focused on omnimodality. Omnimodal AI refers to a single model that can understand and generate text, images, audio, and other modalities simultaneously.
Traditional vision language models (VLMs) had image-processing capabilities but could only respond in text. While they could process visual information, they were limited to explaining things in words—they struggled to communicate across modalities, such as generating images or responding in audio.
We’re overcoming this limitation by building an omnimodal model that can receive text, images, and audio as input and produce them as output. Unlike the previous approach of building separate models for each modality and connecting them afterward, our model integrates processing for each modality within a single architecture. This design produces far more reliable and natural-sounding results in complex, real-world environments that require sophisticated reasoning.
Efficient development and use
Beyond solid performance, we also aim for high efficiency. Running AI requires different model sizes depending on the difficulty and conditions of the problem at hand, and costs grow in proportion to size. No matter how well a model performs, if it costs too much to run, it isn’t practical. Solving problems of varying difficulty and context therefore requires models of varying sizes—including small ones.
Starting with small models also makes sense from a development efficiency perspective. By beginning small and comparing against others of similar size, we can experimentally test different development methods, such as model architecture and training data composition. Validating competitiveness at comparable sizes before scaling up allows us to reliably optimize the performance-to-cost ratio. Rather than prioritizing size to boost performance, we focus on maximizing development efficiency—maintaining reasonable cost and architecture even when expanding to larger models.
AI that can see, hear, and talk: HyperCLOVA X SEED 32B Think & 8B Omni
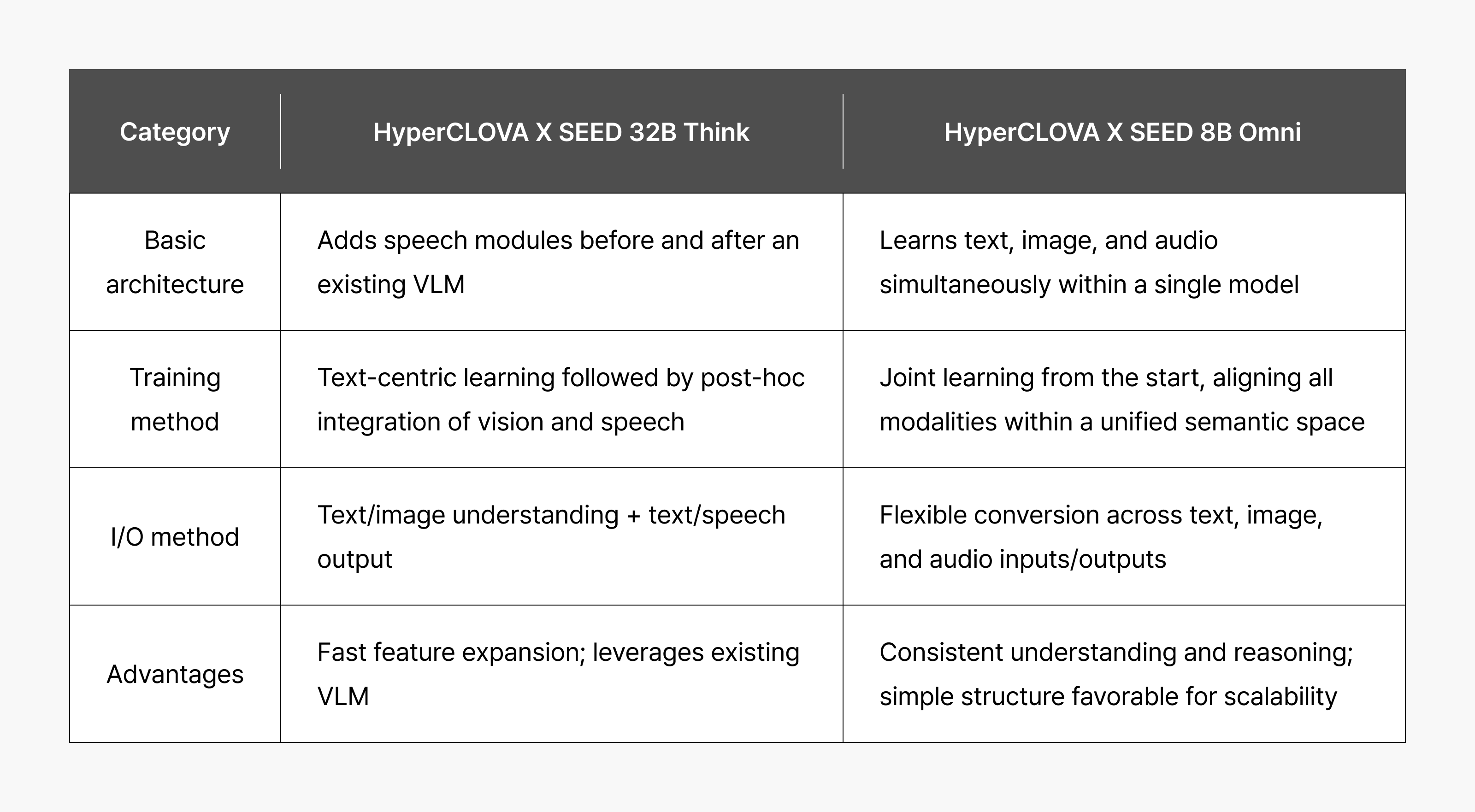
TEAM NAVER has launched two models on two tracks: HyperCLOVA X SEED 32B Think, which adds voice capabilities to our previous text-and-image vision language model to quickly deliver an omnimodal experience, and HyperCLOVA X SEED 8B Omni, designed to train on text, image, and audio simultaneously within a single model.
These two models aren’t competing with one another. HyperCLOVA X SEED 32B Think enables an omnimodal experience in daily life, serving as a bridge to full omnimodal transformation. HyperCLOVA X SEED 8B Omni, on the other hand, is Korea’s first truly omnimodal model—the starting point for our long-term roadmap toward larger-scale expansion.
HyperCLOVA X SEED 32B Think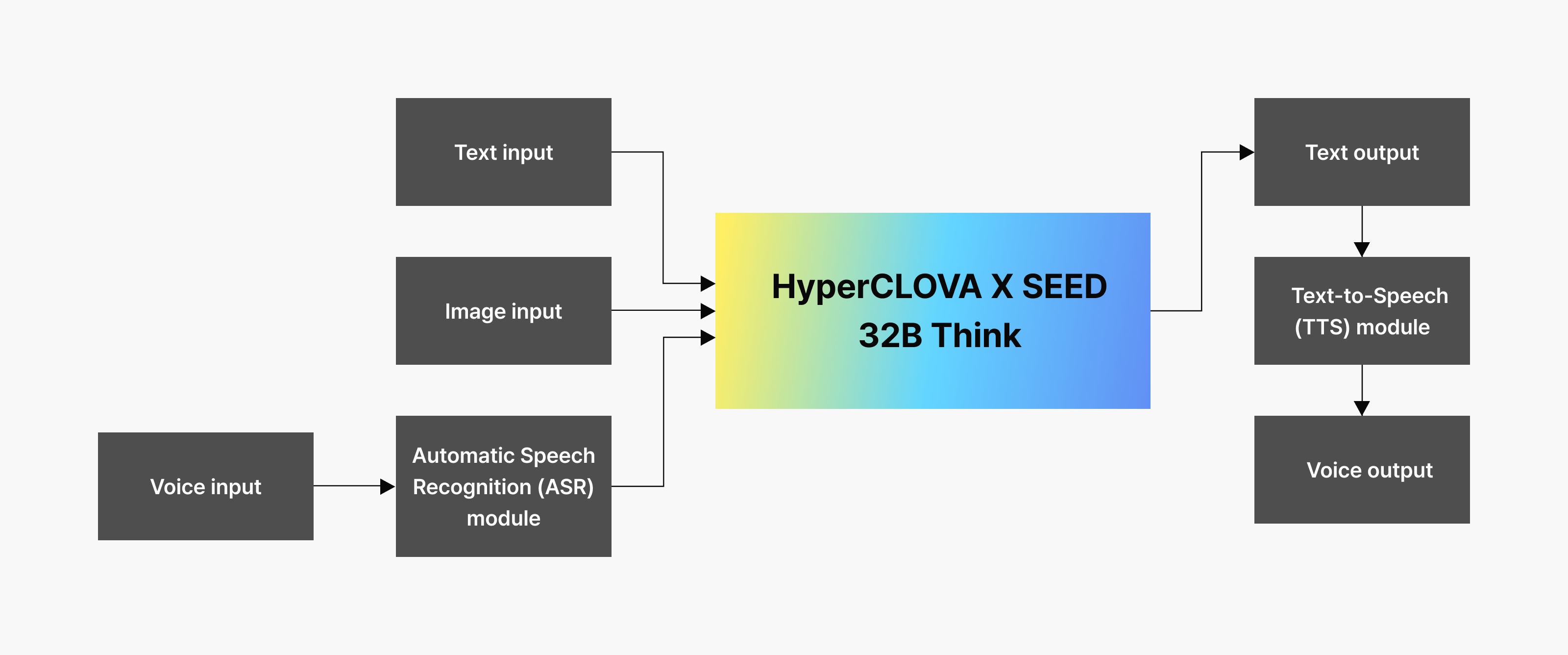 At the center of HyperCLOVA X SEED 32B Think is our existing text-and-image multimodal model, with speech recognition and synthesis modules attached at the front and back. In front of the vision language model (VLM) is a module that converts user speech into text, and at the back is a module that reads the model’s text response aloud.
At the center of HyperCLOVA X SEED 32B Think is our existing text-and-image multimodal model, with speech recognition and synthesis modules attached at the front and back. In front of the vision language model (VLM) is a module that converts user speech into text, and at the back is a module that reads the model’s text response aloud.
This model maintains existing VLM capabilities—the ability to understand text and images and perform in-depth reasoning—while also interacting with users through voice conversation. When a user shows a picture and asks a question aloud, the model understands the picture and question together, generates a response in text, then reads the response aloud.
While this structure makes it easy to add voice capabilities by attaching an audio module to a multimodal model, it has limitations in output modality and latency.
HyperCLOVA X SEED 8B Omni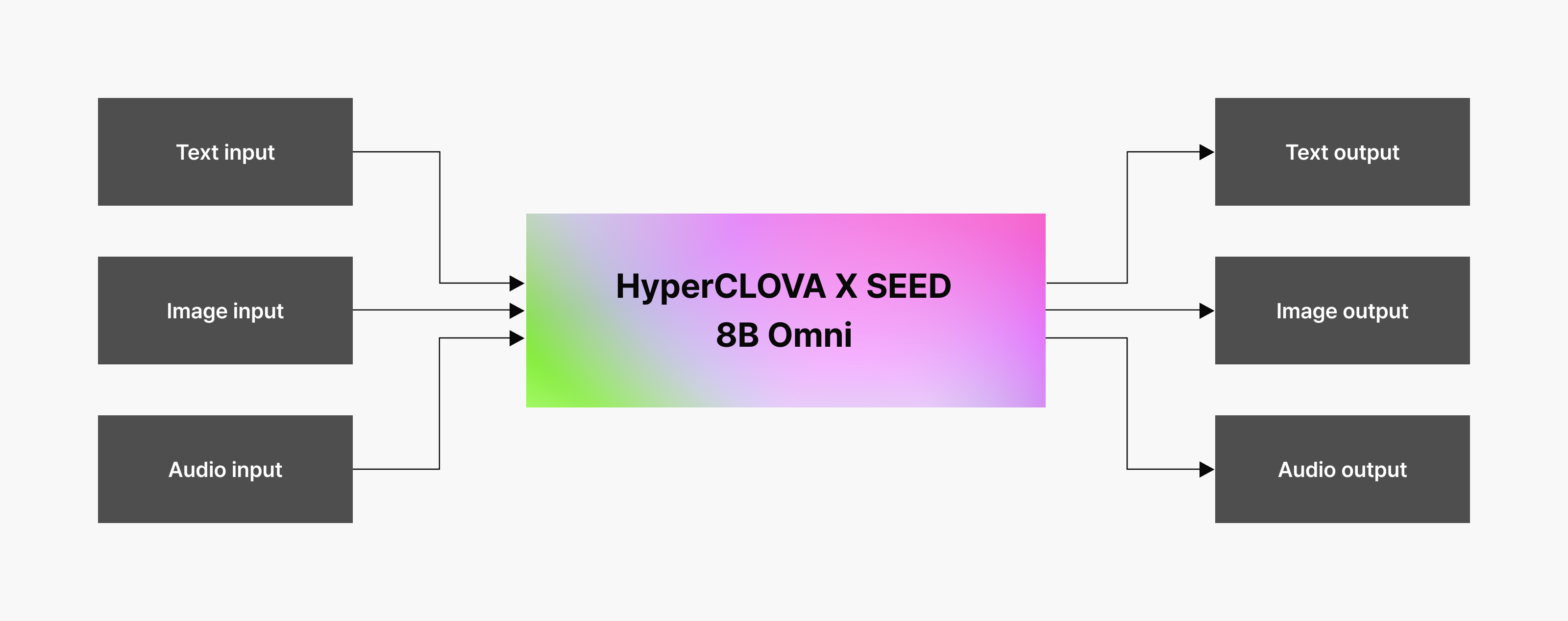 HyperCLOVA X SEED 8B Omni takes a different approach from the start. Instead of connecting separate models that each process text, image, and audio, we designed an integrated model that learns various modalities at once.
HyperCLOVA X SEED 8B Omni takes a different approach from the start. Instead of connecting separate models that each process text, image, and audio, we designed an integrated model that learns various modalities at once.
Inside an omnimodal model, words, scenes, and sounds are aligned within a single semantic space. Whether a concept is expressed in text, image, or sound, the model understands it as having the same meaning—enabling a consistent understanding of the relationships between objects, user intent, and situational context. Whether users ask via text, image, or voice, they can expect a similar level of understanding and answer quality.
Another strength is the model’s simple, integrated architecture, which allows it to scale cleanly as more resources are added. We’ve built a foundation where the model can expand into a larger omnimodal model while maintaining the same architecture as conditions improve.
Omnimodal models in numbers
Let’s take a look at these models from a more objective perspective. What are the strengths of HyperCLOVA X SEED 32B Think and HyperCLOVA X SEED 8B Omni when measured against various multimodal benchmarks?
HyperCLOVA X SEED 32B Think
HyperCLOVA X SEED 32B Think maintains the excellent reasoning capabilities of the previous HyperCLOVA X SEED Think model while enhancing visual understanding and agent capabilities.
To verify these enhancements from multiple angles, we evaluated general knowledge (text-based), vision understanding, and agentic task performance. For comparison, we selected a text-based model from a domestic company (Model A), along with global models Qwen3-VL-32B-Thinking and InternVL3_5-38B —both of which offer reasoning and vision capabilities.
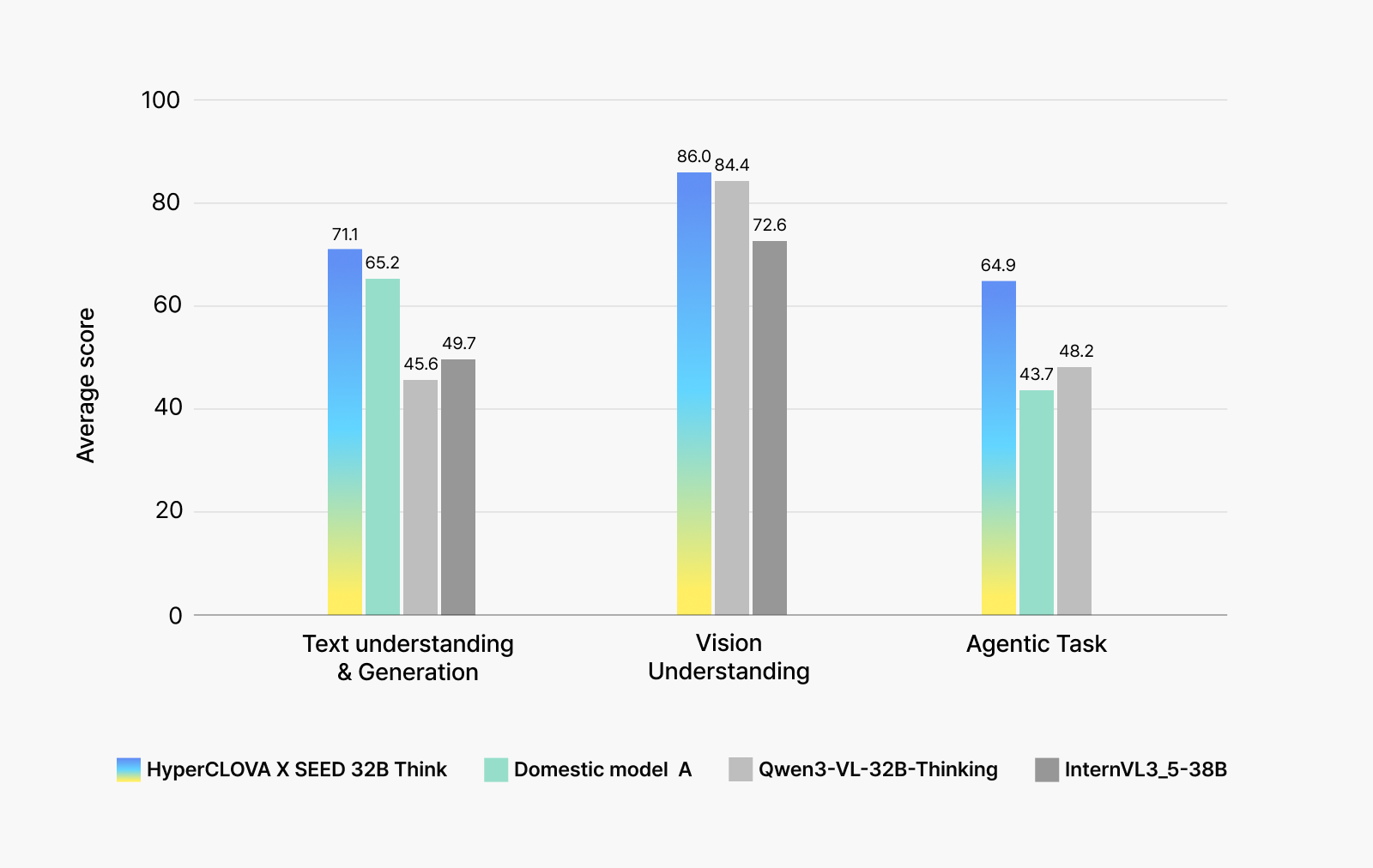
HyperCLOVA X SEED 32B Think scored approximately 10 percentage points higher than the domestic text-based model on general knowledge of Korean culture and language, and outperformed other global models specialized in visual reasoning on vision understanding benchmarks. In agentic tasks—which measure how well a model can solve problems using actual tools—HyperCLOVA X SEED 32B Think also showed dramatically higher performance, scoring 15 percentage points higher than other models.
HyperCLOVA X SEED 8B Omni
How did Korea’s first omnimodal model, HyperCLOVA X SEED 8B Omni, perform? Let’s take an objective look at its performance using global benchmarks.
To truly verify its capabilities as an omnimodal model, we compared HyperCLOVA X SEED 8B Omni against five competitive multimodal LLMs of comparable size. We also selected 12 global multimodal benchmarks to evaluate the model across various scenarios—from vision-and-text to text-to-audio to text-to-vision.
 While these global multimodal models failed to support certain input-output combinations like audio-to-audio, we verified that HyperCLOVA X SEED 8B Omni can support any input or output combination. We also demonstrated that our model holds its own against models that excel in particular combinations like text-to-vision or vision-to-text—achieving high scores across all modality combinations and demonstrating balanced performance overall. This shows that HyperCLOVA X SEED 8B Omni provides a consistently high level of understanding and response quality whether users ask via text, image, or voice.
While these global multimodal models failed to support certain input-output combinations like audio-to-audio, we verified that HyperCLOVA X SEED 8B Omni can support any input or output combination. We also demonstrated that our model holds its own against models that excel in particular combinations like text-to-vision or vision-to-text—achieving high scores across all modality combinations and demonstrating balanced performance overall. This shows that HyperCLOVA X SEED 8B Omni provides a consistently high level of understanding and response quality whether users ask via text, image, or voice.
Can AI actually solve real-world problems?
As mentioned earlier, TEAM NAVER is focused on practicality—expanding AI capabilities to solve real problems. Let’s go beyond the benchmark numbers to see what kinds of problems our models can actually solve.
HyperCLOVA X SEED 32B Think
AI can now take tests like students—recognizing text, images, and audio within questions to solve problems. How did HyperCLOVA X SEED 32B Think fare on Korea’s 2026 College Scholastic Ability Test (CSAT)?
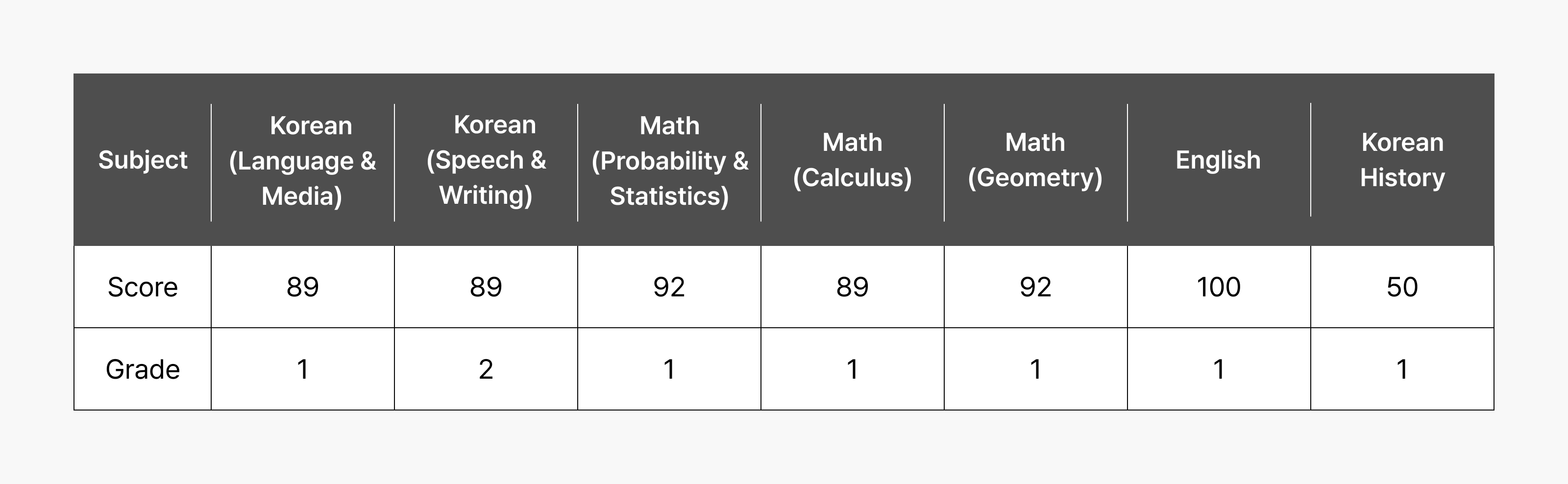 In Korean, English, mathematics, and the required subject Korean History, the model received Grade 1 in most subjects. In particular, it achieved a perfect score in English and Korean History, demonstrating excellent problem-solving abilities. HyperCLOVA X SEED 32B Think reached answers step by step using just photos of the exam papers, without having to type each question manually—a remarkable demonstration of its reasoning and multimodal capabilities.
In Korean, English, mathematics, and the required subject Korean History, the model received Grade 1 in most subjects. In particular, it achieved a perfect score in English and Korean History, demonstrating excellent problem-solving abilities. HyperCLOVA X SEED 32B Think reached answers step by step using just photos of the exam papers, without having to type each question manually—a remarkable demonstration of its reasoning and multimodal capabilities.
HyperCLOVA X SEED 8B Omni
What kinds of tasks can an omnimodal model perform? We applied HyperCLOVA X SEED 8B Omni to actual AI agents to see what it could do.
1) Talk to a consultation agent
Mind Care is a voice conversational agent where an avatar provides consolation and advice through heartwarming conversation. You can speak comfortably as if you’re talking to a human consultant and engage in an immersive conversation.
2) Convert voice into different languages and dialects
Voice Styler is an agent that converts user voice into regional dialects or other languages. You can instantly convert or interpret speech and add your voice for natural-sounding output.
3) Convert image styles
Style Studio is an image agent that transforms a given image into different artistic styles. You can convert images into a variety of fun styles, such as traditional Asian painting or cartoon.
Conclusion
The two models we’ve launched aren’t yet complete versions, but a preview of what’s coming from TEAM NAVER—omnimodal models built for agentic AI systems. Despite being works in progress, HyperCLOVA X SEED 32B Think and 8B Omni deliver omnimodal performance that reliably handles image and audio on top of the high-level reasoning and knowledge understanding capabilities demonstrated on text-based benchmarks. They represent all-around intelligence across language, visual, and auditory domains.
Beyond supporting multiple modalities, these models prove capable of solving various real-world problems and understanding their context. By interpreting images with complex structures and voices that change over time within a single semantic space, then reconstructing them into language, they demonstrate true contextual understanding.
HyperCLOVA X SEED 8B Omni is meaningful in that it maintains an architecture designed to ensure high-quality training while providing a foundation to scale naturally to a larger omnimodal model.
Our direction for the next-generation omnimodal model is already set: AI that naturally understands and generates across all senses, beyond text. The next step is to realize this potential at a bigger scale, step by step.
Check out our technical report for HyperCLOVA X SEED 32B Think
Check out our technical report for HyperCLOVA X SEED 8B Omni