Introduction
They say a picture is worth a thousand words to stress the power of vision over text. They also say eyes are windows to the soul, emphasizing our ability to take in visual information. Think of what it means for HyperCLOVA X (HCX) to understand images on top of text: we could automate document and image processing. Or, in the more distant future, we could use it to power the brains of robots, and these independent agents could perform tasks that require vision capabilities.
For language models to process visual information, we have to train them with large amounts of text and image data. To create our AI model, we first obtained high-quality training data, some of which came from our NAVER services. We then tried to make the best of these data so that they would not contradict each other but create synergy. All these efforts culminated in HyperCLOVA X Vision, which can now understand documents and more. We added image capabilities without compromising its existing text capabilities while also ensuring safety. In this post, we’ll walk you through our HyperCLOVA X Vision use cases to help you get an idea of its technology and performance.
Technology behind HyperCLOVA X Vision
HCX Vision advanced from a large language model (LLM) to a large vision-language model (LVLM). Trained on wide-ranging visual and language data, it can now support text and image modalities and perform tasks in different scenarios, such as recognizing documents and understanding text within images.
Drawing on our world-class OCR technology of extracting Korean and handwritten text, HCX Vision delivers accurate and secure services through enhanced document processing.
HCX Vision is powered by HCX, an LLM trained on vast amounts of Korean data. Its knowledge of the Korean language and culture is unmatched, and its abilities have been successfully translated into HCX Vision to understand both documents and images.
Quantitative evaluations
Public Benchmarks
|
SEEDv1 (image) |
MMMU (val) |
TextVQA (val) |
DocVQA (test) |
ChartQA (test) |
InfographicVQA (test) |
MathVista (testmini) |
VQAv2 | Average | |
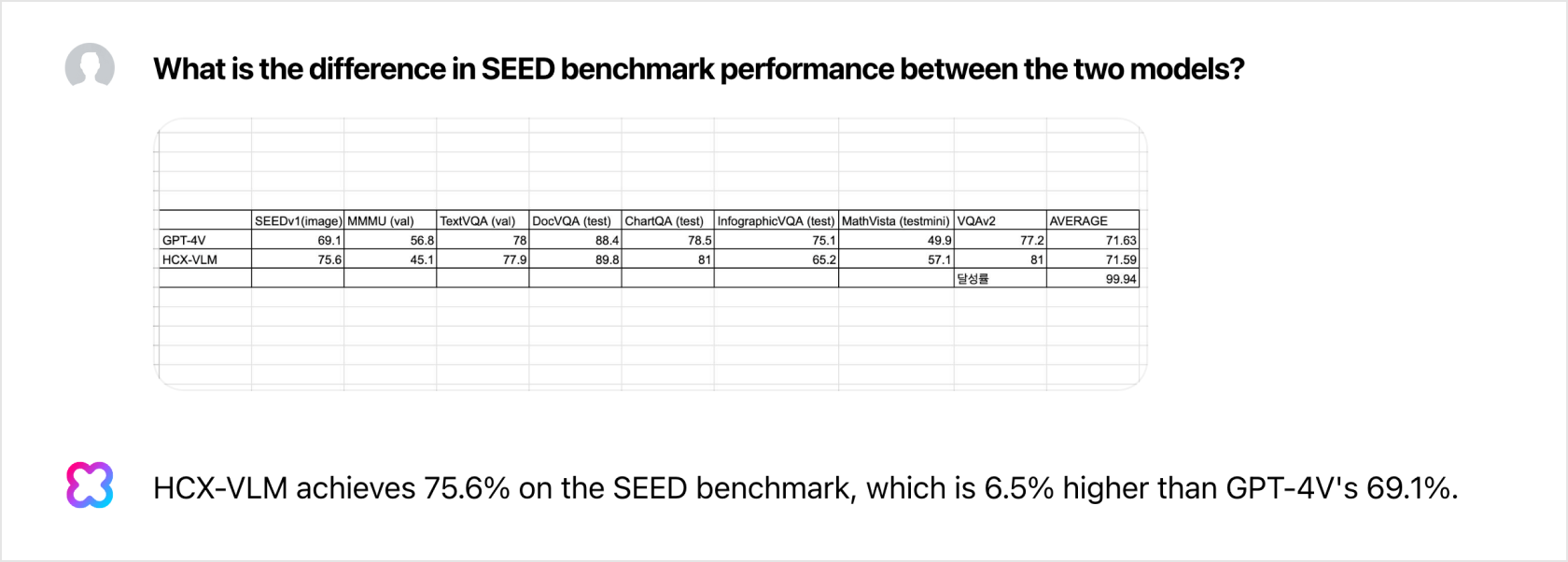
| GPT-4V | 69.1 | 56.8 | 78 | 88.4 | 78.5 | 75.1 | 49.9 | 77.2 | 71.63 |
| HCX-VLM | 75.6 | 45.1 | 77.9 | 89.8 | 81 | 65.2 | 57.1 | 81 | 71.59 |
| Accuracy (%) | 99.94 | ||||||||
We use over 30 benchmarks to track the performance of HCX Vision. Here, we examine some of them to compare our model against GPT-4V. We’ll continue to bring updates in the second half of 2024, including enhancements to reasoning and vision alignment tasks, changes to the encoder structure for high-resolution processing, and more.
K-GED performance
| Model | Correct Answers |
| GPT-4o | 1152/1480 (77.8%) |
| HCX-VLM | 1240/1480 (83.8%) |
We thought that one benchmark that could showcase a model’s Korean capabilities was the Korean General Educational Development (K-GED) tests, which are primary and secondary education equivalency diplomas. The benchmark consists of 1,480 four-option multiple-choice questions. Even when testing with image inputs, HCX Vision answered correctly 83.8% of the time, surpassing the 60% pass threshold and the 77.8% scored by GPT-4o.
Capabilities and use cases
Here, we’ll show you how you can leverage HyperCLOVA X Vision across multiple use cases. Our development is still in progress, and our model has its limitations. But we feel we’ve come a long way since the days when we had to create a separate model for each individual task.
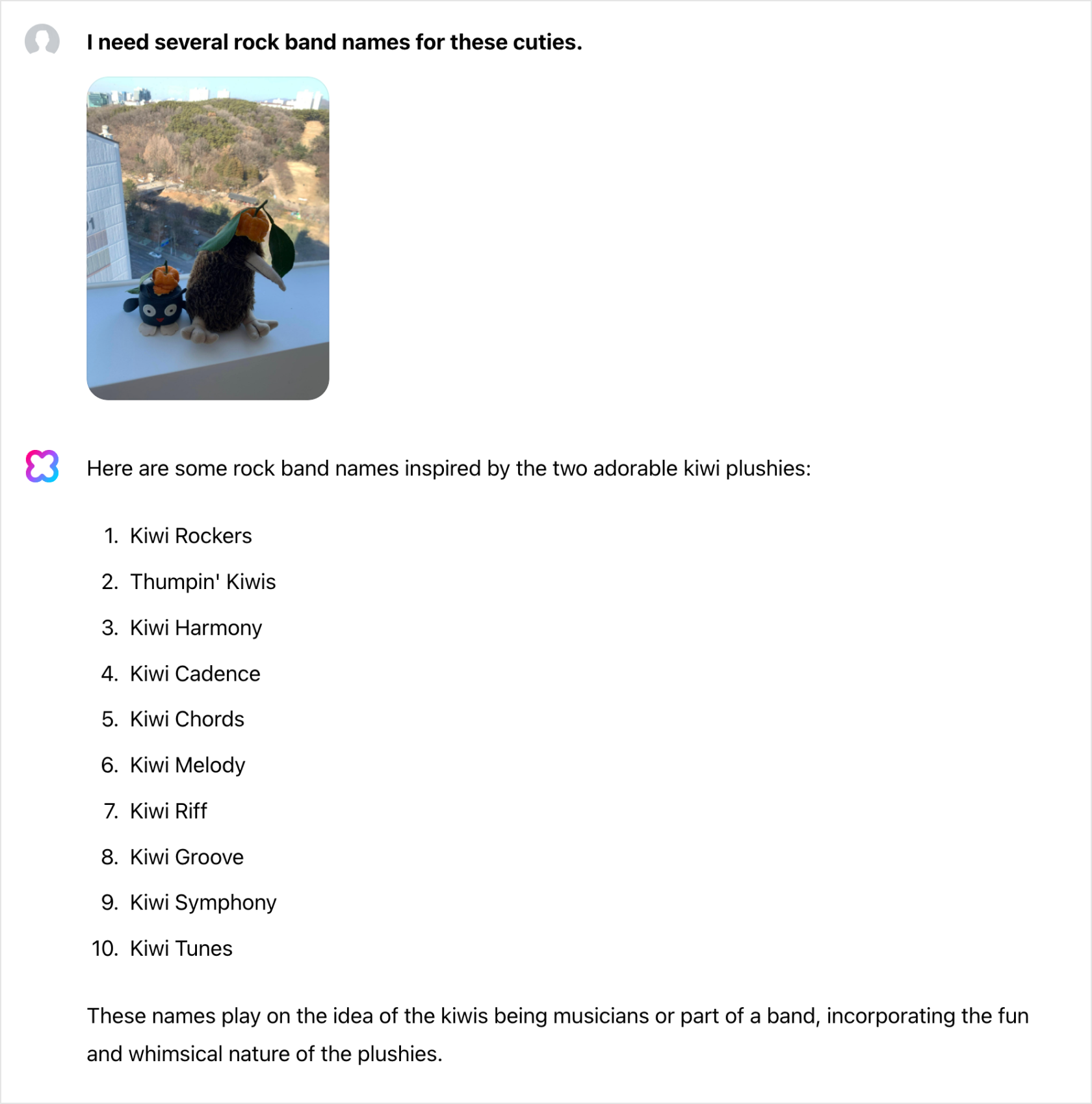
Detailed image captioning
Image captioning allows you to generate image descriptions. HCX Vision can accurately identify and describe small details in an image without using a separate object detection model.

Reasoning
HCX Vision can reason and predict the next step based on images you have uploaded. It leverages the unique capabilities of an LLM but with added visual features.

Entity recognition
An entity can be a person, place, product, or anything that holds meaning in and of itself. HCX Vision can name historical figures, landmarks, products, and food with just image inputs. Even without using the Retrieval Augmented Generation (RAG) technique, our model can easily detect entities that were part of the training data.

Chart understanding
Putting numerical data into a chart helps people understand data intuitively. But this seemingly easy task demands high performance on the part of machines because it requires making sense of something abstract.

Table understanding
Tables are often used to compare numerical data. If the data is in an Excel or CSV file, it can be processed immediately by LLMs that support text modalities. If the data is a screenshot of an image, getting responses for your prompts is more complicated because the model must first recognize text and understand how the numbers are related.
Document understanding
HCX Vision supports documents in Korean, English, Japanese, and Chinese.

Culture and humor (meme understanding)
Understanding humor and cultural norms is a highly complex ability. HCX Vision is trained on large amounts of image and text pairs and can perform well in understanding memes.
Equation understanding
Reading rendered math equations is easy, but rendering them into a digital format is difficult and could take a long time if you’re not used to writing math formulas using TeX. HCX Vision can help you save time manually inputting data.

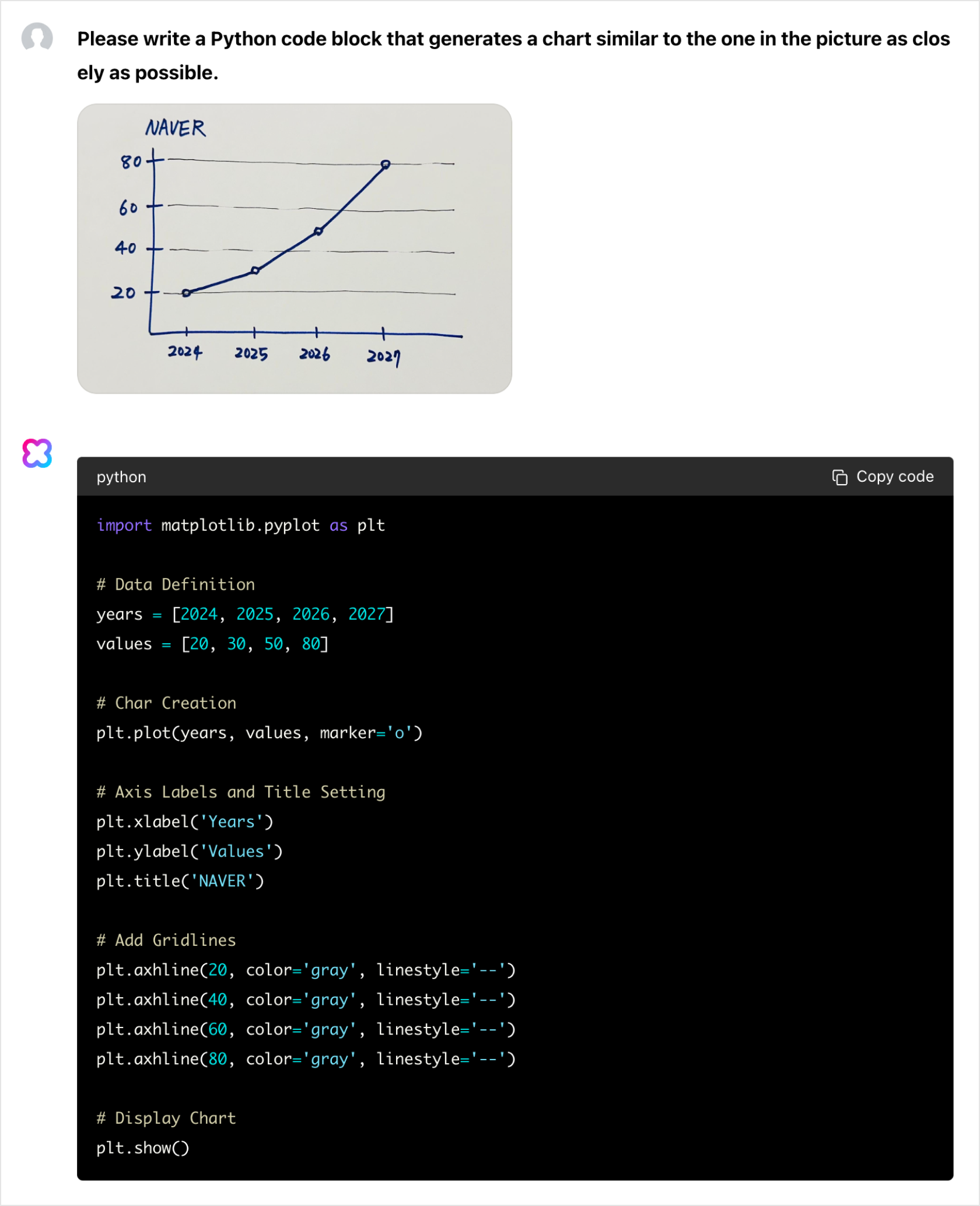
Code generation
You can show HCX Vision a shape, chart, or graph and ask HCX Vision to generate code that resembles your picture.
Math problem-solving
Get answers and explanations to math problems that include shapes.

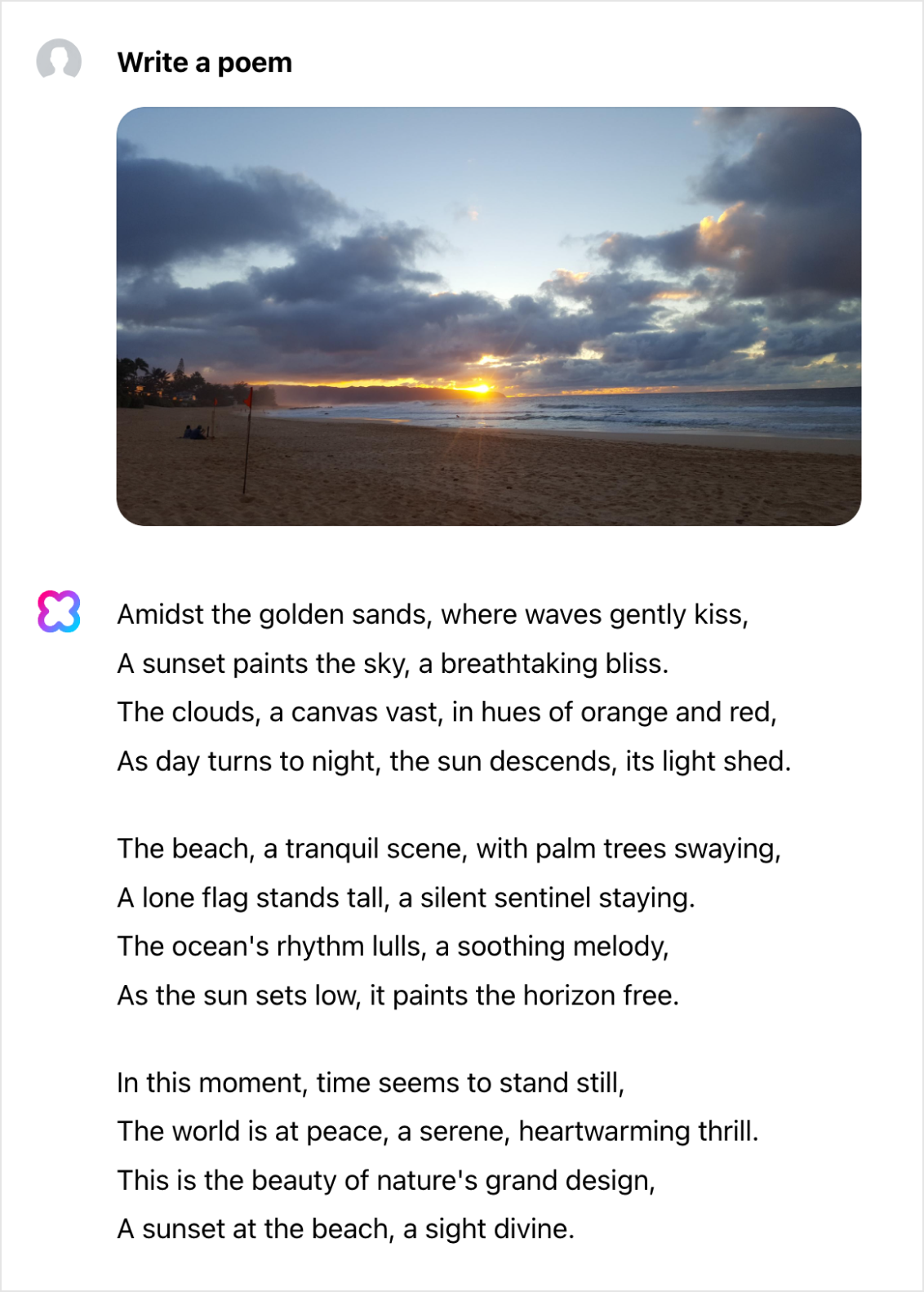
Creative writing (with image grounding)
This feature is already available in the HCX language model, but HCX Vision gets even more creative by drawing inspiration from an image.
What’s next in HyperCLOVA X Vision and sovereign AI?
Right now, HyperCLOVA X Vision can understand one image at a time. But soon, with context length support in the millions, we expect HCX Vision to understand hours-long movies and video streams. Add to that real-time processing capabilities, and AI could become an integral part of our lives, just like robots in the movies who behave like humans.
As with LLMs built to understand textual information, LVLMs must be able to understand and express different social values and norms, whatever the users’ geography and cultural backgrounds. AI sovereignty will play a vital role in interpreting visual information, making access to data aligned with our social values essential in building safe and useful AI. As Korea’s leading platform, NAVER holds an advantage in securing these kinds of quality data.
Conclusion
We expect our LVLM technology to take us beyond the limits of text-based communications and closer to how people interact in the real world. At NAVER, we’re committed to making HCX Vision beneficial to people from diverse backgrounds in many domains, and we envision a future where HCX Vision will become a part of many people’s lives.