
“Why can’t NAVER build something like this?”
Last May, someone asked this question on a YouTube video. It was a direct provocation about why NAVER couldn’t create something comparable to NotebookLM. The response was measured: “It’s not that NAVER lacks the technology—it’s just not among current resource priorities.”
But behind that reply, NAVER’s Audio LLM team felt a complex mix of emotions: frustration, yes, but also ambition. The truth was, while this technology wasn’t at the top of our roadmap, we had been preparing for it.
That single comment sparked a decision: “Let’s show the world what we’re capable of, even if it means going the extra mile.”
This is the story of how PodcastLM came to life.
Step 1: How do you get natural-sounding conversation data?
To create an AI that can talk like an actual person, you first need to collect high-quality audio conversation data. We used two approaches:
- Record conversations ourselves.
Two of our team members sat face-to-face and conversed one-on-one in a real podcast setting. We were careful to keep the voices separate, with each person recording on their own channel. It wasn’t long before the initial awkwardness passed and the conversation became natural and engaging. - Extract audio from existing content.
For those who had multiple appearances on YouTube or podcasts, we didn’t need to create new recordings. We simply extracted clean voice audio from existing videos.

Figure 1. How data preparation works
But we couldn’t just use any audio—the data needed to meet requirements:
- Must contain only one person’s voice
- Cannot include other speakers, background noise, or sound effects
- Audio quality must be professional-grade
- Must align perfectly with corresponding text
Our team organized this data and used it to train our audio LLM.
Step 2: Can AI voices truly sound human?
Theoretically, yes. But practically speaking, this was new territory for us. It was our first attempt at training a Voice Engine using natural conversations between ordinary people.
The results far exceeded our expectations. From pronunciation and intonation to tone and breathing patterns, the output sounded remarkably human.
While converting text to audio isn’t new, our Voice Engine achieves exceptionally natural results because it’s built on core foundational technologies we’ve been developing for some time: HyperCLOVA X Audio, our Voice Model, and UnitBIGVGAN. From the outside, it may look like simple “AI that can talk,” but inside, it’s a carefully orchestrated system where each component plays a crucial role.

Figure 2. Core models and their roles in implementing AI audio capabilities
HyperCLOVA X Audio serves as our backbone model—the foundation of our audio AI technology. It provides essential audio-language understanding capabilities. Think of it as a car’s engine: the better the engine, the better the car performs. Similarly, a stronger backbone means superior performance across diverse audio tasks.
Our Voice Model acts as a bridge connecting HyperCLOVA X Audio and our Voice Engine. It fills the critical gap between these components, strengthening the entire system’s performance.
Our Voice Engine is the star of PodcastLM—an advanced text-to-speech model that naturally conveys emotions, breathing patterns, and nuanced intonation.
UnitBIGVGAN serves as the final converter, transforming voice tokens generated by the Voice Engine into actual audio signals that can be played back.
Step 3: Bringing PodcastLM to life
But creating a Voice Engine was only half the battle. To complete PodcastLM, we needed another crucial component—generating a “script” that the AI would read aloud. When a user inputs documents or text, our LLM analyzes the content and creates a script that sounds natural when spoken, as if real people were having a conversation.
The key to this process is prompting.
Effective prompts must contain clear instructions that the AI can easily understand and follow. At the same time, they must be designed to produce genuinely conversational output. We decided to include actual speech patterns from our Voice Engine as examples in our prompts, making the generated scripts sound much more natural.
Through countless iterations and refinements, we perfected our prompting approach. The resulting scripts are then processed by our Audio LLM to produce podcasts that sound like authentic discussions.
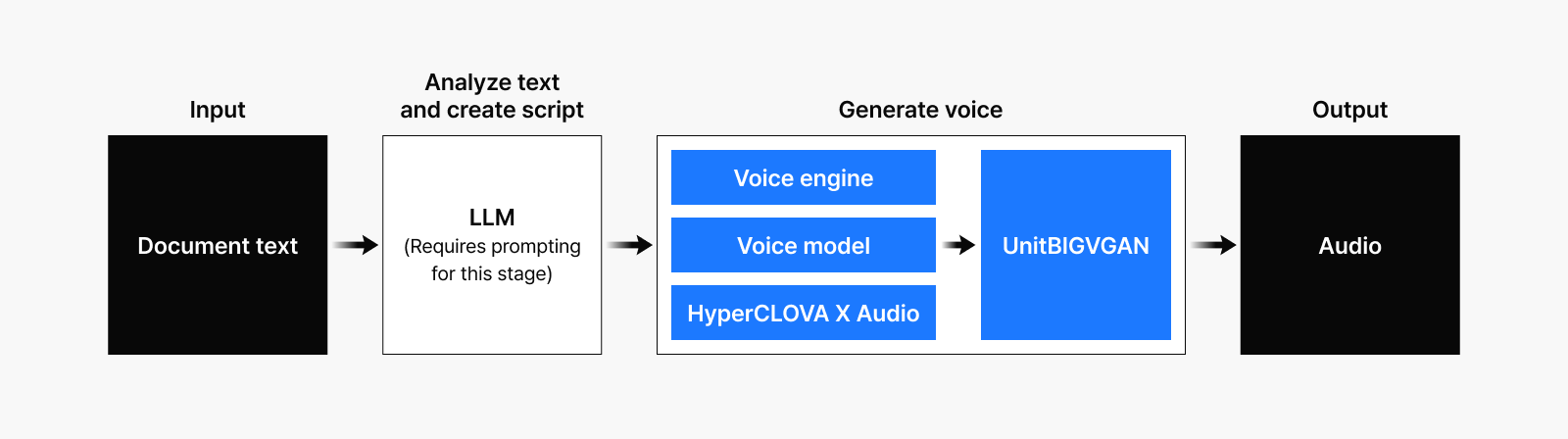
Figure 3. PodcastLM structure
TEAM NAVER has done it and will continue to innovate
The PodcastLM project wasn’t simply a technological experiment, but a demonstration of NAVER’s audio generation capabilities. This project challenged us to create the most user-friendly AI possible and opened up new possibilities for the future.
But this is only the beginning. Our ultimate goal extends far beyond converting text to audio. We’re working toward building an intelligent voice agent that can communicate like a human being. By creating a more human-like multimodal agent that understands context and emotions while leveraging LLM reasoning capabilities, we believe conversations with AI will become much more natural and meaningful.
Today, more than ever, what matters isn’t just how well technology is built, but how thoughtfully it’s applied. As TEAM NAVER, we’ll continue prioritizing users over technology itself, creating unique NAVER AI experiences that blend seamlessly with our emotions, culture, and daily lives.
Hear it in action
The following audio was automatically generated using our PodcastLM system based on this article’s content. AI hosts deliver the information naturally in a conversational format, courtesy of Moon Hakbum from NAVER and Lee Zoo Hyun from NAVER Cloud.