As LLMs become increasingly sophisticated in capabilities like search and reasoning, they inevitably run into a challenge in real-world applications: speed. These models generate text one token at a time, requiring the entire parameter set for each prediction. As models grow larger, this sequential approach creates mounting latency issues that hardware improvements alone can’t resolve.
Speculative decoding offers a promising solution to this bottleneck. Instead of generating tokens one by one, this technique uses parallel processing to dramatically speed up inference. Major AI companies have already adopted variations of this approach—OpenAI with Predicted Outputs and DeepSeek with Multi-Token Prediction (MTP)—both seeing substantial speed gains in production.
In this post, we’ll explore how speculative decoding works, examine its trade-offs, and dive into our experience implementing it for HyperCLOVA X. We’ll share the challenges we encountered along the way, and how we built the technology into a solution that works in the real world.
▲HyperCLOVA X demo: Standard inference (left) vs. speculative decoding (right) showing identical output quality with faster generation.
What is speculative decoding?
Instead of generating tokens sequentially, speculative decoding uses a smaller, faster model to generate multiple candidate tokens, which a larger model then validates in parallel—dramatically improving generation speed.
The process involves two key components: a draft model that’s smaller and faster, creating the initial predictions, and a larger target model that reviews and finalizes those predictions. The draft model proposes several token candidates simultaneously, while the target model evaluates all of them at once to determine the final output.
Let’s examine how this works in practice.
How speculative decoding works
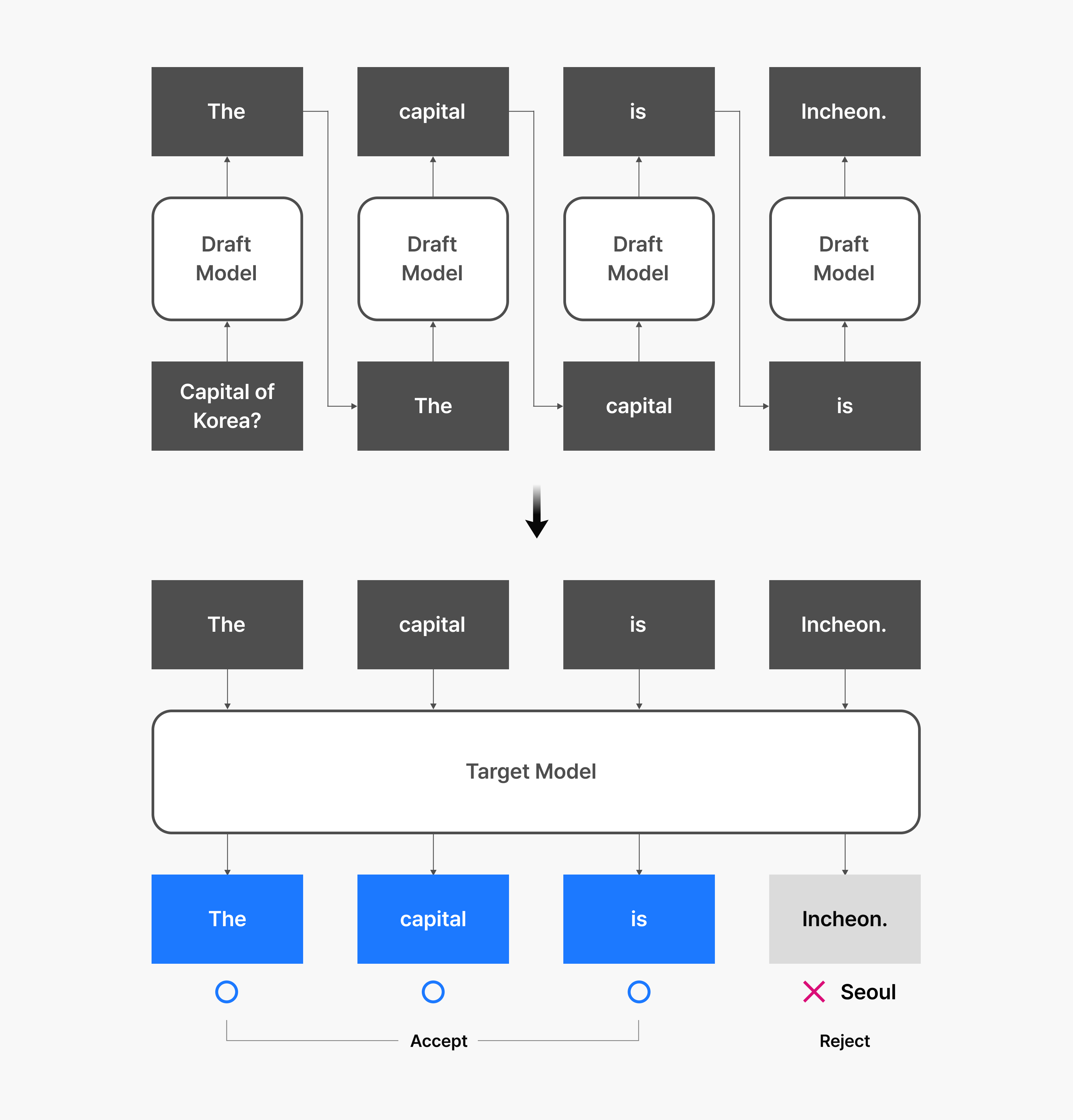
- The draft model generates multiple token candidates based on the user input.
- The target model validates all these candidates simultaneously using parallel processing.
- Accepted tokens move forward while rejected ones are regenerated by the target model.
The key insight is that the context is often predictable enough that the draft model’s predictions are frequently accepted. Since the target model can validate multiple tokens in parallel rather than processing them one at a time, this approach maximizes hardware efficiency and delivers substantial inference speed gains.
Speculative decoding also offers the advantage of being relatively straightforward to implement. It requires only models of different sizes that share the same training setup and tokenizer. The more closely the draft and target models align in their predictions, the greater the speed improvements you’ll see.
Accelerating without changing generation distribution
Traditional model compression techniques like pruning and quantization can improve inference speed, but they often alter the model’s generation distribution or degrade output quality. This creates additional validation overhead in production environments, especially for quality-sensitive services, making teams hesitant to adopt them.
Speculative decoding takes a different approach. It uses rejection sampling, a probability-based method that preserves the original model’s generation distribution while delivering performance gains.
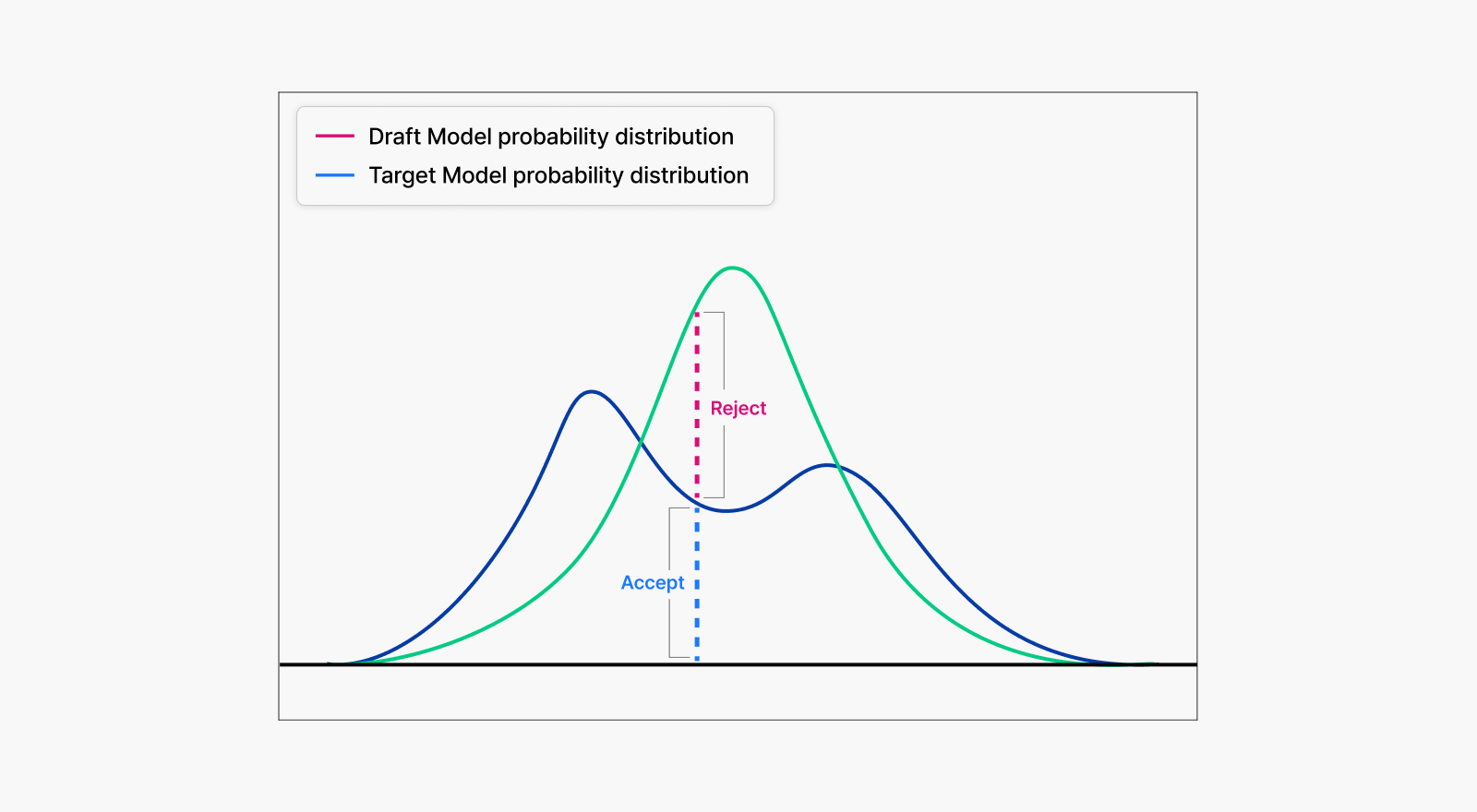
The draft model quickly generates token candidates, then the target model evaluates each candidate against its own probability distribution. For instance, if the draft model predicts token A with 90% confidence while the target model would assign it only 60% probability, the acceptance rate becomes 60/90, or roughly 66.7%. Otherwise, tokens get rejected and the target model regenerates new ones.
This process ensures the final output statistically matches the target model’s distribution exactly. Crucially, this preserves not just accuracy but the model’s characteristic tone, style, and linguistic patterns, and other subtle qualities.
Consider a target model that typically responds with “Hello” seven times out of ten and “Nice to meet you” the other three times. Speculative decoding maintains exactly this distribution. While both greetings may seem equivalent in quality, consistent tone and behavior significantly impact user experience, making this preservation essential for production services.
By meeting both speed and quality preservation needs, speculative decoding offers a practical solution that teams can deploy in real-world applications.
Performance determiners: Acceptance rate and speculation length
As we’ve seen, speculative decoding delivers speed improvements without altering the model’s generation distribution. But how much performance improvement can we realistically expect?
Performance depends primarily on two key factors:
- Draft model acceptance rate and speed
- The critical question is how quickly the draft model can generate tokens similar to the target model’s while maintaining a high acceptance rate.
- If the draft model is slow or produces tokens that get frequently rejected during validation, overall processing speed won’t improve—and may actually get slower.
- Speculation length configuration
- Speculation length determines how many tokens the draft model predicts at once and serves as a crucial tuning parameter.
- Too short, and the acceleration benefits remain limited.
- Too long, and low acceptance rates lead to inefficiency.
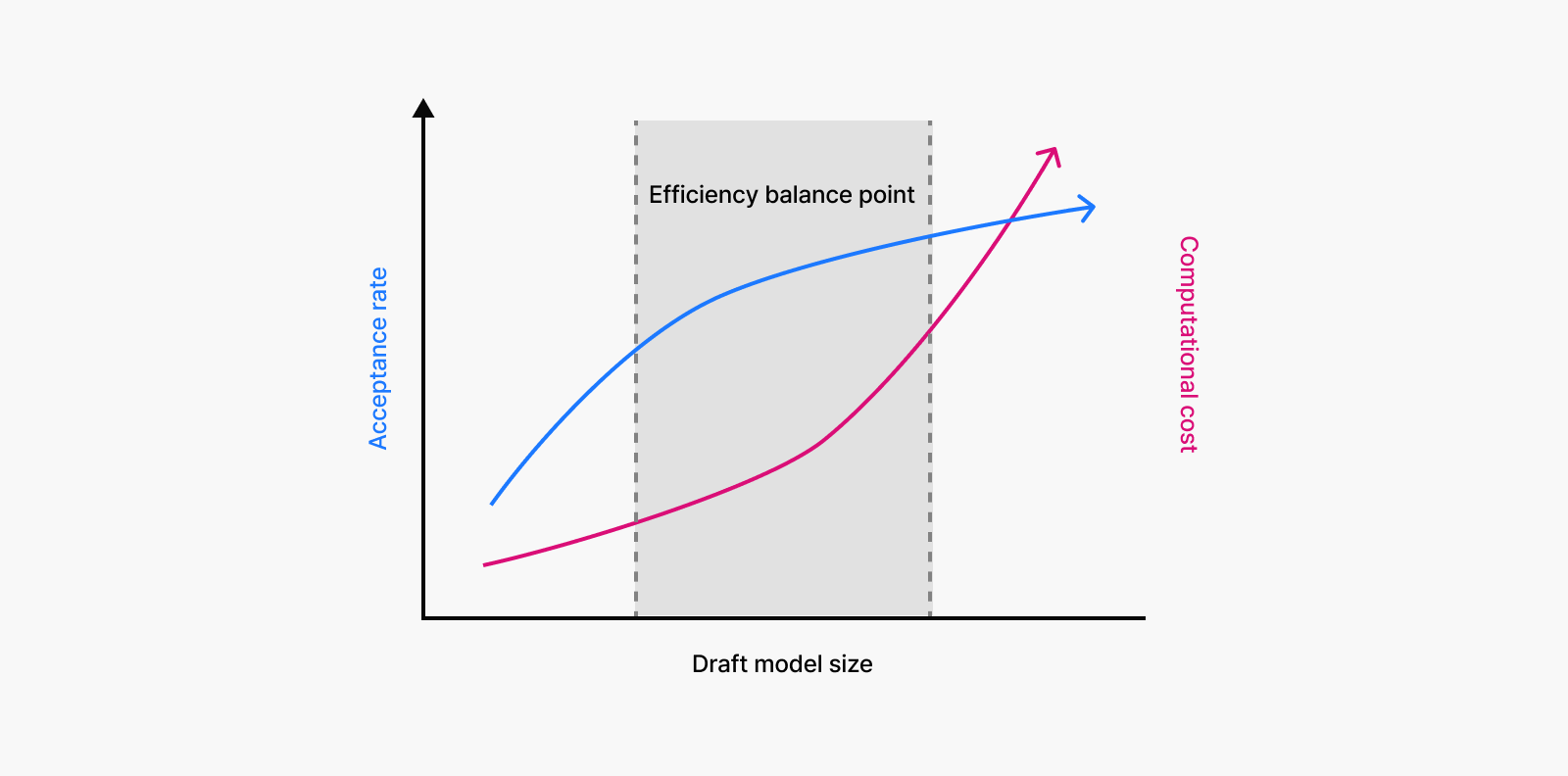
A fundamental trade-off emerges here. For draft models to generate outputs similar to target models, they require a larger size. While it would be ideal for smaller, lightweight models to generate similar predictions, in reality, smaller models tend to have lower acceptance rates, leading to frequent rejections and overall performance drops. This makes finding the right balance between model size, acceptance rate, and processing speed essential.
Speculation length shouldn’t be fixed but should adapt dynamically based on model combinations and system conditions. If speculation length is too short, the acceleration benefits remain limited, whereas if it’s too long, validation fails frequently and creates inefficiency. This requires systems that can optimize in real-time rather than relying on fixed configurations.
Strategies for delivering reliable services
While speculative decoding aims to increase generation speed, incorrect speculation can lead to additional computational costs that actually hurt performance. This is particularly true with longer speculation lengths, where frequent failures can dramatically reduce overall inference efficiency.
Production environments bring constantly shifting variables: varying user input lengths, fluctuating concurrent request volumes, and server load changes throughout the day. As a result, optimal speculation length conditions change continuously as well.
Aside from technological possibilities, real-world deployment challenges prove far more complex and unpredictable. This is why adaptive strategies are essential—systems that can flexibly adjust speculation lengths based on real-time conditions to maintain optimal performance.
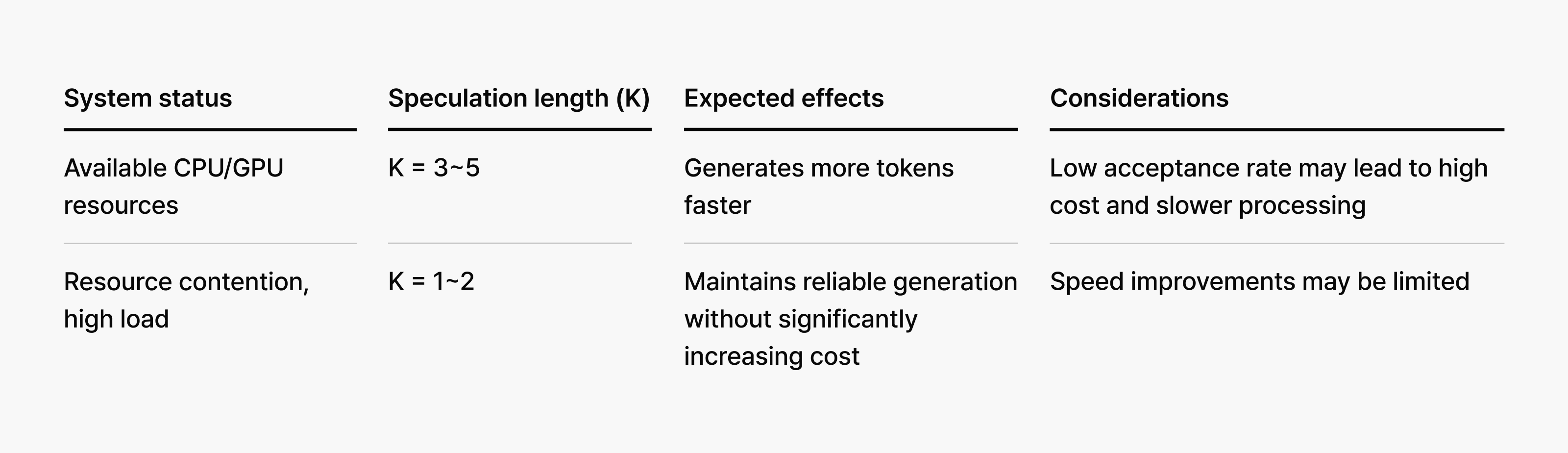
For instance, when system resources are abundant, speculation length can be expanded more aggressively to maximize speed gains. Conversely, during high-load periods with concentrated requests and resource constraints, reducing speculation length prioritizes service reliability over speed improvements.
Why choosing the right model and benchmark is important
Draft model selection is another critical factor in speculative decoding performance. Overly simple draft models suffer from low acceptance rates, while oversized models reduce the speed advantage over the target model, potentially reducing overall efficiency.
The key metric is acceptance rate—how frequently the target model validates speculation results as actual outputs. High acceptance rates allow tokens to pass validation quickly, accelerating inference speed. Incorrect speculation, however, requires recalculation and can actually increase overall processing time.
Maximizing speculative decoding efficiency requires finding the optimal balance between acceptance rate and computational cost rather than simply selecting “fast models.” To achieve this goal, we experimented with various draft models, comparing how different draft-target combinations performed under diverse operational conditions.
Applying speculative decoding in production
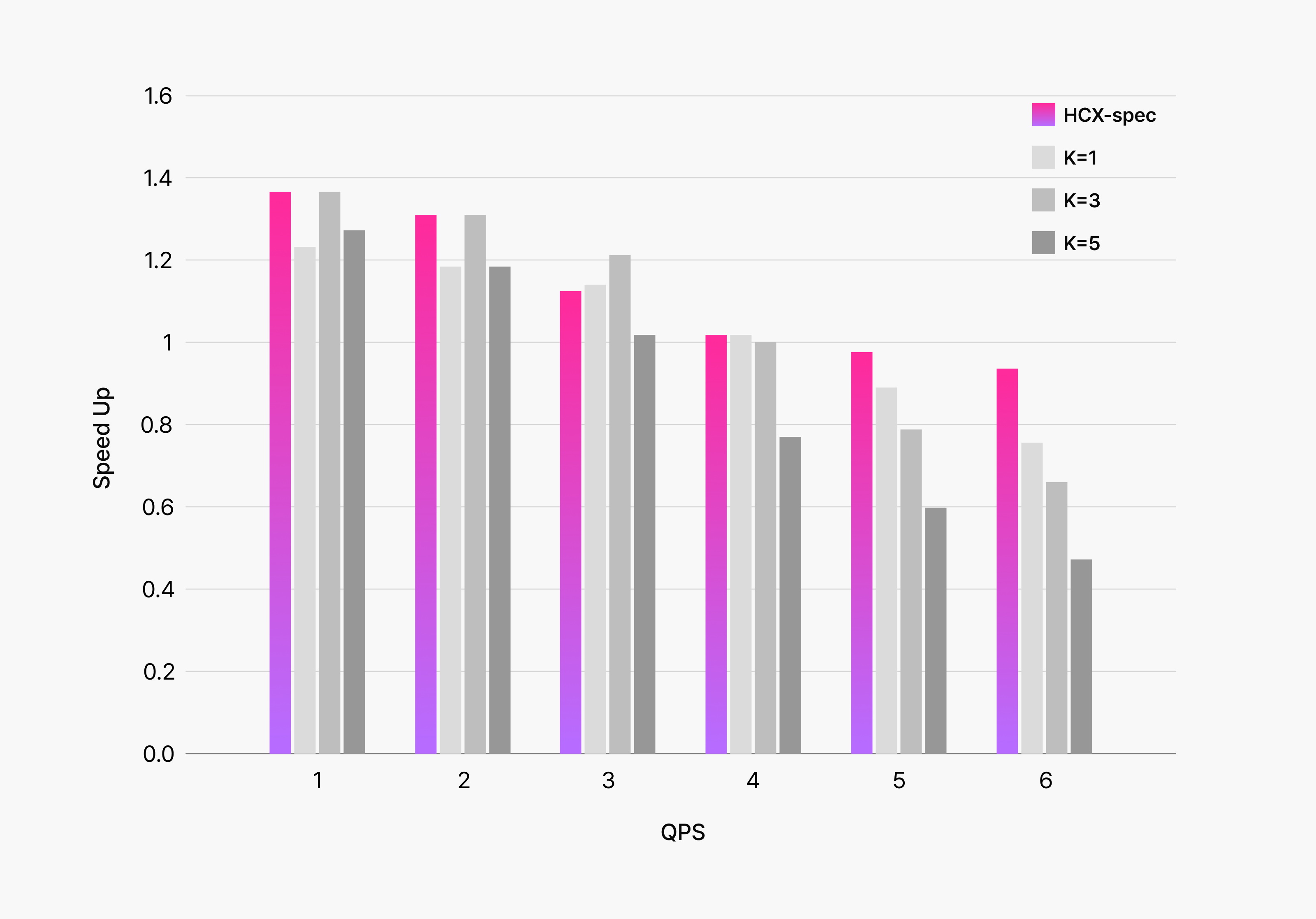
When we deployed speculative decoding in our production environment, we discovered that dynamically adjusting speculation length based on system conditions significantly improved overall efficiency.
The graph below shows our experimental results applying speculative decoding to HyperCLOVA X, comparing fixed speculation token counts against dynamic adjustment based on system status. The dynamic approach clearly achieved superior performance across both speed and reliability metrics.
During periods of low service load with short user inputs, we increase speculation length to maximize speed gains. Conversely, when facing high load or lengthy inputs, and lower acceptance rates, we use conservative speculation lengths to prioritize service reliability over performance.
The key insight from this experiment was that maximizing speculative decoding performance goes far beyond simple technology deployment. Success requires dynamic strategies specifically tailored to real-world operational environments. This adaptive approach proved essential for translating technological capabilities into measurable benefits.
Conclusion
At HyperCLOVA X, we don’t stop at building high-performance models. We continuously pursue optimization strategies that deliver faster, more efficient user experiences.
Speculative decoding represents one key approach toward this goal. Rather than simply implementing the technology, we focused on creating adaptive systems that respond to real-world production environments.
Moving forward, we plan to develop smaller, faster draft models with higher acceptance rates while exploring additional optimization techniques that maximize speculative decoding efficiency.