
AI that can talk and understand human emotions
The way we communicate goes beyond words. We use paralanguage, like tone and pace, to reveal our emotions and intents. When we say, “I’m all right,” it takes on an entirely different meaning depending on whether we use a sad or happy voice.
Until recently, conversing with an AI has never quite felt like talking to an actual person. It didn’t always adopt the right tone and manner and often deviated from the topic. This is because, traditionally, AI relied on text to recognize information and generate responses, and voice capabilities were added only later on in the process. Creating a human-like AI like Jarvis in “Iron Man” requires an understanding of the subtleties of human communication.
The evolution of voice AI
Voice AI has gone through transformative changes in recent years. In May 2024, OpenAI released GPT-4o, garnering wide attention for its voice capabilities. Amazon also plans to launch the upgraded Alexa voice assistant in 2024.
What marks a decisive shift away from text-driven AI models is that you can now speak with AI and expect it to understand the underlying emotions behind words. While AI has yet to understand and convey the complexities of human emotions, this new approach is a meaningful step toward the goal.
Lost in translation: The limitation of existing technologies
Voice AI has so far been built on a cascade of models. It worked by converting audio to text (speech-to-text), processing text, and converting text back to audio (text-to-speech). Paralanguage, including rhymes and emotions, is bound to be lost somewhere in the process.
Taking a new approach: AI that can understand human emotions
Against this backdrop, an end-to-end approach to voice AI is becoming increasingly popular. It ensures that all the paralinguistic elements are preserved when converting speech to text. How is this possible?
This new approach works in three steps: extracting audio features, generating response features, and restoring the generated features to audio.
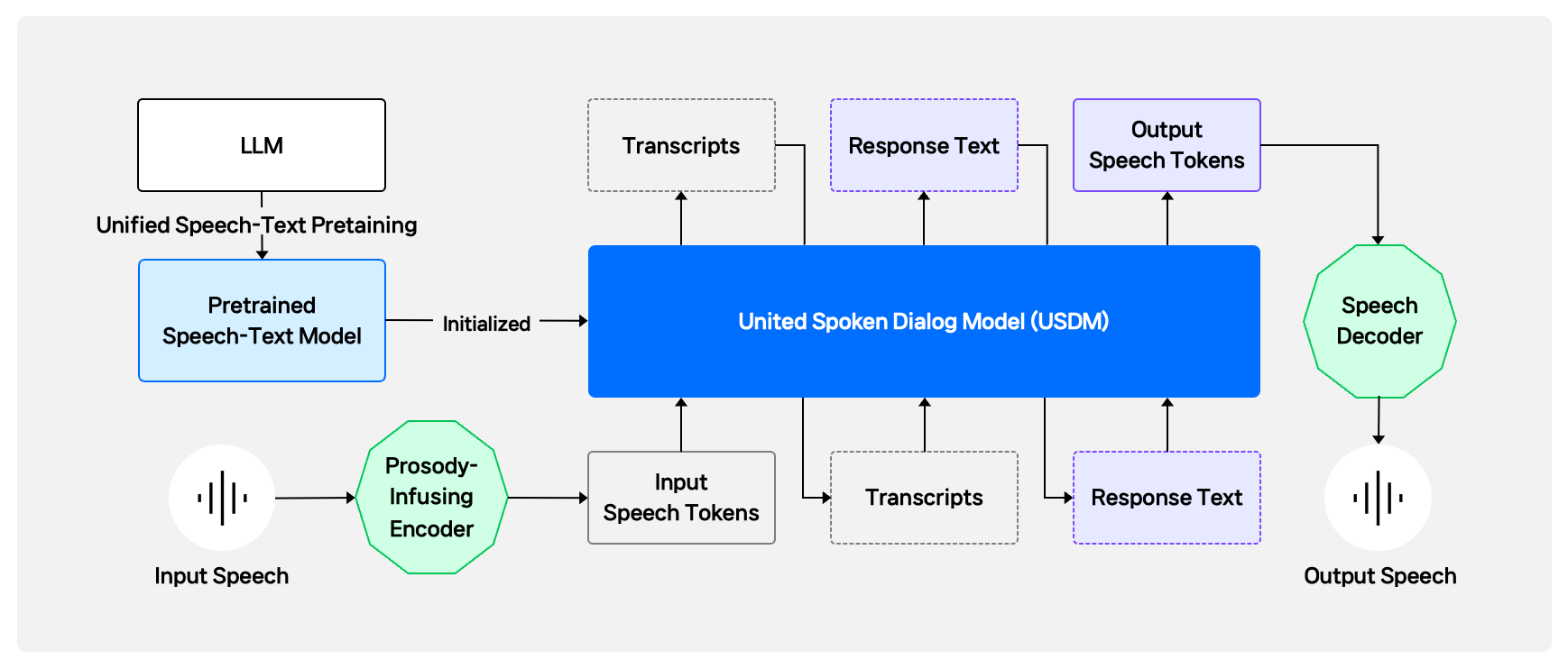
Developing a unified spoken dialog model (USDM) for this purpose involves building a text-based language model, adding audio capabilities, and fine-tuning the model with actual conversations.
AI uses speech tokenization to detect emotions from voice conversations, catching the subtle nuances of voice. It also employs interleaving training to generate context-aware responses and converse in the right tone.
|
For example, when someone says, “I’m all right” in a sad voice, the AI: 1. detects the emotion from the input audio (low tone, slow pace, soft voice) 2. deduces that such a pattern implies that the speaker is not all right 3. generates an empathetic response in a warm tone |
One study showed that the accuracy rate for detecting emotions from voice conversations using an end-to-end approach reached 73.62%, a testament to how adept AI has become at capturing paralinguistic information. Let’s explore these two technologies further.
Speech tokenization
Speech travels through the air as sound waves and can be represented as a waveform with continuous values (see the figure below).

A speech waveform contains more than just words, encompassing everything from emotion and tone to pace and intonation. LLMs are trained on speech data through tokenization, a process where speech data is compressed on the time axis and converted into an integer. The most important thing here is the number of whole units it takes to represent speech : too few units can result in the loss of important information, while too many cause a drop in processing efficiency. The idea is similar to a high-resolution image that holds minute color details.
Recent studies suggest that tokenization is most effective when speech is split into 10,000 tokens, the number it takes to turn even nonverbal aspects of communication into data. Indeed, when tokenized speech data was restored to the original format, the sound pitch and voice changes were identical to those in the source data.
Speech that has been converted into 10,000 tokens includes the following information:
- Speech’s content and speaker’s pronunciation
- Patterns of pitch changes
- Speaking pace and rhythm
- Change in volume
- Voice characteristics that tell a speaker’s emotions
Interleaving training
Text-driven LLMs could take in only one of two inputs at a time: text or audio. The language we use to communicate, however, is any combination of text and audio. Interleaving training attempts to teach AI models how to communicate with human language.
Using this method, AI is trained on different types of data, like text and speech. AI can interpret texts and learn voice characteristics, including intonation, stress, and tempo. You can also place training data in different orders so that AI can effectively learn the association between two modalities in varying contexts.
|
An example of interleaving training: 2. [An audio token containing the speaker’s bright voice] 3. [An audio token containing a warm tone] 4. “Hi, nice to meet you.” (text) |
The future of AI emotion recognition
AI emotion recognition has come a long way, transforming how humans interact with AI. It has evolved from a functional tool to a conversational partner, and the possibilities are endless. Speech tokenization could become even more sophisticated and we might discover a way to convert words into tokens more effectively. In addition to text and audio, interleaving training may support other modalities like image and video.
We expect the advancement of the technology will make a real impact in wide-ranging areas, including customer service, healthcare, and education:
- Customer service: AI can understand customers’ intent and emotions and respond in real time, leading to better user experiences. It allows for more personalized interactions, like responding empathetically to customers who raise complaints. AI can also analyze customer feedback in both text and audio and classify data into positive, neutral, and negative sentiments to improve efficiency.
- Healthcare: AI can analyze speech patterns to check on a person’s emotional and mental health. Some research suggests that AI can detect depression and other mental illnesses, and many are hopeful that AI could help monitor people’s mental health.
- Education: AI can tell if students are bored or frustrated and adopt a different teaching method accordingly. A pilot program experimenting with an AI tutor has shown that it improves students’ academic performance.
Can AI understand human emotions?
By now, you may be wondering: Can AI actually feel? The answer is no—AI has no feelings. Just like text-driven LLMs are trained on text patterns to output text, voice AI is trained on conversation patterns to output voice.
You might also be wondering if AI classifies speech tokens as certain types of emotions. The answer here, too, is no. AI does not classify and identify emotions like “this is a sad feeling” or “this is a happy feeling.” Instead, the AI works the following way:
1. Learn patterns.
- Study the relationship between speech patterns and context from large-scale conversation data.
- Identify the combination of voice characteristics that appear frequently in certain situations.
- Example: AI is trained to learn that “Congratulations” often goes with a bright and high tone.
2. Identify the context.
- Analyze how voice characteristics are related to the conversation context.
- Example:
- A. Patterns associated with sadness: low tone, slow pace, soft volume
- B. Patterns associated with happiness: high tone, fast pace, loud volume3. Identify the context.
3. Reproduce patterns.
- Reproduce voice characteristics based on training data.
- Example:
- A. Take up a comforting tone to offer consolation.
- B. Take up a light tone to offer congratulations.
| # How AI works in real-life conversation When someone says in a sad voice, “I’m all right,” the AI takes the following steps: 1. Analyze the input pattern.- Words: “I’m all right.”- Voice characteristics: low tone, slow pace, soft volume- The AI draws from the training data to conclude that such a pattern implies the speaker is not all right. 2. Understand the context.The AI understands that the text “I’m all right” combined with a sad voice pattern suggests the speaker needs to be consoled.The AI makes a comprehensive analysis of the surrounding context and voice characteristics. 3. Generate an appropriate response. Choose empathetic words and apply a voice pattern that is soft and warm in tone. The AI answers in a reassuring tone: “Do you want to tell me what happened?” |
Reshaping the future with AI
AI technology has advanced so much that we can now train AI what to say and how to say it, which is a significant step towards a more natural interaction between humans and computers. Because even at this stage, AI merely mimics humans by learning their conversation patterns, multimodal AI models face the same limitations as text-driven LLMs. On top of existing issues, voice AI will also bring new ethical challenges, including voice replication and privacy intrusion.
However, LLMs with audio capabilities are not just about enhancing performance. They’re about understanding human intents and generating context-aware responses. Although AI cannot feel in the real sense of the word, it can now address users’ needs in a more satisfying way, and this technology has the potential to transform human-computer interactions.